Pay As You Go - AI Model Orchestration and Workflows Platform


LLM comparison tools help you evaluate large language models (LLMs) like GPT, Claude, Gemini, and LLaMA by analyzing their performance on the same tasks and prompts. These tools focus on practical metrics such as cost per 1M tokens (USD), latency, reasoning accuracy, and hallucination rates in production settings. Their purpose is to assist businesses in selecting the best models for specific workflows, balancing quality, speed, and cost.
Key benefits include:
Top tools:
Quick Tip: Start with leaderboards for general insights, then use tools like Prompts.ai for tailored evaluations with real-world tasks. This layered approach ensures you select the best fit for your needs while managing costs and compliance.
Public leaderboards for large language models (LLMs) rank various models by applying standardized benchmarks. These platforms evaluate models using consistent metrics on identical inputs, then present the results in a ranked format. Key evaluation criteria include the accuracy of answers, semantic similarity, and rates of hallucination. For instance, Hugging Face hosts a widely-used open LLM leaderboard, which tracks metrics like MMLU (Massive Multitask Language Understanding), GPQA (Graduate-Level Question Answering), processing speed, cost per million tokens (in USD), and context window size across numerous open-source models.
The ranking process involves providing identical inputs to all models, evaluating their responses based on predefined metrics, and generating scores accordingly. While this method gives a clear snapshot of general capabilities, it primarily reflects aggregated user preferences and standardized task performance. However, it doesn’t account for how well models perform in specific, real-world scenarios. This standardized approach is helpful for broad comparisons but lacks the adaptability needed for niche or industry-specific applications.
Public leaderboards rely on fixed tests to assess models using general criteria. While useful for broad evaluations, this setup offers limited flexibility for organizations needing to measure how models perform in specialized use cases or meet industry-specific requirements. Factors such as user demographics, prompt phrasing, and voting tendencies can also influence rankings. For businesses requiring precise assessments based on domain-specific accuracy or compliance, these general-purpose rankings may fall short of providing the necessary level of detail.
LLM leaderboards are primarily designed as reference tools to guide initial model research rather than as interactive components of AI workflows. They provide static rankings that help narrow down options but don’t facilitate automated selection or deployment. To bridge this gap, specialized platforms allow for side-by-side testing, the use of custom metrics, human-in-the-loop feedback, and streamlined model transition management. These tools help transform benchmark data into actionable insights. Additionally, rank tracking tools can be integrated into workflows to monitor post-deployment performance. This is particularly valuable for tasks like evaluating brand sentiment or visibility in AI-generated content.
