Pay As You Go - AI Model Orchestration and Workflows Platform


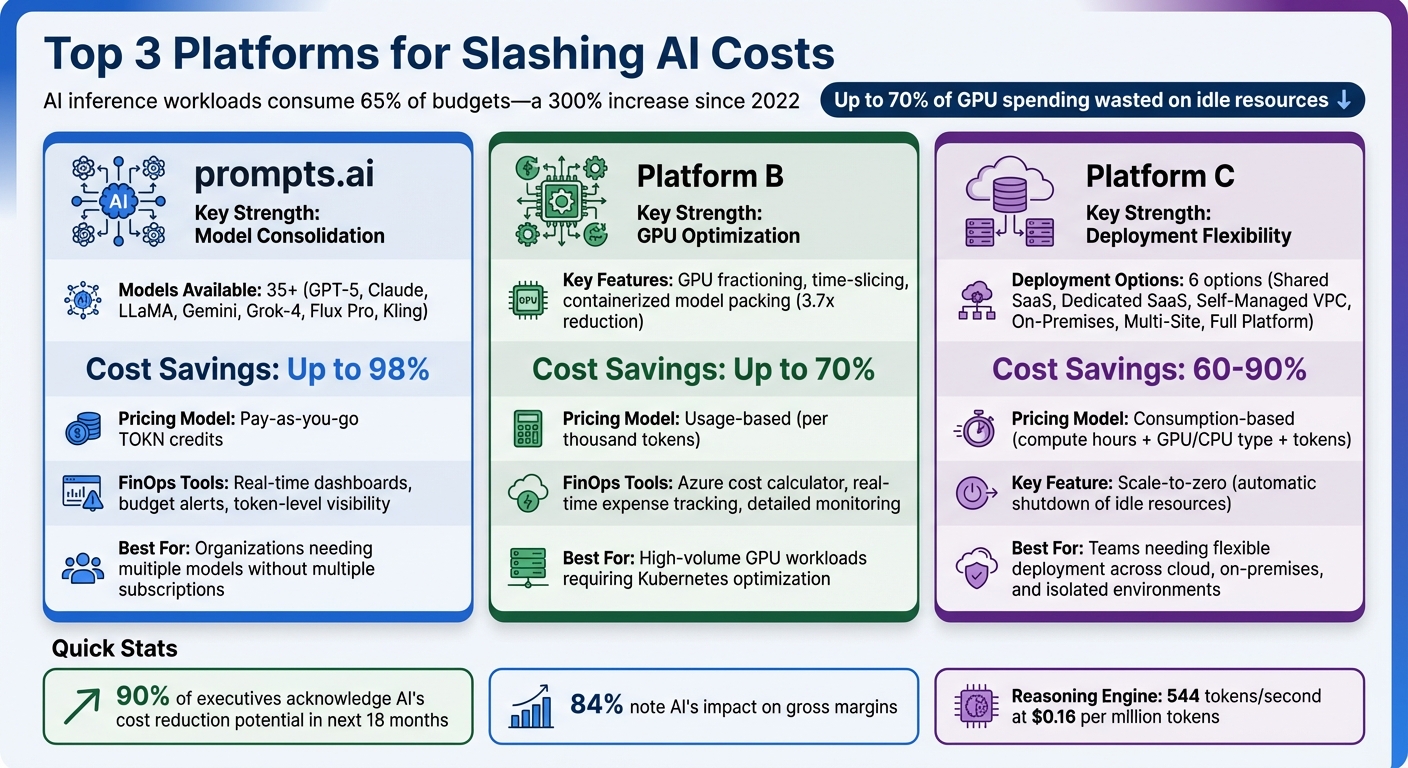
AI costs are skyrocketing, with inference workloads consuming 65% of budgets - a 300% increase since 2022. Many organizations waste up to 70% of GPU spending due to idle resources, poor scaling, and limited cost tracking. Platforms like prompts.ai, Platform B, and Platform C are solving this problem by cutting expenses through smarter resource management, real-time cost insights, and flexible deployment options. Here's how:
These platforms provide the tools and insights needed to transform AI spending into a controlled, measurable investment. Below, we break down how they work and what they offer.
| Platform | Key Strength | Cost Savings | Pricing Model | FinOps Tools |
|---|---|---|---|---|
| prompts.ai | Model consolidation (35+ models) | Up to 98% | Pay-as-you-go TOKN credits | Real-time dashboards, budget alerts |
| Platform B | GPU optimization techniques | Up to 70% | Usage-based | Azure cost calculator, detailed tracking |
| Platform C | Flexible deployment options | 60–90% | Consumption-based | Centralized control center, real-time data |
These tools are reshaping how businesses manage AI costs, offering smarter ways to scale without overspending.
