Pay As You Go - AI Model Orchestration and Workflows Platform


The rapid growth of large language models (LLMs) demands precise evaluation tools to ensure accuracy, compliance, and performance. This article explores the top LLM evaluation platforms for 2026, focusing on their ability to streamline testing, monitor production, and integrate human feedback. Here's what you need to know:
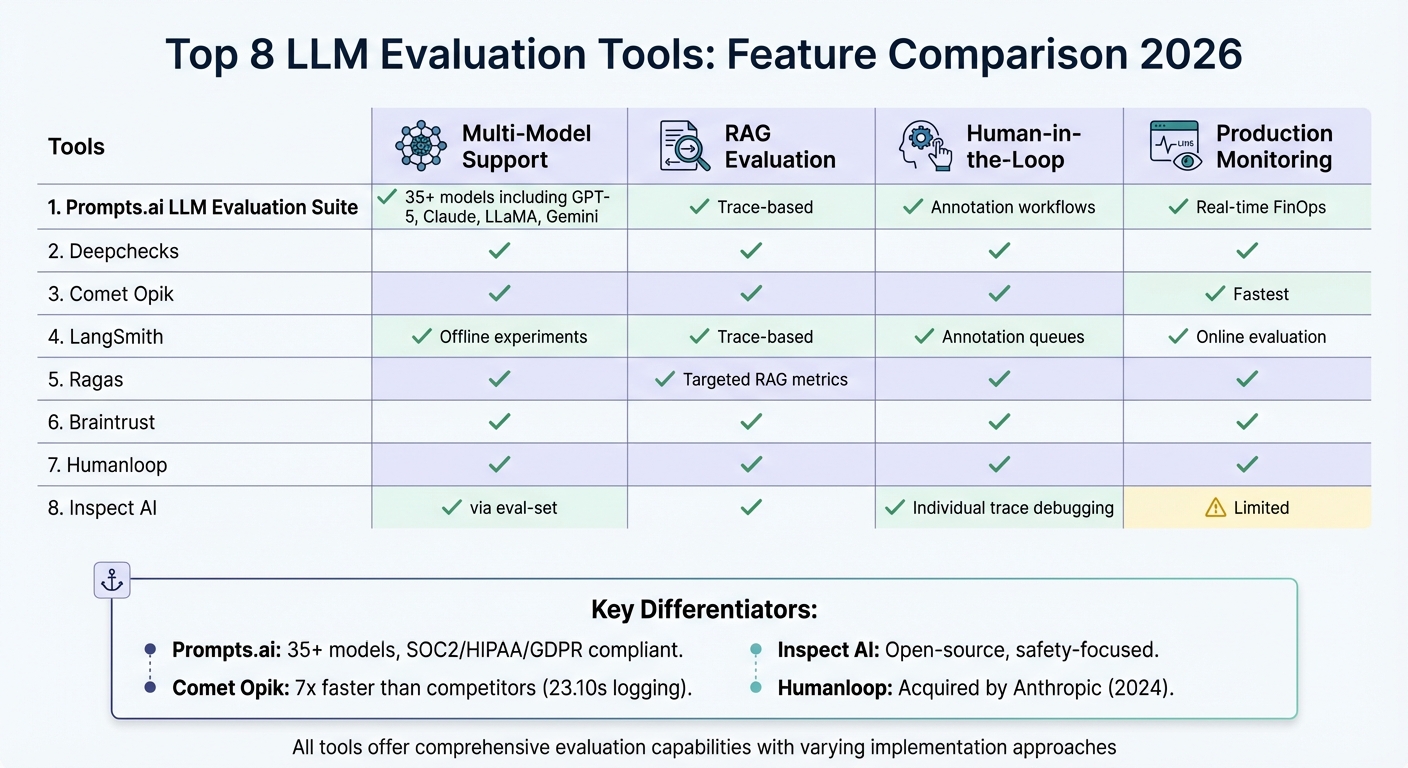
Each tool addresses LLM variability and evaluation challenges differently, offering features like automated scoring, human-in-the-loop workflows, and compliance monitoring. Below is a quick comparison of their key capabilities.
| Tool | Multi-Model Support | RAG Evaluation | Human-in-the-Loop | Production Monitoring |
|---|---|---|---|---|
| Prompts.ai | Yes (35+ models) | Yes | Yes | Yes |
| Deepchecks | Yes | Yes | Yes | Yes |
| Comet Opik | Yes | Yes | Yes | Yes |
| LangSmith | Yes | Yes | Yes | Yes |
| Ragas | Yes | Yes | Yes | Yes |
| Braintrust | Yes | Yes | Yes | Yes |
| Humanloop | Yes | Yes | Yes | Yes |
| Inspect AI | Yes | Yes | Yes | Limited |
These tools empower teams to validate LLMs effectively, ensuring reliable and compliant AI systems for industries like healthcare, finance, and beyond.
