Pay As You Go - AI Model Orchestration and Workflows Platform


AI workflow tools can transform how machine learning teams operate, cutting development time and simplifying complex processes. From managing infrastructure to automating repetitive tasks, these tools streamline the journey from experimentation to production. Here’s a quick look at six standout platforms:
Each tool caters to specific needs, from cost management to scalability and governance. Below, we dive into their features, strengths, and ideal use cases to help you choose the right solution for your team.

Comparison of 6 Top AI Workflow Tools for Machine Learning
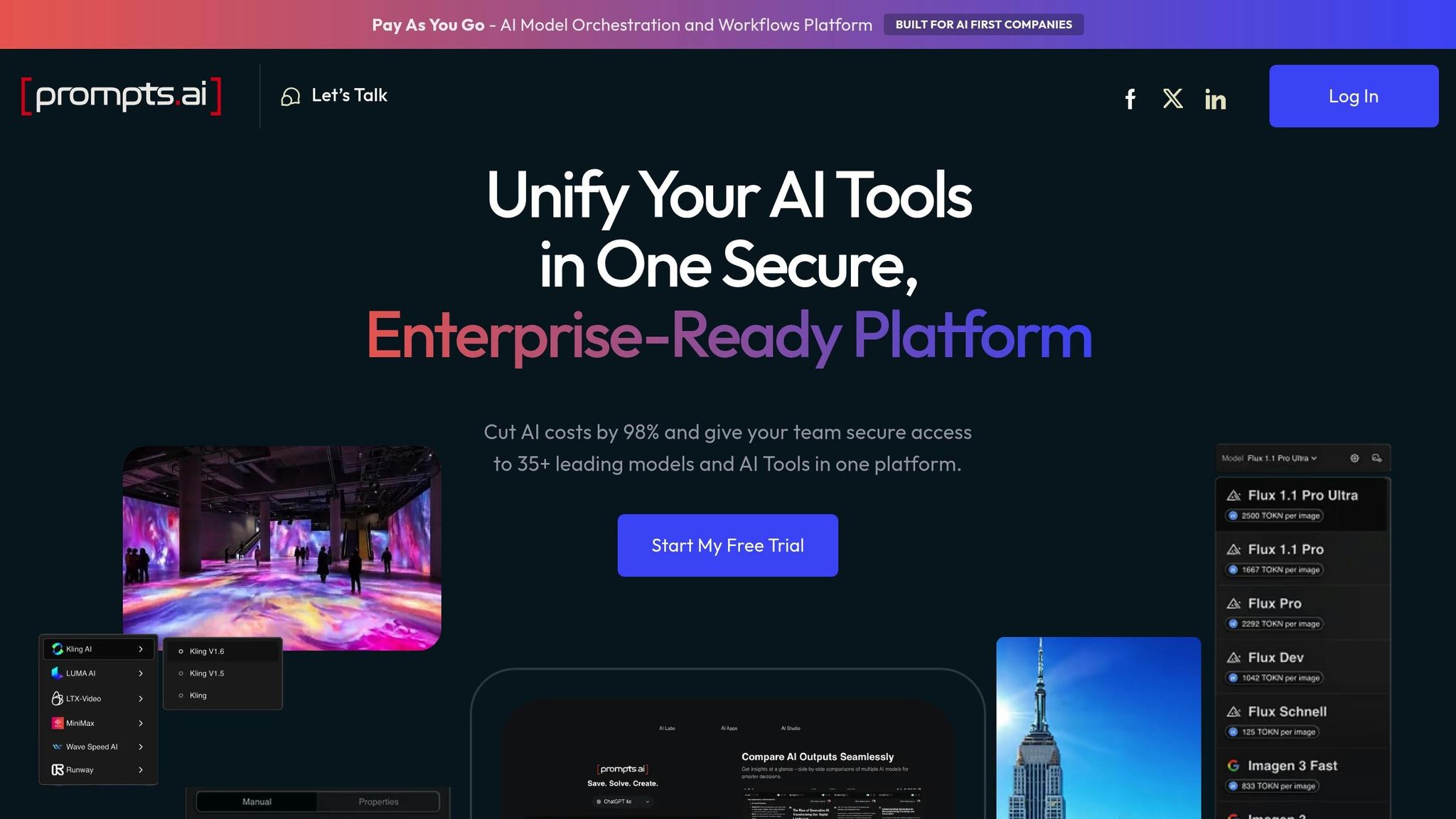
Prompts.ai is an enterprise-focused AI orchestration platform that brings together over 35 advanced large language models, including GPT-5, Claude, LLaMA, and Gemini, into a single, unified interface. For machine learning teams, this eliminates the hassle of managing multiple API keys, billing systems, and disconnected tools. Founded by Emmy Award-winning Creative Director Steven P. Simmons, Prompts.ai simplifies large-scale AI adoption by centralizing access, governance, and cost management.
