Pay As You Go - AI Model Orchestration and Workflows Platform


Managing multiple large language models (LLMs) can be complex, but the right tools make it easier. Platforms like Prompts.ai, Amazon SageMaker, Azure Machine Learning, Hugging Face Transformers, Comet ML, and DeepLake simplify workflows, reduce costs, and improve security. Here's what you need to know:
Quick takeaway: Choose tools based on your team's needs - whether it's cost optimization, scalability, or security - while ensuring they align with your infrastructure and goals.
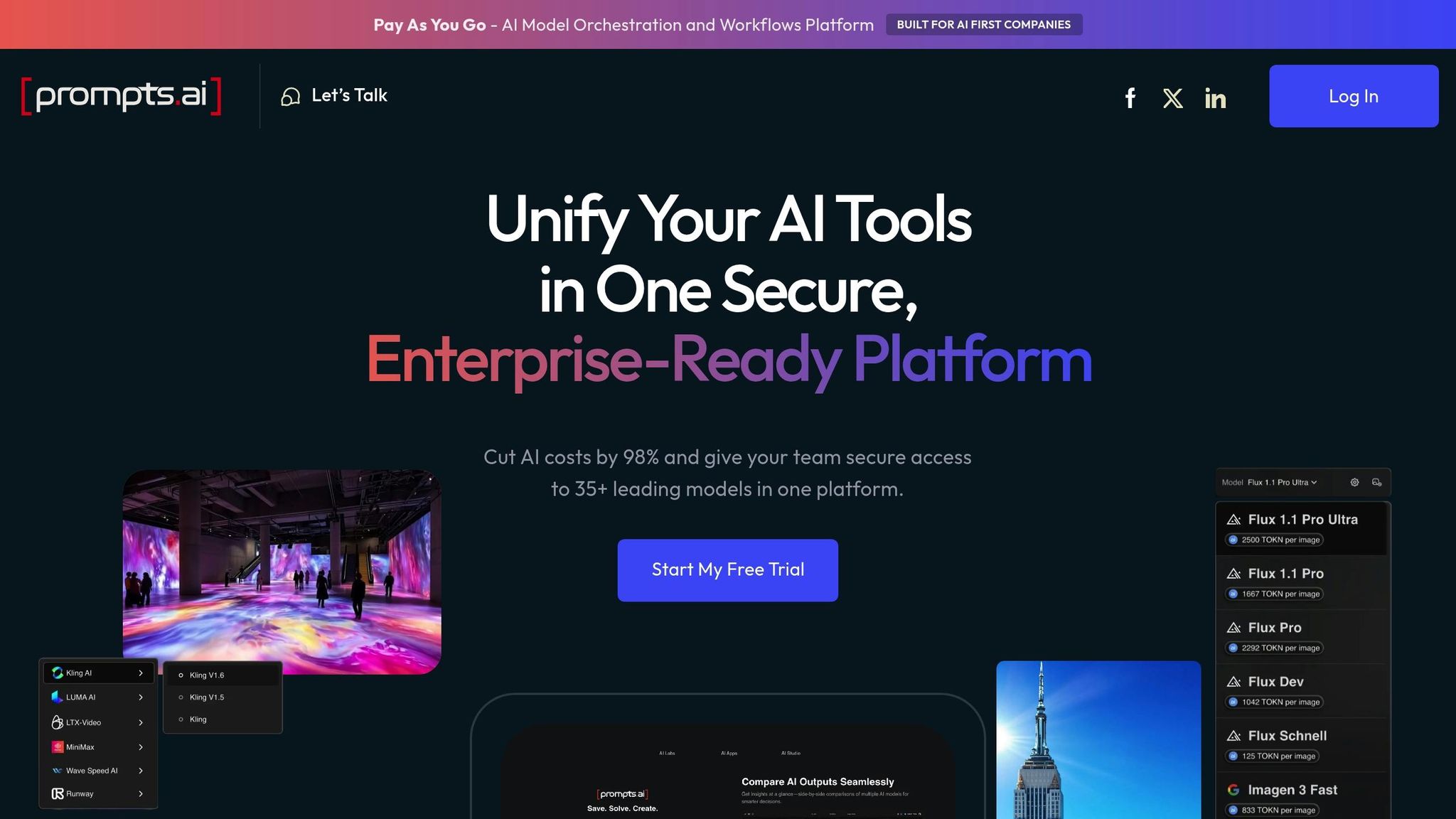
Prompts.ai brings together over 35 top-tier AI models, including GPT-5, Claude, LLaMA, and Gemini, into a single, unified platform. By addressing the complexities of managing multiple large language models (LLMs), it eliminates the inefficiencies caused by scattered tools.