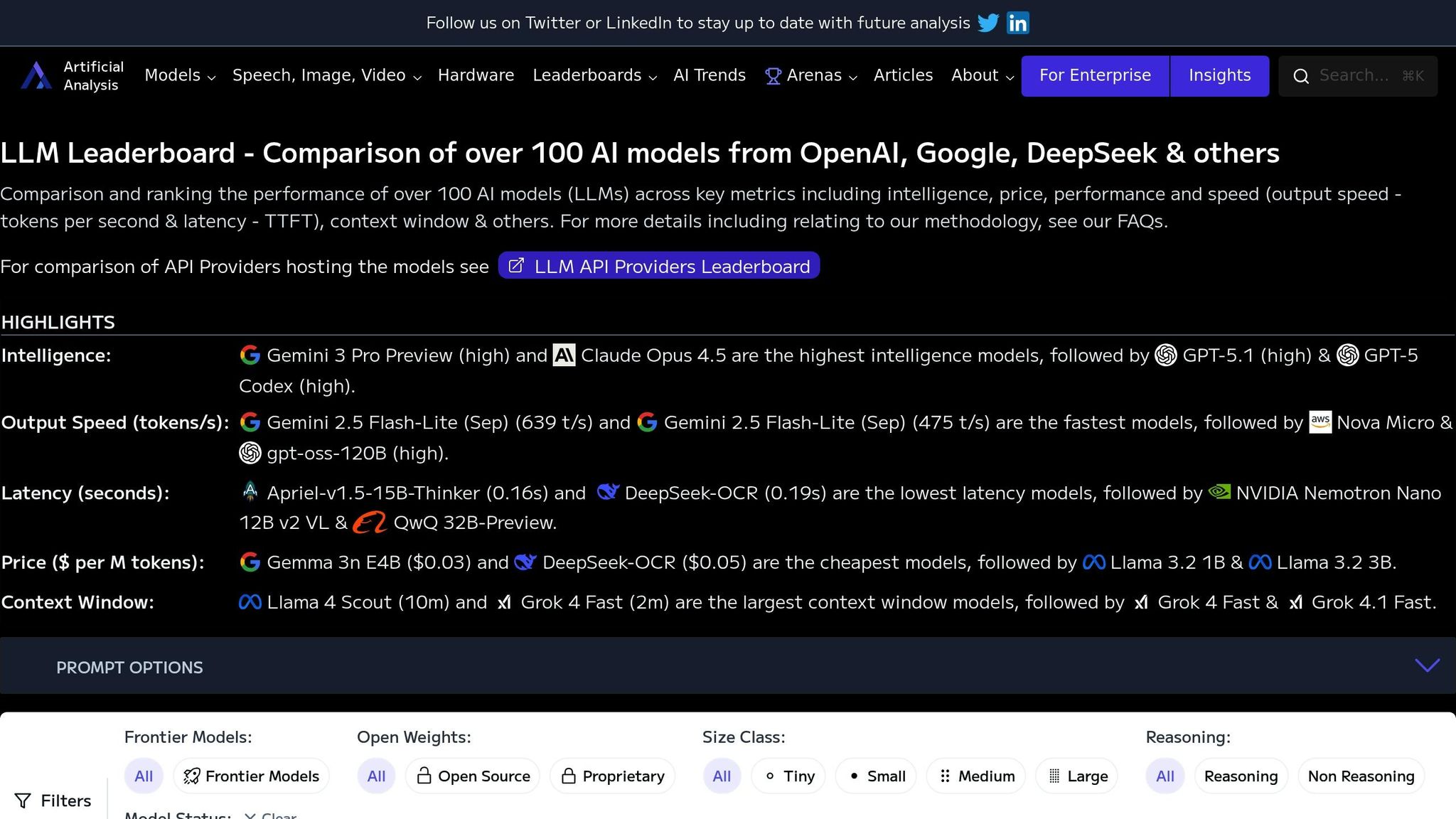
This innovative approach takes a step beyond traditional public leaderboards by using a large language model (LLM) to evaluate other models. Artificial Analysis Model Leaderboards rely on the LLM-as-judge method, where a powerful LLM assesses and scores outputs based on predefined criteria, streamlining the evaluation process [12, 16, 11, 17, 18]. Let’s dive into how this methodology works, its customization options, and how it integrates into workflows.
The LLM-as-judge method simplifies the evaluation of multiple models by leveraging the capabilities of a high-performing LLM. This model reviews outputs from other LLMs and assigns scores based on factors such as coherence, relevance, and tone. This approach is particularly useful for text-heavy assessments where subjective qualities matter, significantly reducing the need for extensive human involvement.
The Artificial Analysis Model Leaderboard provides several filtering options for tailoring model comparisons. Users can sort models by attributes like "Frontier Models", "Open Weights", "Size Class", "Reasoning", and "Model Status". However, it currently lacks features for incorporating custom metrics, industry-specific datasets, or task-focused evaluation methods. This limitation may pose challenges for organizations with specialized evaluation needs.
Integration capabilities vary depending on the tool's design. Some systems allow straightforward API integrations, while others offer more robust, proxy-based solutions that work across multiple LLM endpoints. The success of these integrations largely hinges on the tool's ability to handle diverse LLM providers and to support custom evaluation metrics tailored to specific workflows.
AI leaderboard aggregators gather and organize standardized benchmark data to measure the performance of large language models (LLMs). These platforms use datasets with predefined answers to evaluate models, ranking them based on their scores. This centralized system provides a clear way to compare LLMs side by side, offering transparency and consistency in performance assessments.
Aggregators rely on benchmark tests that assess various skills, such as reasoning, coding, and mathematical problem-solving. Each model's performance is scored against correct answers, and these scores are then compiled into leaderboards. This standardized process ensures a fair comparison across models, eliminating reliance on vendor-provided claims and offering a neutral evaluation framework.