Prompts.ai integrates effortlessly with major ML ecosystems, offering compatibility with OpenAI APIs, Zapier (connecting to more than 8,000 apps), and no-code platforms like n8n. These integrations allow users to easily incorporate prompt outputs into downstream workflows. For example, users can connect with ChatGPT Agent Builder for multi-step inference chains or integrate results directly into Metaflow for model training. In computer vision tasks, the platform enables users to label data efficiently - uploading images via Zapier from Google Drive, generating LLM-based annotations, and feeding them into training pipelines. This process reduces manual labeling time by 70%. These streamlined workflows not only save time but also allow for better cost management.
To address rising API costs, Prompts.ai includes a dedicated FinOps layer that monitors token usage in real time, optimizes spending, and attributes costs to specific workflows. Its prompt optimization tools help teams cut token usage in LLM experiments by up to 40%, delivering substantial savings when running thousands of inference calls. Pricing is based on a pay-as-you-go TOKN credit system, starting at $0 per month for exploration, with business plans ranging from $99 to $129 per member per month. By consolidating model access, Prompts.ai helps reduce AI software expenses by as much as 98% compared to maintaining separate subscriptions for various providers.
Built on a cloud-native architecture, Prompts.ai can handle thousands of simultaneous prompt evaluations with ease. It supports on-premises deployment and integrates with scalable backends like AWS and GCP for distributed processing. Teams can quickly expand by adding models, users, and workflows using pre-built templates. Benchmarks reveal that the platform enables five times faster prompt iterations compared to manual methods, allowing ML engineers to move from prototyping to production more efficiently. This speed advantage enhances the platform’s role in end-to-end ML workflows.
Prompts.ai provides robust governance tools, including role-based access control (RBAC), prompt versioning, and audit logs, ensuring reproducibility in regulated environments. Its centralized dashboard tracks every prompt change and includes tools for bias detection in ML outputs, which is essential for teams working under strict compliance requirements. With SOC 2 Type II-level security features, the platform ensures that organizations can enforce security policies, maintain visibility into AI interactions, and track who accessed specific models, when, and for what purpose.
