Pay As You Go - AI Model Orchestration and Workflows Platform


AI language models are reshaping industries with tools that drive automation and efficiency. Choosing the right provider depends on your business needs. Here’s a quick overview of the top three players:
Each provider has unique strengths, from coding precision to multimodal capabilities. Many businesses combine multiple models for flexibility and performance.
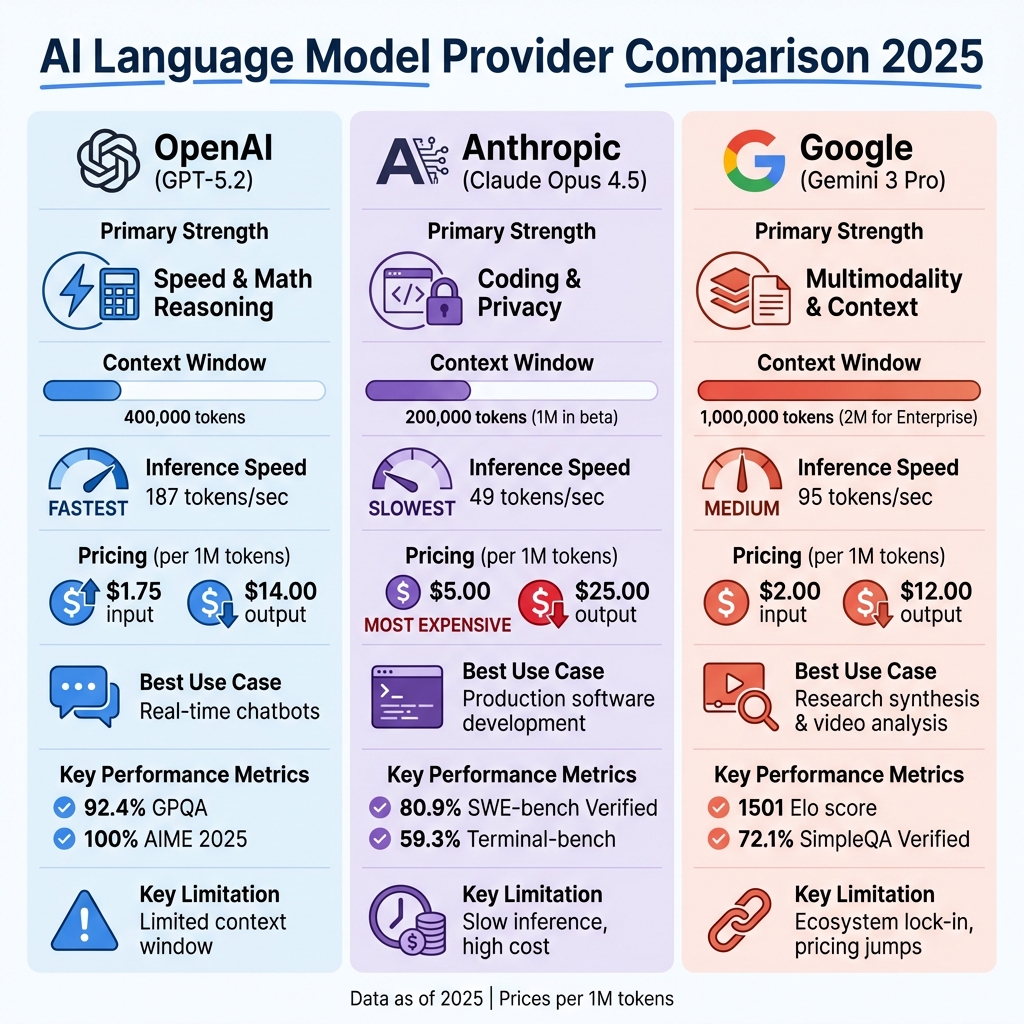
| Provider | Key Strength | Context Window | Speed | Pricing (Input/Output per 1M tokens) | Best Use Case |
|---|---|---|---|---|---|
| OpenAI | Speed & Math Reasoning | 400,000 tokens | 187 tokens/sec | $1.75 / $14.00 | Real-time chatbots |
| Anthropic | Coding & Privacy | 200,000 tokens (1M) | 49 tokens/sec | $5.00 / $25.00 | Software development |
| Multimodality & Context | 1,000,000 tokens (2M) | 95 tokens/sec | $2.00 / $12.00 | Research & video analysis |
To maximize efficiency and reduce costs, consider orchestration platforms like Prompts.ai, which unify access to multiple models under one interface.
