Pay As You Go - AI Model Orchestration and Workflows Platform


Improving machine learning (ML) model performance is critical for reducing costs, speeding up deployment, and boosting efficiency. This article outlines key challenges like overfitting, high computational demands, and deployment bottlenecks, alongside proven strategies to address them.
Start by benchmarking your workflows, optimize with these methods, and track results for measurable ROI.
Scaling machine learning models often brings hurdles that impact their accuracy, efficiency, and reliability.
Overfitting happens when a model becomes overly complex for the training data, essentially memorizing specific examples instead of identifying patterns that apply to unseen data. This issue is common when data is insufficient or inconsistent. On the other hand, underfitting occurs when a model is too simplistic, failing to grasp the underlying patterns in the data, which results in poor performance on both training and new datasets.
Deep learning models demand substantial computing resources due to their intricate architectures and deep layers. The reliance on 32-bit floating-point precision further amplifies these computational requirements. For organizations managing multiple training jobs simultaneously, these demands can quickly escalate operational expenses.
Even models that excel during training can encounter difficulties when deployed in environments with limited resources. As highlighted by Google Cloud:
LLMs that are very large can be highly performant on massive training infrastructure, but very large models might not perform well in capacity-constrained environments like mobile devices.
Challenges arise from limited processing power and memory on edge devices, strict latency requirements, and constraints on data input and output. Moreover, scaling training across multiple GPUs introduces synchronization delays and inter-GPU communication overhead, which can hinder performance gains and reduce overall system reliability.
These obstacles underline the importance of performance optimizations, which will be explored further in the next section.
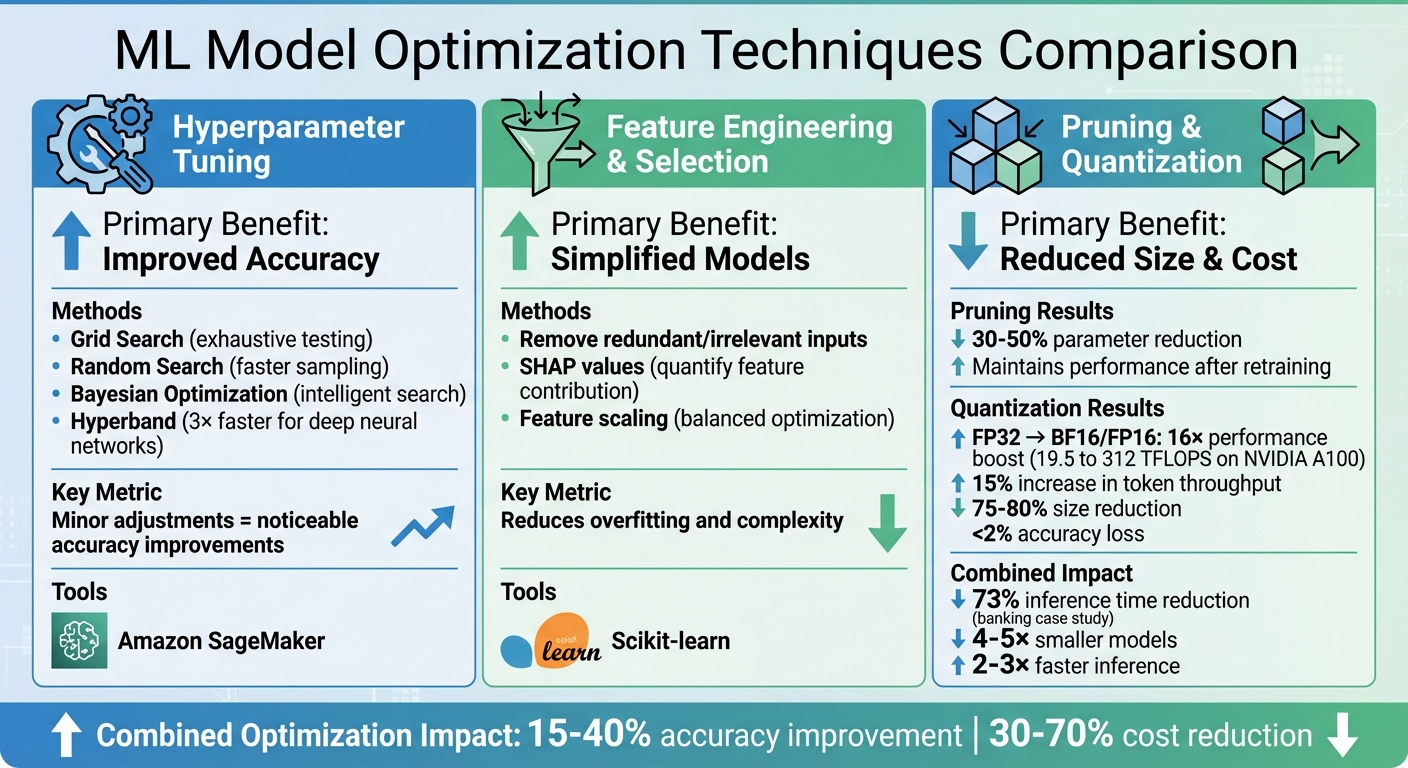
ML Model Optimization Techniques: Impact on Performance and Cost Savings
Achieving better machine learning (ML) model performance involves techniques that enhance accuracy, reduce resource consumption, and enable seamless scalability.
