Pay As You Go - AI Model Orchestration and Workflows Platform


Machine learning orchestration is the backbone of efficient AI operations, automating tasks like data processing, model deployment, and monitoring. Without it, enterprises face high costs, compliance risks, and scaling challenges. Platforms like Prompts.ai simplify orchestration by unifying workflows, enforcing governance, and cutting costs by up to 98%.
Here’s what you need to know:
This approach transforms AI chaos into clarity, enabling enterprises to manage models efficiently while saving time and resources.
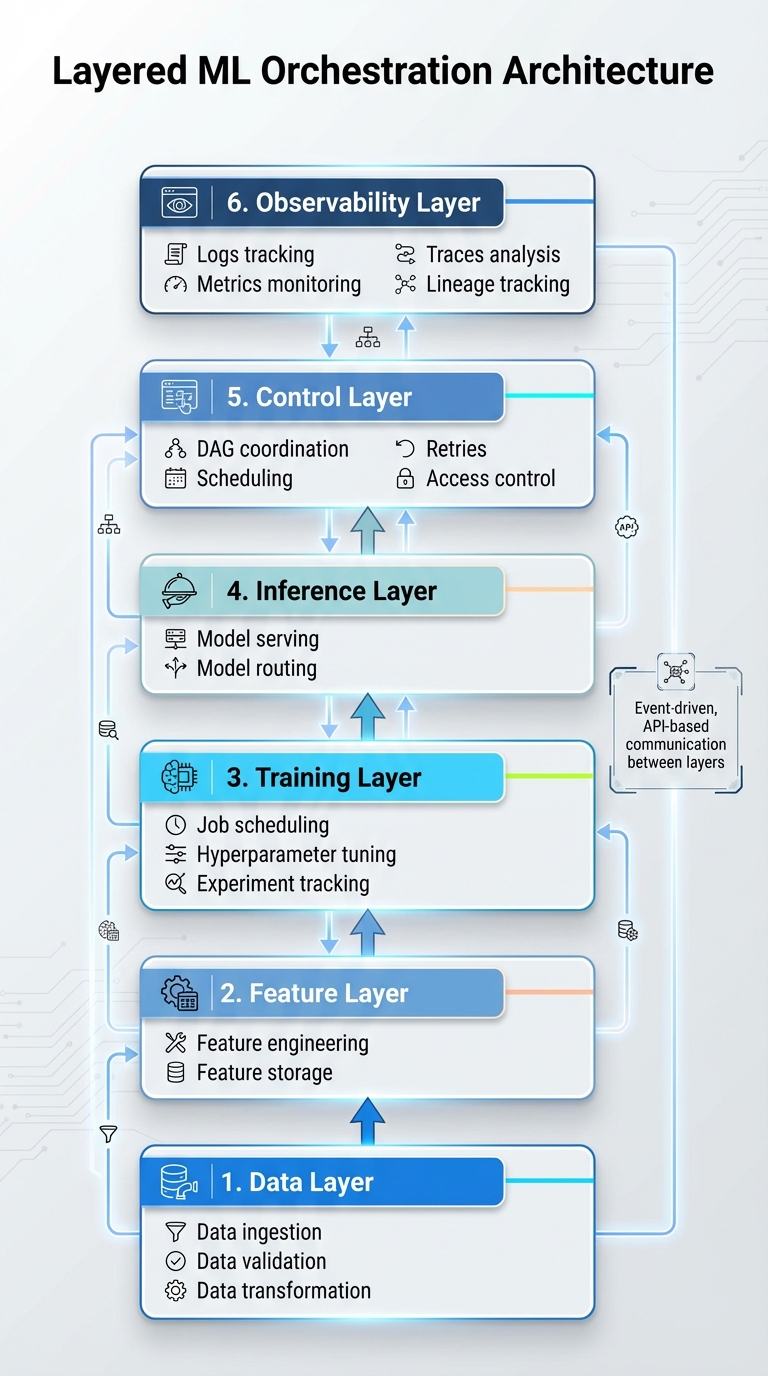
Machine Learning Model Orchestration: 6-Layer Architecture Framework
The orchestration system organizes its processes into six distinct layers: Data (handling ingestion, validation, and transformation), Feature (engineering and storage), Training (managing job scheduling, hyperparameter tuning, and experiment tracking), Inference (model serving and routing), Control (coordinating DAGs, scheduling, retries, and access control), and Observability (tracking logs, metrics, traces, and lineage).
