Pay As You Go - AI Model Orchestration and Workflows Platform


AI costs can quickly spiral out of control without proper oversight. This article compares five platforms - Prompts.ai, Finout, CAST AI, Holori, and Zesty - that help manage AI token usage and expenses. These tools track costs at a granular level, allocate budgets to teams or projects, and automate spending controls. Key features include real-time alerts, detailed cost attribution, and integrations with workflows like Jira or Slack. Choose the right platform based on your priorities, whether it's token-level tracking, infrastructure optimization, or automated cost management.
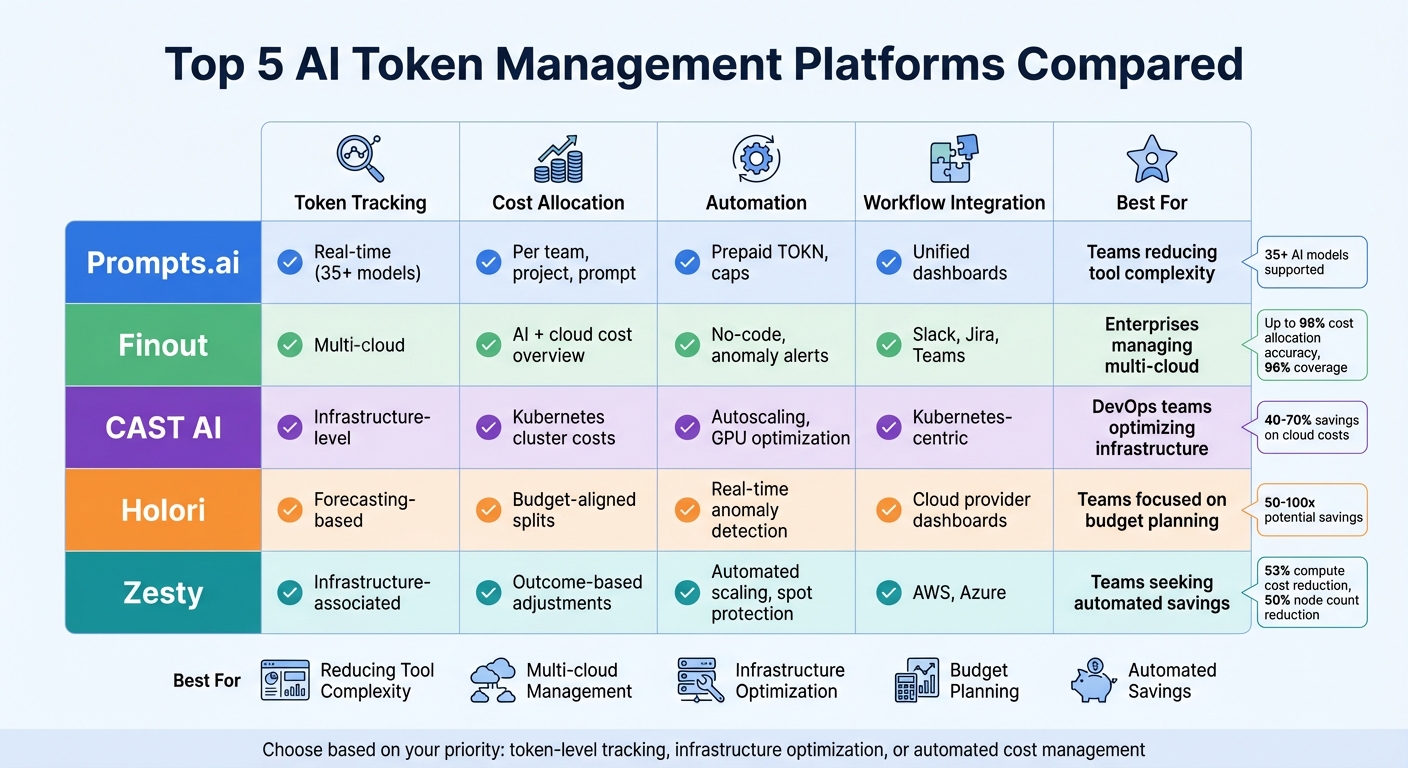
| Platform | Token Tracking | Cost Allocation | Automation | Workflow Integration | Best For |
|---|---|---|---|---|---|
| Prompts.ai | Real-time across 35+ models | Per team, project, prompt | Prepaid TOKN credits, hard caps | Unified dashboards | Teams reducing tool complexity |
| Finout | Multi-cloud token tracking | AI + cloud cost overview | No-code allocation, anomaly alerts | Slack, Jira, Teams | Enterprises managing multi-cloud |
| CAST AI | Infrastructure-level insights | Kubernetes cluster costs | Autoscaling, GPU optimization | Kubernetes-centric | DevOps teams optimizing infrastructure |
| Holori | Forecasting-based tracking | Budget-aligned cost splits | Real-time anomaly detection | Cloud provider dashboards | Teams focused on budget planning |
| Zesty | Infrastructure-associated | Outcome-based adjustments | Automated scaling, spot protection | AWS, Azure | Teams seeking automated savings |
Each platform offers unique strengths depending on your needs, from detailed token tracking to infrastructure-level optimization. Read on for a deeper dive into their features and capabilities.