LLM Evaluation Tools Comparison: Features and Capabilities 2026
The Prompts.ai LLM Evaluation Suite addresses a critical challenge: comparing and validating AI models throughout the entire development process. Operating under the guiding principle that "Evaluation engineering is half the challenge", this suite streamlines operations by consolidating over 35 leading LLMs into a single, easy-to-use interface. Say goodbye to juggling multiple dashboards and API keys - this platform simplifies everything.
With its side-by-side model comparison, the suite allows you to test identical prompts across providers like GPT-5, Claude, LLaMA, and Gemini in real time. The Engine Overrides feature offers precision by letting you tweak evaluation pipelines, adjusting parameters like temperature or token limits for each run. Meanwhile, the Visual Pipeline Builder - a user-friendly, spreadsheet-style tool - makes it possible for engineers and domain experts alike to create intricate A/B tests without writing a single line of code.
For retrieval-augmented generation (RAG) systems, the platform ensures accuracy by validating responses against predefined "golden datasets." It also employs LLM-as-a-judge techniques to verify factuality and relevance within the given context. The suite includes over 20 column types for evaluation, ranging from basic string comparisons to custom webhooks and code snippets, enabling tailored assessment logic for proprietary needs.
Understanding that metrics alone can't capture the nuances of language, the suite incorporates a "HUMAN" column for manual grading. Reviewers can provide numeric scores, detailed feedback, or use sliders to assess subjective elements like tone or brand consistency. For chatbot evaluation, the conversation simulator supports up to 150 conversation turns, combining automated checks with human oversight to ensure high-quality, multi-turn dialogue performance.
The suite’s Nightly Evaluations feature samples production requests to identify performance issues or model drift, with real-time Slack alerts keeping you informed. Its CI/CD integration ensures that no new prompt version is deployed without meeting quality benchmarks. For industries with strict regulations, the platform is certified for SOC2 Type 2, GDPR, HIPAA, and CCPA compliance, and offers BAAs for healthcare. Additionally, it provides real-time token accounting and cost analytics to manage the high token usage typical of RAG workflows. Comprehensive audit trails further support regulatory compliance and internal reviews.
Deepchecks tackles the challenge of evaluating large language models (LLMs) by offering side-by-side comparisons of model versions, prompts, agents, and AI systems. It integrates embedding models, vector databases, and retrieval methods into a unified workflow, streamlining the evaluation process. This approach opens doors to advanced methods for assessing multiple models.
Deepchecks is designed to handle the variability in LLM performance through its robust multi-model support. By leveraging small language models (SLMs) and Mixture of Experts (MoE) pipelines, it acts as an intelligent annotator, delivering objective scoring. This system ensures consistent performance metrics across various LLM providers. Users can also create no-code evaluators with Chain-of-Thought reasoning to analyze specific workflow segments. Deepchecks is seamlessly integrated with AWS SageMaker and is a founding member of LLMOps.Space, a global community for LLM practitioners.
The platform specializes in evaluating Retrieval-Augmented Generation (RAG) systems by assessing groundedness and retrieval relevance. Its Golden Set Management feature helps create consistent test sets for benchmarking different model versions.
Deepchecks combines automated scoring with manual overrides, allowing experts to refine ground truth datasets. Its no-code interface empowers non-technical professionals to define evaluation criteria tailored to specific business needs.
Deepchecks ensures smooth production workflows by monitoring issues like hallucinations, harmful content, and pipeline failures. It also adheres to strict compliance standards, including SOC2 Type 2, GDPR, and HIPAA. Deployment options are flexible, ranging from Multi-Tenant SaaS to Single-Tenant SaaS, Custom On-Prem, and AWS Zero-Friction On-Prem, catering to data residency requirements. For organizations with high-security needs, such as those using AWS GovCloud, the platform offers root-cause analysis tools to identify weak points and troubleshoot failed steps in LLM applications.
