Pay As You Go - AI Model Orchestration and Workflows Platform


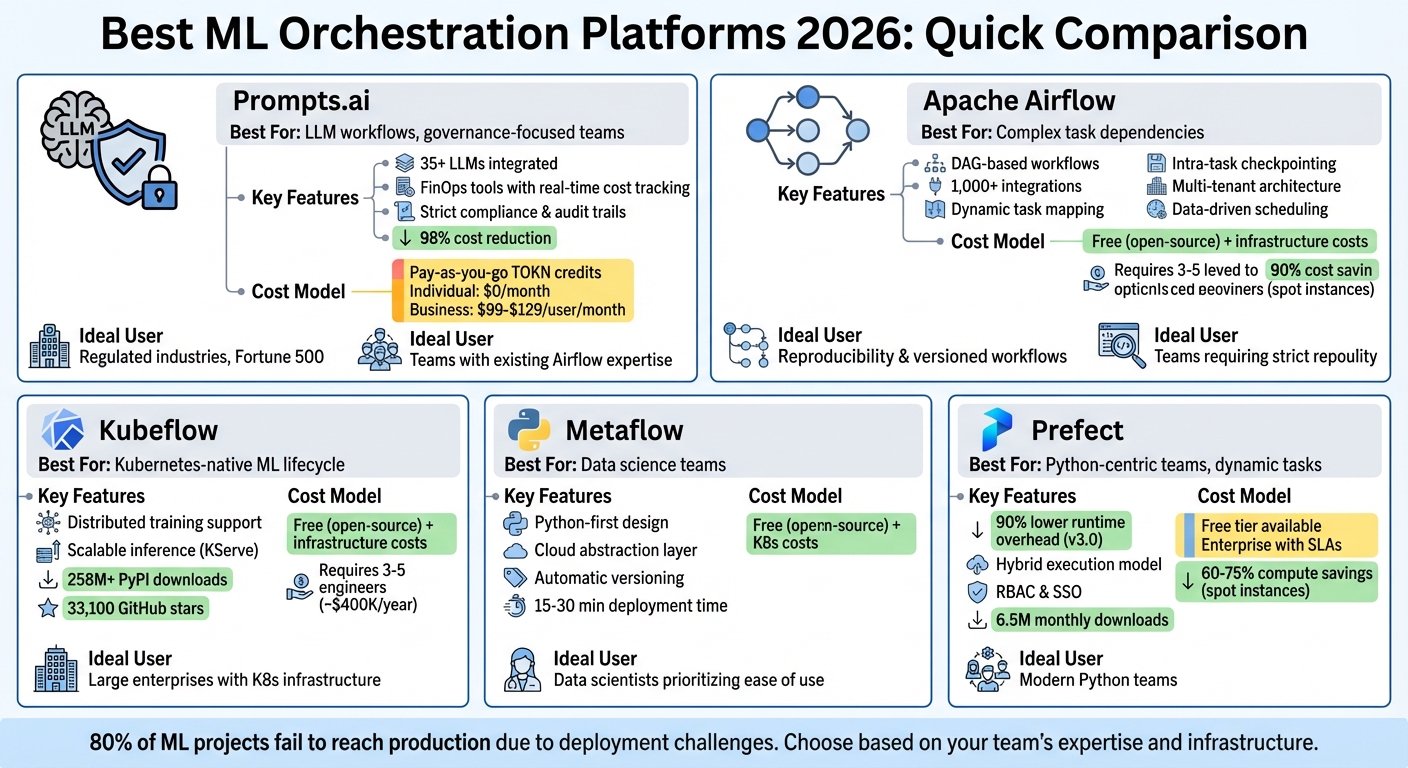
Managing complex ML pipelines is easier than ever. In 2026, machine learning teams are tackling increasing pipeline complexity, compliance needs, and cloud costs. Here’s a quick breakdown of six leading orchestration platforms that streamline workflows, reduce costs, and improve governance for enterprise AI projects:
Each platform has unique strengths, from handling large-scale LLM operations to offering cost-saving features like spot instance support. Below is a quick comparison to help you choose the right solution for your team.