This structure relies on microservices and an event-driven design, making each layer modular and easier to maintain. Instead of building a single, massive system, functionality is broken into smaller services - like data validation, feature generation, model training, inference, and monitoring - that communicate through APIs or messaging systems. For example, at a U.S. retail company, a nightly data ingestion process might trigger feature recalculations and automated retraining using queued messages. This modular setup enhances reliability, supports multi-cloud environments common in U.S. businesses, and allows teams to roll out updates incrementally with minimal disruption. Additionally, it enables precise management of workflow dependencies across these layers.
Directed Acyclic Graphs (DAGs) are key to organizing workflows. They break down tasks - such as data ingestion, validation, feature construction, training, evaluation, and deployment - into discrete steps, ensuring that each one only begins when upstream outputs meet predefined quality standards. By enforcing data and schema contracts, downstream processes are triggered only when upstream results align with set requirements. Instead of relying on a single, overly complex graph, smaller, domain-specific DAGs (for training, inference, or monitoring) linked by event triggers reduce operational risks and improve manageability.
To further ensure reliability, idempotency is achieved by using immutable, versioned artifacts with unique identifiers. Upsert operations prevent duplicates during retries or backfills, while detailed metadata and lineage tracking safeguard against unintended consequences during execution.
With clear dependency management in place, adopting interoperability standards simplifies model integration across various systems. Standards like REST APIs with OpenAPI ensure clarity in integration, gRPC supports high-performance internal communication, and messaging systems decouple producers and consumers for smoother workflows.
These standards allow teams to replace or upgrade models behind stable APIs without disruptions, dynamically route tasks to specialized models, and integrate third-party or in-house solutions under consistent API contracts and security protocols. For instance, Prompts.ai provides unified access to more than 35 leading AI models through a single interface, reducing tool sprawl and simplifying workflows. The platform also supports integrations with external applications like Slack, Gmail, and Trello, allowing teams to automate tasks across different systems seamlessly.
To make your orchestration architecture truly effective, strong deployment and scaling strategies are essential for smooth operations.
Containerizing models with tools like Docker and Kubernetes ensures consistent performance across different environments. Kubernetes takes care of orchestrating these containers, offering features like load balancing, rolling updates, and high availability. Models can be deployed in several ways: batch scoring for scheduled tasks, real-time inference using REST or gRPC for quick predictions, and canary releases to gradually direct traffic to new versions while monitoring their performance. Organizations that adopt thorough MLOps practices have reported deploying models 60% faster and experiencing 40% fewer production issues. These deployment techniques integrate seamlessly with your orchestration framework, providing both efficiency and reliability.
Horizontal autoscaling is a key strategy to match resources with demand, scaling model replicas based on metrics like request volume, CPU/GPU usage, or custom-defined parameters. Kubernetes automates this process, increasing pods when latency spikes and scaling down during quieter periods. Between 2022 and 2024, the cost of AI inference dropped 280-fold, making ongoing optimization both practical and cost-effective. Cost-aware routing is another valuable approach, directing simpler tasks to lightweight models while reserving resource-intensive models for more complex needs. Additionally, selecting the right instance types and using spot instances for workloads that can tolerate interruptions can significantly reduce costs. However, safeguards must be in place to handle spot instance interruptions effectively. These scaling strategies ensure a balance between performance and cost efficiency.
Maintaining system reliability requires proactive measures. Circuit breakers can block traffic to failing endpoints, while rate limiting prevents excessive requests from overwhelming the system. Regular health checks help identify and remove unresponsive instances, and retry logic with exponential backoff ensures failed requests are retried without overloading the system. Detailed logging provides visibility into system performance, helping to quickly address issues and maintain resilience. Together, these practices create a robust foundation for dependable operations.
Once your models are up and running, it’s crucial to maintain control, ensure smooth operations, and keep costs in check.
Keep an eye on your entire AI pipeline in real time with dashboards that track key metrics like response times, accuracy, resource usage, data freshness, and latency. Tools like Apache Airflow provide alerts for performance drops or data quality issues, so you can act quickly.
For instance, consider an e-commerce recommendation system. Dashboards monitor response times across multiple models, and if latency spikes, the system adjusts task distribution automatically to maintain performance. Features like retries, backfills, and Service Level Objectives (SLOs) are in place to prevent cascading failures. This real-time monitoring not only ensures smooth performance but also supports governance efforts to meet compliance standards.
Strong governance frameworks are essential for managing access, tracking versions, and maintaining compliance with regulations such as SOC 2 and HIPAA. By capturing metadata on experiments, datasets, and runs, you create clear audit trails. Tools like Airflow’s Open Lineage integration help trace data lineage across workflows, while containerization and secure credential handling keep sensitive information safe. This governance approach integrates seamlessly with the orchestration architecture discussed earlier.