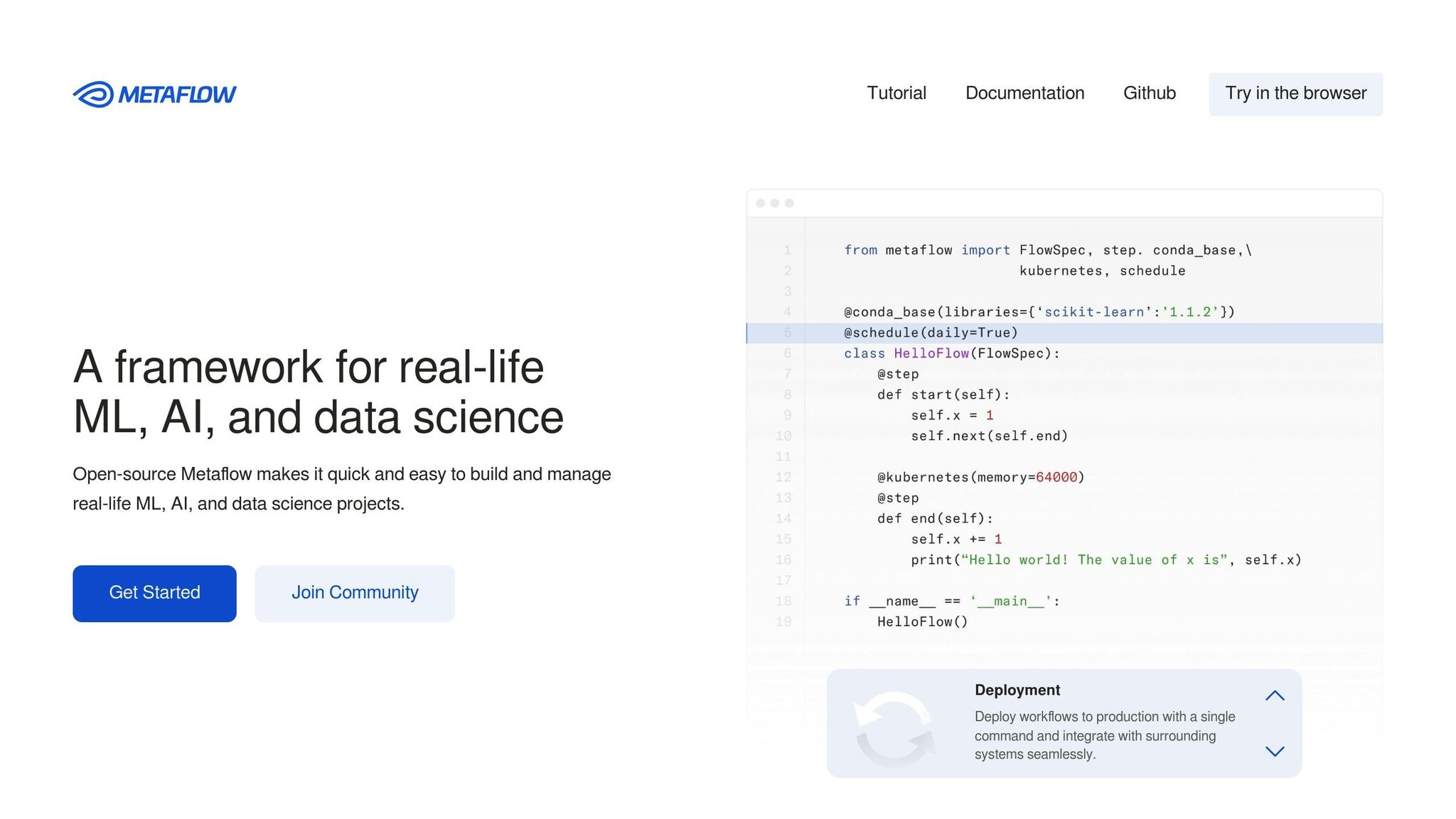
Metaflow is an open-source framework initially developed by Netflix to manage complex machine learning and data science projects. Designed for seamless integration with existing infrastructure, it offers a unified API that spans your entire workflow - from local development to production deployments on AWS, Azure, or Google Cloud. With its "Bring your own Cloud" approach, Metaflow supports AWS services like EKS, S3, Batch, and Step Functions, as well as similar tools on Azure and GCP. This flexibility makes it a strong choice for handling interoperability, scalability, cost management, and governance.
Metaflow works well with various workflow orchestrators, including Argo Workflows, AWS Step Functions, Apache Airflow, and Kubeflow. You can build and debug workflows locally, then deploy them to production with a single command - no code changes needed. The framework automatically saves "artifacts" that remain accessible across environments, whether you're working locally or in the cloud. For model deployment, it integrates with platforms like Seldon and AWS SageMaker. Setting up the required infrastructure stack using Terraform or CloudFormation templates typically takes just 15 to 30 minutes.
Metaflow is built to handle large-scale production environments effortlessly. It has supported use cases involving tens of thousands of workflows and millions of executions. You can scale vertically by assigning specific hardware resources (CPU, RAM, GPUs) with the @resources decorator or scale horizontally using foreach to run thousands of parallel tasks, such as processing data shards or tuning hyperparameters. The metaflow.S3 client is fine-tuned for high-speed downloads, achieving tens of gigabits per second, and can load data straight from S3 into memory, bypassing traditional SQL bottlenecks.
As open-source software under the Apache License, Version 2.0, Metaflow has no licensing fees. You only pay for the cloud resources you use, such as AWS EC2 or S3. AWS Batch, one of Metaflow’s compute options, charges only for the EC2 instance time consumed, down to the second, making it a cost-effective solution for scaling. For non-critical tasks, you can save further by using spot instances, with built-in features for retries and graceful cleanup in case of termination.
