Pay As You Go - AI Model Orchestration and Workflows Platform


Selecting the right large language model (LLM) can feel overwhelming with so many options and varying costs. Tools like Prompts.ai, LLM Benchmark Suite, and EvalFlow simplify this process by offering features such as real-time cost tracking, robust security, and detailed performance benchmarks. Here's what you need to know:
These tools streamline LLM evaluation, helping you save time, cut costs, and ensure secure implementation. Below is a quick comparison of their key features.
| Tool | Integration | Performance Focus | Cost Management | Governance & Security |
|---|---|---|---|---|
| Prompts.ai | Unified API for 35+ LLMs | Real-time model comparisons | Pay-as-you-go TOKN credits | SOC2 Type 2, HIPAA compliance |
| LLM Benchmark Suite | Multi-scenario evaluation via HELM | Accuracy, safety, efficiency | Varies by implementation | Advanced red-teaming tools |
| EvalFlow | Developer SDKs (Python, TypeScript) | Automated scoring (LLM-as-a-judge) | Minimal overhead | Compliance audit trails |
Each tool is tailored to specific needs, from centralized management to developer-friendly integration or research-grade evaluations.

LLM Comparison Tools Feature Matrix: Prompts.ai vs LLM Benchmark Suite vs EvalFlow
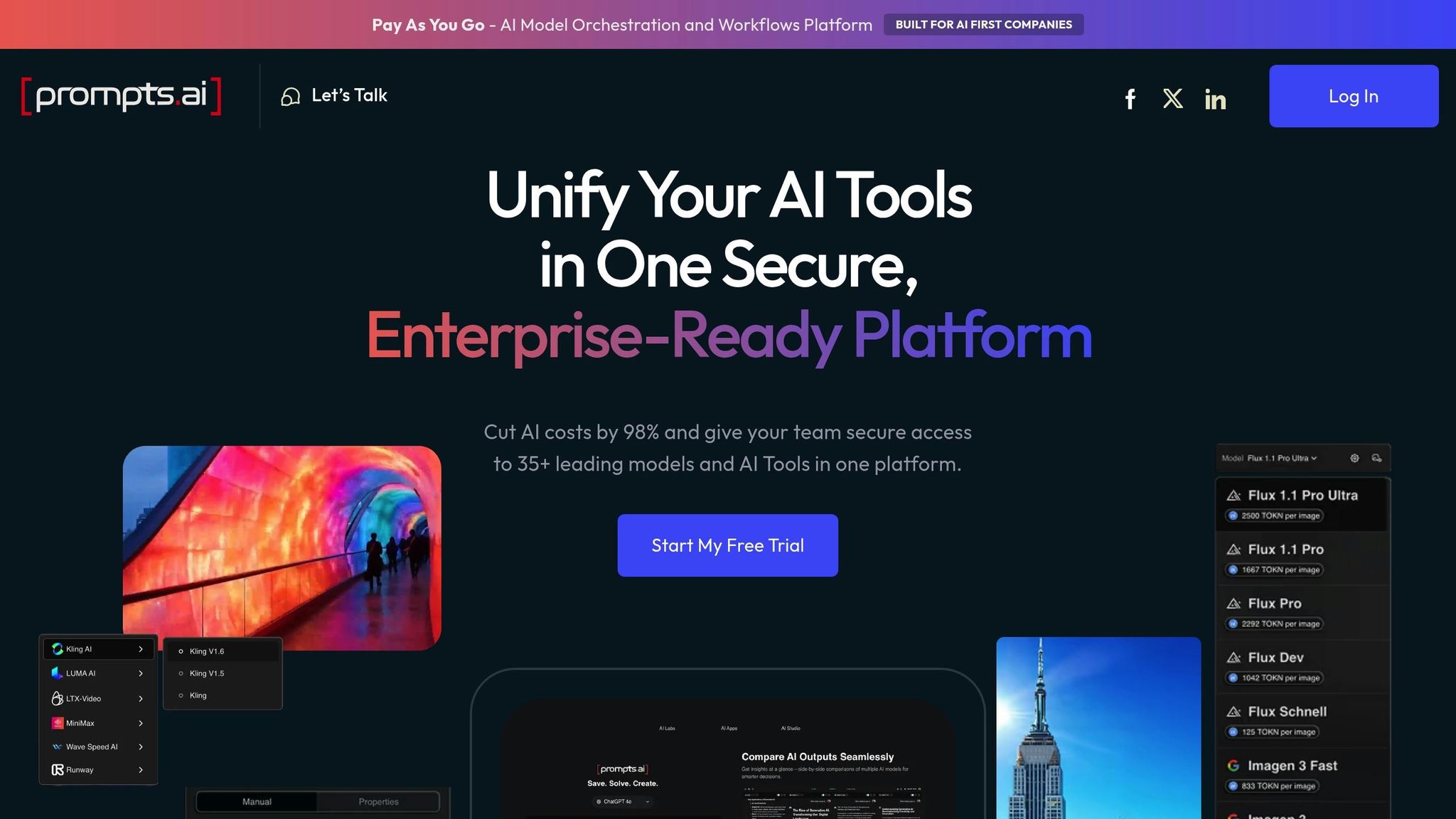
Prompts.ai simplifies access to over 35 leading LLMs, such as GPT-5, Claude, LLaMA, and Gemini, through a single, unified platform. By consolidating these models, it eliminates the hassle of managing multiple API keys and billing accounts. Acting as a proxy layer, the platform connects users to endpoints like OpenAI, Anthropic, and Anyscale, reflecting how modern LLM tools operate in 2026. The following sections highlight its standout features in model integration, cost management, and security.
