Pay As You Go - AI Model Orchestration and Workflows Platform


Which AI model fits your business best? Here’s the short answer: it depends on your priorities - speed, cost, or capability. By December 2025, enterprises are leveraging multi-model strategies to balance performance and expenses. Tools like Prompts.ai simplify this process by integrating 35+ leading models into a single platform, allowing you to compare, manage, and optimize usage in real time.
| Model | Strength | Speed (tok/s) | Context Window | Input Cost (per 1M tokens) |
|---|---|---|---|---|
| GPT-5.2 | Reasoning, speed | 187 | 400K | $1.75 |
| Claude Opus 4.5 | Coding, long-context tasks | 49 | 200K–1M | $5.00 |
| Gemini 3 Pro | Multimodal processing | 95 | 1M–2M | $2.00 |
| LLaMA 4 Scout | Privacy, open-source | N/A | Up to 10M | Compute-only |
| DeepSeek V3.2 | Budget-friendly classification | 142 | 128K | $0.28 |
With Prompts.ai, you’re one step closer to smarter, scalable, and cost-effective AI workflows.
LLM Comparison Chart: Performance, Speed, Cost & Context Windows 2025
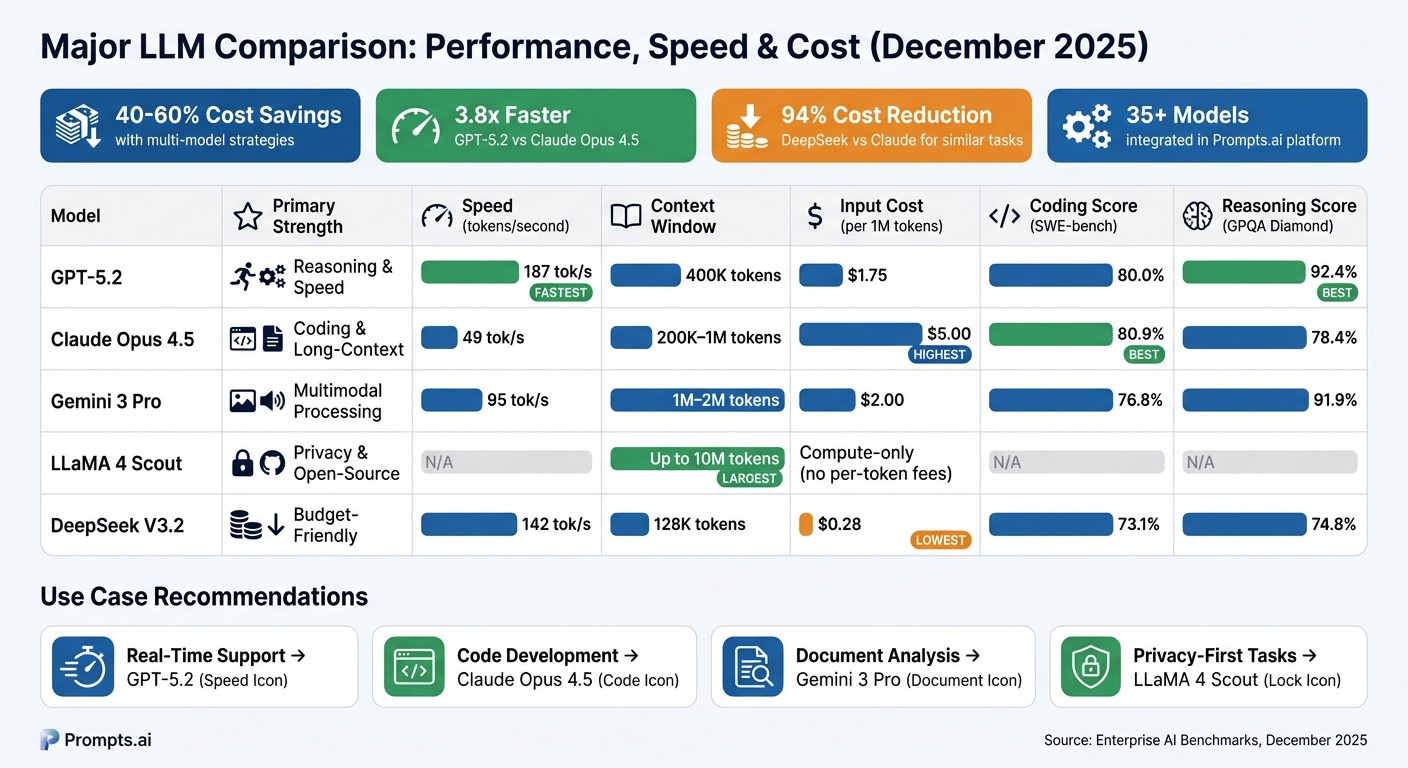
As of December 2025, the landscape for large language models (LLMs) has evolved into a competitive space led by four standout models, each excelling in specific enterprise applications. GPT-5.2 leads in speed, processing 187 tokens per second - 3.8 times faster than Claude - making it a top choice for real-time customer interactions and conversational agents. It also achieved an impressive 70.9% on GDPval, equaling human expert performance across 44 occupations for the first time. On the other hand, Claude Opus 4.5 has set the bar for coding capabilities, earning an 80.9% score on SWE-bench Verified. Gemini 3 Pro broke records with a 1,501 Elo score on the LMArena Leaderboard and stands out for its ability to process text, images, video, and audio within a single architecture. Finally, LLaMA 4 Scout offers unmatched context capabilities, with a window of up to 10 million tokens, enabling enterprises to handle vast codebases or document archives in a single pass.
The gap between open-source and proprietary models has nearly closed, shrinking from 17.5 to just 0.3 percentage points on the MMLU benchmark within a year. This change has major cost implications: while Claude Opus 4.5 costs $5.00 per million input tokens, DeepSeek V3.2 offers similar classification performance for just $0.28 - a 94% reduction. Prompts.ai integrates these models into a single platform, enabling teams to allocate tasks strategically - using budget-friendly options for simpler tasks and reserving premium models for complex reasoning. This approach typically saves enterprises 40% to 60% on AI expenses.