| Platform | Best For | Key Features | Cost Model |
|---|---|---|---|
| Prompts.ai | LLM workflows, governance-focused | 35+ LLMs, FinOps tools, strict compliance | Pay-as-you-go TOKN credits |
| Airflow | Complex task dependencies | DAG-based, 1,000+ integrations, dynamic tasks | Free (open-source) + infra costs |
| Kubeflow | Kubernetes-native ML lifecycle | Distributed training, scalable inference | Free (open-source) + infra costs |
| Flyte | Reproducibility, versioned workflows | Checkpointing, multi-tenant architecture | Free (open-source) + infra costs |
| Metaflow | Data science teams | Python workflows, cloud abstraction | Free (open-source) + cloud costs |
| Prefect | Python-centric teams, dynamic tasks | Hybrid execution, strong security, RBAC | Free (open-source) + paid tiers |
Whether you're scaling AI workflows, optimizing costs, or ensuring compliance, selecting the right platform depends on your infrastructure, team expertise, and project goals. Let’s dive deeper into what makes each solution stand out.
ML Orchestration Platforms 2026: Feature and Cost Comparison
Prompts.ai serves as a unified platform, seamlessly integrating over 35 large language models (including GPT-5, Claude, and LLaMA) into a single interface. Its multi-layered design divides the process into distinct stages: prompt creation, safety checks, and deployment. This structure minimizes operational risks while ensuring compliance throughout machine learning (ML) workflows. The platform also supports agentic workflows, which automate data movement and standardize outputs across pipelines. With chain-of-thought integration, teams can trace every decision made by the models, adding a layer of transparency to production ML systems. This architecture is tailored to enhance ML benchmarking and improve operational efficiency.
Prompts.ai offers tools for direct performance benchmarking, enabling ML engineers to evaluate accuracy, latency, and output quality without needing multiple platforms. Real-time FinOps features monitor token usage, linking AI expenses to business results. This helps teams identify costly workflows before scaling. The platform’s "Time Savers" streamline common ML tasks like data validation, feature engineering, and model evaluation by embedding best practices into reusable workflows. Additionally, the built-in Prompt Engineer Certification program equips teams to refine and standardize workflows, transforming one-off experiments into repeatable, auditable processes. To complement these capabilities, Prompts.ai enforces strict security measures.
Understanding the critical need for governance in enterprise MLOps, Prompts.ai provides a centralized control system that logs every agent decision and enforces strict policies. Automated audit trails and PII filtering ensure compliance with stringent U.S. standards. These security protocols allow Fortune 500 companies and highly regulated industries to deploy ML pipelines confidently, without compromising sensitive data.
Prompts.ai operates on a pay-as-you-go TOKN credit system, tying costs directly to usage. Individual plans start at $0/month, allowing risk-free exploration, while business tiers range from $99 to $129 per user per month. By consolidating tools into one orchestration layer, the platform can reduce AI software costs by up to 98%. Real-time expense tracking and a detailed FinOps dashboard offer granular insights into which models, prompts, and workflows generate the highest costs. This transparency is especially valuable for U.S. teams managing cloud budgets across AWS, Azure, or Google Cloud. The cost model aligns with the need for clear, usage-based spending control.
Apache Airflow 3.x is built on a modular architecture that divides core functionalities into four main components: a scheduler, a webserver, a metadata database, and a standalone DAG processor. This separation ensures better security by isolating user-provided code from the scheduler. As of early 2026, the latest stable version is 3.1.5, which introduces the Task SDK. This SDK streamlines task creation by decoupling execution logic from the orchestration engine, making workflows more efficient.
Similar to prompts.ai, Airflow caters to the demand for scalable and efficient ML orchestration. However, its open-source framework contrasts with prompts.ai's integrated platform model. One standout feature of Airflow is its pluggable compute model, which allows tasks to run across diverse infrastructures. For example, data engineering tasks can leverage Spark clusters, while model training can utilize GPUs via the KubernetesPodOperator. The TaskFlow API simplifies data sharing between tasks through Python decorators and implicit XComs, enabling users to transform standard ML scripts into orchestrated workflows with ease. Additionally, dynamic task mapping enables pipelines to scale dynamically during runtime. This is especially useful for running parallel model training with different hyperparameters without needing to predefine the number of tasks. These features make Airflow a versatile tool for ML projects, complementing the robust capabilities of platforms like prompts.ai.
