Pay As You Go - AI Model Orchestration and Workflows Platform


Choosing the right tool to compare large language models (LLMs) is critical for balancing performance, cost, and workflow efficiency. With AI expenses rising, businesses need reliable platforms to evaluate models like GPT-4, Claude, and Gemini. This guide breaks down seven tools that simplify LLM selection by analyzing response quality, costs, and integration potential.
| Tool | Strengths | Weaknesses | Cost Transparency | Integration Ease |
|---|---|---|---|---|
| Prompts.ai | 35+ models, cost reduction (98%) | None identified | Excellent | High |
| Deepchecks | Strong validation, secure | Steep learning curve | Good | Medium |
| LLMbench | Simple setup | Limited customization | Fair | High |
| MLflow | Experiment tracking, open-source | High maintenance | Good | Medium |
| Scout LLM | User-friendly, quick deployment | Less analytical depth | Fair | High |
| PAIR LLM | Bias detection | Narrow focus | Fair | Medium |
| SNEOS | - | Limited documentation | Poor | Unknown |
For cutting costs and managing multiple models, Prompts.ai stands out. Meanwhile, MLflow and Deepchecks cater to technical teams requiring in-depth analysis. Simpler tools like Scout LLM and LLMbench suit organizations seeking ease of use. Choose the platform that aligns with your goals, whether it’s saving on expenses or improving AI evaluation accuracy.
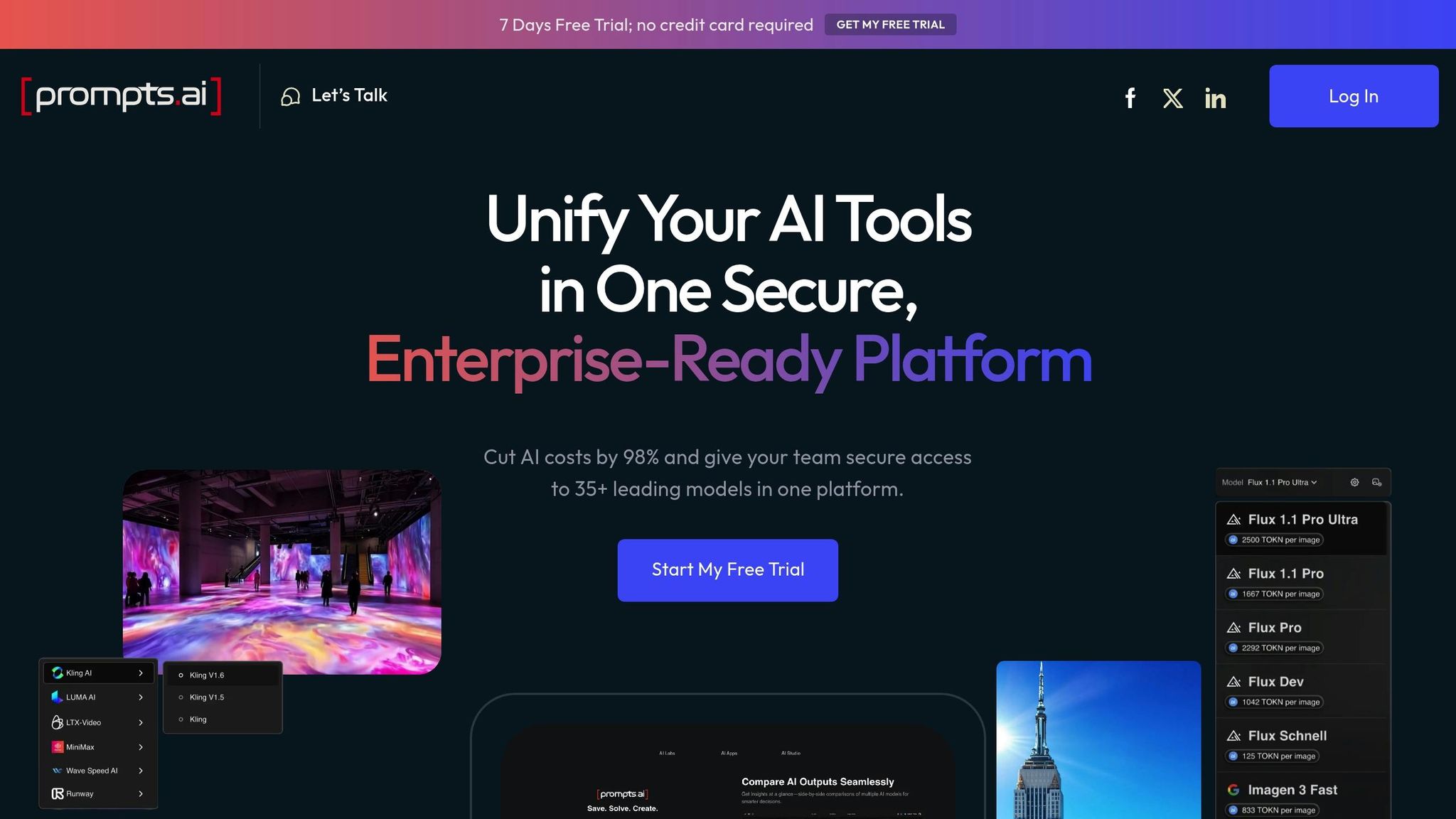
Prompts.ai brings together over 35 leading LLMs into one secure and unified platform. By doing so, it eliminates the hassle of managing multiple subscriptions and tackles the growing issue of AI tool sprawl that many enterprises encounter as they scale their AI operations.
The platform is tailored for Fortune 500 companies, creative agencies, and research labs, simplifying the management of AI vendor relationships. With Prompts.ai, teams can compare model outputs side-by-side without juggling various platforms or maintaining separate API keys for each provider.
Prompts.ai allows users to conduct side-by-side comparisons of model performance across its extensive library. By submitting the same prompt to multiple models, teams can evaluate responses based on accuracy, relevance, and specific task requirements. Detailed logs provide an audit trail, helping users identify the best-performing models for their needs.
