Pay As You Go - AI Model Orchestration and Workflows Platform


Artificial intelligence is reshaping how businesses operate, and by 2026, evaluating large language models (LLMs) will be critical for ensuring reliability, security, and performance. Traditional testing methods simply don’t work for LLMs, which can produce unpredictable outputs and exhibit biases. This has led to the rise of specialized evaluation platforms designed to handle the complexity of modern AI systems.
Here are five leading platforms to consider for LLM evaluation in 2026:
These platforms address different needs, from enterprise-scale orchestration to developer-friendly debugging. Whether you prioritize cost visibility, advanced metrics, or seamless workflow integration, choosing the right tool will help you maximize the value of your AI initiatives.
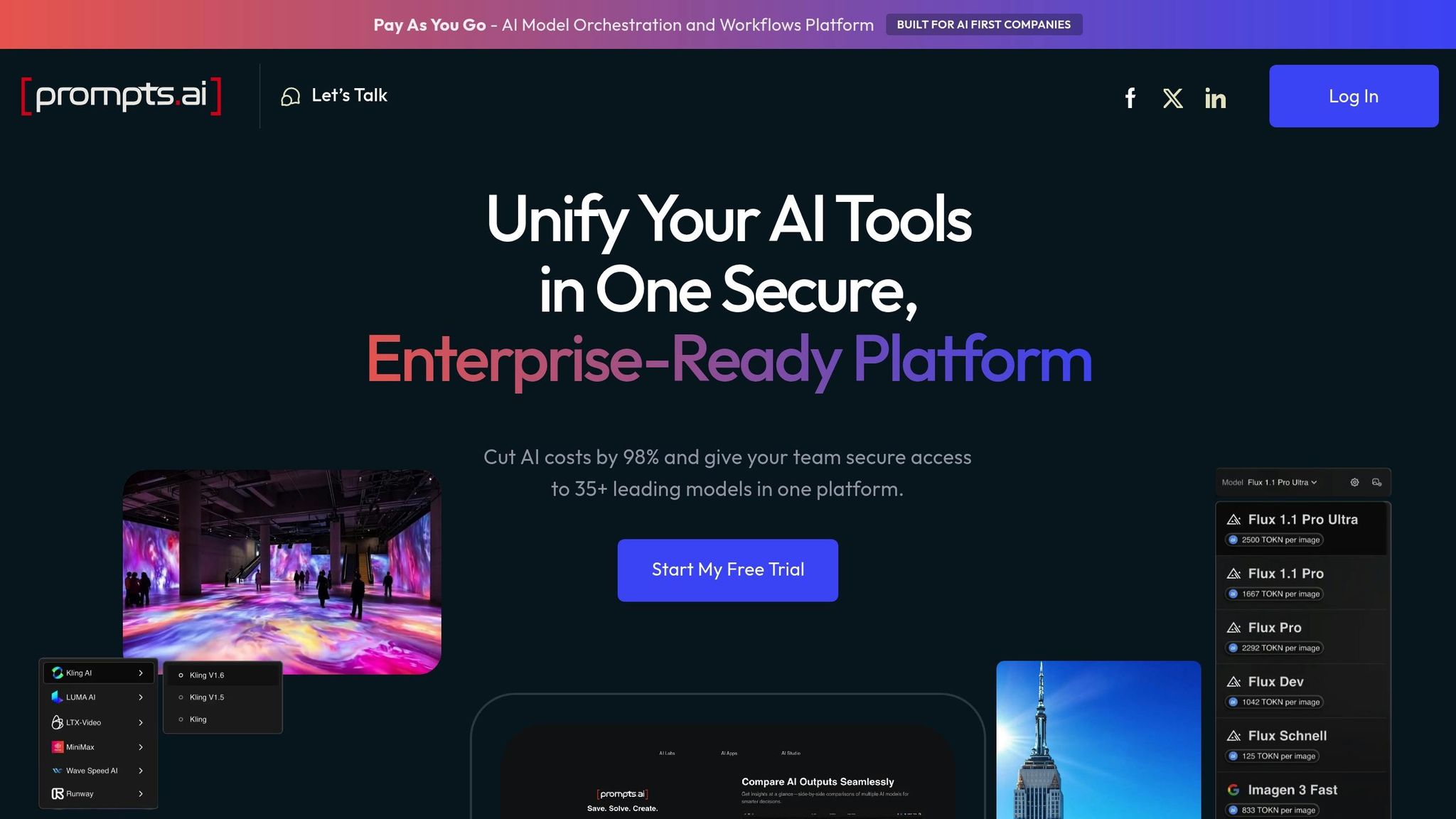
Prompts.ai is a platform designed to simplify how organizations evaluate and deploy large language models (LLMs) on a large scale. Instead of managing multiple disconnected tools, teams can tap into over 35 AI models through a single, secure interface that simplifies governance, reduces costs, and streamlines workflows. Below, we’ll explore the platform’s standout features and how it reshapes AI model evaluation.