Airflow has evolved beyond traditional data engineering, now offering over 1,000 integrations, including MLFlow, Weights & Biases, and vector databases like Pinecone and Weaviate. This expansion positions Airflow as a key player in LLMOps workflows, such as orchestrating Retrieval Augmented Generation (RAG) and fine-tuning pipelines that incorporate proprietary data into vector databases. Dynamic task mapping further enhances its ability to scale ML training tasks in parallel.
With data-driven scheduling powered by Airflow Datasets, workflows can automatically trigger when specific data dependencies are updated, creating more responsive MLOps pipelines. The Setup and Teardown task types help manage temporary ML resources, ensuring that expensive GPU clusters are only active during training tasks, which helps control infrastructure costs. To ensure data quality before training, Airflow integrates with tools like Great Expectations and Soda Core, reducing the risk of poor data affecting model outcomes. These features highlight Airflow's ability to bridge traditional data engineering with cutting-edge ML operations.
Airflow's "Workflows as Code" approach allows teams to use Git for version control and maintain audit trails. Its built-in OpenLineage integration supports data lineage tracking and model governance, which is crucial for meeting compliance standards like GDPR and HIPAA. The recently introduced airflowctl command-line tool (version 0.1.0, released in October 2025) provides a secure, API-driven way to manage deployments.
Security is a key focus in Airflow 3.x, which implements a multi-role security model. Roles such as Deployment Manager, DAG Author, and Operations User ensure that data scientists can create pipelines without needing full administrative access. Workflows can also run under specific Unix user permissions through task impersonation, enforcing strict security boundaries. Furthermore, integrations with Amazon Secrets Manager and HashiCorp Vault ensure sensitive credentials and API keys are stored securely.
Apache Airflow is free to use under the Apache License 2.0. However, the overall cost of running Airflow can be substantial due to the DevOps resources required for setup and ongoing maintenance. While there are no licensing fees, organizations need to account for expenses related to cloud infrastructure, skilled personnel, and the platform's resource-intensive nature.
For those looking to reduce operational overhead, managed services like Astronomer, AWS MWAA, and Google Cloud Composer offer tiered or consumption-based pricing. These services often include optimizations like worker queues, which allocate tasks to the most cost-efficient machines. For instance, GPU nodes can handle resource-heavy training tasks, while lightweight tasks are assigned to more economical CPU instances. To maximize cost efficiency, organizations should align their usage with these flexible pricing models, especially in hybrid or cloud-based environments.
Kubeflow Pipelines (KFP) allow users to define machine learning workflows as directed acyclic graphs through a Python SDK. These workflows are compiled into YAML files for containerized execution. The platform’s modular design integrates several key components, including Trainer for distributed training, Katib for hyperparameter tuning, and KServe for scalable inference. A centralized dashboard provides a unified interface to manage these components, making it a go-to choice for Kubernetes-native ML orchestration. Kubeflow ensures workflows run consistently, whether on local machines, on-premises clusters, or cloud platforms like Google Cloud’s Vertex AI. This architecture supports a seamless and efficient ML lifecycle.
Kubeflow’s modular approach equips it with a range of tools tailored for machine learning. It orchestrates the entire ML lifecycle - from data preparation to deployment - using Pipelines, Trainer, Katib, and KServe. A built-in Model Registry ensures reproducibility across experiments and deployments. Katib simplifies hyperparameter tuning with methods such as Bayesian optimization and grid search. For large-scale tasks, the Trainer component supports distributed training using frameworks like PyTorch, HuggingFace, DeepSpeed, and JAX. KServe offers a serverless, framework-independent platform for deploying models built with TensorFlow, PyTorch, or scikit-learn. Additional features like parallel execution and caching enhance computational efficiency, while the Kubeflow Python SDK makes pipeline creation straightforward.
Kubeflow employs Kubernetes RBAC and namespaces to isolate workloads and manage user permissions effectively. The ML Metadata Service tracks the state and lineage of executed containers, capturing details about their inputs, outputs, and associated data artifacts. The Model Registry maintains a clear audit trail, linking experimentation to production workflows. Access to all components is secured via the Central Dashboard, which uses authenticated interfaces. A Pipeline Persistence Agent logs execution data into a MySQL-backed metadata store, supporting governance and audit needs. Kubernetes secrets are used to securely manage sensitive credentials, making Kubeflow a viable option for air-gapped environments and private cloud deployments.
