Pay As You Go - AI Model Orchestration and Workflows Platform


Token usage can silently drive up AI costs if left unchecked. With expenses ranging from $10 to $20 per million tokens, large-scale operations can quickly scale into billions of tokens monthly. Tracking token consumption is key to controlling costs, optimizing workflows, and ensuring performance accountability. This article explores three platforms that simplify token tracking and cost management:
Each platform offers unique features for monitoring token usage, optimizing costs, and improving AI performance. Below is a quick comparison to help you choose the right solution.
| Feature | Prompts.ai | Laminar | Braintrust |
|---|---|---|---|
| Token Tracking | Real-time insights, user-level data | Multi-turn session tracing | Detailed metrics for all LLM calls |
| Cost Management | Pay-as-you-go TOKN credits | Real-time cost calculations | Pre-built charts, Pro plan options |
| Integrations | 35+ LLMs, unified interface | OpenAI, Anthropic, LangChain, more | Zapier, 15+ AI providers, GitHub |
| Pricing | Starts at $0/month | Freemium, from $25/month | Free tier, Pro plan at $249/month |
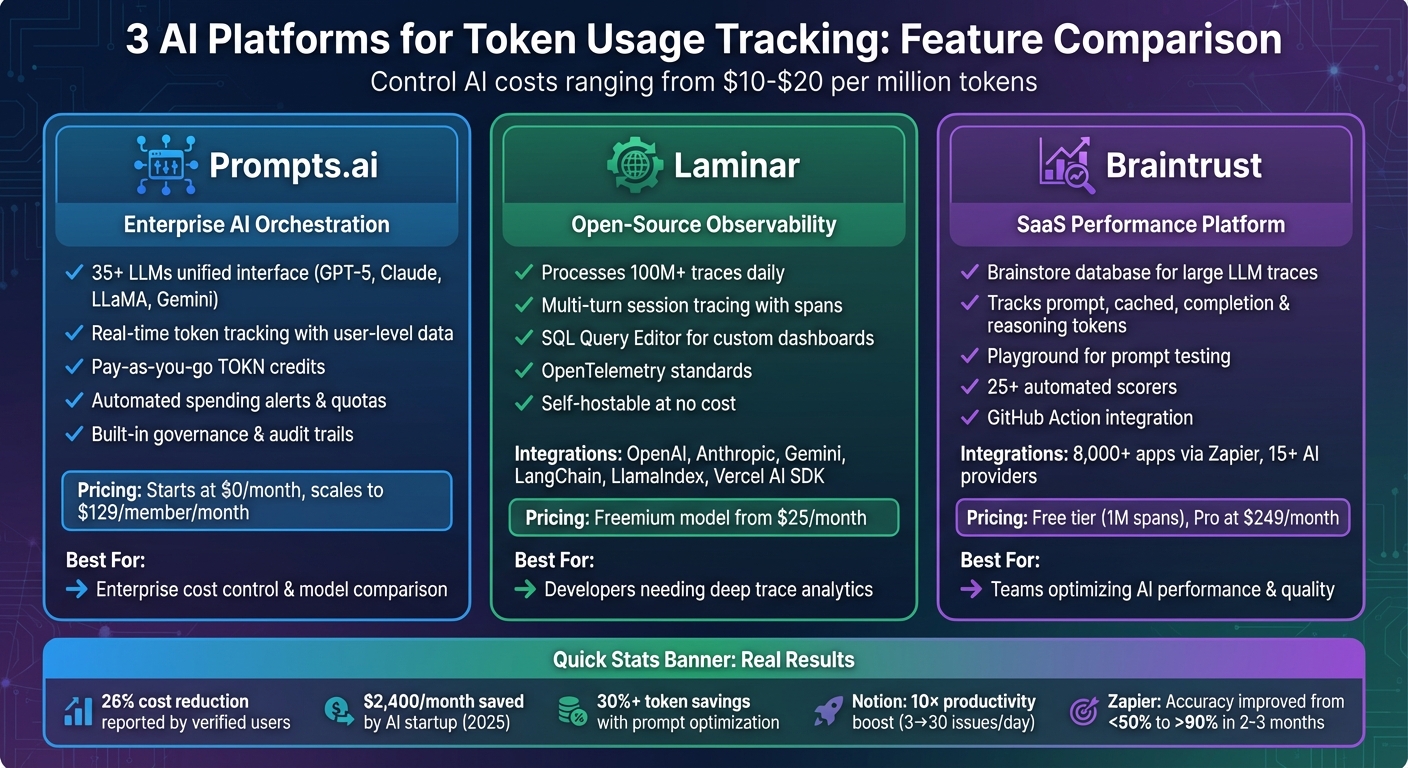
AI Token Tracking Platforms Comparison: Prompts.ai vs Laminar vs Braintrust
Prompts.ai serves as an enterprise AI orchestration platform, seamlessly uniting over 35 advanced language models - including GPT-5, Claude, LLaMA, and Gemini - within a single, streamlined interface. Tailored for organizations looking to manage AI expenses at scale, it combines real-time token tracking with robust financial controls to help prevent overspending.
