Pay As You GoEssai gratuit de 7 jours ; aucune carte de crédit requise


En 2026, la gestion des demandes d'IA n'est plus une question secondaire : elle fait partie intégrante de la création de systèmes d'IA évolutifs et efficaces. Alors que 75 % des entreprises devraient adopter l'IA générative, les outils qui simplifient les flux de travail rapides sont essentiels pour rester compétitives. Les meilleures plateformes actuelles rationalisent la gestion rapide sur plusieurs modèles, réduisent les coûts et améliorent la collaboration entre les équipes. Voici un bref aperçu des principaux outils :
Ces outils aident les équipes à proposer des fonctionnalités d'IA plus rapidement, à réduire les coûts opérationnels et à gérer la complexité croissante des flux de travail multimodèles. Que vous soyez une start-up ou une grande entreprise, l'adoption de l'une de ces plateformes permet d'économiser du temps et des ressources tout en améliorant les résultats de l'IA.
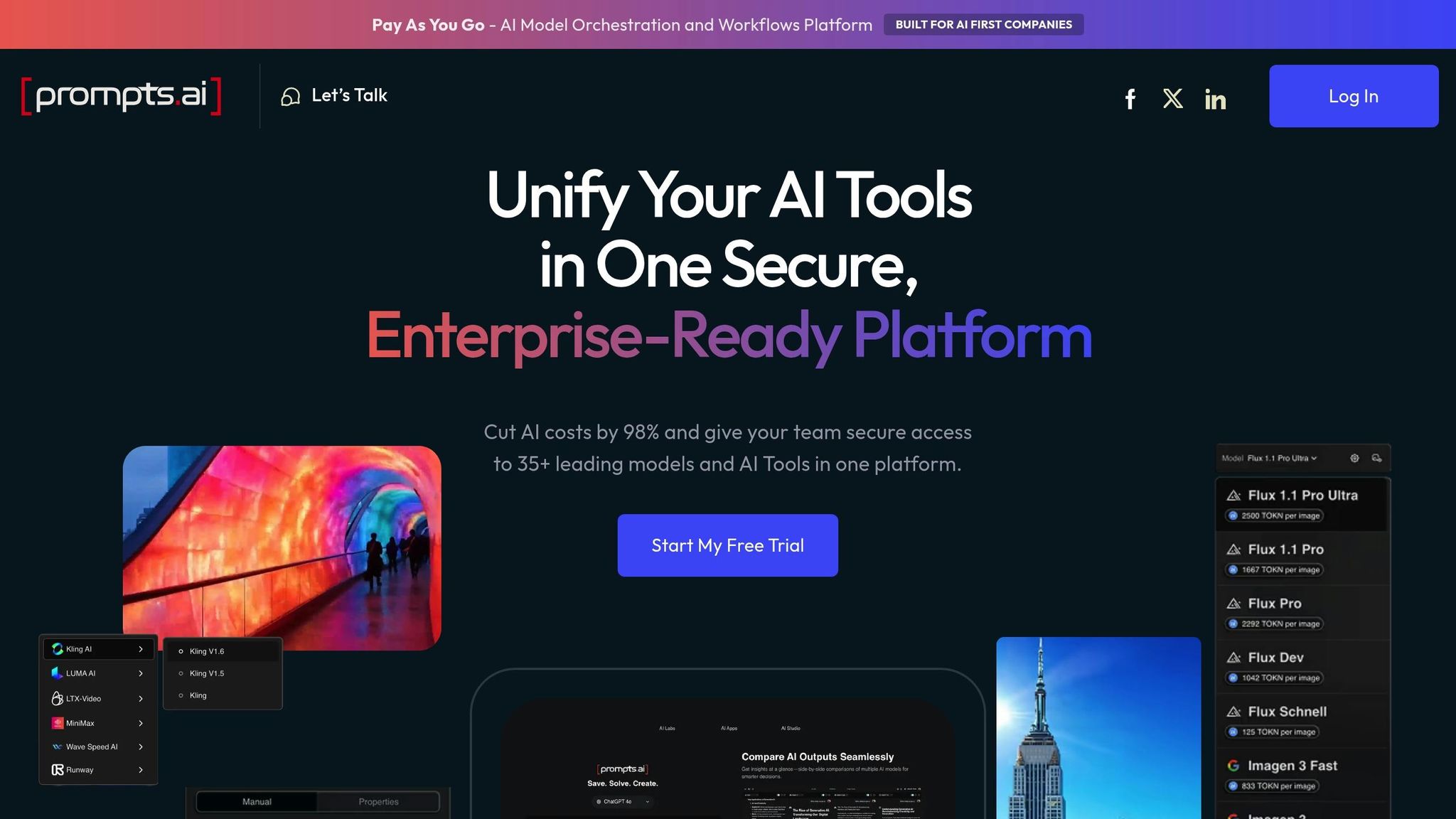
Prompts.ai est une plateforme conçue pour relever les défis de l'ingénierie rapide moderne. Il regroupe plus de 35 grands modèles de langage (LLM), tels que GPT-5, Claude, LLama, Gemini et Grok-4, dans une interface unique et cohérente adaptée aux opérations au niveau de l'entreprise. Vous trouverez ci-dessous un aperçu de ses caractéristiques les plus remarquables.