The platform also includes pre-built prompt workflows created by expert engineers. These templates serve as a reliable starting point for common business tasks, ensuring consistent results across team members. Organizations can further customize these workflows to align with their unique needs and branding.
Beyond simple text comparisons, Prompts.ai monitors response consistency over time. This feature helps teams identify when models start producing inconsistent results for similar inputs, a critical capability for maintaining reliable workflows in production environments.
These features lay the groundwork for robust performance tracking.
Prompts.ai offers a detailed view of performance metrics that go beyond basic response times. Teams can track token usage, speed, and availability across all integrated models, providing valuable insights into which models deliver the best results for specific workloads.
The platform also analyzes usage patterns at both individual and team levels, offering a clearer picture of how various departments are leveraging AI models. This data-driven approach allows organizations to refine their AI strategies based on actual usage rather than assumptions.
Additionally, the platform measures productivity gains, with its streamlined workflows driving noticeable improvements. Performance dashboards provide managers with key metrics, enabling them to monitor ROI and pinpoint areas for further optimization.
On top of quality and performance, Prompts.ai ensures financial clarity.
A standout feature of Prompts.ai is its FinOps layer, offering complete visibility into AI-related expenses. By eliminating redundant subscriptions and optimizing model selection based on real-world performance, the platform significantly reduces AI software costs.
The Pay-As-You-Go TOKN credits system replaces traditional monthly fees, aligning costs with actual usage. Organizations only pay for the tokens they consume, making it easier to predict and control expenses. This model is especially beneficial for companies with fluctuating AI workloads or those just beginning their AI journey.
Detailed cost tracking shows exactly how much each prompt, project, or team member contributes to overall expenses. This level of transparency helps finance teams allocate budgets effectively and enables project managers to stay on track. By tying spending directly to business outcomes, the platform makes it easier to justify AI investments and demonstrate their value.