Metaflow ensures full reproducibility by automatically creating immutable snapshots of code, data, and dependencies for every execution step. It saves instance variables as versioned "artifacts" throughout the workflow lifecycle, ensuring a complete and permanent data record. The Metadata Service tracks all experiments and artifacts in a central database, fostering team collaboration. Developers can use the @project decorator to create isolated namespaces (e.g., user, test, prod) to avoid overwriting production deployments. Additionally, the resume command allows you to pick up failed production runs locally from the last successful step, simplifying debugging.
Argo Workflows is an open-source orchestration engine designed specifically for Kubernetes, making it a powerful tool for managing production ML pipelines. As a Cloud Native Computing Foundation (CNCF) graduated project, it has earned the trust of over 200 organizations and benefits from strong community support. Built as a Kubernetes Custom Resource Definition (CRD), Argo operates entirely within your cluster, eliminating the need for external runners while utilizing Kubernetes features like volumes, secrets, and RBAC.
Argo's flexibility allows it to run on any Kubernetes cluster, whether hosted on AWS, Azure, Google Cloud, or on-premises infrastructure. It serves as the backbone for major ML platforms like Kubeflow Pipelines, Netflix Metaflow, Kedro, and Seldon, making it an excellent fit for teams already using these tools. The platform supports multi-language SDKs - Python (Hera), Java, Golang, and TypeScript (Juno) - enabling data scientists to design workflows in their preferred languages while avoiding the complexity of YAML files. For artifact storage, Argo integrates seamlessly with S3, Google Cloud Storage, Azure Blob Storage, Artifactory, Alibaba Cloud OSS, and Git repositories, ensuring smooth operation across diverse storage solutions.
Argo is built to handle large-scale workloads, processing tens of thousands of workflows with thousands of steps each. A standout example is CoreWeave's deployment of Argo in January 2021 on a 1,000-node cluster with 6,000 GPUs to manage 3D rendering tasks. CERN also relies on Argo for orchestrating complex data processing in physics research, while Intuit uses it for AI pipelines at scale. Features like the Emissary executor (introduced in v3.1+) reduce Kubernetes API overhead, and tools such as parallelism limits, node selectors, and affinity rules provide precise control over resource allocation, especially for GPU-heavy tasks.
Argo’s cost-effective approach is another key advantage. Distributed under the Apache 2.0 license, it’s completely free to use, with expenses limited to the underlying Kubernetes resources. Its container-native architecture eliminates the overhead of virtual machines, and its automatic resource usage tracking per workflow step helps teams monitor and optimize costs. Additionally, built-in garbage collection for workflows and pods ensures that completed tasks are cleaned up automatically, preventing unnecessary storage expenses.
Argo also excels in governance, delivering reliability and security for production environments. It integrates seamlessly with Kubernetes RBAC and supports Single Sign-On (SSO) via OAuth2 and OIDC. A centralized UI offers real-time workflow visualization, log monitoring, and access to archived execution histories, which are essential for compliance and model lineage tracking. Prometheus metrics and step-level resource usage calculations provide full operational transparency. For enhanced security, teams can configure the Argo Server with --auth-mode=sso and assign specific ServiceAccounts to workflows, enforcing the principle of least privilege and reducing permission-related risks.
Kedro is an open-source Python framework, hosted by the Linux Foundation's LF AI & Data, that focuses on applying software engineering principles to ML projects. Unlike task-scheduling orchestrators, Kedro emphasizes building well-structured, maintainable pipelines during development. It tackles the challenge of turning experimental code into production-ready systems by using a standardized project template. This structure separates configuration, source code, tests, and documentation, making collaboration smoother and production transitions more efficient.
At the heart of Kedro's interoperability lies its Data Catalog, which provides lightweight connectors for a wide range of file systems, including S3, Google Cloud Platform, Azure, sFTP, and DBFS. The framework integrates seamlessly with data processing tools like Pandas, PySpark, and Dask, enabling teams to move fluidly between local CSV files and cloud-based datasets. While Kedro itself is not an orchestrator, it works with tools like Airflow, Argo, Prefect, and Kubeflow through plugins such as Kedro-Airflow. It also supports platforms like Amazon SageMaker, Azure ML, VertexAI, MLflow, Databricks, and Docker, ensuring compatibility across various ecosystems. These features make Kedro a versatile tool for building scalable workflows.