L'un des aspects clés d'une efficacité rapide réside dans la capacité à s'intégrer parfaitement à différents modèles. La plateforme Passerelle Bifrost sert de colonne vertébrale à l'accès multimodèle, offrant une connectivité unifiée à plus de 12 fournisseurs d'IA via une seule API compatible OpenAI. Cette configuration prend en charge les principaux fournisseurs tels que OpenAI, Anthropic, AWS Bedrock et Google Vertex. Pour garantir la fiabilité, le système intègre un basculement automatique et un équilibrage de charge, permettant des opérations ininterrompues même en cas de changement de fournisseur. Les équipes peuvent facilement passer d'un modèle à l'autre sans avoir à réécrire le code d'intégration, ce qui élimine le risque d'être bloquées sur un seul fournisseur.
Prompts.ai met fortement l'accent sur la gestion des coûts. Avec ses mise en cache sémantique fonctionnalité, la plateforme réutilise des réponses similaires pour réduire le traitement redondant. En outre, la couche FinOps intégrée surveille l'utilisation des jetons en temps réel, reliant ainsi les dépenses directement aux objectifs commerciaux. Cette approche proactive permet aux organisations de repérer les opportunités de réduction des coûts au fur et à mesure qu'elles se présentent, évitant ainsi les dépassements de budget imprévus à la fin du mois.
La plateforme s'intègre parfaitement à Actions sur GitHub, permettant des flux de déploiement spécifiques à l'environnement. Les équipes peuvent tirer parti de fonctionnalités telles que le contrôle des versions, les tests automatisés et les déploiements personnalisés pour différents environnements. En automatisant ces processus, la plateforme supprime les retards et les risques associés aux transferts manuels, garantissant ainsi une transition plus fluide de l'expérimentation à la production pour les fonctionnalités d'IA.