Prompts.ai is designed for seamless scalability. Organizations can add new models, users, and teams within minutes, avoiding lengthy procurement and integration processes. This agility is essential for businesses needing to adapt quickly to evolving demands or the latest AI advancements.
The platform integrates smoothly with existing enterprise systems via APIs and webhooks, enabling teams to incorporate AI capabilities into their workflows with minimal disruption. Its user-friendly interface accommodates both technical and non-technical users, ensuring accessibility for a variety of roles and use cases.
Scalability also extends to model management. When new LLMs become available, Prompts.ai integrates them rapidly, giving users access to cutting-edge AI capabilities without requiring additional vendor relationships or technical setup. This streamlined process enhances the platform’s role in comprehensive LLM evaluation.
For enterprises, secure and compliant AI operations are non-negotiable. Prompts.ai offers enterprise-grade security features to protect sensitive data throughout the AI workflow. The platform maintains audit trails for every interaction, ensuring compliance with industry regulations. Organizations can track who accessed specific models, what prompts were used, and how the results were applied.
Governance tools allow administrators to define usage policies, spending limits, and access controls at a granular level. These controls enable organizations to enforce consistent AI practices across teams while preserving the flexibility needed for experimentation and innovation.
This robust security framework empowers companies to harness advanced AI capabilities without compromising on data privacy or compliance standards.
Deepchecks prioritizes the protection of sensitive data through advanced measures like anonymization - using masking and pseudonymization - and robust encryption for both stored data and data in transit. These safeguards are designed to prevent unauthorized access and potential breaches.
To further ensure data security, Deepchecks implements role-based access controls, restricting data visibility to only those who need it. Regular audits are conducted to maintain compliance, uncover potential vulnerabilities, and uphold the system's security. Additionally, Deepchecks advises on creating a detailed incident response plan to quickly and effectively address any breaches that may occur. Together, these steps not only secure critical information but also reinforce the reliability of model evaluations.
This commitment to rigorous data protection sets Deepchecks apart from other tools in the LLM comparison space.
LLMbench reveals very little about its methodologies and specifications, leaving many aspects uncertain. Below, we explore the key areas of LLMbench based on the limited information available.
Details about how LLMbench evaluates performance are sparse. It does not provide clear benchmarks or structured measurement standards, making it difficult to assess its evaluation framework.
The platform offers no substantial information about how it integrates with AI workflows or whether it can handle high-volume, enterprise-level evaluations. This lack of clarity raises questions about its adaptability for larger-scale operations.
Information about LLMbench's security measures and governance practices is equally limited. Prospective users may need to conduct additional inquiries to ensure it meets data protection and compliance requirements.
The platform's lack of transparency sets it apart from others, highlighting the importance of thorough evaluation before considering LLMbench for your workflow.
MLflow provides an open-source solution for tracking experiments and managing the machine learning lifecycle, making it a valuable tool for evaluating large language models (LLMs). Originally developed by Databricks, MLflow simplifies the process of logging experiments, managing models, and comparing outputs across various AI systems. Its adaptable design allows users to log custom metrics and track experiments in detail, making it a practical choice for evaluating LLM outputs. By offering robust tracking and integration capabilities, MLflow ensures a more streamlined approach to comparing LLM performance.
MLflow offers a clear framework for logging and evaluating performance metrics. Standard measures such as BLEU scores, ROUGE metrics, and perplexity values for text generation tasks can be easily recorded. Additionally, users can define custom evaluation functions to assess specific qualities like factual accuracy or response relevance. The platform's experiment tracking feature enables teams to log metrics across multiple model runs, which is especially helpful when testing various prompt strategies. These detailed metrics integrate smoothly into existing workflows, supporting comprehensive evaluations.