AI Cost Reduction Platform Comparison: Features and Savings
Prompts.ai brings together over 35 models - including GPT-5, Claude, LLaMA, Gemini, Grok-4, Flux Pro, and Kling - within a single, secure platform. By consolidating these tools, it eliminates the need for multiple subscriptions and can reduce costs by as much as 98%. With its Pay-As-You-Go TOKN credit system, organizations are charged only for the resources they actually use.
Prompts.ai offers plans tailored to different needs. For individuals, there’s a free option, while the Creator plan is priced at $29/month, and the Family plan at $99/month. For businesses, options include Core at $99 per member/month, Pro at $119 per member/month, and Elite at $129 per member/month. These plans avoid the waste of traditional seat-based licenses, ensuring costs align directly with usage. Additionally, the plans integrate seamlessly with advanced FinOps tools to help manage budgets effectively.
The platform includes FinOps dashboards that provide real-time insights into spending. Teams can monitor costs by project, set budget limits, and receive alerts to avoid overspending. Side-by-side model performance comparisons make it easy to route tasks to the most cost-effective options without sacrificing quality. These tools not only keep expenses under control but also improve operational efficiency.
Prompts.ai supports a range of deployment options while upholding strict security and compliance standards. Teams can scale models, users, and operations in just minutes, avoiding lengthy setup times. The Prompt Engineer Certification program helps organizations build in-house expertise, reducing reliance on expensive external consultants. Additionally, community-driven workflows allow teams to quickly implement proven solutions, improving productivity by up to 10× with customizable tools.
Platform B is built to address AI-related expenses by employing advanced GPU management techniques. Features like GPU fractioning and time-slicing enable multiple models or tasks to share a single GPU, boosting utilization and lowering costs per user. Additionally, the platform leverages containerized model packing, which streamlines resource usage and reduces compute requirements by up to 3.7x. The scale-to-zero feature automatically powers down idle model replicas and compute nodes, ensuring no unnecessary costs are incurred.
These resource management strategies support a transparent, usage-based pricing structure that aligns costs with actual consumption.
Platform B uses a usage-based pricing model, where charges are tied to actual usage. Billing is calculated per thousand tokens, with prices displayed per million tokens for better clarity. Agent creation is free, and the platform ensures pricing transparency by matching serverless inference costs to published provider rates. Organizations can fine-tune spending by testing agents and adjusting parameters before full-scale deployment. Features like auto-indexing pauses and fixed-length chunking further reduce costs when managing knowledge bases.
To complement this pricing structure, the platform provides robust financial insights through its FinOps tools.
Platform B incorporates FinOps tools to maximize cost efficiency. An Azure pricing calculator helps users estimate costs for services such as Azure OpenAI, Speech, and Language before deployment. The Cost Analysis tool offers real-time expense tracking within both the Foundry and Azure portals, allowing teams to monitor spending daily, monthly, or annually. Detailed monitoring options break down expenses by billing meter, resource group, or specific model deployment, providing clear visibility into input and output token usage for individual language models.
Platform C helps reduce expenses by using advanced compute orchestration to efficiently balance workloads across cloud, on-premises, and isolated environments. With features like GPU fractioning and model packing, resource allocation becomes more efficient. Companies that implement these tools, along with autoscaling, have reported cutting compute costs by over 70%.
The platform’s scale-to-zero feature is designed for various infrastructures, automatically shutting down idle model replicas and compute nodes. This ensures businesses only pay for resources when they are actively in use. Depending on the configuration, users can save at least 60%, with some achieving up to 90% savings. Additionally, the integrated Reasoning Engine processes 544 tokens per second at a cost of approximately $0.16 per million tokens.
These capabilities directly address rising AI compute costs, offering a transparent, usage-based pricing structure that aligns with actual resource consumption.