Prompts.ai provides detailed insights into every AI interaction, capturing critical data such as the model used, user ID, routing, and timing. Unlike traditional systems that rely on monthly invoices, this platform offers immediate visibility into token consumption, helping you pinpoint high-usage workflows and uncover opportunities for optimization.
The platform simplifies cost control with features like prompt refinement and workflow adjustments. By reducing unnecessary token usage - such as trimming boilerplate text or shortening system messages - teams can significantly cut costs. Real-time usage data for each model and prompt allows users to identify expensive tasks and redirect simpler requests to more economical models. Additionally, the pay-as-you-go TOKN credit system ensures you’re only charged for what you use, eliminating the need for recurring subscription fees.
Prompts.ai consolidates 35+ leading LLMs into one platform, eliminating the inefficiencies of juggling multiple tools. Teams can easily switch between models, compare their performance side-by-side, and deploy workflows in a matter of minutes - all without the hassle of managing separate API keys or billing systems. Built-in governance and audit trails ensure compliance is seamlessly integrated into every workflow.
The platform includes automated spending controls, offering quotas and budget alerts to keep costs in check. This proactive approach ensures teams stay within budget, addressing potential overages before they occur rather than reacting after the fact. Next, we’ll explore how Laminar extends these capabilities.
Laminar is an open-source observability platform designed to automatically track token usage across AI workflows. It’s built to handle massive scale, processing hundreds of millions of traces daily. Unlike systems that rely on manual logging, Laminar begins capturing input and output token counts as soon as it’s set up at your application’s entry point.
Laminar meticulously records your execution flow by tracing every LLM call, function execution, and API request. Each trace is broken into spans that detail input/output token counts, latency, and the model used. These spans are grouped into sessions, making it possible to monitor multi-turn conversations or complex workflows. With its built-in SQL Query Editor, you can create custom dashboards to uncover spending trends and performance bottlenecks. This level of tracking provides the groundwork for identifying areas to optimize costs and improve performance.
Laminar calculates costs in real time based on the token volume and the specific model used for each API call. It also includes a Playground environment where you can test models and prompts before deployment. By using the @observe() decorator in Python or the observe() wrapper in JavaScript, you can trace custom functions and identify token-heavy nested LLM calls. This detailed visualization highlights the components consuming the most tokens. Additionally, Laminar integrates seamlessly with various LLM providers and frameworks, making it a versatile tool for cost and performance management.
Laminar supports automatic instrumentation for major LLM providers like OpenAI, Anthropic, Gemini, Mistral, and Groq. It also integrates with frameworks such as LangChain, LlamaIndex, Vercel AI SDK, and LiteLLM. For browser-based AI agents, it synchronizes window recordings from tools like Browser Use, Stagehand, Playwright, and Puppeteer with execution traces. Built on OpenTelemetry standards, Laminar also offers a SQL API for custom external reporting.
Laminar provides real-time visibility into spans and execution steps, allowing you to debug long-running agents without delay. It captures application-level exceptions as they happen, logging errors along with the relevant token usage data. Its managed cloud service at laminar.sh offers unlimited span ingestion on a generous free tier, while the platform is fully self-hostable at no cost.
Braintrust is a SaaS platform designed to help teams track token usage while improving AI performance. It automatically collects detailed token metrics for every LLM call - this includes prompt tokens, cached tokens, completion tokens, and reasoning tokens. At its core is Brainstore, a database specifically built to handle large LLM traces, which can span tens of kilobytes per operation.
Braintrust meticulously logs execution details such as total duration, LLM-specific timing, and time to first token (TTFT). It also tracks LLM and tool calls, alongside error types. The platform’s Monitor page consolidates token counts and costs into pre-built charts, while custom BTQL dashboards allow users to organize data by model or project. One standout feature is the ability to turn production traces into evaluation cases with a single click, enabling structured regression testing. These capabilities lay the groundwork for effective cost management.
The platform includes a Playground environment where teams can experiment with prompts using actual production data. This setup makes it easy to compare models and fine-tune configurations, helping teams identify the most cost-efficient options before deployment . For Pro plan users, Braintrust integrates with the Orb usage portal, offering detailed cost monitoring throughout the billing cycle . The free tier supports up to 1,000,000 trace spans and 10,000 scores, while the Pro plan starts at $249/month, offering unlimited spans and 5GB of data. Companies like Notion have seen dramatic improvements, reporting a shift from resolving 3 issues per day to 30, resulting in a 10× boost in productivity.