MLflow is designed to work seamlessly with popular machine learning frameworks, including TensorFlow, PyTorch, and Hugging Face Transformers, through its REST API and Python SDK. It also supports distributed computing environments like Apache Spark and Kubernetes, making it well-suited for large-scale evaluations. For enterprise use, MLflow’s model registry simplifies versioning and central management of different model implementations, allowing teams to track performance over time. This scalability ensures efficient evaluations while maintaining compatibility with enterprise infrastructures.
Enterprise security is a key focus for MLflow, which incorporates role-based access controls and audit logging to meet organizational requirements. The platform integrates with existing authentication systems, such as LDAP and OAuth, ensuring alignment with security policies.
MLflow also supports model governance by tracking lineage and maintaining a history of model development. This transparency is critical for compliance, offering clear insights into how LLM outputs are generated and validated. Additionally, MLflow’s deployment flexibility allows organizations to run evaluations entirely on their own infrastructure, addressing concerns about data privacy and sensitive information handling.
The Scout LLM Model Comparison Tool is designed to evaluate outputs from language models across a variety of use cases, specifically tailored for enterprise needs. It empowers organizations to make informed decisions by analyzing which models are best suited for specific tasks. With a strong focus on transparency in evaluation, Scout offers detailed reporting features that benefit both technical teams and business stakeholders, making it easier to understand the differences in model performance. While transparency is a shared goal with earlier tools, Scout stands out for its detailed analysis of both costs and performance.
Scout goes beyond conventional metrics when assessing output quality. It evaluates factors like response coherence, factual accuracy, and contextual relevance using automated scoring systems, which are further enhanced by human reviews. A key feature is its semantic similarity analysis, which measures how closely model outputs align with expected results across various domains.
The tool breaks down quality insights to pinpoint where models excel or fall short. For tasks like content creation, Scout assesses creativity, tone consistency, and adherence to style guidelines. For analytical tasks, it examines logical reasoning, data interpretation accuracy, and the validity of conclusions. These detailed evaluations give teams a clear understanding of each model's strengths and weaknesses, not just overall performance.
Scout features a metrics dashboard that tracks both standard and custom performance indicators. It automatically calculates widely-used NLP metrics such as BLEU, ROUGE, and F1 scores, while also accommodating domain-specific evaluation needs. Beyond these, Scout monitors response times, token consumption, and computational resource usage.
The platform incorporates statistical significance testing to ensure that observed performance differences between models are meaningful rather than random. With trending analysis, Scout highlights performance changes over time, helping teams identify patterns of improvement or degradation. Additionally, it provides insights into model efficiency, offering a well-rounded view of performance.
Scout’s cost analysis tools offer a clear view of financial implications tied to model usage. It tracks token consumption, API call frequencies, and associated costs, enabling organizations to evaluate the economic impact of their choices. Cost projections help estimate expenses for scaling deployments based on current usage.
The platform includes budgeting tools that allow teams to set spending limits and receive alerts when usage nears these thresholds. Scout also provides recommendations for cost optimization by analyzing performance-to-price ratios across different models.
Scout integrates effortlessly with existing development workflows through its REST API and SDK support for popular programming languages. It connects with major cloud providers and model hosting platforms, enabling evaluations regardless of deployment location. Integration with CI/CD pipelines allows automated model comparisons to be embedded directly into development processes.
Its scalable architecture supports simultaneous evaluations of multiple models and datasets. With distributed processing, Scout reduces the time needed for large-scale comparisons. It can handle structured and unstructured data inputs, making it highly adaptable for diverse evaluation needs. This robust integration is complemented by stringent security features.
Scout ensures enterprise-grade security with end-to-end encryption for data both in transit and at rest. It supports single sign-on integration with corporate identity systems and provides audit logs for all evaluation activities. Role-based access controls restrict sensitive data and results to authorized personnel only.
The platform’s governance framework includes compliance tracking to help organizations meet regulatory requirements for AI evaluation and documentation. Scout maintains detailed records of methodologies, data sources, and results, ensuring transparency and accountability in model selection. Additionally, its data residency options allow organizations to store evaluation data within specific geographic regions or on-premises infrastructure, addressing data sovereignty concerns effectively.