As an open-source project under the Apache 2.0 license, Kubeflow eliminates licensing fees, though users must account for the costs of the underlying Kubernetes infrastructure. This includes expenses related to cloud platforms like Google Kubernetes Engine or on-premises deployments, as well as storage needs for managing artifacts through tools like SeaweedFS or Google Cloud Storage. For organizations looking to streamline operations, managed services such as Google Cloud Vertex AI Pipelines offer a pay-as-you-go model that takes care of infrastructure management. Additionally, features like caching in Kubeflow Pipelines can help reduce iteration times, cutting down on associated cloud costs.
Flyte is built on a three-plane architecture that efficiently organizes its operations: the User Plane, the Control Plane, and the Data Plane.
This Kubernetes-native design allows Flyte to handle high concurrency and scale effortlessly, supporting projects ranging from small experiments to workloads requiring thousands of CPUs. Today, over 3,000 teams rely on Flyte to deploy pipelines at scale. This architecture forms the backbone of Flyte's machine learning capabilities.
Flyte supports the entire machine learning lifecycle with tools tailored for distributed training. It integrates with Horovod and Kubeflow operators for MPI, TensorFlow, and PyTorch. Developers can define resource requirements directly in Python using decorators like @task(requests=Resources(gpu="2")). Flyte also simplifies hyperparameter tuning with map_task for parallel processing and @dynamic workflows for grid search, random search, or Bayesian optimization.
One standout feature is intra-task checkpointing, which allows long-running jobs to resume from their last checkpoint after a failure, avoiding the need to start over. A real-world example of Flyte's scalability is MethaneSAT, which uses Flyte to process over 200 GB of raw data daily, leveraging more than 10,000 CPUs and generating approximately 2 TB of output.
"When you write Python scripts, everything runs and takes a certain amount of time, whereas now for free we get parallelism across tasks. Our data scientists think that's really cool." - Dylan Wilder, Engineering Manager, Spotify
Flyte's multi-tenant architecture enables multiple teams to share infrastructure while keeping their data, configurations, and resources isolated. Immutable execution ensures that workflows cannot be altered after execution, creating a robust audit trail and reinforcing data isolation. Workflow versioning allows teams to track changes and revert to previous versions when needed. Jeev Balakrishnan, Software Engineer at Freenome, highlighted this benefit:
"Flyte has this concept of immutable transformation - it turns out the executions cannot be deleted, and so having immutable transformation is a really nice abstraction for our data-engineering stack".
Flyte also employs strongly typed interfaces to validate data at every step. Sensitive credentials are securely managed, either mounted as files or passed as environment variables. Additionally, end-to-end data lineage tracking provides complete visibility into data origins and transformations throughout its lifecycle.
Flyte is a free, open-source platform available under the Apache 2.0 license, with users covering their own Kubernetes infrastructure costs. To cut expenses, Flyte offers the interruptible argument in task decorators, enabling the use of spot or preemptible instances. This approach can reduce compute costs by up to 90% compared to on-demand pricing. Jeev Balakrishnan from Freenome explained:
"Given the scale at which some of these tasks run, compute can get really expensive. So being able to add an interruptible argument to the task decorator for certain tasks has been really useful to cut costs".
Metaflow features a modular design that separates workflow logic from execution, making it easier for developers to focus on building workflows without worrying about the underlying infrastructure. Workflows are written in plain Python using a unified API, while Metaflow manages execution across various environments. Its layered approach abstracts key components like modeling, compute, data access, and orchestration. Unlike standalone schedulers, Metaflow works seamlessly with production-grade orchestrators such as AWS Step Functions, Argo Workflows, Apache Airflow, and Kubeflow. This allows teams to develop workflows locally and deploy them to production without altering the code. The framework also integrates with leading cloud services to handle data-heavy tasks effectively. Deploying Metaflow infrastructure to a cloud account or Kubernetes cluster typically takes just 15 to 30 minutes. This architecture simplifies machine learning (ML) operations, setting the stage for the platform's specialized ML capabilities.
Metaflow automatically tracks versions of code, data, and artifacts, removing the need for manual oversight. Developers can use decorators like @batch, @kubernetes, and @checkpoint to assign resources for specific steps and checkpoint progress during lengthy training processes, helping to optimize cloud costs.