Prompts.ai brings together models like GPT-4, Claude, Llama, and Gemini under one roof, making it easy for teams to compare and evaluate their performance. By consolidating access to these models, it eliminates the hassle of maintaining separate subscriptions and navigating multiple interfaces. With side-by-side comparisons, teams can identify the best-performing model for their specific needs with minimal effort.
The platform offers detailed analytics and reporting tools across its pricing plans. These tools allow users to benchmark multiple models using identical prompts and datasets, simplifying the decision-making process. The ability to compare performance metrics in real time ensures that teams can select and deploy the most effective models for their projects.
Prompts.ai stands out for its ability to automate and standardize workflows across departments. It integrates seamlessly with widely-used business tools such as Slack, Gmail, and Trello, enabling teams to quickly automate repetitive tasks. For businesses on the platform’s advanced plans, the interoperable workflows feature ensures smooth collaboration within existing enterprise systems, enhancing productivity.
With its pay-as-you-go TOKN credit system, Prompts.ai offers clear and transparent cost management, helping organizations cut software expenses by up to 98%. This approach provides full visibility into AI spending across teams and projects, allowing businesses to maximize their investments while avoiding hidden fees that often come with managing multiple vendors.
Security is a top priority for Prompts.ai. The platform includes built-in audit trails and governance tools, making it particularly suited for regulated industries. By centralizing security protocols and providing full visibility into all AI interactions, Prompts.ai ensures that every model evaluation and deployment complies with established standards. This reduces the compliance challenges that often arise when using multiple platforms with inconsistent security measures.
DeepEval serves as a specialized framework designed to evaluate and debug large language model (LLM) applications. Its developer-focused approach treats evaluations like unit tests, making it easy to integrate with standard testing frameworks.
DeepEval provides more than 14 targeted metrics tailored for both Retrieval-Augmented Generation (RAG) and fine-tuning scenarios. These metrics are regularly updated to align with the latest advancements in LLM evaluation. They address critical areas such as G-Eval, Summarization, Hallucination, Faithfulness, Contextual Relevancy, Answer Relevancy, Contextual Recall, Contextual Precision, RAGAS, Bias, and Toxicity. What sets these metrics apart is their "self-explaining" nature, offering detailed insights into why a score falls short and how it can be improved - making debugging significantly easier. Additionally, DeepEval supports evaluations for RAG systems, AI agents, and conversational LLMs.
Designed with flexibility in mind, DeepEval allows users to combine modular components to create custom evaluation pipelines. Its compatibility with Pytest enables developers to treat evaluations as unit tests, seamlessly integrating them into continuous integration and deployment processes. Teams can also generate synthetic datasets from their knowledge base or utilize pre-existing datasets, simplifying the testing workflow.
Deepchecks is designed to zero in on the core performance of models, steering clear of evaluating complete LLM applications. The platform places a strong emphasis on visual analysis, using dashboards to give teams a detailed look at how their models perform. Unlike DeepEval, which employs a modular strategy, Deepchecks is entirely focused on analyzing the intrinsic performance of models.
Deepchecks prioritizes metrics that are crucial for understanding a model's capabilities. This approach sets it apart from platforms that focus on application-level evaluations, such as those used for retrieval-augmented generation or fine-tuning. It’s a go-to tool for teams aiming to dive deep into the fundamental abilities of their models.
Deepchecks provides an open-source solution, leveraging visual dashboards to present performance data in a clear and organized way. While these dashboards simplify the interpretation of complex metrics, setting up the platform requires technical know-how. Teams should account for this complexity when planning their timelines and allocating resources.

MLflow LLM Evaluate simplifies experiment management by logging hyperparameters, code versions, and evaluation metrics. Instead of providing an extensive library of pre-built metrics, it focuses on organizing and managing the evaluation process, making it an excellent choice for teams aiming for systematic experiment tracking and management.
MLflow LLM Evaluate is tailored for use cases like Retrieval Augmented Generation (RAG) and Question Answering (QA). It’s particularly effective in applications such as conversational AI, knowledge bases, and document retrieval. Designed specifically for assessing LLM models, it shines in question-answering scenarios, utilizing the model_type="question-answering" feature.
This makes it an ideal solution for teams working on conversational AI systems or applications where RAG and QA functionalities are critical to performance.
While MLflow tracks parameters and metrics as part of its experiment management, it requires teams to integrate their own custom or third-party evaluation libraries for a more thorough assessment of LLMs.
The platform’s flexibility is its key advantage - teams can adopt any custom evaluation framework that suits their specific needs. However, this also means organizations must bring their own evaluation metrics or rely on external libraries to fully assess their models.
Integrating MLflow into existing workflows is straightforward with a simple mlflow.evaluate call. This logs parameters, metrics, code versions, and artifacts, ensuring reproducibility and consistency across experiments.