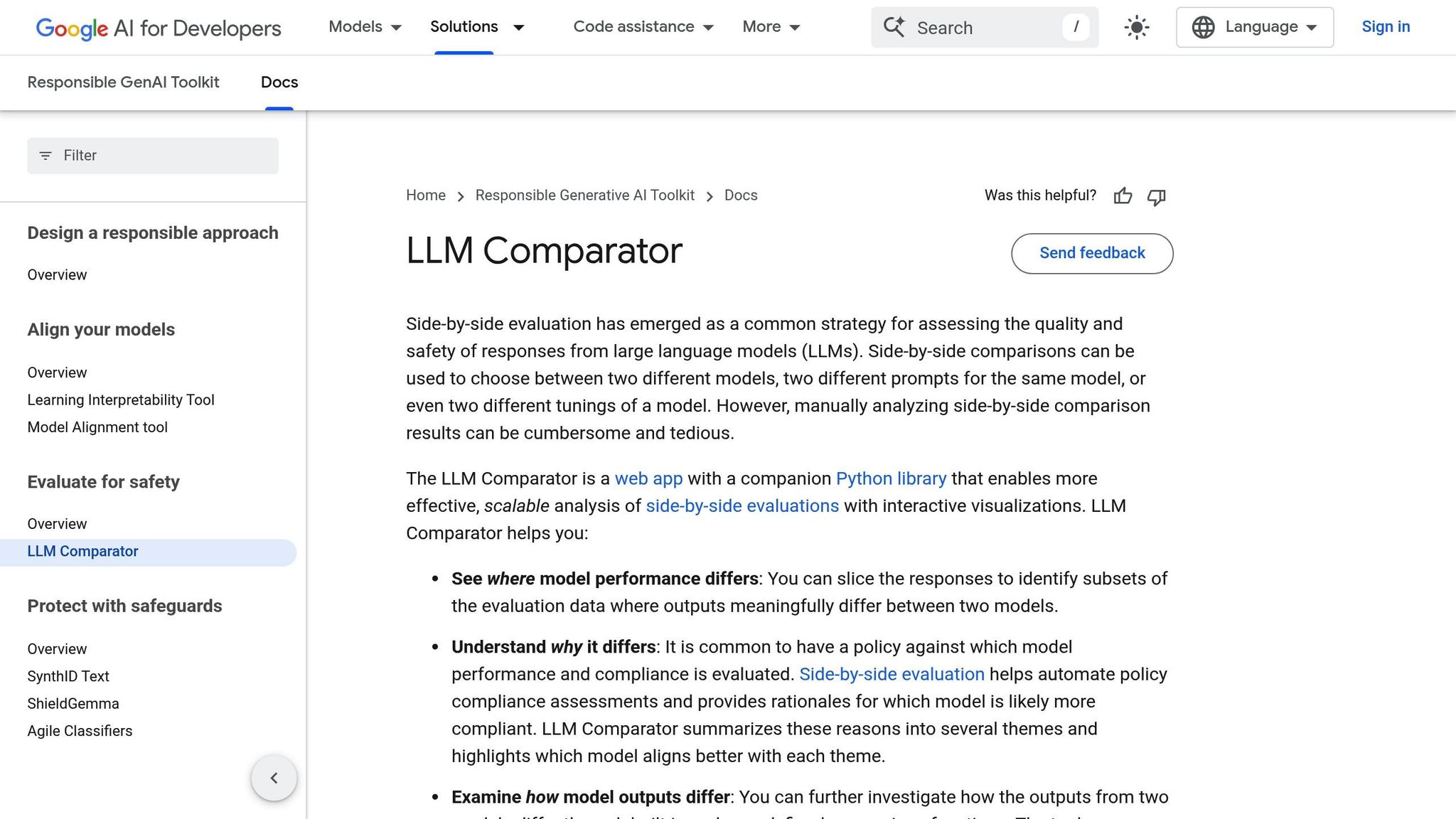
The PAIR LLM Comparator simplifies the process of evaluating language models, offering developers an efficient and user-friendly tool. This system integrates directly into AI workflows, ensuring smooth operation. At its core is a Python library (llm-comparator, available on PyPI) that works with standardized JSON inputs. This allows users to upload their evaluation results for detailed visualization and analysis.