Recent enhancements include support for conditional and iterative steps, enabling more advanced AI workflows. The "spin" command simplifies incremental flow creation. Additionally, Metaflow supports specialized hardware, such as AWS Trainium, for tasks like training and fine-tuning large language models.
The platform has demonstrated its ability to accelerate ML workflows significantly. For example, Peyton McCullough, a software engineer at Ramp, shared that implementing Metaflow with AWS Batch and Step Functions dramatically increased their ML development speed. After completing a "riskiness" model that once took months to build, the team delivered eight additional models within ten months. Today, their system handles over 6,000 flow runs. Similarly, CNN’s data science team reported testing twice as many models in the first quarter of 2021 compared to the entire year of 2020.
"Airflow is meant to be used as an orchestrator for compute workloads, rather than the workloads themselves... Metaflow still includes a handy UI where data scientists can examine task progress."
- Peyton McCullough, Software Engineer, Ramp
Metaflow’s technical strengths are complemented by its focus on governance and security, which are critical for enterprise usage.
Metaflow offers robust security features tailored for enterprise environments. The @project decorator ensures namespace isolation for different environments (e.g., user, test, prod), safeguarding production deployments. To further secure operations, production deployments require authorization tokens. By deploying Metaflow directly into an organization’s cloud account or Kubernetes cluster, all data and compute resources remain within the enterprise’s security perimeter.
The @project decorator also supports comprehensive audit capabilities by automatically tracking all flows, experiments, and artifacts. Metaflow integrates seamlessly with existing corporate security protocols, data governance frameworks, and secret management systems, ensuring compliance with enterprise standards.
Metaflow is open-source and available under the Apache License 2.0, meaning teams only pay for the cloud resources they use. Its "Bring Your Own Cloud" approach provides full control over costs. For those seeking additional support, managed versions and professional services are available through Outerbounds.
Prefect employs a hybrid architecture that separates orchestration from execution. The control plane, managed through Prefect Cloud, handles metadata and scheduling, while runtime execution occurs on private infrastructure. This setup ensures sensitive data remains within your network, offering security and flexibility. Tasks are dynamically executed based on real-time conditions, with the ability to resume from failure points.
Workflows are defined using Python decorators like @flow and @task, making it easy to integrate modern programming patterns such as async/await and type hints. This approach allows machine learning engineers to create tasks and branches dynamically, adapting workflows based on data conditions without needing to predefine every scenario.
Prefect uses a "pull" mechanism where workers poll the Prefect API for scheduled tasks, eliminating the need for inbound connections and keeping firewalls secure. This design supports scalable, efficient workflows for machine learning projects.
Prefect 3.0 has reduced runtime overhead by up to 90%, gaining traction with over 6.5 million monthly downloads and nearly 30,000 contributing engineers. Its flexibility and scalability have made it a go-to tool for many organizations.
At Cash App, Machine Learning Engineer Wendy Tang spearheaded Prefect's integration to enhance fraud prevention workflows. The team tailored Prefect's features to align with their infrastructure needs while maintaining strict security standards.
"We took all the Prefect features and designed an architecture that really works for our infrastructure provisioning and our organization." - Wendy Tang, Machine Learning Engineer, Cash App
Snorkel AI utilized Prefect's open-source version to achieve remarkable scalability. Smit Shah, Director of Engineering, implemented Prefect to manage over 1,000 flows per hour and tens of thousands of daily executions on Kubernetes, resulting in a 20x boost in throughput.
"We improved throughput by 20x with Prefect. It's our workhorse for asynchronous processing - a Swiss Army knife." - Smit Shah, Director of Engineering, Snorkel AI
Prefect also includes the MCP (Model Context Protocol) server, which simplifies monitoring, debugging, and querying infrastructure. This tool streamlines troubleshooting for complex machine learning pipelines.
Prefect provides robust security features, including Role-Based Access Control (RBAC) at multiple levels - account, workspace, and object. This allows teams to separate development, staging, and production environments. Enterprise features such as single sign-on (SSO), SCIM-based team management, and a zero-inbound-connection design enhance security and compliance.
Audit logs track all actions to meet compliance requirements, while secure secret management ensures credentials are safely stored and not hardcoded into pipelines.