Platform C uses a consumption-based pricing approach, factoring in compute hours, the type of GPU/CPU used, and the number of tokens processed. The Shared SaaS model offers a fully managed, serverless environment without infrastructure maintenance costs for curated models. Businesses opting for the Self-Managed VPC model can utilize their existing cloud provider credits and reserved instances while keeping full control over their infrastructure.
This pricing model is adaptable, aligning with different deployment needs and infrastructure investments.
Platform C addresses inefficiencies found in older AI platforms by offering six deployment options that prioritize simplified management and real-time monitoring:
A centralized Control Center ties all deployment options together, enabling real-time tracking of performance, costs, and usage. This ensures businesses can manage their AI expenses efficiently and with full visibility.
Tackling the challenge of reducing AI compute spending by 65% requires innovative approaches, and these platforms bring distinct strategies to the table. prompts.ai stands out by consolidating over 35 leading models into a single interface, cutting AI software expenses by up to 98% through its pay-as-you-go TOKN credit system. Its real-time FinOps controls provide detailed token-level visibility and simplify cost tracking, helping teams manage spending without juggling multiple subscriptions. However, organizations locked into specific cloud ecosystems may need to adjust workflows to fully integrate.
Platform B leverages Kubernetes-native management and spot GPU optimization to deliver up to 70% savings on compute costs. This is achieved through automated provisioning and hibernation processes. Its unified AI Gateway simplifies the handling of multiple model APIs while ensuring compliance with SOC2, HIPAA, and GDPR standards. On the downside, teams must place trust in its autonomous decision-making and navigate the learning curve associated with Kubernetes orchestration.
Platform C prioritizes deployment flexibility, offering options from shared SaaS environments to more secure, isolated setups. Its scale-to-zero capability can reduce compute costs by 40–60%. However, achieving peak performance often requires custom configurations for CPU-only workloads, and its abstractions may take time to master.
These platforms highlight the importance of an interoperable AI workflow platform in reducing costs. The right choice depends on whether your priorities lie in model consolidation, GPU optimization, or deployment flexibility.
Reducing AI costs requires aligning tools and strategies with your specific workload and scale. prompts.ai simplifies this process by integrating 35 models into a single ecosystem, using a pay-as-you-go TOKN system paired with real-time FinOps controls. This setup minimizes software expenses, eliminates redundant subscriptions, and ensures precise cost tracking, giving organizations complete spending visibility.
Beyond cost savings, automation and infrastructure efficiency play a key role. For example, Platform B excels in optimizing Kubernetes environments with features like spot optimization and automated hibernation for high-volume GPU workloads. Meanwhile, Platform C caters to teams needing flexible deployment options, offering both shared SaaS and isolated environments with scale-to-zero capabilities, though it requires more hands-on setup.
These tailored solutions address a range of needs: small businesses gain seamless access to multiple models without juggling subscriptions, regulated enterprises benefit from built-in governance and audit trails, and solo users can tap into advanced models without separate fees. Together, these options transform AI spending from a hidden drain into a strategic opportunity.
With over 90% of executives acknowledging AI's potential for cost reduction within the next 18 months - and 84% noting its impact on gross margins - success hinges on visibility and control. prompts.ai brings it all together with model access, cost tracking, and workflow optimization in one platform. This approach ensures organizations know exactly where their dollars go, turning AI expenses into a calculated investment that drives results.
To get a handle on AI inference costs before scaling, start by examining token usage, latency, and operational expenses. Break down token consumption for each request and factor in how batching, caching, and your choice of model can influence costs. Tools like inference cost calculators can help you project these expenses more accurately. Also, selecting the appropriate inference method - whether it’s real-time, serverless, or asynchronous - based on your workload patterns can help keep costs under control and prevent surprises as you scale.
The most effective way to cut costs on idle GPU resources is by using autoscaling solutions like scale-to-zero. These tools automatically deactivate GPUs when they’re not in use, ensuring you’re not paying for unused capacity. Examples include Kubernetes tools, serverless inference models, and cloud services with built-in autoscaling features. This method helps you pay only for active usage, eliminating unnecessary spending.
You can monitor AI spending by team or project in real time using platforms like Prompts.ai. With features like detailed token usage tracking, cost attribution, and live monitoring, it helps you manage expenses effectively and keep budgets on track.


