Comet Opik stands out for its speed and adaptability in evaluating large language models (LLMs). It logs traces and spans in just 23.10 seconds and delivers evaluation results in an impressive 0.34 seconds. This makes it nearly seven times faster than Arize Phoenix and fourteen times faster than Langfuse. Leonardo Gonzalez, VP of the AI Center of Excellence at Trilogy, praised its efficiency:
"Opik processed interactions and delivered metrics almost instantly after logging - a remarkably fast turnaround".
Opik’s speed is matched by its broad compatibility with leading models. It integrates seamlessly with platforms like OpenAI, Anthropic, Bedrock, and Predibase. Its Prompt Playground allows users to test models side by side, tweak parameters such as temperature, and switch models for real-time performance comparisons. Additionally, Opik supports LLM Juries, enabling multiple models to evaluate outputs independently and combine their scores into a single ensemble score. Its parent platform, Comet-ml, has garnered over 14,000 stars on GitHub, highlighting its popularity among developers.
Opik excels in evaluating Retrieval-Augmented Generation (RAG) systems, offering specialized metrics for detecting hallucinations, assessing answer relevance, and measuring context precision and recall. The platform automatically traces the entire LLM pipeline, making it easier for developers to debug components in complex RAG or multi-agent setups. It also integrates with the Ragas framework. Recently, Opik expanded its library to include 37 new metrics, such as BERTScore and sentiment analysis.
While automated metrics are a key strength, Opik also prioritizes expert input. Its Annotation Queues enable manual review and scoring of traces by experts. The Multi-Value Feedback Scores feature allows team members to independently score the same trace, minimizing bias and enhancing evaluation accuracy. These manual scores are combined with automated metrics to create a continuous feedback loop for refining model performance.
Opik’s Online Evaluation Rules offer configurable sampling options (10%-100%) and include features like PII redaction. Real-time alerts via Slack and PagerDuty notify teams of cost overruns, latency issues, or errors. As an open-source platform, Opik provides a generous free tier without requiring a credit card. For enterprises, it offers additional scalability and compliance features tailored to industry needs.
LangSmith seamlessly integrates with the LangChain ecosystem while remaining flexible enough to work with other frameworks. It captures nested traces across complex workflows, allowing developers to identify and fix issues in areas like retrieval, tool calls, or generation.
LangSmith's Prompt Playground enables developers to test multiple LLMs, such as OpenAI and Anthropic, side by side. This feature makes it easier to weigh factors like quality, cost, and latency. With its Experiment Benchmarking tool, users can run different models or prompt versions against the same curated dataset, offering a clear comparison of results. The platform also supports pairwise comparison evaluators, where either an LLM-as-a-judge or a human reviewer scores outputs from two models in a head-to-head evaluation. Additionally, the openevals package allows teams to design model-agnostic evaluators using various models to assess application performance, ensuring flexibility when working with different providers.
LangSmith goes beyond simple model comparisons, offering advanced tools for evaluating RAG systems.
LangSmith provides detailed insights into RAG systems by tracking every step of the retrieval process. Teams can measure retrieval relevance (whether the correct documents were identified) and answer accuracy (how complete and correct the responses are). By using a trace-based approach, LangSmith pinpoints exactly where a workflow breaks down, removing the guesswork from debugging complex retrieval pipelines.
In addition to its detailed evaluations, the platform offers robust production monitoring to ensure smooth operations.
LangSmith's Annotation Queues enable structured workflows where subject-matter experts can review, score, and annotate application responses. As LangChain highlights:
"Human feedback often provides the most valuable assessment, particularly for subjective quality dimensions".
When automated evaluators or user feedback flag production traces, these are routed to experts for review. The annotated traces are then transformed into "gold standard" datasets for future testing, enhancing the system's capabilities over time.
LangSmith monitors key metrics like request-level latency, token usage, and cost attribution in real time. Its Online Evaluators allow teams to sample specific portions of traffic, such as 10%, to balance visibility with cost, supporting up to 500 threads evaluated simultaneously within a five-minute window. This real-time tracking ensures production issues are addressed quickly and efficiently.
The platform meets enterprise-grade security standards, maintaining HIPAA, SOC 2 Type 2, and GDPR compliance. Automated checks, including safety filters, format validation, and quality heuristics, add an extra layer of protection. Basic alerts for errors and latency spikes help teams respond promptly to incidents. LangSmith uses a per-trace pricing model, with a free tier available, though costs can rise significantly for high production volumes.