At Endpoint, Sunny Pachunuri, Data Engineering and Platform Manager, led a migration to Prefect from a competing platform. This transition eliminated the need for retrofitting and resulted in substantial cost savings and productivity gains.
"Switching from Astronomer to Prefect resulted in a 73.78% reduction in invoice costs alone." - Sunny Pachunuri, Data Engineering and Platform Manager, Endpoint
These features make Prefect both secure and cost-effective for enterprise use.
Prefect offers three pricing tiers to meet different needs:
Prefect's durable execution model allows workflows to resume from failure points, avoiding the need to re-run entire machine learning training jobs. This reduces compute costs significantly. Additionally, infrastructure-aware orchestration supports Kubernetes spot instances, which can lower compute expenses by 60–75% compared to on-demand pricing.
For instance, Rent The Runway reported a 70% reduction in compute costs by leveraging Prefect's infrastructure-aware orchestration.
This section builds on the earlier platform reviews, offering a side-by-side comparison of their core advantages and challenges. Each platform brings its own set of strengths and trade-offs, making it essential to choose one that aligns with your infrastructure, expertise, and budget. The table below highlights the key strengths, limitations, and ideal use cases for each platform.
Apache Airflow is well-regarded for managing complex task dependencies using its Directed Acyclic Graph (DAG) structure, which ensures transparent and predictable execution. However, it requires custom ML extensions, can be resource-intensive, and lacks official enterprise support.
Kubeflow integrates seamlessly with Kubernetes and has garnered significant community support, evidenced by over 258 million PyPI downloads and 33,100 GitHub stars. Despite this, it is known for its complexity and high maintenance demands, often requiring a dedicated team of 3–5 engineers, which can cost around $400,000 annually.
Flyte excels in handling large-scale, versioned workflows with a focus on reproducibility, but it demands Kubernetes expertise and introduces additional infrastructure overhead.
Metaflow simplifies infrastructure management for data scientists, but its heavy reliance on Python makes it less suitable for environments that require support for multiple programming languages.
Prefect takes a lightweight approach with its pure Python design, eliminating the need for DSLs or YAML, and boasts a 90% reduction in runtime overhead in version 3.0. However, it can still be resource-heavy for smaller tasks.
| Platform | Key Strengths | Primary Limitations | Best For |
|---|---|---|---|
| prompts.ai | Unified access to 35+ LLMs; real-time FinOps cost controls; up to 98% cost reduction | Focused on LLM orchestration rather than traditional ML pipelines | Organizations running multi-model AI workflows with strict governance needs |
| Apache Airflow | Clear DAG-based dependencies; extensive community connectors; hybrid scalability | Requires custom ML extensions, is resource-intensive, and lacks official enterprise support | Complex data engineering pipelines with established Airflow expertise |
| Kubeflow | Kubernetes-native; parallel execution; caching eliminates redundant runs | High maintenance overhead; requires a dedicated platform team | Large enterprises with existing Kubernetes infrastructure and DevOps resources |
| Flyte | Strong versioning; reliable at scale; reproducible workflows | Steep learning curve; Kubernetes expertise required | Teams already operating in Kubernetes environments seeking strict reproducibility |
| Metaflow | Data scientist-friendly; effective infrastructure abstraction | Python-focused; offers limited granular control | Data science teams prioritizing ease of use over infrastructure management |
| Prefect | Native Python approach; 90% lower runtime overhead; supports dynamic task creation | Can be resource-heavy for simple tasks | Python-centric teams in need of modern, flexible workflow automation |
These insights highlight the importance of aligning your platform choice with your specific project needs. Nearly 80% of machine learning projects fail to progress beyond experimentation due to challenges with deployment, monitoring, and model reliability. Selecting a platform that complements your team's expertise and existing infrastructure - rather than simply opting for the most feature-packed option - can significantly boost your chances of successfully reaching production.
The comparison above showcases the unique strengths of various orchestration platforms, making it clear that the right choice depends on your team’s expertise and project needs.
For teams working heavily in Python, Prefect offers an intuitive solution. With its straightforward @flow decorator, you can easily transform functions into production workflows. Its hybrid execution model ensures data security by keeping sensitive information local while only sharing metadata externally.