"The choice between ChatGPT, Claude, and Gemini in December 2025 reflects a matured market with clear specializations." - Aloa AI Comparison Report
These distinctions pave the way for a closer look at each model’s strengths and specialized applications.
GPT-5.2 is designed for tasks requiring both speed and accuracy, thanks to its dynamic reasoning capabilities that adapt to task complexity. Compared to GPT-4, it reduces factual errors by up to 80%, making it a reliable tool for customer-facing applications where precision is essential. With pricing at $1.75 per million input tokens and $14.00 for output tokens - plus a 90% discount on cached inputs - it offers cost efficiency for repetitive workflows like document summarization or FAQ automation. Through Prompts.ai's unified API, teams can easily integrate GPT-5.2 into their workflows, accessing its capabilities without the hassle of managing separate accounts or billing systems.
Claude Opus 4.5 shines in industries with strict regulatory requirements, such as healthcare, finance, and legal services, thanks to its embedded ethical guidelines. Beyond its coding expertise, it can autonomously execute tasks for over 30 hours, handling complex processes like building data pipelines or conducting compliance audits. Its context window spans 200,000 tokens in standard mode and up to 1 million tokens in beta, making it ideal for analyzing lengthy documents like contracts or research papers. With a zero-data-retention policy and a 90% discount on cached inputs, Claude is also cost-effective for workflows that prioritize privacy. Prompts.ai offers direct access to Claude's enterprise features, including real-time token monitoring and compliance tools aligned with GDPR and SOC 2 standards.
LLaMA 4's open-weight design allows enterprises to self-host the model, ensuring complete data privacy and eliminating per-token fees - costs are limited to compute resources. This makes it a strong choice for high-volume tasks like batch classification or for environments requiring air-gapped deployments. The Scout variant's 10 million token context window outperforms proprietary competitors, making it ideal for retrieval-augmented generation (RAG) workflows that leverage expansive internal knowledge bases without the need for chunking or summarization. Prompts.ai simplifies the deployment of LLaMA, enabling teams to test open-source models alongside proprietary ones and switch seamlessly based on workload demands.