AI Token Management Platforms Comparison: Features and Best Use Cases
Prompts.ai simplifies the complex task of token tracking with its unified TOKN Credit system, which works seamlessly across 35+ AI models. Instead of juggling usage metrics for each model, teams rely on a single credit type that translates all activity into USD, ensuring clear and consistent financial reporting. The platform meticulously logs interactions across models, projects, organizations, and API keys, providing a detailed breakdown of resource consumption.
Its real-time FinOps layer links token usage directly to business outcomes. Customizable dashboards make it easy to spot cost drivers, allowing teams to address inefficiencies without delay. This granular tracking ensures accurate cost allocation across all teams and projects.
The TOKN Pooling feature takes cost allocation to the next level by enabling finance teams to distribute a central budget among departments while enforcing spending limits. Whether it's marketing, customer support, or product development, shared token resources can be allocated with precision. Hard caps ensure no single team overspends, and the system maintains a complete audit trail of all AI interactions. This provides finance and security teams with the data they need to monitor and review usage effectively, ensuring tight financial oversight.
With a prepaid model, Prompts.ai automatically halts AI processing when TOKN credits are depleted, eliminating the risk of surprise charges. This pay-as-you-go approach guarantees that budgets are adhered to without requiring manual intervention. From the start, teams have a clear understanding of their maximum financial exposure, offering peace of mind and financial clarity.
Finout simplifies cost tracking by converting billing units into tokens across various services. This unified approach applies to AWS Bedrock, Azure OpenAI, and GCP Vertex AI, allowing for side-by-side comparisons regardless of the provider. Costs are broken down into categories like input, output, and specialized tokens (e.g., batch or cached tokens).
For providers that don’t support detailed tagging, Finout's LLM Proxy adds metadata (such as team, feature, and environment) to each API call. This metadata links usage data with cost data using project IDs, enabling precise attribution to specific features or products.
This process ensures a consistent and accurate framework for cost allocation.
With Virtual Tags (VTags), Finout uses AI to allocate costs to teams, business units, or features - no code changes or agents required. Even untagged resources can be accounted for, solving a major challenge for finance teams. The FairShare Cost Formula ensures discounts are distributed fairly based on actual resource usage.
Enterprise users have reported achieving up to 98% accuracy in cost allocation, boosting their coverage from 80% to 96% while identifying waste 90% faster. The MegaBill Integration consolidates multi-cloud AI expenses into one unified view, offering 100% cost allocation and clear insights into unit economics.
"Finout's exceptional granularity in cost allocation has been an invaluable asset, providing us with unprecedented insight into our cloud spend." - Vijay Kurra, Lead Cloud FinOps & Analysis
Finout goes beyond allocation by integrating cost accountability into everyday tools like Jira, ServiceNow, Slack, and Microsoft Teams. Its no-code, no-agent integration connects to your entire tech stack using a single API key, streamlining spend management across multi-cloud environments, Kubernetes, and AI services into one cohesive view. This integration ensures cost alerts, context, and action items fit seamlessly into existing workflows.