Prompts.ai seamlessly integrates with popular orchestration frameworks, including LangChain, LlamaIndex, and OpenAI agents. This architecture allows organizations to incorporate the platform into their existing AI workflows effortlessly. Switching between models or testing new ones takes mere minutes, making it easy to stay ahead in a fast-changing AI landscape.
With Prompts.ai, users gain real-time visibility into token usage across all models and teams. This live tracking enables immediate adjustments, preventing unexpected bills at the end of the month. Costs are tied directly to specific projects, prompts, and team members, offering unmatched clarity. The platform operates on a pay-as-you-go TOKN credit system with no subscription fees, ensuring users only pay for what they use - no wasted capacity.
The platform includes robust security measures, automatically detecting prompt injections and jailbreak attempts while flagging rule violations or potential data breaches. Sensitive data, such as personally identifiable information, is automatically redacted before being logged or stored. Additionally, every interaction is tied to specific versions of prompts, models, and datasets, creating a detailed audit trail for compliance reviews. These features ensure a secure and trustworthy environment for daily operations.
The LLM Benchmark Suite offers a thorough assessment of language models through standardized testing protocols. A standout example is Stanford's HELM framework, which evaluates models across 200+ scenarios and considers seven key dimensions: accuracy, calibration, robustness, fairness, bias, toxicity, and efficiency. By looking beyond just accuracy, this multi-faceted approach delivers a well-rounded understanding of model performance. These evaluations lay the groundwork for the detailed performance and security insights discussed below.
The suite relies on well-established benchmarks, including MMLU (Massive Multitask Language Understanding), GSM8K for mathematical reasoning, HumanEval for coding tasks, and BIG-bench Hard. Tools like Lighteval further extend its capabilities, supporting over 1,000 evaluation tasks across various domains. Notably, HELM has significantly expanded its scenario coverage, growing from 18% to an impressive 96%. It also goes beyond traditional accuracy measures by incorporating metrics like inference time and computational resource usage, offering a more comprehensive performance analysis.
"HELM was created to address the fragmented and inconsistent evaluation practices prevalent in LLM research, enabling standardized, transparent, and reproducible comparisons." – Stanford CRFM
Security and governance are equally vital in these evaluations. The AIR-Bench leaderboard, for instance, assesses models against emerging regulations and corporate policies. Advanced tools like WildTeaming provide automated red-teaming capabilities to uncover vulnerabilities, while WildGuard evaluates real-time safety. Privacy is another critical focus, with the ConfAIde benchmark specifically designed to test how well models handle sensitive personal information.
These tools not only highlight performance but also ensure secure implementation in practical applications. Organizations can create private evaluation registries using platforms like OpenAI Evals, enabling them to test proprietary data securely and without public exposure. Additionally, leveraging the Batch API can reduce evaluation costs by up to 50% compared to real-time inference methods.
EvalFlow takes a developer-first approach to evaluating large language models (LLMs), seamlessly integrating into modern AI workflows instead of functioning as a separate tool. In today’s landscape, evaluation platforms treat datasets, prompts, and policies as versioned assets within LLMOps. This integration helps teams uphold consistent quality standards as models transition from development to production. EvalFlow complements the leading tools discussed earlier, further refining LLMOps processes.
EvalFlow can be integrated using standard SDKs in Python and TypeScript. This setup offers developers detailed tracking and control over model behavior at every stage of deployment. By embedding evaluation directly into the development pipeline, EvalFlow eliminates the need for manual checkpoints, making the process more efficient and reliable.
With its LLM-as-a-judge framework, EvalFlow automates scoring and tracks experiments systematically. This enables teams to compare models effectively and detect performance issues early, ensuring that models meet expectations before deployment.
EvalFlow’s automated evaluation process includes enterprise-grade governance features. These controls allow organizations to maintain audit trails and compliance records throughout the evaluation lifecycle. This is especially crucial when working with sensitive data or adhering to regulatory standards, providing an added layer of security and accountability.
This section highlights the advantages and limitations of each tool, helping you determine which best fits your AI workflow needs.
Each tool offers its own strengths and trade-offs, depending on what your priorities are.
Prompts.ai stands out for its ability to centralize model management, bringing together over 35 leading LLMs into a single, unified interface. It enables direct model comparisons, real-time FinOps cost tracking, and enterprise-grade governance, all in one place. Its pay-as-you-go TOKN credit system can reduce AI software costs by as much as 98%, while maintaining compliance with SOC2 Type 2 and HIPAA standards. However, organizations heavily invested in specific frameworks may encounter some initial challenges when transitioning their existing workflows.