The tool provides two main options: users can either create a comprehensive JSON file featuring side-by-side model comparisons and grouped rationale clusters or focus on clustering rationale from existing outputs. This flexibility makes it easier to conduct thorough, scalable evaluations of language models, adapting to different project needs.
SNEOS does not appear to function as a dedicated tool for comparing LLM outputs. Its lack of documented features and capabilities creates challenges when attempting to evaluate it alongside more established tools.
There is no published methodology or data from SNEOS regarding how it measures the quality of LLM outputs. In contrast, widely recognized frameworks rely on metrics like BLEU scores, ROUGE metrics, and human preference rankings to assess performance. Without such information, it becomes difficult to gauge how SNEOS handles quality evaluation or to compare its effectiveness to other tools that provide detailed analysis.
SNEOS does not provide any performance metrics, leaving its evaluation capabilities ambiguous. The absence of this information makes it unclear how well the tool performs or whether it can meet the needs of users looking for reliable benchmarks.
SNEOS does not offer any technical documentation regarding integration or scalability. Established platforms typically provide API access, compatibility with multiple model formats, and smooth integration into existing workflows, all of which are critical for handling large-scale operations. Without similar details, it is impossible to determine whether SNEOS can accommodate enterprise-level demands.
Compared to the more transparent and feature-rich platforms discussed earlier, SNEOS's limited documentation highlights the importance of providing clear and detailed information for effective LLM evaluation.
To complement the detailed reviews of each tool, here's a concise comparison of their strengths and challenges. Each tool brings distinct benefits and trade-offs, making them suitable for different needs.
Prompts.ai delivers a highly efficient approach to managing models and reducing costs. Its ability to cut AI expenses by up to 98% through a unified interface is a game-changer for organizations juggling multiple LLM subscriptions. Additionally, its pay-as-you-go TOKN credit system eliminates recurring fees, offering flexibility and cost control.
Deepchecks shines in its ability to offer thorough validation tailored for machine learning workflows. It excels in detecting data drift and monitoring model performance, all while integrating seamlessly with existing MLOps pipelines. However, its steep learning curve and the need for technical expertise can be a hurdle for some users.
LLMbench is ideal for teams new to LLM evaluations, thanks to its straightforward benchmarking setup and standard tests. It provides a consistent testing environment across models, but its limited customization options may not satisfy organizations with more specialized evaluation needs.
MLflow stands out for its robust experiment tracking and model versioning capabilities. As an open-source platform, it’s a cost-effective option for those with the technical resources to handle deployment and maintenance. However, its extensive setup and upkeep requirements can be a drawback.
Scout LLM Model Comparison Tool prioritizes ease of use with a user-friendly interface and quick setup. Its strong visualization tools allow for side-by-side model comparisons, but it may lack the analytical depth and scalability needed for enterprise-level operations.
PAIR LLM Comparator focuses on ethical AI evaluation, incorporating bias detection and fairness metrics. This makes it a valuable choice for organizations committed to responsible AI deployment. However, its narrower focus may necessitate additional tools for a more comprehensive performance analysis.
SNEOS faces challenges due to a lack of clear documentation and opaque features. Without transparent methodologies or established performance metrics, it’s difficult to gauge its effectiveness or confidently integrate it into workflows.