If your team relies on Kubernetes, platforms like Kubeflow or Flyte are excellent options. These tools shine in environments that demand strict reproducibility and robust DevOps capabilities, though they come with a steeper learning curve and higher maintenance demands.
Serverless orchestration platforms like SageMaker Pipelines or Vertex AI Pipelines are ideal for cloud-native, budget-conscious projects. By charging only for actual compute time and avoiding idle infrastructure costs, they provide an efficient and cost-effective model.
For U.S.-based teams operating in regulated industries, security features such as Single Sign-On, role-based access control, and detailed audit logs are non-negotiable. Choosing platforms with these capabilities ensures compliance and smooth deployment processes.
Organizations managing multi-model AI workflows with strict governance needs should consider prompts.ai. With access to over 35 top AI models and real-time FinOps tools, it offers a unified ecosystem that can slash AI costs by up to 98%. Its pay-as-you-go TOKN credits align spending directly with usage, ensuring both cost efficiency and enterprise-grade governance.
As orchestration platforms evolve beyond rigid DAG structures toward more flexible Python-based control flows, they enable dynamic, event-driven workflows and agentic AI orchestration. Selecting the right platform now will not only address your current needs but also position your organization for the future of autonomous orchestration.
When selecting a machine learning orchestration platform, scalability should be a top priority. Choose a solution capable of adapting to increasing workloads while supporting deployments across on-premises, cloud, or hybrid setups. The best platforms achieve this without requiring extensive code modifications. Features like container orchestration, particularly with Kubernetes, can simplify scaling and deployment processes.
Another crucial factor is the ease of building and managing workflows. Platforms that support widely-used programming languages like Python make it simpler for data scientists to design pipelines intuitively. Additionally, look for seamless integration with tools for data versioning, model monitoring, and CI/CD pipelines to ensure smooth, end-to-end workflows.
Lastly, pay attention to observability, reliability, and cost. A reliable platform should provide comprehensive monitoring, real-time metrics, and effective error-handling to maintain system uptime. Compare pricing structures - whether it's pay-as-you-go managed services or self-hosted solutions - and confirm the inclusion of essential security features like role-based access control to meet compliance standards. By prioritizing these considerations, you'll be better equipped to select a platform that aligns with your project's requirements and objectives.
Pricing models for machine learning orchestration platforms generally fall into three main types: flat-rate subscriptions, usage-based fees, and custom enterprise contracts. Flat-rate plans offer predictable monthly expenses, which can be helpful for budgeting, but they might become costly if your usage surpasses the allotted quota. Usage-based models, on the other hand, charge based on factors like compute time, API calls, or the number of workflow runs. These align costs with actual usage, making them a good fit for businesses with fluctuating workloads, though they can be harder to forecast. Some platforms take a hybrid approach, combining a base subscription fee with additional charges for usage, offering a mix of flexibility and cost management.
Pricing can also be influenced by the platform's features. Options like GPU acceleration, managed Kubernetes, or access to a wide range of AI models may increase costs. For businesses focused on controlling expenses, platforms with clear cost dashboards and transparent billing systems are a better choice. Meanwhile, teams that prioritize fast scalability might lean toward solutions with flexible, on-demand pricing, even if it means higher variable costs. To accurately assess the financial impact of an orchestration platform, it’s crucial to understand its pricing structure in detail.
When choosing an ML orchestration platform, it’s essential to focus on security measures that protect both your data and workflows, while meeting industry compliance standards. Seek platforms that prioritize data residency, ensuring your code and data stay within your environment. Features like outbound-only worker connections and hybrid architectures that block inbound network access are vital for maintaining control and security. Look for certifications such as SOC 2 Type II, GDPR, and HIPAA, alongside practices like regular penetration testing and bug-bounty programs to identify and address vulnerabilities.
Effective access management is another critical factor. Platforms should include role-based access control (RBAC), multi-factor authentication (MFA), and single sign-on (SSO) to ensure only authorized users have access. Secure service-to-service communication with service accounts, and confirm that all data is encrypted both at rest and during transit. A comprehensive audit log with customizable retention periods is also necessary for compliance and forensic investigations.
To further secure the infrastructure, look for features like container security, Kubernetes RBAC, network segmentation, and IP allow-listing. These tools help reduce potential vulnerabilities and ensure your ML environment is secure and ready for production.


