Ragas, established in 2023, focuses on evaluating RAG (Retrieval-Augmented Generation) pipelines. Born out of research on referenceless evaluation methods published earlier that year, it separates the performance analysis of retriever and generator components. This distinction helps teams identify whether issues arise from flawed data retrieval or hallucinations in the language model, aligning with the broader theme of specialized tools for evaluation.
Ragas offers targeted metrics for both retrieval and generation processes. For retrieval, it measures:
On the generation side, it evaluates:
This granular approach simplifies debugging for complex RAG workflows. For instance, in an August 2025 benchmark, a model's accuracy jumped from 50% to 90% after addressing issues like missed rule stacking and boundary conditions.
Using an "LLM-as-a-judge" methodology, Ragas generates quantitative scores, minimizing the need for manual ground-truth labels. It also supports synthetic test data generation, with recommendations to start with 20–30 samples and scale up to 50–100 for more dependable results.
Ragas integrates seamlessly with various LLM providers, including OpenAI, Anthropic (Claude), Google (Gemini), and local models via Ollama. It ensures reproducibility by allowing teams to lock specific model versions (e.g., "gpt-4o-2024-08-06") during benchmarking, even as providers update their models. Additionally, the tool is highly extensible, enabling custom metrics through decorators like @discrete_metric, which can be used for tasks such as JSON validation.
Although Ragas emphasizes automated metrics, it incorporates human oversight for added reliability. The framework includes a user interface for metric annotation, allowing users to add grading_notes to test datasets and define human-specific evaluation criteria. Each evaluation also includes a score_reason field for transparency and auditability. As the Ragas documentation puts it:
"Ragas is a library that helps you move from 'vibe checks' to systematic evaluation loops for your AI applications".
This combination of automated scoring and human input ensures rigorous performance monitoring, even in dynamic environments.
Ragas extends its capabilities to production monitoring by integrating with observability platforms like Langfuse and Arize. This allows real-time scoring of production traces. Its reference-free metrics, such as Faithfulness for detecting hallucinations, are particularly useful in live settings where ground-truth answers aren't always available. The framework also supports integration into CI/CD pipelines, enabling continuous evaluation to ensure updates meet performance and safety standards. Teams can choose to score every trace or use periodic batch sampling to balance costs while maintaining insight into model behavior.
Braintrust blends evaluation and production monitoring directly into standard engineering workflows, ensuring a smooth and efficient process.
Braintrust's web-based Playground empowers teams to compare models side-by-side, making data-driven decisions easier. With the Playground, users can fine-tune prompts, switch between models, and conduct evaluations seamlessly. Side-by-side comparisons highlight model performance on identical prompts, offering clear insights. Integrated with GitHub Actions, the platform runs evaluations automatically with every commit, comparing results to baselines and preventing merges if quality declines. Braintrust includes over 25 built-in scorers to measure key metrics like factuality, relevance, and safety, while also allowing for custom scorers - whether through code or by leveraging an LLM-as-a-judge. Alongside automated metrics, the platform emphasizes the importance of expert reviews.
To incorporate human expertise, Braintrust features its "Annotate" workflow. This enables teams to set up review processes, apply labels, and refine model outputs. Its no-code interface allows product managers and domain experts to prototype prompts and review results with ease. By combining automated scoring with human feedback, the platform captures subtleties that algorithms might overlook. Additionally, the "Loop" AI agent identifies failure patterns and surfaces insights from production logs. This integration of human input reflects the principles of modern evaluation-driven development. Lee Weisberger from Airtable shared:
"Every new AI project starts with evals in Braintrust - it's a game changer."
Braintrust extends its capabilities to live production environments, continuously evaluating traffic using the same quality metrics applied during development. It tracks token usage in detail - by user, feature, and conversation - to detect costly patterns early, helping teams manage budgets effectively. The platform also delivers exceptional performance, offering 23.9x faster full-text search (401 ms vs. 9,587 ms) and 2.55x faster write latency. Sarah Sachs, Engineering Lead at Notion, remarked:
"Brainstore has completely changed how our team interacts with logs. We've been able to discover insights by running searches in seconds that would previously take hours."
For organizations with strict data sovereignty needs, Braintrust provides self-hosting options and is SOC 2 Type II certified, ensuring compliance and security.
Note: Humanloop's standalone features reflect the platform's capabilities before its acquisition by Anthropic in late 2024. These earlier functionalities have shaped the integrated evaluation approaches seen today, highlighting the progression of evaluation-driven development practices.
Humanloop bridged the gap between engineers and non-technical collaborators, offering a shared workspace where product managers, legal teams, and subject matter experts could actively engage in prompt engineering and evaluation - without the need for cumbersome spreadsheets. Below is a closer look at how Humanloop streamlined evaluation workflows.