AI Language Model Provider Comparison: OpenAI vs Anthropic vs Google Gemini
OpenAI provides a robust AI ecosystem built around its GPT model family. Among these, GPT-5.2 stands out for its exceptional performance in coding and agentic tasks, achieving 92.4% on GPQA and 100% on AIME 2025. For users seeking enhanced speed and precision, a premium "Pro" version is also available.
The capabilities of OpenAI's models are impressive. GPT-5 supports a 400K-token context window, making it ideal for analyzing large datasets such as entire codebases or comprehensive legal documents. Meanwhile, GPT-4o delivers rapid responses in just 320ms, enabling seamless natural voice interactions.
Alexandr Frunza, Backend Developer at Index.dev, shared: "OpenAI built GPT-4o to handle real conversations... fast enough that users don't notice the delay".
OpenAI also offers specialized models like o3-deep-research, tailored for advanced analytics, and Sora 2, designed for high-quality video processing with synchronized audio. For high-volume tasks, GPT-5 mini is an economical choice, priced at just $0.25 per 1M input tokens. Zillow, for instance, uses the OpenAI Realtime API to power voice-based searches for homes and financing options, allowing users to engage naturally with their platform.
OpenAI is committed to safety, employing a multi-layered approach that includes data filtering, alignment through Reinforcement Learning from Human Feedback (RLHF), and rigorous red teaming. During the launch of GPT-4o, over 100 external red teamers were involved to identify and mitigate risks. The results are clear: GPT-4 is 82% less likely to respond to disallowed content and 40% more likely to provide factual information compared to GPT-3.5.
The Safety Advisory Group oversees model evaluations, ensuring only those with a "medium" or lower post-mitigation risk score are released to the public. OpenAI also publishes detailed System Cards for major releases, outlining potential risks and safeguards. For enterprise users, the platform offers SOC 2 Type 2 compliance and optional zero data retention policies for added security.
OpenAI's APIs are designed for flexibility, offering RESTful, streaming, and realtime options compatible with any system that supports HTTP requests. Official SDKs for Python, JavaScript, and C# streamline development processes, while tools like the Agents SDK and Agent Builder simplify the creation of production-ready workflows.
Stripe leveraged the OpenAI Evals framework to assess the accuracy of their GPT-powered technical documentation tool, enhancing it with human oversight.
For enterprises, OpenAI offers features like SSO, MFA, and RBAC. In regulated industries, deployments through Azure ensure VNet isolation and HIPAA compliance via Business Associate Agreements. Developers are advised to use pinned model versions (e.g., gpt-4o-2024-08-06) to maintain consistent behavior in production environments.
| Model | Input (per 1M tokens) | Output (per 1M tokens) | Context Window |
|---|---|---|---|
| GPT-5 mini | $0.25 | $2.00 | 400K |
| GPT-5.1 | $1.25 | $10.00 | 400K |
| GPT-5.2 | $1.75 | $14.00 | 400K |
| GPT-5.2 Pro | $21.00 | $168.00 | 400K |
When compared to competitors like Claude Opus 4.1, which charges $15.00 per 1M input tokens and $75.00 per 1M output tokens, GPT-5.1 proves to be about 8x more cost-efficient. For tasks that aren't time-sensitive, the Batch API provides additional savings by allowing delayed processing.
Next, we’ll take a closer look at Anthropic Claude, which offers a distinct set of capabilities in the AI landscape.
The Anthropic Claude family delivers conversational AI that feels natural, steering clear of robotic tones. Its flagship model, Claude Opus 4.5, debuted in November 2025 and boasts an impressive intelligence score of 49. One of its standout features is Extended Thinking mode, enabling detailed, step-by-step reasoning for tackling complex analytical tasks.
Claude Opus 4.5 shines in coding and autonomous workflows, handling intricate software engineering challenges with ease. It scored an impressive 80.9% on SWE-bench Verified, and supports a standard 200,000-token context window, with enterprise-level options extending up to a remarkable 1 million tokens[5,32].