Platforms like Vellum AI Leaderboard and LLM-Stats go beyond basic rankings, including metrics like speed and cost in their assessments. For users needing more flexibility, advanced tools provide customization options. For instance, Nexla offers over 20 pre-built LLM connectors and a visual pipeline designer, enabling engineers to manage parallel calls to multiple models with ease. These adjustments can be made through simple configuration updates, avoiding the need for extensive code rewrites. Similarly, Helicone allows users to test their actual production prompts across different models, tracking usage, costs, and performance metrics in real-time.
The best aggregators go a step further by integrating seamlessly into existing development workflows. Platforms like Helicone provide unified interfaces compatible with major LLM APIs, requiring minimal code changes. This enables teams to log baseline performance, conduct side-by-side comparisons, gradually shift traffic between models, and monitor outcomes - all without disrupting their workflows. By simplifying what is often a complex process, these tools make evaluating and switching between models as straightforward as tweaking a few settings, ensuring smooth and efficient operations.
Prompts.ai offers a fresh perspective on evaluating AI models, moving away from traditional benchmark-focused leaderboards. Instead, it emphasizes direct prompt testing across over 35 leading LLMs, including GPT, Claude, LLaMA, and Gemini. By allowing teams to test their actual production prompts - real-world tasks rather than synthetic benchmarks - it provides insights into which model best aligns with specific workflows. This hands-on approach ensures that U.S. product teams can make informed decisions based on practical performance rather than generic rankings.
Prompts.ai’s comparison process is built around standardized prompt execution, ensuring that tests are fair and reflective of real-world use. Teams create prompts that mimic their actual production tasks and run them with identical inputs across multiple models. This setup guarantees that any differences in outputs are purely model-driven. Results are displayed side by side, allowing users to evaluate them based on criteria that matter to their organization, such as factual accuracy, adherence to tone, or compliance with brand voice. This tailored approach ensures that evaluations go beyond generic metrics to meet specific quality standards.
The platform offers extensive customization options to meet the varied needs of different organizations. Teams can create and organize prompt libraries tailored to specific projects or departments, such as retail support or healthcare compliance. Variables like {{customer_name}} or {{account_tier}} can be added to simulate real-world scenarios, while model-specific settings can be adjusted for each use case. For teams working on advanced projects, Prompts.ai also supports training and fine-tuning LoRA models. This flexibility is essential because the effectiveness of prompts and models can vary widely depending on the task - a model that excels in creative writing might struggle with technical documentation.
Prompts.ai also simplifies integration, ensuring it fits seamlessly into existing workflows.
The platform is designed for both pre-deployment testing and ongoing optimization. Engineering teams can evaluate candidate models using production-like prompts, comparing factors like quality, response time, and estimated costs per 1,000,000 tokens (calculated in USD). Once applications are deployed, anonymized prompts can be exported and tested on updated models. Winning configurations can then be seamlessly integrated back into the system using CI/CD pipelines or feature flags. Human review ensures that any changes align with organizational standards, enabling smooth integration without disrupting established DevOps workflows.
Prompts.ai provides detailed cost transparency, displaying estimates for both per-request and per-token expenses. Current provider pricing is shown in USD, such as "$X per 1M input tokens / $Y per 1M output tokens." Teams can also analyze aggregated costs for specific tasks, like the cost per support ticket, and perform simple what-if scenarios by adjusting token limits or switching to more budget-friendly models. This feature helps finance and engineering teams collaborate effectively, balancing performance needs with budget constraints. With cost per 1M tokens varying by over 10× between premium reasoning models and more economical alternatives, this visibility is invaluable for making cost-effective decisions.

Comparison of Top 4 LLM Evaluation Tools: Features, Methodology, and Use Cases
Every LLM comparison tool has its own set of strengths and drawbacks, and understanding these nuances is key to selecting the right one for your needs. Below is a closer look at what each platform offers and where it might fall short in practical applications.
LLM Leaderboard provides a wide range of models with standardized benchmark scores, making it an excellent resource for quickly gauging general performance. However, these benchmarks are broad and may not accurately reflect how a model will perform on specific tasks in your production environment.