Gemini 3 Pro offers a unified transformer architecture capable of processing text, images, audio, video, and code simultaneously, eliminating the need for separate preprocessing steps. With a context window ranging from 1 million to 2 million tokens (depending on the enterprise tier), it excels in research-heavy tasks such as analyzing extensive video libraries or managing mixed-media marketing campaigns. Priced at $2.00 per million input tokens and $12.00 for output tokens, Gemini balances performance with cost-effectiveness and integrates seamlessly with Google Workspace. Prompts.ai enables users to compare Gemini directly with GPT-5.2 and Claude using identical prompts, allowing enterprises to evaluate multimodal performance and select the best model for their needs without vendor lock-in.
When evaluating leading language models, four critical metrics come into play: coding proficiency (SWE-bench Verified), reasoning depth (GPQA Diamond and ARC-AGI-2), inference speed (tokens per second), and context capacity. Each model has its strengths, making them suitable for different tasks. For coding benchmarks, Claude Opus 4.5 leads with an 80.9% score, slightly ahead of GPT-5.2 at 80.0%, while Gemini 3 Pro follows at 76.8%. On reasoning tasks requiring advanced expertise, GPT-5.2 outperforms with a 92.4% score on GPQA Diamond, with Gemini 3 Pro close behind at 91.9%.
Speed is another differentiator. GPT-5.2 processes 187 tokens per second, making it 3.8 times faster than Claude Opus 4.5's 49 tokens per second. This speed advantage makes GPT-5.2 an excellent choice for applications like customer-facing chatbots, where quick response times are essential.
| Model | SWE-bench (Coding) | GPQA Diamond (Reasoning) | Speed (tok/s) | Context Window | Input Cost (per 1M tokens) |
|---|---|---|---|---|---|
| GPT-5.2 | 80.0% | 92.4% | 187 | 400K | $1.75 |
| Claude Opus 4.5 | 80.9% | 78.4% | 49 | 200K–1M | $5.00 |
| Gemini 3 Pro | 76.8% | 91.9% | 95 | 1M–2M | $2.00 |
| DeepSeek V3.2 | 73.1% | 74.8% | 142 | 128K | $0.28 |
Interestingly, the performance gap between open-source and proprietary models has nearly disappeared on the MMLU benchmark, shrinking from 17.5 percentage points to just 0.3 within a year. This progress means enterprises can now confidently deploy self-hosted models like LLaMA 4 for tasks where privacy is paramount, while reserving premium models for advanced reasoning or multimodal applications. These metrics highlight how each model aligns with specific business needs.
The choice of a language model depends heavily on the task at hand. For real-time customer support, GPT-5.2 is the standout option, delivering 500 tokens in just 2.7 seconds compared to Claude Opus 4.5's 10.2 seconds. When it comes to production code development, Claude Opus 4.5 excels with its top score on SWE-bench Verified, demonstrating proficiency in resolving real-world GitHub issues. For research and document analysis, Gemini 3 Pro shines with its expansive context window of 1M–2M tokens, allowing users to process entire codebases or multiple research papers in a single query - offering 2.5 times the capacity of GPT-5.2's 400K tokens.
"The optimal strategy is no longer 'which single model should we use?' but 'which models for which tasks?'" - Digital Applied
By adopting a multi-model approach, businesses can save 40% to 60% in costs. For instance, simpler tasks like classification can leverage cost-effective models such as DeepSeek V3.2, while complex reasoning tasks are better suited for Claude Opus 4.5 or GPT-5.2. This tailored approach ensures that resources are allocated wisely, balancing performance with cost efficiency.
The cost of using language models varies significantly, with pricing influenced by factors such as API rates, error correction, and integration efforts. Providers like Anthropic and OpenAI offer prompt caching and batch processing to reduce expenses. Cached input tokens can cut costs by up to 90%, while non-real-time batch API tasks, such as overnight report generation, receive discounts of up to 50%. Tools like Prompts.ai simplify these optimizations by offering a unified dashboard that tracks token usage, automates task routing based on performance thresholds, and provides real-time FinOps controls. These features help teams monitor spending, set budget alerts, and enforce usage policies without manual oversight.
Governance also plays a crucial role in model selection. While most providers meet standards like SOC 2 Type II and GDPR, only Claude Opus 4.5 and GPT-5.2 offer HIPAA Business Associate Agreements, making them suitable for healthcare applications. Data residency is another key factor; for instance, DeepSeek processes data on China-based infrastructure, which may conflict with regulations in industries like finance or government. Prompts.ai addresses these challenges by offering side-by-side comparisons and audit trails, ensuring that compliance requirements are consistently met across all models.