"Claude Opus 4.5 is our new hybrid reasoning large language model. It is state-of-the-art among frontier models on software coding tasks and agentic tasks that require it to run autonomously on a user's behalf." – Anthropic
The model's Artifacts feature enhances collaboration by displaying code, diagrams, and website previews side by side, streamlining iteration[5,25]. In terminal-based tasks, Claude leads with a 59.3% score on Terminal-bench, outperforming its nearest competitor by roughly 12 points. Developers also benefit from the Claude Code CLI tool, which allows direct interaction with complex codebases, solidifying its reputation as a coding powerhouse.
These achievements in performance set the foundation for its robust safety measures and seamless integration capabilities.
Claude stands out with its safety-first approach, leveraging Constitutional AI to ensure models remain helpful, honest, and harmless. Its Responsible Scaling Policy assigns AI Safety Levels (ASL) based on catastrophic risk evaluations, with Claude Opus 4.5 meeting the stringent ASL-3 Standard for security[26,28].
In multilingual safety tests, the model achieved a 99.78% harmless response rate for violative requests across languages like Arabic, French, Korean, Mandarin, and Russian. It also demonstrated strong agentic safety, refusing 88.39% of harmful computer-use requests and successfully blocking 99.4% of prompt injection attacks during bash command execution.
Claude integrates seamlessly with platforms like Amazon Bedrock, Google Vertex AI, and Microsoft Azure AI Foundry. Its Model Context Protocol (MCP) securely connects to external data sources while blocking 94% of prompt injection attacks. These capabilities are bolstered by enterprise-grade certifications, including SOC II Type 2 and optional HIPAA compliance.
To optimize costs, Claude employs prompt caching, reducing input expenses by 90% for repetitive workflows. The Developer Console includes a workbench for prompt engineering, and the platform supports vision capabilities, making it adept at processing charts, graphs, and technical diagrams.
| Model | Input (per 1M tokens) | Output (per 1M tokens) | Context Window |
|---|---|---|---|
| Claude Opus 4.5 | $5.00 | $25.00 | 200K |
| Claude Sonnet 4.5 | $3.00 | $15.00 | 200K (1M beta) |
| Claude Haiku 4.5 | $1.00 | $5.00 | 200K |
Claude Opus 4.5 processes at 49 tokens per second, prioritizing deep analytical reasoning over speed, making it ideal for complex tasks. For quicker responses, Claude Sonnet 4.5 delivers 70 tokens per second with a latency of just 2.15 seconds. Individual users can opt for a Claude Pro subscription, priced at around $20 per month, for higher usage limits.
Next, we’ll explore how Google Gemini approaches multimodal AI capabilities.
Released in November 2025, Google's Gemini 3 family brings advanced multimodal AI capabilities, handling text, images, video, and audio seamlessly [33, 34]. The flagship model, Gemini 3 Pro, achieved an impressive 1501 Elo score on the LMArena leaderboard and scored 72.1% on SimpleQA Verified [33, 35].
Gemini 3 Pro stands out for its ability to handle complex reasoning tasks, scoring 91.9% on GPQA Diamond, and performing intricate multimodal operations with 81.0% accuracy on MMMU-Pro. Its 1M-token context window enables processing extensive datasets, such as entire codebases, lengthy video lectures, or hundreds of academic papers simultaneously [33, 35].
For applications requiring speed and cost-efficiency, Gemini 3 Flash processes data at just $0.50 per million input tokens. Meanwhile, Gemini 2.5 Flash-Lite, optimized for high-volume tasks, operates at an economical $0.02 per million tokens [35, 42].
"Gemini 3 is also much better at figuring out the context and intent behind your request, so you get what you need with less prompting." – Sundar Pichai, CEO, Google and Alphabet
In practical applications, JetBrains tested Gemini 3 Pro by generating thousands of lines of front-end code from a single prompt, showing a 50% performance improvement over Gemini 2.5 Pro in benchmarks. Similarly, Rakuten Group Inc. used Gemini 3 to transcribe multilingual meetings lasting three hours, excelling in speaker identification and outperforming baseline models by over 50%.