Kedro supports scalability through its integration with distributed frameworks like PySpark and Dask. For instance, Telkomsel, Indonesia's largest telecommunications provider, uses Kedro to process tens of terabytes of data and manage hundreds of feature engineering tasks. JungleScout, on the other hand, reported an 18× speed improvement in development thanks to Kedro's modular pipeline design, which automatically resolves dependencies between nodes without requiring manual setup. The framework also supports parallel execution through built-in runners, which can be activated with simple command-line switches. Additionally, Kedro is deployable across distributed environments such as AWS Batch, Amazon SageMaker, Azure ML, and Kubernetes-based platforms, making it a powerful option for handling large-scale projects.
Kedro ensures strong governance by maintaining data and model integrity through its Data Catalog, which acts as a centralized registry and single source of truth for data access within pipelines. The Kedro-Viz plugin enhances traceability by generating visual data lineage graphs, showing node statuses and execution times. This feature not only aids technical teams but also helps communicate workflows to non-technical stakeholders. Sensitive credentials are securely stored in conf/local/credentials.yml, which is excluded from version control via .gitignore. Additionally, Kedro supports data and model versioning, ensuring reproducibility. It incorporates robust software engineering practices such as test-driven development with pytest, code linting with ruff, and automated documentation generation through Sphinx.
"We use Kedro in our production environment which consumes tens of TBs of data, runs hundreds of feature engineering tasks, and serves dozens of ML models." - Ghifari Dwiki Ramadhan, Data Engineering, Telkomsel
Valohai provides a managed, configuration-driven platform that simplifies machine learning (ML) operations by removing the need for infrastructure management. By orchestrating ML workflows through configurations, it offers a ready-to-use system that handles versioning, orchestration, and deployment seamlessly across cloud or on-premises environments. Using a valohai.yaml configuration file, workflows are defined in a way that remains non-intrusive and avoids vendor lock-in.
Valohai integrates effortlessly with any Dockerized environment, allowing teams to use their preferred libraries - such as TensorFlow, PyTorch, or scikit-learn - without requiring modifications. It supports deployment on AWS, Azure, GCP, Oracle, Snowflake, Kubernetes, Slurm, and on-premises servers, offering flexibility for diverse workloads. Every feature available in the platform's UI can also be accessed via a REST API, while webhooks enable integration with external tools, CI/CD pipelines, or custom dashboards. The platform also supports data interoperability with major data platforms and annotation tools, ensuring smooth operations across the ML lifecycle.
Valohai optimizes resource usage by allowing teams to allocate hardware specific to each pipeline step - such as high-memory CPUs for preprocessing or multi-GPU setups for training. This precision ensures that expensive resources are only utilized when absolutely necessary. The platform can execute thousands of runs from a single step definition, making it ideal for large-scale hyperparameter tuning or parallel model benchmarking.
"Valohai allows us to scale up machine learning without worrying about managing infrastructure. The platform has drastically changed how we build our team because our expertise can be more focused on data science and less on cloud and DevOps." - Petr Jordan, CTO at Onc.ai
Additionally, Valohai includes automatic checkpointing between pipeline steps, enabling workflows to resume from the last successful step in the event of a failure - saving both time and effort during long-running processes.
Valohai ensures thorough versioning by linking every execution to a specific Git commit, Docker image, and dataset version.
"The version control of all parts of an experiment, from code to data to environment, allows for systematic research, which can be reviewed months later." - Andres Hernandez, Lead Data Scientist at KONUX
The platform introduces human-in-the-loop approval gates within automated pipelines, allowing compliance officers or subject matter experts to review results before they are deployed in production. Its Model Catalog consolidates model lineage and performance metrics, simplifying the comparison of model versions and ensuring regulatory compliance. For industries with strict regulations, Valohai supports hybrid deployments, enabling sensitive data to remain on-premises while managing workloads through a unified interface. These governance tools enhance operational efficiency while maintaining compliance.
Valohai minimizes resource waste by letting users specify compute requirements for each node, ensuring that GPU resources aren't unnecessarily consumed by CPU tasks. The platform also identifies and reuses completed steps if the code and inputs remain unchanged, reducing both time and compute costs. During development, the --adhoc flag allows teams to test local code changes on remote infrastructure without committing to Git, streamlining iterations while preserving reproducibility.