The platform delivers reports 10 times faster and tracks usage 3 times faster than manual methods. Teams can set anomaly detection thresholds to catch issues - such as a runaway token loop that could drain a monthly budget overnight - before they escalate into financial disasters.
CAST AI takes a focused approach to managing costs by targeting the underlying infrastructure that drives AI workloads. Instead of monitoring third-party tokens, it optimizes expenses at the infrastructure level by keeping tabs on GPUs and Kubernetes clusters.
The platform organizes costs by clusters, workloads, namespaces, and custom allocation groups, allowing you to pinpoint GPU expenses down to specific research teams or projects. With cost data refreshing every 60 seconds, you gain near real-time insights into your compute spending. It also identifies inefficiencies by calculating the difference between provisioned and requested resources, exposing wasted money on idle CPU and memory capacity. This method complements token-level tracking by addressing the root compute resources behind those costs.
"CAST AI's monitoring presents all expenses in one place and enables breaking them down by K8s concepts like cluster, workload, and namespaces." - CAST AI
CAST AI doesn’t stop at cost tracking - it also automates infrastructure optimization. By using 95th percentile CPU and 99th percentile RAM metrics, the platform automatically rightsizes containers. It also manages Spot Instances with automated fallback to on-demand nodes, eliminating the need for manual intervention. Workload Autoscaling further simplifies capacity planning by dynamically adjusting resources.
The bin packing feature consolidates workloads onto fewer nodes while decommissioning empty ones, ensuring resources are used efficiently. Cost anomaly detection adds another layer of control, sending alerts for unexpected spending spikes, such as runaway training loops, before they spiral out of control.
In 2024, Akamai reported 40-70% savings on cloud costs and improved engineering productivity after adopting CAST AI’s automation.
"I had an aha moment – an iPhone moment – with Cast. Literally two minutes into the integration, we saw the cost analytics, and I had an insight into something I had never had before." - Dekel Shavit, Sr. Director of Engineering, Akamai
CAST AI seamlessly integrates with major cloud providers like AWS (EKS), Google Cloud (GKE), Azure (AKS), and even on-premises setups. It uses either a read-only agent or an agentless Cloud Connect to feed cost metrics into monitoring tools such as Grafana.
Yotpo achieved a 40% reduction in cloud costs by leveraging CAST AI’s automated Spot Instance management.
"With Cast AI, we didn't do anything... there was a lot of human resources and time saved here. That was a very good experience. And again, from a cost perspective, it was highly optimized." - Achi Solomon, Director of DevOps, Yotpo
The platform’s cost monitoring is available free of charge for unlimited clusters, regardless of their size. It doesn’t require billing data access, instead using public cloud pricing to estimate expenses.
Holori provides a detailed breakdown of AI expenses by tracking costs at the individual token level. It monitors input tokens, output tokens, model types, model tiers, and request counts across providers like OpenAI, Anthropic, and Google. This precision is crucial as pricing can vary significantly. For instance, Anthropic Claude Opus 4.1 charges $15.00 per million input tokens but $75.00 for output tokens - a 5x difference. Similarly, Google Gemini Pro exhibits an 8x gap between input and output tokens ($1.25 vs. $10.00 per million tokens).
Holori consolidates AI API and GPU compute costs into a single dashboard, giving you a comprehensive view of your AI-related expenses.
Holori simplifies cost allocation with its "Virtual Tagging" feature, addressing a common issue: the lack of native tagging in most AI APIs. This system applies consistent tagging rules across providers without requiring DevOps modifications. You can easily assign costs to specific projects, teams, or departments using a drag-and-drop organizational chart. For shared resources, costs can be split by percentage for accurate distribution.
With Cloud Cost Allocation identified as the second highest priority for FinOps practitioners by 2025, Holori's tools meet the growing demand for precise chargeback and showback models.
Holori automates cost tagging using project names, cost centers, or environments, ensuring consistency and saving time. Its ML-powered anomaly detection identifies unusual spending patterns in real time, preventing unexpected cost spikes. Alerts for budget limits and cost thresholds are sent via Slack or email, keeping you informed.