Humanloop allowed teams to compare various base models side-by-side using a single dataset. This included models from OpenAI (GPT-4o, GPT-4o-mini), Anthropic's Claude 3.5 Sonnet, Google, and open-source options like Mistral. Spider plots provided a clear visualization of trade-offs between factors like cost, latency, and user satisfaction. For instance, one evaluation documented GPT-4o delivering higher user satisfaction but at a higher cost and slower speed. Additionally, the platform's log caching feature enabled teams to reuse logs for specific datasets and prompts, cutting down both time and expenses during evaluations. This feature tackled the challenges posed by the variable performance of large language models, a common issue in modern evaluation frameworks.
For retrieval-augmented generation (RAG) use cases, Humanloop offered pre-built templates. These templates included AI-as-a-judge evaluators designed to verify factual accuracy and ensure context relevance.
The platform's interface empowered experts to review logs, provide binary, categorical, or textual feedback, and add grading notes to refine evaluation criteria. Teams reported saving 6–8 engineering hours each week thanks to these streamlined workflows. Humanloop supported both offline testing for benchmarking new versions and online monitoring for reviewing live production data.
Humanloop also excelled in production monitoring, integrating evaluations into CI/CD pipelines to catch regressions before deployment. Automated online evaluators monitored live production logs, tracking performance trends and triggering alerts for any performance dips. Daniele Alfarone, Sr. Director of Engineering at Dixa, emphasized the platform's importance:
"We don't make any new LLM deployment decisions before evaluating new models via Humanloop first. The team has evaluation performance metrics that give them confidence."
The platform also supported enterprise-grade security with version control, SOC-2 compliance, and self-hosting options.
Created by the UK AI Security Institute, Inspect AI takes a research-driven approach to evaluating large language models (LLMs), emphasizing safety and security. Its open-source MIT license ensures accessibility for teams dedicated to thorough development testing. The framework includes over 100 pre-built evaluations, covering areas like coding, reasoning, agentic tasks, and multimodal understanding.
With the eval-set command, Inspect AI allows users to run a single evaluation task across multiple models simultaneously, leveraging parallel execution to save time on benchmarking. It supports a range of providers, including OpenAI, Anthropic, Google, Mistral, Hugging Face, and local models via vLLM or Ollama. By appending the provider name to the model ID, users can compare performance, speed, and cost across different inference providers. Automated selection policies, such as :fastest or :cheapest, further streamline evaluations by routing tasks to the most efficient provider based on throughput and cost. For instance, in one benchmark, the gpt-oss-120b model demonstrated varying accuracy, with Hyperbolic scoring 0.84, while Groq and Sambanova both scored 0.80. This multi-model comparison capability is bolstered by human oversight to ensure accurate performance validation.
In addition to automated benchmarks, Inspect AI integrates human evaluation to establish performance baselines against human capabilities on computational tasks. Its Agent solver facilitates this process, while the Tool Approval feature allows humans to review and approve tool calls made by models during evaluations. For real-time insights, the Inspect View web tool and VS Code Extension provide visualization of evaluation trajectories, enabling manual error analysis and debugging. The UK AI Security Institute highlights the framework’s adaptability:
"Inspect can be used for a broad range of evaluations that measure coding, agentic tasks, reasoning, knowledge, behavior, and multi-modal understanding".
Though primarily designed for testing and development, Inspect AI also excels in safety and compliance. Its sandboxing system - compatible with Docker, Kubernetes, Modal, and Proxmox - allows untrusted model-generated code to run in isolated environments. At the same time, it requires human authorization for critical tool calls, an essential feature for assessing agentic workflows in high-stakes scenarios. These measures reflect the platform’s strong focus on secure and reliable testing, aligning with industry best practices for AI safety and security.
Choose the best LLM evaluation tool by assessing essential features like multi-model compatibility, RAG evaluation, human-in-the-loop workflows, and production monitoring.