On the other hand, LLM Benchmark Suite platforms, like HELM, shine in their ability to evaluate models across multiple dimensions, including accuracy, safety, and efficiency. Stanford's CRFM describes it as a "true LLM evaluation framework" that spans various domains, such as legal, medical, and technical areas. That said, the non-deterministic nature of probabilistic outputs can make consistency measurements tricky, and many evaluation tasks lack definitive answers - particularly for open-ended tasks like summarization.
Similarly, EvalFlow is particularly well-suited for developer-focused environments. It integrates seamlessly into CI/CD pipelines without requiring cloud setups or SDK dependencies. Its LLM-as-a-judge framework automates scoring in a systematic way. However, it provides less visibility at the production level. Greg Brockman, President of OpenAI, emphasizes its importance:
"If you are building with LLMs, creating high quality evals is one of the most impactful things you can do".
Below is a table comparing these tools based on integration, performance, cost, and governance:
| Tool | Model Integration | Performance Benchmarking | Cost Optimization | Governance & Security |
|---|---|---|---|---|
| Prompts.ai | Unified API for over 35 LLMs; framework-agnostic | Direct model comparisons with real-time metrics | Real-time FinOps tracking; pay-as-you-go TOKN credits | SOC2 Type 2, HIPAA with BAAs; full audit trails |
| LLM Benchmark Suite | Multi-model evaluation via AI Gateways | Holistic scoring across accuracy, safety, and efficiency | Varies by implementation; OpenAI Evals is free (API costs apply) | Depends on deployment; Snowflake integration available |
| EvalFlow | Python/TypeScript SDKs; CI/CD native | Automated LLM-as-a-judge scoring | Minimal overhead; no cloud dependencies | Enterprise governance with compliance audit trails |
These comparisons highlight the trade-offs to consider when incorporating these tools into your workflows.
Ecosystem lock-in is a potential concern - selecting a platform may limit flexibility for teams working across multi-model or multi-cloud environments. Additionally, while deeply integrated tools can offer robust observability, they often require a significant engineering investment.
Selecting the best LLM comparison tool hinges on your specific goals. Prompts.ai stands out by streamlining model management, cost tracking, and governance across more than 35 LLMs. With its pay-as-you-go TOKN credit system and strict compliance standards, it’s an excellent fit for teams aiming to reduce tool sprawl while meeting stringent security requirements.
For research teams conducting in-depth model assessments, platforms like HELM shine with their multi-dimensional evaluation capabilities, analyzing metrics such as accuracy, safety, and efficiency.
The industry is also shifting toward behavior-based evaluation methods, changing how teams assess LLM performance. As Anthropic highlights:
"Evaluating how a model behaves, not just what it says, could become a crucial dimension of trust and safety in next-generation AI systems".
This approach emphasizes monitoring multi-step reasoning and tool usage, moving beyond static outputs. Such advancements underscore the importance of aligning tool features with your workflow priorities.
Each tool has its own strengths tailored to specific operational needs. Prompts.ai excels in centralized management with integrated FinOps and compliance features. HELM offers detailed benchmarking for research-focused environments, while EvalFlow caters to developers with seamless CI/CD pipeline integration. For teams working on agentic workflows, tools that support multi-turn evaluations and robust monitoring are essential. By matching tool capabilities - whether for cost management, regulatory compliance, development efficiency, or production monitoring - to your priorities, you can confidently choose the solution that best fits your needs.
Prompts.ai offers a cloud-based platform designed to simplify and enhance your work with large language models (LLMs). With access to over 35 models, you can test and compare them side-by-side - no coding required. Run the same prompt across multiple models, get instant results, and review key metrics like accuracy, latency, and token usage, all from one intuitive dashboard. Plus, with real-time cost tracking in USD and token-level pricing, it’s easy to spot costly requests and manage your budget effectively.
Beyond just comparisons, Prompts.ai optimizes LLM workflows by consolidating API access, cutting down on redundant calls, and centralizing security measures. This not only boosts efficiency and reduces expenses but also lowers the risk of data breaches. The platform is built for teamwork, allowing users to share results and collaborate effortlessly. Whether you’re a non-technical user exploring LLMs or part of an enterprise juggling multiple models, Prompts.ai provides the tools and insights to make your work smoother and more impactful.
The LLM Benchmark Suite offers a comprehensive way to evaluate models by testing them in over 200 scenarios. These tests span key areas such as accuracy, robustness, efficiency, and ethical considerations, giving a clear picture of each model's strengths and where it could improve.
With standardized datasets and a unified API, the suite ensures consistent and transparent comparisons between models. It also includes tools like a web interface and a leaderboard, allowing users to dive into detailed results. These features make it easier to assess technical performance and ethical aspects in practical applications.
The details about EvalFlow and its features are not included in the provided information. Without additional context or a description of its capabilities, it’s challenging to discuss how it might fit within developer-focused environments. If you can share more about EvalFlow, I’d be glad to offer a response tailored to its specific attributes.


