This streamlined approach allows teams to compare test configurations effectively and identify the best-performing setups. Additionally, MLflow’s Projects feature helps maintain reproducibility across different environments by standardizing dependencies and workflows. Its model lifecycle management tools, including version control and stage transitions, align perfectly with the iterative nature of LLM development.
Jonathan Bown, MLOps Engineer at Western Governors University, noted that combining Evidently with MLflow significantly sped up test provisioning and provided greater flexibility for customizing tests, metrics, and reports.
For organizations with established MLOps workflows, MLflow adds value by extending existing infrastructure to include robust LLM evaluation capabilities.
TruLens is designed to assess the performance of large language models (LLMs) within specific, real-world applications. By focusing on Retrieval-Augmented Generation (RAG) and agent-based systems, it tackles the unique challenges these use cases present, offering insights tailored to practical implementation scenarios.
TruLens specializes in evaluating RAG applications and agent-based systems. This targeted approach ensures that performance assessments align closely with the demands of diverse real-world use cases.
In addition to its evaluation tools, TruLens supports developers with a range of educational resources. Through DeepLearning.AI, users can access courses and workshops that demonstrate how to effectively utilize TruLens for testing RAG and agent-based applications. This makes it easier to incorporate TruLens into existing development workflows.
When selecting an LLM evaluation platform, it’s important to weigh how each option aligns with your workflow needs and budget considerations. The table below breaks down the standout features of Prompts.ai, a trusted solution for LLM evaluation and orchestration:
| Platform | Supported LLMs | Primary Evaluation Focus | Workflow Integration | Cost Structure | Security & Compliance |
|---|---|---|---|---|---|
| Prompts.ai | 35+ models, including GPT-5, Claude, LLaMA, Gemini | Unified model comparison, performance benchmarking, and cost efficiency | Enterprise-grade orchestration with real-time FinOps tracking | Pay-as-you-go TOKN credits; no recurring fees | Enterprise-level governance, audit trails, and data protection |
This table highlights Prompts.ai’s standout capabilities, which are further explored below. One of the platform’s key advantages is its cost transparency. The pay-as-you-go TOKN credit system ensures you only pay for what you use, eliminating recurring fees and making budgeting straightforward.
Prompts.ai also prioritizes enterprise-level security, offering robust governance, detailed audit trails, and strong data protection measures. With support for over 35 top-performing LLMs, the platform empowers users to compare models side by side, enabling smarter decisions that maximize productivity and drive measurable ROI.
Choosing the right LLM evaluation platform in 2026 means finding one that matches your organization's specific requirements. With a range of options available, each offering distinct advantages in model compatibility, evaluation capabilities, and cost transparency, it's essential to weigh your priorities carefully.
Start by considering model coverage. Platforms like Prompts.ai, which support over 35 models, allow for thorough comparisons, helping you identify the best-performing solution for each unique use case.
Look for platforms with straightforward, pay-as-you-go pricing models. This structure ties costs directly to usage, avoiding unexpected expenses and simplifying budget management.
Next, evaluate the depth of the platform's assessment tools. Features like detailed metrics, real-time FinOps tracking, and secure audit trails are critical, especially for organizations managing sensitive data. Platforms with built-in compliance capabilities can ensure your workflows remain secure and efficient.
Finally, focus on solutions that offer enterprise-grade orchestration to unify your AI workflows. From testing to deployment, such platforms minimize tool sprawl and enhance team collaboration, streamlining the entire process.
The platform you select will directly influence your team's ability to evaluate, implement, and refine LLMs throughout the year. Carefully assess which combination of model support, pricing structure, and workflow integration best aligns with your AI strategy and long-term goals.
When selecting an LLM evaluation platform in 2026, it's essential to focus on key features that align with your organization's goals. Ensure the platform offers a wide range of metrics to evaluate performance across various use cases and includes RAG-specific capabilities (Retrieval-Augmented Generation) for handling advanced workflows. Pay close attention to strong security measures to protect sensitive data and dataset versioning to maintain consistency and reproducibility in results. These elements are crucial for evaluating performance, ensuring reliability, and assessing integration possibilities.
Prompts.ai comes equipped with a FinOps layer that offers real-time visibility into your AI usage and spending. This feature keeps tabs on costs across various workflows, enabling you to track ROI and manage expenses with precision.
With clear insights into how resources are allocated and utilized, Prompts.ai simplifies budget management. It ensures your AI projects remain cost-efficient while maintaining top-notch performance.
DeepEval offers a robust suite of over 30 prebuilt metrics designed to evaluate large language models (LLMs) across critical dimensions such as accuracy, relevance, factual consistency, coherence, and safety. Beyond these, it supports sophisticated testing approaches, including red-teaming simulations and unit-test-style assertions, allowing for in-depth debugging and performance analysis. These capabilities make it an invaluable resource for verifying that your LLMs deliver reliable and effective results.


