Artificial Analysis Model Leaderboards stands out for offering detailed metrics like latency and throughput, which are especially useful for teams focused on speed and efficiency. On the downside, these metrics are based on generic scenarios, which might overlook critical factors like quality nuances, especially for creative tasks or compliance-heavy requirements.
AI Leaderboards Aggregator simplifies the research process by combining benchmarks from various sources into one consolidated view. This can save time when assessing model capabilities. That said, relying solely on aggregated benchmarks can be risky, given the vast number of available LLMs and their inconsistent performance across different domains. Testing models with your specific production prompts remains a crucial step to ensure compatibility and effectiveness.
Prompts.ai offers a unique advantage by allowing direct testing of production prompts across more than 35 top models. This ensures evaluations are grounded in real-world performance. The platform also provides transparent, per-token pricing in USD and integrates smoothly with enterprise workflows, helping teams balance cost, performance, and compliance. While setting up representative test prompts requires an initial time investment, the insights gained are directly aligned with your operational goals, quality standards, and budgetary needs. This tailored approach makes it especially valuable for production-focused environments.
The stage of your AI journey plays a key role in determining the best tools for comparing models. For initial exploration, tools like LLM Leaderboard and Artificial Analysis Model Leaderboards are excellent starting points. They provide quick overviews of model performance, context window sizes, and USD pricing, helping you create an initial shortlist of options. When your needs extend to cross-verified benchmarks or evaluating capabilities beyond text generation, the AI Leaderboards Aggregator becomes a valuable resource. These tools help you narrow down choices, setting the foundation for deeper, more practical evaluations.
Once you’ve filtered options using broader benchmarks, it’s crucial to test models with real production prompts. This hands-on approach ensures the models can handle specific tasks, including region-specific formats and compliance-related language. Practical testing is vital for identifying the right fit.
Prompts.ai takes this evaluation process a step further by allowing you to test models side by side using actual production prompts. With access to over 35 models, you can compare key metrics like quality, cost per token in USD, and latency for tasks that matter most to your business - be it managing customer support tickets, creating regulatory documents, or crafting sales copy. The platform also includes features like prompt versioning, team collaboration tools, and governance capabilities tailored to meet US enterprise standards. Notably, Prompts.ai is aligned with compliance expectations, with an active SOC 2 Type 2 audit process initiated on June 19, 2025.
By combining these tools, you can establish an efficient workflow. Start with leaderboards to filter models based on budget and capabilities, then leverage Prompts.ai to validate their performance on real-world data and integrate them into your operations. This layered approach ensures you’re not just selecting the top-ranked model, but the one that meets your specific use case, compliance needs, and cost considerations.
While public benchmarks are helpful for periodic market reviews, platforms like Prompts.ai become indispensable for ongoing tasks like refining prompts, selecting models, and scaling deployments. This is especially true when priorities like auditability, data security, and seamless operational integration are critical to achieving your goals.
LLM comparison tools help assess and contrast large language models by focusing on critical aspects such as accuracy, response time, cost-efficiency, and domain-specific suitability. They offer a clear view of each model's capabilities and limitations, making it easier to pinpoint the right fit for your specific needs.
By examining performance data and real-world applications, these tools streamline decision-making, ensuring the selected model supports your business objectives and achieves the best possible outcomes.
A leaderboard offers a snapshot of how language models perform by ranking them based on standardized benchmarks and aggregated metrics. It’s a quick way to identify which models stand out in terms of overall capabilities.
Direct prompt testing takes a more focused approach, diving into how a model responds to specific tasks or queries. This method reveals detailed insights into its accuracy, behavior, and how well it aligns with particular requirements, making it especially useful for customizing solutions to fit your needs.
These methods complement each other: leaderboards are great for broad comparisons, while prompt testing zeroes in on finding the right model for specific workflows.
Prompts.ai brings simplicity to the complex world of LLM selection by offering a secure, enterprise-ready platform that consolidates access to over 35 AI models in one place. This unified approach not only reduces the hassle of juggling multiple tools but also ensures streamlined governance, helping businesses stay compliant and efficient.
With optimized AI workflows, Prompts.ai delivers substantial cost savings - up to 98% - without compromising on performance or reliability. It’s a smart choice for companies aiming to drive progress while keeping expenses under control.



