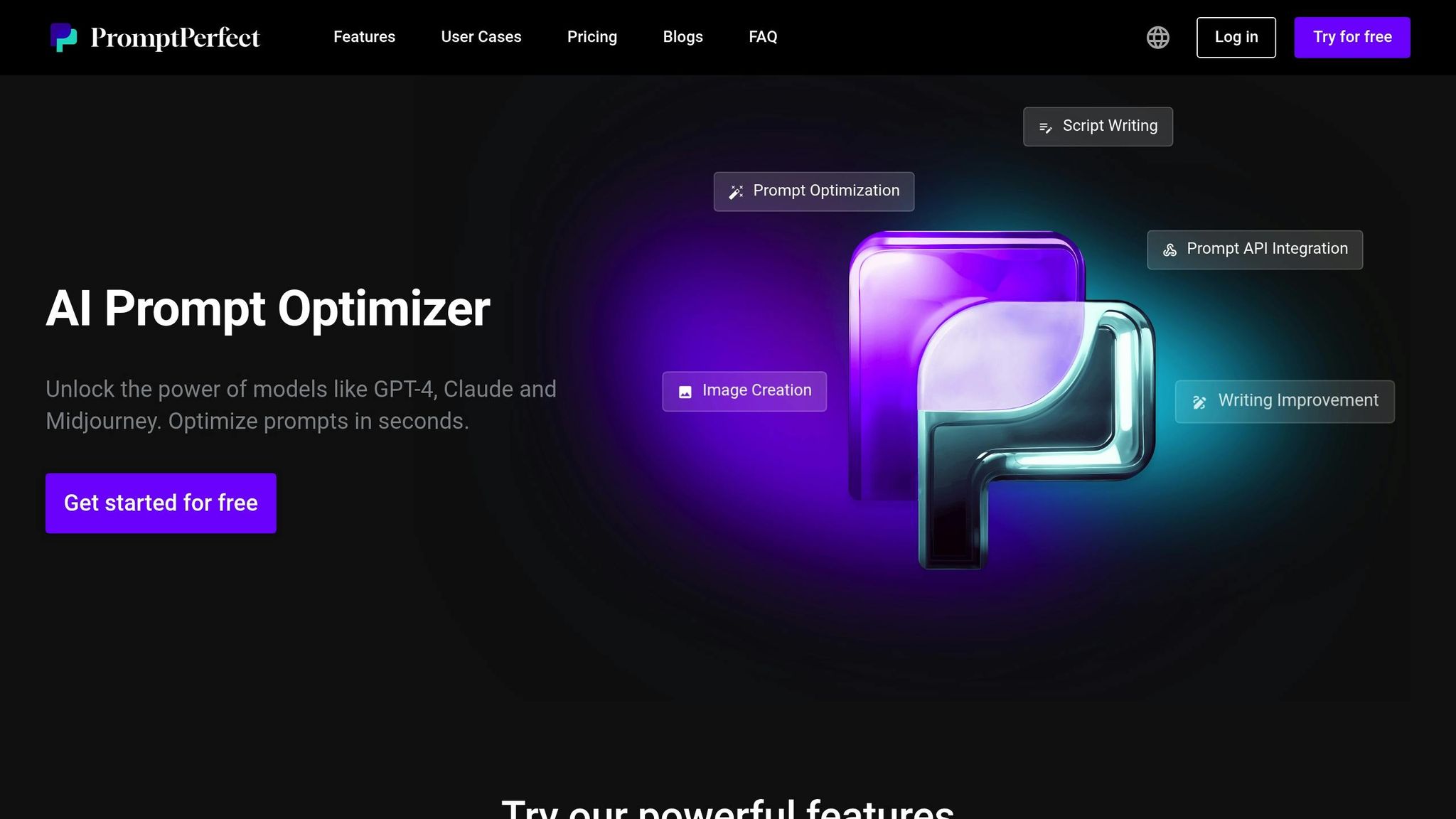
PromptPerfect utilise l'apprentissage par renforcement piloté par l'IA pour affiner les invites, en les adaptant à des objectifs tels que la clarté, la précision et la brièveté. Cet outil est particulièrement utile pour les créateurs de contenu, les spécialistes du marketing et les développeurs qui ont besoin d'ajustements rapides et efficaces. Il s'intègre parfaitement aux flux de travail avancés de l'IA, ce qui en fait un ajout précieux à tout pipeline de développement.
La plateforme fonctionne avec un large éventail de modèles, notamment le GPT-4 d'OpenAI, le Claude d'Anthropic et des générateurs d'images tels que DALL-E, Midjourney et Stable Diffusion. Sa fonction de comparaison de modèles côte à côte permet aux utilisateurs d'évaluer les réponses entre les modèles, ce qui permet d'identifier l'option la plus efficace pour leurs besoins. Au-delà des modèles basés sur du texte, PromptPerfect prend également en charge les invites pour différents types de supports, offrant ainsi flexibilité et économies. En outre, il permet une optimisation rapide du multilinguisme, garantissant ainsi que l'intention reste intacte dans les différentes langues.
PromptPerfect inclut des fonctionnalités conçues pour gérer efficacement les coûts. Sa comparaison multi-modèles aide les utilisateurs à trouver le modèle le plus économique tout en offrant la qualité souhaitée. En utilisant l'apprentissage par renforcement pour optimiser la durée des invites, la plateforme réduit l'utilisation des jetons, ce qui réduit directement les dépenses liées à l'API. L'automatisation minimise davantage les essais et les erreurs, ce qui permet de gagner du temps et de l'argent en matière de développement. Ce processus rationalisé garantit moins d'itérations et des coûts plus prévisibles pendant la phase d'ingénierie rapide.