"Building a barebones infrastructure layer for our use case would have taken months... with Valohai, [features] come included", - Renaud Allioux, CTO at Preligens
Dagster takes a fresh approach to workflow orchestration by focusing on data assets - like models, tables, and datasets - rather than just tasks. This asset-based design naturally highlights how your ML pipelines are interconnected, making it easier to grasp dependencies, such as the relationship between a dbt transformation and a downstream PyTorch model. By clarifying these connections, Dagster simplifies ML operations, ensuring workflows are reproducible and dependencies are clear. It serves as a unified control plane, integrating effortlessly with tools in the modern data stack, including Snowflake, Spark, Databricks, and ML-specific platforms like MLflow and Weights & Biases.
Dagster acts as a central hub for your entire ML infrastructure. With Dagster Pipes, teams can run resource-intensive training tasks on external clusters like AWS EMR or GCP Dataproc while maintaining full observability and metadata tracking. By separating business logic from infrastructure, Dagster allows for seamless execution across both local and production environments. Its native integrations cover a wide array of platforms, from compute solutions like Ray, AWS Glue, and SLURM to AI frameworks such as OpenAI, Anthropic, and Google Gemini. It also supports storage tools like BigQuery, Delta Lake, and Pinecone. For teams relying on Jupyter notebooks, Dagster works with Papermill and Noteable to turn notebook code into reusable, observable assets. This flexible integration approach ensures scalable, high-performance workflows.
Dagster is built to handle growth with features like data partitioning and incremental runs, enabling efficient computation. Its execution model seamlessly scales from a single laptop to large production clusters, supporting parallel and distributed computing. For example, EvolutionIQ, a company specializing in AI-driven insurance insights, reduced client onboarding time from months to under a week after adopting Dagster. Debugging ML model updates also became significantly faster, dropping from hours to just minutes. The platform’s lightweight execution model allows teams to restart pipelines in the middle of a run, saving valuable time during tasks like hyperparameter tuning or feature engineering.
Dagster ensures every asset has a complete audit trail by automatically registering code, data, and source versions. It embeds data quality checks directly into pipelines, including automated testing, freshness validations, and custom rules that can run at any stage. With Software-Defined Assets, teams can track ML model lineage back to the original data sources, ensuring that changes in upstream data automatically trigger retraining workflows.
"The asset-based approach of orchestration significantly reduces debugging complexity by clearly aligning with data lineage." - Steven Ayers, Principal Engineer, Ayersio Services Limited
For organizations with strict compliance needs, Dagster+ offers enterprise-level security and regulatory features. Its integrated metadata UI provides visibility into evaluation metrics, training accuracy, and model performance over time. These capabilities, combined with its data-centric approach, also help optimize resource use.
Dagster includes tools to track resource usage and costs, helping teams manage infrastructure spending as workloads grow. The platform’s declarative automation - using triggers like eager or on_cron - ensures that ML models only retrain when upstream dependencies change, avoiding unnecessary computations. Features like partitions and partition sets enable batch processing, reducing redundant compute tasks and cutting development costs by allowing local testing before deploying to the cloud. Around half of Dagster’s users leverage the platform for machine learning workflows, benefiting from either the open-source version (Dagster OSS) for smaller teams or the managed Dagster+ offering for enterprise-scale needs.
Each machine learning (ML) workflow tool comes with its own set of strengths and challenges, making them suitable for different team sizes, budgets, and infrastructure needs. Here's a closer look at the standout features and limitations of some popular tools:
Prompts.ai stands out with its ability to orchestrate workflows across 35+ leading LLMs, offering centralized governance and cost tracking. This makes it an excellent choice for enterprises managing complex operations. However, its pricing structure may be less accessible for smaller teams or startups. Metaflow provides seamless versioning and tight integration with AWS, but its AWS-centric design can be a drawback for teams looking to implement multi-cloud strategies.
Argo is a great fit for Kubernetes environments, excelling in parallel job execution and cloud-agnostic setups. However, it can be difficult to implement for teams using legacy systems or non-containerized environments. Kedro offers Python-based reproducibility and a modular design that appeals to larger teams, but it struggles to support cutting-edge generative AI pipelines that rely heavily on LLM workflows. Valohai simplifies end-to-end pipeline automation with managed infrastructure, but its premium pricing and lack of a free tier can deter individual developers or small teams.