Gemini 3 underwent rigorous safety evaluations in collaboration with the UK AISI and independent firms like Apollo and Vaultis. These assessments revealed improved resistance to prompt injections and reduced sycophantic behavior compared to earlier versions. Google has also integrated SynthID into Gemini, a tool that embeds imperceptible digital watermarks into AI-generated images and text, ensuring traceability of AI-created content.
Gemini integrates seamlessly into Google Search, the Gemini app, AI Studio, and Vertex AI. Through Vertex AI, businesses gain access to over 200 foundation models, including an Agent Builder for creating AI agents using natural language. Queries can be enhanced with real-time search results or proprietary data stored in BigQuery and AlloyDB [37, 40, 41].
Real-world applications highlight Gemini's versatility. FOX Sports uses Vertex AI and Gemini to catalog and retrieve video highlights for broadcasts, while Wendy's has implemented a generative AI-driven drive-thru system to handle and display custom orders, streamlining customer interactions.
Gemini also offers cost-saving features like Context Caching, allowing users to store frequently used context at a 75% discount (with a 32,000-token minimum), and Batch Mode, which reduces token costs by 50% for tasks processed within 24 hours [42, 43]. These features make Gemini a flexible and cost-efficient solution for various business needs.
| Model | Input (per 1M tokens) | Output (per 1M tokens) | Best For |
|---|---|---|---|
| Gemini 3 Pro | $2.00 | $12.00 | Complex reasoning & coding |
| Gemini 3 Flash | $0.50 | $3.00 | General purpose tasks |
| Gemini 2.5 Flash-Lite | $0.02 | $0.02 | High-volume, simple queries |
For individual users, Gemini 2.5 Pro is available through Gemini Advanced for $19.99 per month [7, 36]. New Google Cloud customers can test Gemini on Vertex AI with $300 in free credits [37, 41]. Enterprises processing over 100 million tokens monthly can negotiate volume discounts ranging from 20% to 40%.
With the Gemini app now boasting over 650 million monthly users, the platform demonstrates its appeal to both individual consumers and large enterprises. The following sections will further explore the strengths and challenges of these offerings.
Every provider brings unique advantages and challenges, making their suitability dependent on your specific needs. Below, we break down the key factors that differentiate these providers.
OpenAI's GPT-5.2 stands out for its speed and mathematical reasoning, processing an impressive 187 tokens per second - 3.8 times faster than Anthropic's Claude Opus 4.5, which processes 49 tokens per second. This makes GPT-5.2 an excellent choice for real-time, customer-facing applications. However, its 400,000-token context window can be a limitation when working with extremely large datasets.
Anthropic's Claude Opus 4.5 excels in coding accuracy, achieving an 80.9% score on SWE-bench Verified, outperforming GPT-5.2's 80.0% and Gemini 3 Pro's 76.8%. Its policy of not training on customer data provides added privacy, which is a significant advantage for enterprise workflows. However, it comes with the highest cost - $5.00 per million input tokens and $25.00 per million output tokens - and struggles with complex reasoning tasks, scoring 78.4% on GPQA Diamond compared to GPT-5.2's 92.4%.
While Anthropic focuses on coding precision, Google's Gemini 3 Pro emphasizes multimodal capabilities and extensive context depth. With the largest context window at 1 million tokens (up to 2 million for enterprise customers), Gemini can handle text, images, audio, and video simultaneously. It also achieved an impressive top LMArena Elo score of 1501 by late 2025. However, Gemini has been known to produce irrelevant content during complex data analysis, and its pricing doubles when the input context exceeds 200,000 tokens.
When it comes to ecosystem integration, OpenAI leads with over 1,000 third-party connectors. Anthropic, however, captured 32% of the enterprise market share by mid-2025, surpassing OpenAI's 25%. Google's Gemini benefits from tight integration with Google Workspace, offering a seamless experience for organizations using GCP. However, it has faced criticism for its limited ecosystem, with only 50+ third-party integrations.