Braintrust simplifies operations with an AI Proxy that provides a single OpenAI-compatible API for multiple models, including OpenAI, Anthropic, and Google. This proxy automatically traces and caches every call. The platform supports automatic tracing through TypeScript and Python wrapper functions, capturing all token metrics. Additionally, it integrates with over 8,000 apps and 450+ AI tools via Zapier, while also supporting more than 15 major AI providers like AWS Bedrock, Azure OpenAI, Google Vertex AI, Databricks, Groq, Cerebras, and Fireworks . Since August 2023, Zapier’s integration with Braintrust has enabled logging of user interactions and automated evaluations, resulting in a leap in AI product accuracy - from under 50% to over 90% - within just 2–3 months. These integrations provide real-time monitoring and significantly enhance production quality.
Braintrust includes Online Scorers that review live traffic for issues like hallucinations or subpar responses as they happen. A native GitHub Action posts evaluation results directly to pull requests, streamlining development workflows. For streaming use cases, enabling the include_usage parameter in model options captures token metrics in real time.
Prompts.ai, Laminar, and Braintrust each bring unique strengths to the table, offering distinct approaches to token management, integration, and pricing. Here's how they compare across key features:
Prompts.ai simplifies token tracking with built-in FinOps controls, while Laminar focuses on trace analytics, and Braintrust excels in detailed cost attribution using metadata. Prompts.ai also stands out by consolidating model comparisons, allowing businesses to optimize performance and costs without juggling multiple tools.
Integration flexibility varies across platforms:
Pricing structures also differ significantly:
"Braintrust's cost monitoring shows exactly where your spending goes in real-time dashboards and identifies expensive workflows. You can group costs by any metadata field to understand which parts of your application consume the most tokens."
- Braintrust Team
The platforms discussed above highlight the importance of accurate token tracking for managing both costs and performance in AI operations. These tools replace guesswork with precise, data-driven insights by offering detailed visibility into input, output, and reasoning tokens. This level of transparency allows teams to pinpoint exactly where their spending goes - whether it's tied to a user session, a workflow, or a specific AI agent. Without such clarity, organizations risk unexpected expenses and inefficient use of resources.
Token tracking isn't just about cost control; it also enhances performance monitoring. By keeping an eye on metrics like latency, throughput, and success rates in real time, developers can spot and resolve bottlenecks before they affect user experience. For instance, comparing models like GPT-4 and Claude on identical tasks enables informed decision-making based on actual performance data.
Automated governance features, such as budget thresholds and alert systems, help prevent cost overruns. These proactive measures have shown tangible results. Verified users have reported cutting AI expenses by 26% while increasing overall usage, thanks to unified billing views. In 2025, Sarah Chen, CTO of an AI startup, saved $2,400 per month by leveraging a centralized dashboard to identify cost-saving opportunities across their AI stack.
Transitioning from intuition to observability transforms the way AI resources are managed. Teams that adopt practices like prompt discipline - removing unnecessary boilerplate context and setting strict output limits - paired with intelligent model routing, have achieved token savings of over 30% when cache hit rates align with those benchmarks.
Cost-per-outcome analysis further connects token usage to tangible business results. As the Statsig Team aptly puts it:
"Cost without outcomes is noise; outcomes without cost is hope".
With effective tracking tools, organizations can confidently scale their AI capabilities while maintaining tight control over both performance and expenses.
Monitoring token usage gives you the ability to spot inefficient prompts and less-than-ideal model selections, enabling you to fine-tune your workflows. By establishing usage limits and choosing models more strategically, you can dramatically reduce costs while enhancing performance. Some users have even achieved cost savings of up to 98% through effective token management.
When choosing a token tracking platform, focus on tools that deliver real-time monitoring, cost control, and actionable insights. Platforms with detailed analytics can break down token usage by project or model, helping you pinpoint inefficiencies and streamline workflows.
Opt for solutions that include customizable limits and alerts to keep budgets on track. Features like usage caps, automated notifications when thresholds are near, and the ability to pause activity once limits are hit can safeguard against unexpected expenses.
Effective cost management tools are also key. Look for options that provide budget forecasting, token allocation, and clear expense reports in U.S. dollars to help you plan and manage spending. Security measures such as audit logs and user tracking add an extra layer of control, ensuring compliance and protecting data integrity while enhancing AI performance.
Real-time token tracking provides instant insights into token usage, enabling you to adjust prompts and refine model interactions immediately. This approach minimizes unnecessary usage, enhances response times, and ensures steady output quality.
By keeping a close eye on token consumption in real time, you can make informed decisions to control costs while maintaining top-notch performance in your AI workflows - all without compromising on efficiency or results.



