The platform's Provider Tag Converter transforms existing tags from AWS, GCP, or OCI into Holori's virtual tags, ensuring uniformity across hybrid setups. Additionally, Holori highlights inefficiencies such as using premium models unnecessarily. For example, premium models may cost $15-$75 per million tokens, whereas economy models range from $0.25-$4 per million tokens, representing a potential 50-100x savings.
Holori integrates seamlessly into existing FinOps workflows, bridging AI and cloud infrastructure costs. It visually maps infrastructure expenses and resource relationships, making it easier to understand your cost structure. Real-time threshold monitoring helps you catch sudden AI cost increases before they escalate, while model-specific attribution identifies opportunities to shift simpler tasks from high-cost models like GPT-4 to more affordable options.
Zesty sets itself apart by automating cloud resource adjustments to improve the efficiency of AI workloads. Its AI-driven algorithms analyze both historical and real-time usage patterns, making resource adjustments automatically - no manual input required. The Commitment Manager handles a dynamic portfolio of micro Savings Plans that adapt to changing usage patterns, removing the risks tied to long-term contracts.
The platform also offers Pod Rightsizing, which fine-tunes CPU and memory allocation at the container level to align with workload demands. Additionally, PV Autoscaling ensures persistent volume capacity is adjusted in real time. For organizations leveraging spot instances for AI workloads, Zesty's Spot Protection feature migrates pods to new nodes up to 40 seconds before an interruption occurs.
"With simple integration and zero effort, we were able to cut down our compute costs by 53%." - Roi Amitay, Head of DevOps
Zesty goes beyond optimization, integrating effortlessly into existing cloud environments to deliver cost reductions. It connects directly to AWS and Azure accounts via a read-only agent that monitors Kubernetes environments. The onboarding process is quick, taking just minutes, and users often notice measurable savings within 10 days of linking their Cost and Usage Report. Importantly, Zesty manages the cloud infrastructure hosting AI models without accessing sensitive disk data or requiring application code changes.
Blake Mitchell, VP of Engineering, implemented Zesty's Kubernetes optimization tools and achieved a 50% reduction in their cluster’s node count. The platform is SOC 2 compliant and uses success-based pricing, charging 25% of the savings generated - you only pay when it delivers cost reductions. For the Commitment Manager, a minimum monthly on-demand EC2 spend of $7,000 is required.
Every platform in this comparison brings its own set of advantages and trade-offs when it comes to token tracking and cost management. Choosing the right one depends on whether your priorities lean toward instant cost visibility, seamless workflow integration, or automated expense management. Below is a breakdown of each platform’s standout features and limitations.
Prompts.ai stands out for its real-time FinOps tools, which are directly built into the platform. Its pay-as-you-go TOKN credit system eliminates subscription fees, offering precise spending visibility across models and prompts. By combining governance, cost tracking, and performance comparisons in one secure interface, it helps teams cut down on redundant tools.
Finout excels in consolidating cost data from multiple cloud providers, offering a unified view of both AI and infrastructure expenses. However, for teams focused solely on token-level tracking, its broader scope might feel unnecessary.
CAST AI is tailored for managing infrastructure costs in Kubernetes environments, focusing on resource optimization rather than token-specific analytics.
Holori prioritizes budget planning with forecasting and alerting tools that span various cloud providers. While it shines in proactive cost management, it lacks real-time token-level insights.
Zesty leverages automation to align cloud expenses with outcomes through a success-based pricing model. Its strength lies in automated adjustments for cloud costs, but it doesn’t provide the granular tracking of individual AI token usage.