Selecting the right language model involves balancing intelligence and cost efficiency. High-performing models like Gemini 3 Pro and GPT-5.2 excel in handling complex tasks such as multi-step reasoning, advanced coding, and strategic analysis, though they come with higher token costs. For instance, simpler tasks can be routed to cost-effective options like DeepSeek V3.2, which costs just $0.28 per 1M input tokens, while reserving premium models for more demanding jobs.
Speed is another critical factor, especially for real-time applications like customer service chatbots or live voice assistants. GPT-5.2 processes 187 tokens per second, making it 3.8 times faster than Claude Opus 4.5, which handles only 49 tokens per second. However, for batch processing or large-scale data analysis where immediate responses aren't required, you can prioritize other factors, such as reasoning depth or cost, over speed.
When working with extensive datasets or lengthy documents, the context window size becomes essential. Models like LLaMA 4 Scout offer a context window of up to 10 million tokens, allowing comprehensive analysis of entire codebases, research papers, or legal documents in a single query. This capability is particularly useful in Retrieval-Augmented Generation (RAG) workflows, where large volumes of knowledge need to be incorporated without retraining the model. For standard tasks, smaller context windows are usually sufficient and more economical.
The choice between reasoning-focused and conversational models depends on the nature of your tasks. GPT-5.2 is ideal for logic-heavy activities like coding, mathematical calculations, and intricate problem-solving, while Claude Opus 4.5 shines in nuanced dialogue, tone adaptation, and content creation, making it perfect for customer support or tasks requiring a personal touch. Additionally, consider whether you need proprietary models for their ease of API access or open-weight models like LLaMA 4 for private deployment, fine-tuning, and enhanced control over sensitive data. With Prompts.ai, you can refine your selection through real-time, side-by-side comparisons of these criteria.
Prompts.ai simplifies the process of evaluating language models by enabling real-time, side-by-side comparisons. Instead of locking into a single vendor, you can test the same prompt across models like GPT-5.2, Claude Opus 4.5, and Gemini 3 Pro to determine which delivers the best results for your specific needs. This vendor-neutral approach ensures flexibility, allowing you to seamlessly switch between models - for example, using GPT-5.2 for logic-intensive tasks and Claude for creative content - without disrupting workflows.
The platform operates on a pay-as-you-go TOKN credit system, so you only pay for what you use, avoiding costly monthly subscriptions. This is especially valuable given the rapid pace of AI advancements. Prompts.ai also offers FinOps controls through a unified dashboard, making it easy to track token usage, monitor spending, and set budget alerts. You can even automate task routing by performance thresholds, directing simple tasks to budget-friendly models while reserving premium options for complex reasoning. This multi-model approach can lead to significant cost savings.
In addition to cost management, Prompts.ai provides pre-built workflows called "Time Savers", which are ready-to-use templates for tasks in sales, marketing, and operations. These templates standardize prompt engineering across your team, ensuring consistent results when switching between models. The platform also supports custom workflows using LoRAs (Low-Rank Adaptations), cutting down on the time needed for demanding tasks like rendering and proposal creation. With access to over 35 leading LLMs through a single interface, you can quickly adapt to new models as they emerge without overhauling your infrastructure.
Interoperability begins with standardizing how prompts are structured across different models. By defining elements like role, task, example output, and exclusions, you can achieve consistent results whether using GPT-5.2, Claude Opus 4.5, or open-weight models like LLaMA 4. Prompts.ai helps with this by maintaining a centralized prompt library, making refined prompts easily accessible for your team and simplifying integration into workflows.
"Recognize the potential of AI and consider it like a young, inexperienced, yet brilliant employee who can significantly enhance or even replace your entire team." - Fedor Pak, CEO, Chatfuel
Compliance requirements vary depending on industry and region. While many providers adhere to standards like SOC 2 Type II and GDPR, only a few offer HIPAA Business Associate Agreements for healthcare applications. Prompts.ai ensures enterprise-grade security with complete audit trails, enabling you to track every AI interaction for regulatory reviews. The platform also allows you to enforce usage policies, meet data residency requirements, and safeguard sensitive information, particularly when deploying open-weight models on private infrastructure.