Below is a breakdown of these capabilities across various platforms:
| Tool | Multi-Model Support | RAG Evaluation | Human-in-the-Loop | Production Monitoring |
|---|---|---|---|---|
| Prompts.ai LLM Evaluation Suite | Yes (35+ models, including GPT-5, Claude, LLaMA, Gemini) | Yes (Trace-based analysis) | Yes (Annotation workflows) | Yes (Real-time FinOps tracking) |
| Deepchecks | Yes | Yes | Yes | Yes |
| Comet Opik | Yes | Yes | Yes | Yes |
| LangSmith | Yes (Offline experiments) | Yes (Trace-based) | Yes (Annotation queues) | Yes (Online evaluation) |
| Ragas | Yes | Yes (Targeted RAG metrics) | Yes | Yes |
| Braintrust | Yes | Yes | Yes | Yes |
| Humanloop | Yes | Yes | Yes | Yes |
| Inspect AI | Yes (via eval-set) | Yes | Yes (Individual trace debugging) | Limited |
While most tools support all four capabilities, their implementation methods differ. For example, Inspect AI focuses on manual review with individual trace debugging, making it more suitable for development testing but offering limited production monitoring.
Choosing the right LLM evaluation tool in 2026 isn’t about chasing the most feature-heavy option - it’s about aligning the tool’s capabilities with your unique workflow. Whether your focus is on CI/CD pipelines with native Pytest integration, production systems requiring real-time monitoring, or RAG applications that need trace-based analysis, the ideal tool should integrate smoothly with your existing infrastructure. This emphasis on tailored functionality underscores the growing importance of metric-based evaluation.
The industry’s shift from subjective assessments to data-driven metrics is no longer optional - it’s essential for production environments. OpenAI highlights this point:
"If you are building with LLMs, creating high quality evals is one of the most impactful things you can do".
This approach ensures that automated scoring becomes both scalable and dependable when combined with expert oversight.
Interoperability and compliance have also become non-negotiable. Tools that support multiple inference backends allow for performance testing across diverse hardware setups, while built-in safety benchmarks and moderation frameworks help teams meet 2026 regulatory requirements. These safeguards are critical for addressing issues like bias, toxicity, and privacy concerns. By adopting a continuous evaluation strategy, organizations can shift from isolated testing to a more dynamic process of ongoing model improvement.
As discussed, writing scoped tests at every stage - rather than waiting until after deployment - drives better results. Teams that log development data can identify edge cases, use pairwise comparisons for more consistent LLM-as-a-judge scoring, and build feedback loops that turn failing traces into valuable test datasets. This "data flywheel" transforms evaluation from a one-off task into a continuous cycle of improvement.
RAG (Retrieval-Augmented Generation) evaluation plays a crucial role in understanding the two-step process behind many large language model (LLM) applications. This process involves retrieving relevant information from an external knowledge base and then generating responses based on that context. By assessing the retriever and generator independently, RAG evaluation makes it easier to pinpoint problems, whether it's irrelevant information being retrieved or inaccuracies in the generated output. This approach simplifies both debugging and fine-tuning.
Metrics such as relevancy, faithfulness, precision, and recall are key to ensuring the retrieved data supports the final response and that the model accurately represents the information. This level of evaluation is especially important for tasks that demand current or specialized knowledge, such as legal research, customer service, or scientific analysis.
Ultimately, RAG evaluation provides a detailed understanding of how well an LLM performs, ensuring workflows produce accurate and dependable results - an essential factor for successfully deploying AI in practical, high-stakes scenarios.
Human-in-the-loop (HITL) workflows bring a valuable balance to evaluating large language models (LLMs) by blending automated tools with expert human insights. While automated metrics are great for quickly spotting obvious errors, they often fall short when it comes to assessing more nuanced aspects, such as factual accuracy, safety concerns, or how well a model performs in specific domains. Human reviewers step in to address these gaps, offering detailed, high-quality evaluations that help establish more reliable benchmarks and refine the criteria used for assessment.
These workflows are commonly embedded into testing and development processes, enabling teams to test LLMs on carefully selected datasets and uncover potential issues before deployment. This combination of automation and expert input not only speeds up the process of improving models but also ensures that evaluations reflect practical, real-world scenarios. In high-stakes areas like healthcare, expert involvement is especially crucial to guarantee that models meet stringent standards for accuracy, safety, and ethical responsibility.
Multi-model support plays a key role in empowering practitioners to assess and compare various large language models (LLMs) from different providers or architectures within a single, unified framework. This setup ensures consistent testing conditions and reproducible benchmarking, offering users a clear understanding of how different models perform when evaluated under identical circumstances.
By facilitating side-by-side comparisons, multi-model support offers deeper insights into each model's strengths, limitations, and suitability for specific tasks. This approach equips machine learning professionals with the information they need to make smarter decisions and streamline their AI workflows efficiently.


