Hyperparameters dictate critical aspects of a model, such as learning rate, architecture, and complexity. Unlike parameters learned during training, hyperparameters must be manually adjusted to balance overfitting and underfitting. Popular methods include Grid Search, which exhaustively tests all combinations, and Random Search, which samples configurations for quicker results. For a more intelligent approach, Bayesian Optimization uses probabilistic models to identify promising hyperparameter sets.
For large-scale models, particularly deep neural networks in computer vision, Hyperband can speed up hyperparameter tuning by up to three times compared to Bayesian methods. Even minor adjustments to hyperparameters can lead to noticeable accuracy improvements. Platforms like Amazon SageMaker simplify this process by offering automated tuning with Bayesian search and Hyperband. Once hyperparameters are optimized, focusing on input features can further enhance performance.
The input features you provide a model play a pivotal role in its success. Too few features can hinder generalization, while too many can lead to overfitting and unnecessary complexity. Features that are highly correlated with each other or irrelevant to the target variable can also degrade performance and obscure model interpretability.
Feature selection techniques help identify and remove redundant or uninformative inputs. One approach is to iteratively add or remove features, testing their impact on the model’s performance. Tools like SHAP (SHapley Additive exPlanations) values can quantify the contribution of each feature, making it easier to eliminate those with minimal impact. Additionally, preprocessing techniques such as feature scaling ensure that input variables are properly balanced during optimization, improving model stability. Libraries like Scikit-learn provide accessible implementations for many feature selection and preprocessing methods.
Streamlining models through pruning and quantization can significantly reduce computational demands while maintaining accuracy.
Pruning removes unnecessary weights from the model. Magnitude-based pruning, followed by retraining, can maintain performance while reducing parameters by 30–50%. This process not only decreases model size but also makes inference faster and more efficient.
Quantization reduces the precision of numerical values in a model. For instance, converting 32-bit floating-point values to 16-bit or 8-bit integers can lead to substantial performance gains. On NVIDIA A100 GPUs, lowering precision from FP32 to BF16/FP16 can theoretically increase performance from 19.5 TFLOPS to 312 TFLOPS - a 16× improvement. In language model training, using lower precision data types has shown a 15% increase in token throughput. Quantization typically shrinks model size by 75–80% with minimal accuracy loss (usually less than 2%). While post-training quantization is simple, it may slightly affect accuracy; quantization-aware training addresses this by considering precision constraints during the training phase, preserving performance more effectively.
Combining pruning and quantization can yield even greater benefits. For example, a major bank reduced inference time by 73% using these methods. Models that undergo pruning followed by quantization are often 4–5× smaller and 2–3× faster than their original counterparts. To ensure these optimizations deliver real-world benefits, it’s essential to benchmark metrics like inference time, memory usage, and FLOPS throughout the process.
Advanced tools take machine learning workflows to the next level, improving training, inference, and deployment processes. These tools address common production challenges, helping teams speed up deployment and create scalable, efficient systems while maintaining high accuracy.
XGBoost is a standout choice for structured data tasks like regression, classification, and clustering. Its ability to efficiently handle large datasets and deliver high performance makes it a go-to tool for many machine learning practitioners.
Transfer learning leverages pre-trained models, such as ResNet-50 trained on ImageNet, to simplify and accelerate the process of fine-tuning for specific tasks. This approach is especially helpful when working with limited training data, as it taps into patterns learned from larger, diverse datasets to enhance performance. However, it's important to note that pre-trained models can sometimes carry biases from their original training data.
TensorRT is designed to optimize deep learning models for inference, increasing throughput and minimizing latency. This makes it ideal for high-performance applications.
ONNX Runtime offers a versatile, cross-platform solution for deploying models from frameworks like PyTorch, TensorFlow/Keras, TFLite, and scikit-learn. It supports deployment across a range of hardware and programming environments, including Python, C#, C++, and Java. Both tools enhance inference efficiency and ensure optimal resource use in production settings.
Managing multiple AI models and tools can quickly drive up costs and complexity for machine learning (ML) teams. To tackle this, orchestration platforms play a key role in streamlining operations and improving performance. Prompts.ai simplifies these challenges by offering a single interface to centralize model access, enforce governance, and monitor AI spending.
Prompts.ai optimizes model management by unifying access to over 35 leading AI models - including GPT-5, Claude, Gemini, and LLaMA - through a single API. Switching between models is as simple as adjusting a configuration setting. The platform also includes a versioned prompt template library, enabling teams to reuse effective workflows across departments. For example, a U.S.-based customer support team could set up a workflow that retrieves knowledge-base articles, routes queries to the most cost-efficient model based on complexity, checks for sensitive data, and logs every interaction. This setup allows teams to test new models in staging environments while keeping stable versions in production, promoting updates only after thorough evaluation.