Finally, Dagster provides a unique asset-based approach to data orchestration, which ensures strong lineage tracking. However, its steep learning curve and need for specialized engineering talent can slow adoption. Additionally, high computational demands - requiring advanced GPUs, TPUs, and significant RAM - may strain organizations with limited resources.
| Tool | Strengths | Weaknesses |
|---|---|---|
| Prompts.ai | Unified multi-model orchestration, centralized cost tracking | Higher cost for smaller teams and startups |
| Metaflow | Automatic versioning, user-friendly design, AWS integration | Limited multi-cloud support; AWS-specific architecture |
| Argo | Kubernetes-native, excels in parallel job execution | Difficult to implement in legacy or non-containerized setups |
| Kedro | Python-based modularity, reproducibility, data abstraction | Lacks support for modern generative AI workflows |
| Valohai | Managed infrastructure, full pipeline automation | High cost; no free tier for small-scale users |
| Dagster | Asset-based orchestration, excellent lineage tracking | Steep learning curve; requires specialized expertise |
Choosing the right tool depends on aligning its capabilities with your operational needs. For instance, automation-focused platforms are ideal for repetitive tasks like model retraining, while flexible architectures may better support exploratory research. However, integration remains a challenge due to varying data-sharing protocols. Careful evaluation of these factors is crucial to ensure the tool enhances productivity without overwhelming your resources.
Selecting the right tool for your workflow needs is key to moving from experimental code to fully functioning production pipelines. As discussed earlier, Prompts.ai stands out by offering centralized orchestration for over 35 leading LLMs, complete with built-in cost tracking and compliance features - an excellent fit for Fortune 500 companies managing sensitive data. On the other hand, Metaflow integrates seamlessly with AWS services like S3, Batch, and Step Functions but is limited in multi-cloud functionality.
For Kubernetes-native environments, Argo shines with its parallel execution capabilities, while Kedro provides a modular Python framework that supports large teams focused on maintaining clean, manageable code. Valohai simplifies end-to-end pipeline automation with managed infrastructure but may stretch smaller budgets due to its premium pricing. Meanwhile, Dagster excels in asset-based orchestration and lineage tracking but requires specialized engineering skills and additional computational resources. Each of these tools offers distinct advantages tailored to different budgets and team sizes.
Open-source solutions like Metaflow, Argo, and Kedro help cut licensing costs, though cloud infrastructure expenses still apply. For smaller teams, focus on tools that save time on repetitive tasks - aiming to reclaim at least 30 minutes per week - rather than investing in feature-heavy platforms that may exceed your operational capacity. Success often hinges on starting with clear objectives and measurable goals.
Swiss Life Germany managed to slash deployment times from several weeks to just 20 minutes by automating data governance through strategic tool selection and infrastructure planning.
When choosing a solution, consider your team size, technical expertise, and the balance between automation needs and research flexibility. Early testing of integration capabilities is crucial, as poor integration remains a significant hurdle in AI adoption. By opting for tools that streamline machine learning workflows and boost efficiency, teams can dedicate their energy to improving models instead of wrestling with infrastructure complexities.
The best AI workflow tool will depend on what your team is looking for. prompts.ai provides access to over 35 language models, seamless interoperability, and cost-saving features, making it an excellent choice for simplifying machine learning workflows. Alternatives like Prefect offer a wide range of integrations, while tools such as Dagster and MLflow are designed to handle the entire machine learning lifecycle. What sets prompts.ai apart is its focus on scalability and efficiency, making it a great fit for AI-driven companies.
Before rolling out a machine learning workflow to production, it's crucial to evaluate several important aspects. Focus on dependency management, experiment tracking, automation, scalability, data flow management, and governance. Addressing these areas helps ensure the workflow operates smoothly, can be replicated, and meets all required standards.
To cut down on machine learning workflow expenses while maintaining a steady pace of iteration, prioritize refining your build and packaging processes to reduce unnecessary overhead and improve efficiency. Consider leveraging budget-friendly orchestration tools like prompts.ai, which provide features such as cost tracking and automation to simplify workflows and keep expenses under control.



