LangChain Hub sert de plate-forme centralisée pour découvrir, partager et gérer des invites adaptées à divers grands modèles linguistiques. Il combine des outils tels que le contrôle des versions, des fonctionnalités collaboratives et l'automatisation du déploiement dans un flux de travail unique, spécialement conçu pour les ingénieurs rapides. En se concentrant sur une intégration fluide et des solutions soucieuses des coûts, LangChain Hub renforce les flux de travail tout en encourageant l'engagement de la communauté.
Le SDK de la plateforme permet aux utilisateurs d'intégrer des instructions dans des environnements tels qu'OpenAI, Anthropic, CrewAI, Vercel AI SDK et Pydantic AI. Grâce à la possibilité de filtrer les invites créées par la communauté en fonction de modèles, de cas d'utilisation ou de créateurs spécifiques, les utilisateurs peuvent garantir la compatibilité avec leurs LLM cibles. Le LangSmith Playground simplifie encore le développement en permettant de tester les invites sur différents modèles tels qu'OpenAI et Anthropic au sein d'une seule interface. Les invites sont stockées dans un format de modèle standardisé et sont accessibles via des balises stables telles que prod ou mise en scène, ce qui permet de les intégrer facilement dans le code quel que soit le modèle utilisé. Ces fonctionnalités répondent au besoin croissant du secteur en matière de gestion rapide rationalisée et complètent les intégrations similaires observées sur les plateformes précédentes, créant ainsi une expérience multimodèle cohérente.
LangChain Hub s'intègre également parfaitement aux pipelines GitHub et CI/CD, introduisant une synchronisation automatique pour simplifier les processus de déploiement. Les utilisateurs peuvent configurer des webhooks qui déclenchent des actions telles que le lancement d'un pipeline CI/CD ou une synchronisation rapide avec les référentiels GitHub chaque fois qu'une invite est validée. En utilisant des balises de validation telles que prod ou mise en scène, les utilisateurs peuvent mettre à jour les invites sans avoir à redéployer le code. Cette configuration permet également d'effectuer des annulations ou des mises à jour en un clic en réaffectant des balises à différents commits directement via l'interface du Hub, offrant ainsi flexibilité et contrôle en matière de gestion des notifications.
Le Public Prompt Hub agit comme un répertoire consultable dans lequel les utilisateurs peuvent explorer, télécharger et modifier les invites proposées par la communauté. Les fonctionnalités de découverte sociale, telles que le tri par favoris, vues ou téléchargements, aident les utilisateurs à trouver rapidement des invites de haute qualité. Le forking permet aux utilisateurs d'adapter les instructions publiques à leurs propres besoins, favorisant ainsi un développement et une amélioration itératifs. Ces outils axés sur la communauté reflètent les avantages de l'automatisation évoqués précédemment, en mettant l'accent sur la valeur de la collaboration. La plateforme a reçu une note de 4,5/5 sur recommend.ai (sur la base de 3 210 avis), les utilisateurs faisant l'éloge de sa vaste bibliothèque rapide et de sa facilité de partage. Comme Ethan Mollick l'a indiqué à juste titre dans une annonce de LangChain :
Le moment est venu de créer des grimoires... des bibliothèques rapides qui encodent l'expertise de leurs meilleures pratiques dans des formulaires utilisables par tous.
OpenAI Playground Pro simplifie le processus de développement et de déploiement des invites. Au cœur de sa conception se trouve le Système d'identification rapide, qui sécurise les brouillons publiés tout en permettant des améliorations continues sans perturber les applications actives. Cette approche garantit la flexibilité du déploiement et permet une gestion avancée des coûts.
Le Outil d'optimisation est conçu pour identifier et corriger rapidement les incohérences avant le déploiement, afin de minimiser le gaspillage de jetons. En intégrant Evals intégrés, les équipes peuvent connecter directement les évaluations aux invites, détectant ainsi les problèmes potentiels pendant les tests plutôt qu'en production. Comme le souligne le centre d'aide OpenAI :
Relancez votre Eval associé à chaque fois que vous publiez : il est beaucoup moins coûteux de détecter les problèmes rapidement que de les corriger en production.
La plateforme comprend également des outils de comparaison côte à côte, permettant aux équipes d'analyser visuellement différentes versions des invites et de choisir la plus efficace avant le déploiement. OpenAI déployant des mises à jour environ tous les trois jours, ces fonctionnalités sont essentielles pour maintenir des coûts prévisibles et gérables.