The table below highlights the core attributes of each platform for a clearer comparison:
| Platform | Token Tracking | Cost Allocation | Automation | Workflow Integration | Best For |
|---|---|---|---|---|---|
| Prompts.ai | Real-time tracking across 35+ models | Detailed per model, team, and prompt | Embedded FinOps controls | Unified, secure interface | Teams reducing tool redundancy |
| Finout | Cloud-level visibility | Multi-cloud cost overview | Consolidated reporting | Integrated multi-cloud dashboards | Organizations managing diverse cloud expenses |
| CAST AI | Infrastructure-level insights | Kubernetes cluster-level cost management | Automated resource rightsizing | Kubernetes-centric workflows | Teams optimizing infrastructure costs |
| Holori | Forecasting-based tracking | Budget-aligned cost allocation | Proactive alerting | Cloud provider dashboards | Teams focused on budget planning |
| Zesty | Infrastructure-associated tracking | Outcome-driven cost allocation | Automation-driven cost management | Integration with major cloud platforms | Teams seeking automated cloud savings |
This comparison provides a clear foundation for making informed decisions to optimize AI-related expenditures.
Managing AI token costs is a nuanced challenge, requiring tailored solutions for different team sizes and needs. Smaller teams benefit from tools like Prompts.ai, which offers a straightforward pay-as-you-go TOKN credit system and real-time tracking across 35+ models. This approach helps avoid the complexity of juggling multiple tools, making it ideal for lean operations.
For large enterprises, the focus shifts to achieving comprehensive oversight. Platforms such as Finout excel in consolidating spending across third-party LLM APIs and cloud infrastructure, providing the unified visibility that bigger organizations need. DevOps teams, on the other hand, should consider tools that enable governance at the gateway level, effectively curbing excessive costs before they escalate in production.
Granular attribution is another critical piece of the cost-management puzzle. By analyzing which workflows are the most resource-intensive, teams can make smarter decisions - routing simpler tasks to budget-friendly models and reserving higher-cost options for complex scenarios. For instance, Notion's use of Braintrust resulted in a tenfold increase in development speed, going from fixing 3 issues per day to 30. This example highlights how thoughtful strategies can streamline both cost control and resource allocation.
Integrating cost tracking into development workflows further enhances efficiency. Platforms that combine token monitoring with features like prompt versioning and evaluation gates allow teams to identify cost regressions early, before deployment. The choice of tools should align with your architecture, whether that means SDK logging for low-latency environments or gateway proxies for improved caching.
Reducing AI costs hinges on three key factors: visibility, attribution, and automation. Each platform discussed addresses a unique aspect of this challenge, so selecting the right one depends on your specific goals - whether that's minimizing redundant tools, fine-tuning infrastructure, or managing budgets across multiple cloud providers.
AI platforms make it easier to manage token usage and control costs by offering in-depth insights into how tokens are used across various models, features, and teams. This detailed tracking helps businesses pinpoint areas with higher expenses, streamline workflows, and allocate resources more effectively.
Many of these platforms include real-time analytics and cost breakdowns, allowing organizations to keep a close eye on spending patterns and make well-informed choices. Tools like cost alerts, usage caps, and model routing controls help ensure budgets are maintained while enhancing efficiency. These features provide businesses with greater transparency and control over their AI expenses, leading to smarter resource allocation and improved financial performance.
When choosing an AI cost management platform, focus on tools that provide detailed token-level tracking, real-time expense monitoring, and customizable alerts. These features are essential for keeping costs under control, especially when dealing with AI models that charge based on tokens, API calls, or GPU usage - areas where expenses can quickly spiral out of control.
It's also important to select a platform with budget controls, granular cost attribution, and predictive analytics. These capabilities help you anticipate future expenses, avoid budget overruns, and allocate resources more effectively, ensuring your AI workflows remain efficient and manageable.
Automation in AI platforms plays a crucial role in managing costs by providing real-time tracking and in-depth insights into token usage, which is often a significant contributor to AI-related expenses. Platforms like Prompts.ai enable organizations to keep a close eye on token consumption, pinpoint inefficiencies, and make necessary adjustments before costs escalate.
Through automation, businesses can adopt smarter cost-management practices, such as setting usage caps, receiving alerts for unusual activity, and dynamically reallocating resources based on current demand. By reducing the need for manual intervention and offering detailed visibility, automation helps ensure AI operations stay efficient and budget-friendly, reducing the likelihood of unexpected financial surprises.

