Prompts.ai achieved SOC 2 Type 2 certification on June 19, 2025, showcasing its dedication to compliance and continuous monitoring. The platform’s Compliance Monitoring and Governance Administration features offer complete visibility and tracking for all AI activities. Every approval, rollback, and version update is systematically recorded, ensuring regulatory requirements are met while fostering trust. This robust governance model also supports financial oversight, aligning operational performance with cost management.
Understanding and managing costs is just as important as technical performance. By tracking model expenses in USD, organizations can directly tie AI spending to business goals. Real-time dashboards and budget alerts provide clarity, while cost-aware routing identifies inefficiencies, such as using overly complex models for simple tasks. Prompts.ai’s FinOps layer, powered by TOKN credits, allows businesses to monitor usage patterns and set budgets to avoid overspending.
One example of this efficiency: organizations have reduced AI costs by up to 98% by consolidating over 35 separate AI tools into a single platform. This shift transforms fixed costs into scalable, on-demand solutions. Regular resource allocation reviews ensure models are appropriately sized for their tasks. In geospatial annotation projects, orchestration distributes workloads across models to cut both processing costs and errors. By combining modular deployment with cloud integration for hybrid models, businesses ensure that every dollar spent translates into measurable gains, such as faster data processing and improved efficiency. This ongoing financial oversight strengthens the cost-saving benefits of Prompts.ai’s orchestration strategy.
Effectively managing machine learning (ML) models is crucial for ensuring dependable, cost-effective, and compliant AI operations. By employing layered orchestration frameworks, addressing workflow dependencies, and enabling seamless system interoperability, organizations can efficiently manage multiple models and data streams from start to finish.
Beyond the technical aspects, strong governance and thorough monitoring are the backbone of trustworthy AI systems. Comprehensive observability - tracking metrics like response times, accuracy, resource consumption, and costs - combined with adherence to standards such as SOC 2 and HIPAA, ensures regulatory compliance while simplifying issue resolution. These measures not only fulfill legal requirements but also instill confidence that AI systems perform as intended and contribute measurable value to the business.
Cost management rooted in FinOps principles further trims AI-related expenses. Scaling infrastructure dynamically based on demand, using lightweight models for simpler tasks, and monitoring spending in real time can significantly cut costs. Organizations leveraging unified orchestration platforms have seen notable savings by streamlining their tools and processes.
Prompts.ai takes this a step further by integrating over 35 leading AI models into a single platform. With built-in governance tools, compliance tracking, and a FinOps layer powered by TOKN credits, the platform offers complete visibility and auditability for all AI activities. This allows teams to deploy, scale, and optimize models without the chaos of juggling multiple tools.
The way forward is straightforward: implement orchestration strategies that combine technical efficiency with strong governance and clear cost management. By treating models as interconnected, orchestrated components rather than isolated tools, businesses can shift their focus to innovation and achieving meaningful outcomes, leaving infrastructure challenges behind.
Machine learning orchestration brings a range of benefits to refine and optimize your AI workflows. For starters, it enhances scalability, allowing you to efficiently manage and deploy multiple models across diverse environments. This ensures your systems can grow and adapt as demands increase.
It also improves efficiency by automating repetitive tasks and streamlining processes, saving both time and valuable resources. Beyond that, orchestration promotes collaboration by seamlessly integrating tools and workflows, making teamwork smoother and more effective.
Reliability is another advantage - real-time monitoring and optimization ensure your models perform consistently. Plus, it strengthens governance and compliance by providing clear oversight and control, giving you the confidence to meet regulatory standards without hassle.
A layered architecture breaks down machine learning workflows into distinct, manageable segments, ensuring a clear division of responsibilities. Each layer focuses on a specific task - whether it’s data preprocessing, model training, validation, deployment, or monitoring - allowing these functions to operate independently. This structure not only simplifies updates but also enhances scalability and makes troubleshooting far more efficient.
By segmenting workflows into layers, resources can be allocated more strategically, improving fault tolerance and streamlining version control. This organized method fosters smoother collaboration and supports the development of dependable AI systems that align with your goals.
To make scaling and deploying AI models smoother and more budget-friendly, prioritize automation, smart resource management, and real-time tracking. Incorporate tools like automated CI/CD pipelines to simplify deployment processes and cut down on manual tasks. Dynamic resource allocation ensures that computational power is used only when necessary, helping to avoid extra costs.
Set up real-time monitoring systems to keep an eye on model performance and resource consumption. This enables swift adjustments to optimize efficiency and manage expenses effectively. By integrating these approaches, you can build AI workflows that are scalable, dependable, and mindful of costs.



