L'ID d'invite fait office de référence permanente, pointant toujours vers la dernière version d'une invite. Cela permet des mises à jour instantanées sans nécessiter de déploiements CI/CD complets. Les développeurs peuvent également épingler des versions spécifiques à des fins de gouvernance, garantissant ainsi un meilleur contrôle. Le système de mise à jour découplé permet aux équipes de modifier les instructions dans le Playground et de déployer les modifications instantanément, simplifiant ainsi la gestion des systèmes d'IA multi-agents. De plus, les annulations en un clic facilitent le contrôle des versions.
Variables définies à l'aide de {variable} la syntaxe s'intègre parfaitement à l'API Responses et au SDK Agents, garantissant que le modèle testé fonctionne exactement comme prévu en production. L'organisation au niveau des projets de la plateforme s'aligne sur les structures des équipes, ce qui permet aux ingénieurs de gérer et de localiser plus facilement les instructions prêtes pour la production. Des conventions claires de dénomination des dossiers permettent de réduire les tests dupliqués et les inefficacités.
L'intégration à la plateforme d'entreprise Frontier d'OpenAI étend encore les fonctionnalités, permettant l'interopérabilité entre différents clouds et environnements d'exécution. En prenant en charge les normes ouvertes, la plateforme élimine le besoin de changer de plateforme, renforçant ainsi son rôle dans la rationalisation des flux de travail d'ingénierie rapides.

PromptLayer sert de système centralisé pour enregistrer chaque interaction d'API entre votre application et les fournisseurs LLM. En créant un registre unifié pour les flux de travail multimodèles, il est devenu un choix de premier plan pour une gestion et une collaboration rapides dès le début de 2026.
L'ingénierie rapide nécessite souvent des transitions fluides entre les modèles et celui de PromptLayer CMS rapide simplifie ce processus. Il stocke des modèles auxquels les développeurs peuvent accéder par programmation via un SDK. Cette configuration permet de changer de modèle ou de mettre rapidement à jour la logique via un tableau de bord visuel intuitif. Il n'est pas nécessaire de redéployer le code. Les membres de l'équipe non techniques peuvent modifier les instructions en temps réel, et ces mises à jour sont immédiatement répercutées dans la production. En outre, la plateforme offre des fonctionnalités de test par lots, permettant la régression et le backtesting des invites sur différents modèles.
PromptLayer ne se contente pas de rationaliser les flux de travail, il permet également de gérer efficacement les coûts. En surveillant les tendances en matière de coûts et de latence entre les fonctionnalités et les modèles, il fournit des informations sur l'utilisation des ressources. Les historiques des demandes enregistrées sont enrichis de métadonnées et de balises, ce qui permet d'identifier facilement les demandes lentes ou coûteuses. Chaque appel d'API est versionné et suivi, ce qui permet aux utilisateurs d'évaluer les ratios coûts-performances des différents fournisseurs. Il est ainsi plus facile de déterminer quels modèles offrent le meilleur équilibre entre performances et valeur pour des tâches spécifiques.
PromptLayer s'intègre parfaitement aux pipelines de déploiement existants, offrant des fonctionnalités telles que étiquettes de sortie et la mise en cache pilotée par Webhook. Les développeurs peuvent utiliser des étiquettes (par exemple, « prod » ou « staging ») dans le SDK pour mettre à jour les modèles d'invite via le tableau de bord visuel, les modifications prenant effet immédiatement, aucun redéploiement du code d'application n'étant requis. Pour les scénarios de trafic élevé, la mise en cache pilotée par les webhooks garantit la mise à jour des caches ou des bases de données locaux chaque fois qu'un modèle d'invite est modifié. Cela permet de réduire la latence tout en préservant la fiabilité. Pour les flux de travail plus complexes, la plateforme fournit une infrastructure d'agents gérés qui coordonne les communications des modèles et déclenche les déploiements via des API.

Comparaison des 5 meilleurs outils d'ingénierie rapide pour 2026 : fonctionnalités, prix et meilleurs cas d'utilisation
Lorsque vous choisissez un outil d'ingénierie rapide, votre décision dépendra probablement de facteurs tels que la taille de l'équipe, le budget et les besoins techniques. Les plateformes examinées ici proposent une variété de modèles de tarification, allant des options gratuites aux plans personnalisés adaptés aux grandes entreprises. Vous trouverez ci-dessous une ventilation des structures tarifaires, des fonctionnalités de gestion des coûts et des fonctionnalités d'interopérabilité.