For organizations handling proprietary data, Retrieval-Augmented Generation (RAG) offers a secure way to incorporate knowledge into models without exposing sensitive information. Prompts.ai supports RAG workflows, giving you full control over your data while leveraging top-tier LLM capabilities. Additionally, the platform includes deliberative alignment features, which verify decisions against safety guidelines before execution - an essential safeguard for high-stakes industries like finance, healthcare, or legal services. By combining robust compliance tools with the flexibility to switch between models, Prompts.ai ensures you can meet regulatory standards without compromising performance or efficiency.
Choosing the right large language model (LLM) comes down to balancing performance, cost, and compliance. No single model can handle every enterprise need anymore. Instead, companies are adopting multi-model strategies, assigning specific tasks to models best suited for them - whether it’s speed, coding capabilities, or handling long-context data. This targeted approach not only boosts performance but also simplifies workflows.
Cost differences between models are striking, with some budget options being 94% cheaper than premium ones. Enterprises can save 40–60% on costs by using affordable models for straightforward tasks and reserving pricier ones for more complex operations. Additionally, ensuring compliance with standards like SOC 2, HIPAA, and GDPR is critical for secure deployments, particularly in regulated sectors.
Prompts.ai makes managing and integrating multiple LLMs seamless. With access to over 35 leading models through a single interface and a pay-as-you-go TOKN credit system, you only pay for what you use. Plus, you can start experimenting with 100,000 free tokens, allowing you to compare models side-by-side and identify the best fit for your business workflows.
The platform’s real-time comparison tools let you evaluate models based on actual tasks, while built-in FinOps controls track token usage, set budget limits, and automate task distribution. Pre-designed Time Savers templates and custom workflows simplify prompt engineering, ensuring consistent results across your team. From managing customer service bots to processing complex documents or writing advanced code, Prompts.ai gives you the flexibility and control to scale AI without locking into a single vendor.
Using a variety of language models lets you align each task with the model that best fits its needs in terms of complexity and cost. For instance, high-performance models like GPT-4 are ideal for demanding tasks such as advanced reasoning or generating code, while simpler tasks like summarization or classification can be handled by faster, more budget-friendly models. This approach ensures you get the results you need without unnecessary expenses.
By reserving premium models for critical tasks and using lower-cost models for routine work, organizations can often save 40–60% on costs without compromising quality. Automated systems can take this a step further by dynamically choosing the most suitable model for each request, optimizing speed, cost, and accuracy across all workflows.
GPT-5.2 and Claude Opus 4.5 each bring distinct strengths to the table, making them well-suited for different needs.
Claude Opus 4.5 shines in coding tasks, delivering around 80% accuracy on software engineering benchmarks. It emphasizes safety, thoughtful reasoning, and a strong defense against prompt-injection attacks. These qualities make it a reliable choice for sensitive tasks or complex writing that demands precision and care.
Meanwhile, GPT-5.2 excels in abstract reasoning, mathematics, and professional knowledge. It achieves top-tier results on reasoning and math benchmarks and processes text roughly 3.8 times faster than Claude Opus 4.5. This speed advantage makes it a standout option for real-time or low-latency scenarios.
If your focus is on coding accuracy and safety-critical work, Claude Opus 4.5 is the way to go. For tasks requiring quick processing, math-heavy problem-solving, or professional expertise, GPT-5.2 is the better fit.
Prompts.ai places a strong emphasis on data privacy by incorporating top-tier security protocols and comprehensive compliance measures. By centralizing AI workflows within a secure orchestration layer, the platform ensures user data stays protected and avoids exposure to unmanaged third-party endpoints.
Data protection is reinforced with encryption both in transit and at rest, while access is tightly controlled through role-based permissions and detailed audit logs. This setup not only safeguards sensitive information but also provides full transparency for regulatory audits. The platform’s real-time cost and usage tracking doubles as an activity log, enabling businesses to align with regulations such as CCPA, GDPR, and other industry-specific requirements. These features make Prompts.ai a trusted solution for U.S. organizations prioritizing security and regulatory compliance.



