Prompts.ai integrates financial operations directly into AI workflows, providing real-time tracking of spending by model, team, and project. Dashboards present costs in USD with detailed breakdowns by day or hour, reflecting token usage and provider pricing. Organizations can set budgets - for instance, capping a sales project at $25,000 per month - and receive alerts when spending hits 75%, 90%, or 100% of the limit. Dynamic routing rules further optimize costs by assigning low-risk tasks to more affordable models while reserving premium options for critical work. By linking model usage to business outcomes, the platform calculates cost-per-outcome metrics, helping decision-makers assess return on investment (ROI). This level of cost control also supports benchmarking and ensures compliance.
Prompts.ai allows teams to benchmark models side-by-side using real workloads and U.S.-specific prompts, such as dollar-based pricing and MM/DD/YYYY date formats. Metrics like latency (p95 response time), cost per 1,000 tokens, and quality scores provide actionable insights. For example, a comparison might show one model is 28% cheaper but 6% less accurate for compliance-sensitive queries, guiding policy decisions. On the compliance front, the platform enforces role-based access control and integrates with single sign-on (SSO) to restrict sensitive workflow modifications to authorized users. Built-in guardrails prevent external models from accessing sensitive data, while centralized audit logs support SOC 2, HIPAA, and other regulatory reviews. Prompts.ai began its SOC 2 Type 2 audit process on June 19, 2025, and maintains a public Trust Center for real-time updates on its security posture.
Improving the performance of machine learning models isn’t just a technical necessity - it directly influences your bottom line. By leveraging proven optimization strategies, businesses can enhance model accuracy by 15–40% while slashing inference costs by 30–70%. For instance, a U.S. company handling 50 million predictions monthly could save hundreds of thousands of dollars annually by switching to optimized runtimes like TensorRT or ONNX Runtime at standard cloud GPU pricing.
The key challenge lies in balancing accuracy, speed, and cost for each use case. Take a mobile banking app as an example - it might prioritize pruned or quantized models to minimize latency and conserve battery life across millions of devices. Meanwhile, a fraud detection system could reserve high-accuracy models for critical transactions, routing lower-risk queries through more cost-effective alternatives. Prompts.ai simplifies this decision-making process by centralizing model selection and cost tracking, making these trade-offs easier to manage.
To begin realizing returns, start by benchmarking your current performance and costs across 1–3 key ML workflows. Focus on achievable improvements, such as hyperparameter tuning or adopting optimized runtimes, to secure quick wins. Integrating these workflows into Prompts.ai allows you to monitor performance metrics, experiment with pruned or distilled models, and tie model usage directly to business outcomes - whether that’s reducing cost per prediction, meeting latency SLAs, or increasing revenue per visitor. These efforts can help you estimate a payback period of 6–18 months.
Beyond these immediate optimizations, Prompts.ai provides a framework for long-term governance and scalable returns. By unifying finance, risk, and engineering teams under a single platform, it institutionalizes AI spend management and compliance. Features like centralized audit logs, role-based access controls, and built-in guardrails ensure that only vetted, high-performing models make it to production. This streamlined approach turns isolated improvements into a repeatable, scalable process, enhancing both model performance and organizational compliance. The result? Tangible productivity gains and measurable ROI across your enterprise.
Hyperparameter tuning involves fine-tuning a machine learning model's settings - like the learning rate, batch size, or number of layers - to improve its performance. By systematically experimenting with various combinations, you can boost the model's accuracy and ensure it generalizes effectively to unseen data.
When done right, tuning minimizes errors and avoids overfitting, helping the model perform reliably beyond just the training dataset. Techniques such as grid search, random search, or using automated frameworks can simplify and speed up this optimization process.
Optimizing machine learning models for performance and efficiency often involves two key techniques: pruning and quantization.
Pruning focuses on trimming down a model by eliminating parameters that aren't essential. By reducing the model's size and complexity, it achieves faster computations and uses fewer resources, all while maintaining accuracy at near-original levels.
Quantization tackles memory and computational demands by using lower-precision data types for model weights and activations - like switching from 32-bit to 8-bit. This approach not only accelerates inference but also ensures the model can run effectively on hardware-constrained devices, such as smartphones or edge devices.
Prompts.ai makes managing expenses straightforward with its pay-as-you-go system, offering access to more than 35 AI models. This approach allows users to reduce costs by up to 98%, paying only for what they actually use. It's a smart way to keep budgets under control without sacrificing access to powerful tools.
For organizations prioritizing security and compliance, Prompts.ai provides a secure, enterprise-ready platform. With strong governance features, it ensures controlled access to AI tools and workflows, helping businesses meet regulatory standards while safeguarding their data.



