Prompts.ai utilise un système de crédit TOKN par paiement à l'utilisation, avec des forfaits professionnels à partir de 99$ par membre et par mois pour le niveau Core et à 129$ par membre et par mois pour le plan Elite. Ce modèle évite les frais récurrents tout en donnant accès à plus de 35 LLM, à un suivi des coûts FinOps intégré et à des outils de gouvernance au niveau de l'entreprise. Parfait et rapide, d'autre part, s'adresse aux créateurs individuels et aux petites équipes, en proposant des forfaits payants axés sur l'optimisation des invites sur des modèles tels que GPT-4 et Claude. Hub LangChain, disponible via LangSmith, propose un niveau gratuit avec des options de tarification supplémentaires pour les grandes organisations travaillant au sein de l'écosystème LangChain. OpenAI Playground Pro s'en tient à un système de facturation basé sur l'utilisation et basé sur le paiement par jeton, ce qui le rend mieux adapté au prototypage qu'aux opérations à grande échelle. Enfin, couche rapide utilise un modèle freemium, avec des niveaux payants offrant une gestion des versions de style Git et des analyses au coût par demande, ce qui est idéal pour les petites équipes ou les projets en phase de démarrage.
Du point de vue de la gestion des coûts, chaque plateforme propose des outils uniques. Prompts.ai offre un suivi des coûts en temps réel sur plusieurs LLM, ce qui permet aux équipes de se développer plus facilement sans perdre la supervision financière. PromptPerfect tire parti de l'apprentissage par renforcement pour optimiser les invites, réduire l'utilisation des jetons et économiser sur les coûts d'API. LangChain Hub intègre la surveillance de l'utilisation des jetons dans ses niveaux de tarification, tandis qu'OpenAI Playground Pro offre une visibilité claire sur les coûts des jetons via son modèle basé sur l'utilisation. PromptLayer se concentre sur le suivi des coûts et de la latence pour chaque version d'un prompt, ce qui permet aux équipes d'évaluer l'équilibre coût-performance entre les fournisseurs.
L'interopérabilité est un autre domaine dans lequel ces plateformes diffèrent. Prompts.ai se connecte à plus de 35 LLM via une interface unifiée, éliminant ainsi les tracas liés à la gestion de plusieurs clés API et comptes de facturation. PromptLayer utilise des modèles indépendants du modèle, permettant des transitions fluides entre les fournisseurs sans réécrire la logique. LangSmith propose une instrumentation intégrée pour les applications LangChain et LangGraph, tandis qu'OpenAI Playground Pro fournit un accès direct aux paramètres du modèle OpenAI. Pour les entreprises, les plateformes telles que Prompts.ai se distinguent par leur gouvernance centralisée, leur conformité à la norme SOC 2 et leur surveillance avancée des coûts, ce qui permet d'éviter une prolifération rapide et des frais imprévus lors des déploiements d'IA à grande échelle.
Voici une comparaison rapide des principales fonctionnalités :
Pour les petites équipes aux budgets serrés, le niveau freemium de PromptLayer constitue un point de départ solide. Les équipes de taille moyenne peuvent bénéficier de la tarification échelonnée de LangChain Hub, qui équilibre les fonctionnalités de débogage avec des coûts gérables. Pour les grandes entreprises, Prompts.ai fournit une gouvernance centralisée, des certifications de conformité et une gestion évolutive de l'IA, le tout sans frais cachés.
Le choix du bon outil de gestion rapide peut redéfinir la manière dont les organisations déploient l'IA. Étant donné que l'adoption générative de l'IA devrait atteindre 75 % des entreprises d'ici 2026, le passage d'instructions statiques codées en dur à une approche systématique et évolutive n'est plus une option, mais une nécessité.
Les organisations qui mettent en œuvre des pratiques éprouvées de gestion rapide obtiennent des résultats plus rapides, grâce à un contrôle de version structuré qui réduit considérablement les délais de déploiement. Bien que chaque plateforme abordée ici réponde à des besoins uniques, elles relèvent toutes le même défi : éliminer les obstacles au développement de l'IA.