| Criterion | OpenAI (GPT-5.2) | Anthropic (Claude Opus 4.5) | Google (Gemini 3 Pro) |
|---|---|---|---|
| Primary Strength | Speed & Math Reasoning | Coding & Privacy | Multimodality & Context |
| Context Window | 400,000 tokens | 200,000 tokens (1M in beta) | 1,000,000 tokens (2M for Enterprise) |
| Inference Speed | 187 tokens/sec | 49 tokens/sec | 95 tokens/sec |
| Best Use Case | Real-time chatbots | Production software development | Research synthesis, video analysis |
| Pricing (Input/Output) | $1.75 / $14.00 per 1M tokens | $5.00 / $25.00 per 1M tokens | $2.00 / $12.00 per 1M tokens |
| Key Limitation | Limited context window | Slow inference, high cost | Ecosystem lock-in, pricing jumps |
These comparisons provide a clear view of each provider's strengths and challenges, helping you identify the best fit for your specific requirements.
Selecting the right AI language model provider depends heavily on your business's unique requirements. OpenAI's GPT-5.2 is a standout for creative content creation and conversational tasks, making it a go-to for marketing teams and customer-facing roles. On the other hand, Anthropic's Claude Opus 4.5 is tailored for technical applications, with a strong emphasis on privacy through its zero-training policy - an excellent fit for software development teams and industries with strict regulations. For research-driven organizations that rely on Google Workspace, Google's Gemini 3 Pro is a natural choice.
Many U.S. businesses are taking a strategic approach by deploying multiple providers, each selected for its specific strengths. This hybrid model not only avoids vendor lock-in but also ensures teams have access to the best tools for their particular needs.
To manage these diverse capabilities effectively, a unified orchestration solution becomes indispensable. Traditionally, managing multiple AI providers required juggling separate accounts, tracking costs across various billing systems, and handling complex integrations. Platforms like Prompts.ai simplify this process by offering a single control plane, granting access to over 35 leading language models - including GPT-5.2, Claude, and Gemini - all from one interface. This unified approach allows businesses to switch between models seamlessly, optimizing both performance and cost with features like real-time token tracking.
"The advantage of having a single control plane is that architecturally, you as a data team aren't paying 50 different vendors for 50 different compute clusters, all of which cost time and money to maintain." – Hugo Lu, CEO, Orchestra
For U.S. enterprises aiming to scale AI adoption efficiently, orchestration platforms provide a way to reduce tool sprawl, enforce governance, and lower AI software costs by up to 98%. These tools transform scattered, experimental efforts into streamlined, compliant workflows, while maintaining the flexibility to adapt as new models and technologies emerge.
To find the right AI language model provider for your business, start by clearly defining your goals. Identify the specific tasks you need the model to perform, whether it’s summarizing reports, writing code, or powering chatbots. Focus on your priorities and seek providers whose models specialize in those areas. For instance, some models are designed to handle extensive text processing, while others excel in real-time interactions or tasks involving multiple formats like images and audio.
Once you’ve outlined your needs, consider practical aspects such as cost, privacy, integration capabilities, and performance metrics. Examine factors like token-processing speed, context length, and pricing to ensure the model aligns with both your budget and technical requirements. If your business already uses tools like Google Workspace, choosing a provider with smooth integration can save time and reduce complexity during setup.
Lastly, take advantage of free trials or limited-access tiers to test different models within your workflows. Evaluate their performance based on quality, speed, and cost-efficiency. Combine these findings with considerations like vendor support and privacy assurances to make an informed decision that aligns with your business needs.
Pricing among providers shows a wide range, influenced by the model type and usage levels.
OpenAI caters to those seeking top-tier performance at a premium cost, Anthropic offers a balanced mid-range option, and Google stands out for its affordability, particularly for tasks requiring high volume or multimodal capabilities.
Businesses often rely on a mix of AI language model providers to address a variety of needs. Each provider brings its own strengths to the table - some shine in delivering real-time responses, others handle complex tasks like code generation with ease, and some offer budget-friendly solutions for high-volume workloads. By leveraging multiple providers, companies can strike the perfect balance of performance, cost, and efficiency, ensuring they always have the right tool for the task at hand.
This approach also offers practical benefits, such as avoiding vendor lock-in, ensuring uninterrupted service during potential outages, and meeting specific privacy or regulatory requirements. Furthermore, with AI technology advancing at a rapid pace, working with multiple providers keeps businesses agile and allows them to adopt cutting-edge features without waiting for a single vendor to catch up.


