Here’s a summarized view of each tool’s key strengths, challenges, cost clarity, and ease of integration:
| Tool | Key Advantages | Main Disadvantages | Cost Transparency | Integration Ease |
|---|---|---|---|---|
| Prompts.ai | 35+ models, 98% cost reduction, enterprise features | None identified | Excellent | High |
| Deepchecks | Comprehensive validation, clear reports | Steep learning curve | Good | Medium |
| LLMbench | Simple setup, standard benchmarks | Limited customization | Fair | High |
| MLflow | Open-source, highly customizable | High maintenance overhead | Good | Medium |
| Scout LLM | User-friendly interface, quick deployment | Limited analytical depth | Fair | High |
| PAIR LLM | Ethical AI focus, bias detection | Narrow evaluation scope | Fair | Medium |
| SNEOS | - | Lack of documentation, unclear capabilities | Poor | Unknown |
This overview provides a clear snapshot of each tool’s capabilities, helping you align their features with your organization’s AI evaluation priorities. Choose the one that best matches your specific requirements.
Choosing the right LLM output comparison tool depends on aligning the platform's features with your organization's priorities and technical requirements. With many options available, it's crucial to identify what best supports your goals in AI evaluation and management.
For organizations focused on reducing costs and ensuring enterprise-level security, Prompts.ai offers a compelling solution. By consolidating access to over 35 models within a secure interface, it eliminates the need for multiple subscriptions and can cut costs by up to 98%. This streamlined approach ensures compliance and security without compromising functionality.
What sets Prompts.ai apart is its ability to simplify workflows while delivering exceptional results. As shared by an industry professional:
"An architect blending AI with creative vision, once had to rely on time-consuming drafting processes. Now, by comparing different LLM side by side on prompts.ai, allows her to bring complex projects to life while exploring innovative, dreamlike concepts."
- Ar. June Chow, Architect
However, different needs call for different tools. For organizations emphasizing technical depth and customization, platforms like MLflow offer robust experiment tracking, while Deepchecks provides detailed validation workflows. These options cater to teams with advanced technical expertise seeking granular evaluation capabilities.
For teams seeking simplicity or quick implementation, LLMbench and Scout LLM deliver user-friendly setups, making them ideal for newcomers to LLM evaluation. Additionally, companies prioritizing responsible AI practices may benefit from PAIR LLM Comparator, which focuses on bias detection and fairness metrics. That said, supplementary tools may be necessary for a comprehensive performance analysis.
Ultimately, factors such as cost efficiency, performance tracking, and integration capabilities should guide your decision. Consider how well a tool integrates with your existing systems, its ease of maintenance, and its scalability. By selecting the right platform, you can transition from scattered experiments to secure, repeatable processes that deliver consistent value.
Prompts.ai offers businesses a smarter way to manage AI software expenses with a centralized platform that integrates over 35 AI models. Using transparent pay-per-use pricing powered by TOKN credits, this system can slash costs by as much as 98%, making advanced AI tools both affordable and accessible.
Key features like real-time monitoring, cost tracking, and prompt versioning allow users to fine-tune their AI usage, eliminate wasteful spending, and simplify workflows. These capabilities help organizations cut operational expenses while ensuring their AI projects remain efficient and scalable.
Prompts.ai places a strong emphasis on protecting data and meeting compliance requirements by employing measures such as role-based access control (RBAC), real-time monitoring, and strict adherence to privacy standards like GDPR and HIPAA. These safeguards are designed to protect sensitive information while ensuring organizations remain compliant with regulatory mandates.
To further enhance security, Prompts.ai integrates AI governance tools that promote responsible data management and streamline workflows, all without sacrificing user privacy. This thorough strategy helps organizations confidently manage their AI-powered initiatives.
Prompts.ai strengthens the reliability and consistency of AI workflows with advanced output comparison tools. These tools allow users to evaluate different models and prompt variations side by side, simplifying the process of pinpointing the configurations that deliver the most stable and predictable results.
The platform also bolsters workflow dependability through features like governance tools, audit trails, and version control systems. These elements promote compliance, enhance transparency, and make managing AI projects more straightforward, empowering teams to deliver better results with assurance.


