L'ajustement des instructions codées en dur peut prendre des jours, mais les outils dédiés permettent des mises à jour en quelques minutes. Cela permet aux chefs de produit, aux experts du domaine et aux concepteurs d'itérer de manière indépendante, ce qui accélère les cycles de développement et réduit les coûts. De plus, ces outils permettent d'éviter des erreurs coûteuses. Sans évaluation systématique, les équipes sont confrontées à des taux de régression plus élevés et risquent de gonfler les coûts opérationnels de 30 à 50 % en raison d'une utilisation inefficace des jetons. Des fonctionnalités telles que le suivi des coûts en temps réel, les tests automatisés et l'observabilité de la production remplacent les conjectures par des informations exploitables, garantissant ainsi des décisions fondées sur les données.
Que vous lanciez votre première fonctionnalité d'IA ou que vous gériez un écosystème complexe d'instructions sur plusieurs modèles, les bons outils permettent de mettre de l'ordre dans un éventuel chaos. En intégrant une gestion rapide agile à une analyse des coûts en temps réel, ces plateformes offrent la précision et les performances nécessaires pour répondre aux exigences du paysage de l'IA de 2026. Pour les équipes qui souhaitent faire évoluer leurs opérations tout en maintenant une gouvernance au niveau de l'entreprise et un accès fluide à de grands modèles linguistiques, Prompts.ai offre l'agilité et la supervision nécessaires pour réussir.
Prompts.ai apporte des avantages distincts aux entreprises qui mettent l'accent sur l'ingénierie rapide. En centralisant l'accès à plus de 35 grands modèles linguistiques (LLM) de premier plan, tels que GPT-4, Claude et Gemini, la plateforme permet aux utilisateurs de gérer plusieurs modèles de manière fluide à partir d'un seul endroit. Cette intégration simplifie non seulement les flux de travail, mais élimine également les tracas liés à la jonglerie entre plusieurs outils, ce qui se traduit par une efficacité accrue.
La plateforme répond également aux problèmes de coûts grâce au suivi en temps réel des dépenses et de l'utilisation des jetons, offrant la possibilité de réduire les coûts opérationnels de l'IA jusqu'à 98 %. En plus de cela, il donne la priorité sécurité, gouvernance et conformité au niveau de l'entreprise, en veillant à ce que toute gestion rapide soit conforme aux politiques et normes de l'entreprise.
Pour rationaliser davantage les processus, Prompts.ai inclut des fonctionnalités telles que le contrôle rapide des versions et les tests structurés. Ces outils permettent aux équipes de développer, de tester et de déployer des instructions de manière cohérente et précise. Sa capacité à évoluer et à s'intégrer aux systèmes existants en fait un choix puissant pour les organisations qui souhaitent augmenter la productivité, contrôler les dépenses et respecter des normes rigoureuses dans le cadre de leurs initiatives d'IA.
L'optimisation des coûts en temps réel dans les outils d'ingénierie rapide repose sur des fonctionnalités intelligentes telles que le routage rapide dynamique, le suivi de l'utilisation des jetons et la surveillance des coûts. Ces outils évaluent les flux de travail à la volée, orientent les tâches les plus simples vers des modèles plus abordables et ajustent la complexité rapide pour réduire les coûts.
En suivant activement la consommation de jetons et les dépenses liées aux modèles, ces plateformes permettent d'éviter les frais imprévus et de maintenir un contrôle budgétaire efficace. Cela est particulièrement crucial pour les opérations d'IA à volume élevé, où la tarification basée sur des jetons peut augmenter rapidement. Grâce au suivi et à l'optimisation intégrés des coûts, les équipes peuvent étendre leurs flux de travail de manière efficace tout en maîtrisant les dépenses.
L'interopérabilité avec les différents modèles d'IA est cruciale pour une gestion rapide et fluide, car elle permet aux équipes d'intégrer et de superviser plusieurs grands modèles de langage (LLM) au sein d'un flux de travail unifié. Les systèmes avancés tels que GPT-5, Claude, Gemini et LLama devenant de plus en plus répandus, la gestion séparée de chaque modèle peut rapidement devenir inefficace et fastidieuse.
L'utilisation d'outils qui fonctionnent sur plusieurs LLM permet aux organisations de choisissez le modèle le plus adapté à des tâches spécifiques, simplifiez les processus et réduisez les coûts opérationnels. Cette stratégie favorise la cohérence, permet une meilleure utilisation des ressources et facilite le déploiement, tout en préservant l'efficacité et la préparation des équipes face à l'évolution rapide du paysage de l'IA.


