With its centralized prompt management system, Prompts.ai allows teams to design, test, and deploy prompts across various models effortlessly. The platform ensures seamless version tracking, helping maintain consistency across AI workflows.
The platform's workflow orchestration tools simplify multi-LLM management through automated pipelines. Teams can compare model outputs side by side, making it easier to identify the best-performing configurations for specific tasks.
Prompts.ai also integrates smoothly with frameworks like LangChain, Hugging Face, and Vercel AI SDK, as well as cloud services such as AWS Bedrock and Azure OpenAI. These integrations streamline workflow automation and model evaluation without requiring extensive technical adjustments.
These features not only improve efficiency but also pave the way for better cost management and stronger security protocols.
Prompts.ai delivers detailed cost tracking and analytics, offering token-level monitoring to track usage and expenses for each LLM in real time. By consolidating AI tools, the platform boasts up to 98% cost savings.
Through real-time dashboards, users gain insights into cost attributions, enabling more efficient prompt designs. This transparency allows teams to pick the most cost-effective models for their needs without compromising performance. Additionally, the platform transforms fixed costs into scalable, on-demand expenses, making AI adoption more flexible and manageable.
For example, a financial services company used Prompts.ai to manage workflows across OpenAI, Anthropic, and Google VertexAI models. By centralizing prompt management and cost tracking, they cut operational overhead by 30% and enhanced response accuracy by leveraging the strengths of individual models for different tasks.
Prompts.ai prioritizes security with features like role-based access, audit logging, and encryption. It supports compliance with key standards, including SOC 2 Type II, HIPAA, and GDPR, ensuring organizations meet regulatory requirements when managing multiple LLMs.
The platform partners with Vanta for continuous control monitoring and began its SOC 2 Type II audit process on June 19, 2025. Its Trust Center provides real-time updates on security policies, controls, and compliance, giving organizations full visibility into their security posture.
All enterprise plans include governance and compliance tools, offering complete transparency and auditability for all AI interactions. This robust security framework enhances governance while meeting the demands of enterprise-scale operations.
Prompts.ai's architecture is designed to scale horizontally, managing dozens or even hundreds of LLM instances. Automated load balancing and resource allocation ensure optimal performance, while intelligent routing directs requests to the most suitable model based on predefined criteria.
The platform supports both cloud and on-premises deployments, offering flexibility for organizations with diverse infrastructure needs. Its scalable design allows for seamless expansion without major reconfigurations, catering to both small teams and large enterprises.
Real-time monitoring tools include automated alerts for prompt failures, latency issues, and cost overruns, ensuring reliable operations in production environments. Performance dashboards track latency, response quality, and model drift, enabling teams to quickly resolve issues and fine-tune model selection for specific tasks.
Amazon SageMaker provides a robust platform for deploying and managing multiple large language models (LLMs) at scale. It offers enterprise-level infrastructure designed to address the challenges of LLM deployment, focusing on orchestration, cost efficiency, security, and scalability.
SageMaker's Model Registry acts as a centralized hub for managing various LLM versions. It allows teams to track model lineage, store metadata, and manage approval workflows across different models. For streamlined operations, SageMaker Pipelines automates complex workflows, enabling the orchestration of multiple LLMs in either sequential or parallel configurations.
With Multi-Model Endpoints, teams can host several LLMs on a single endpoint, dynamically loading models as needed. This setup not only cuts down infrastructure costs but also ensures flexibility in choosing models. Whether it’s BERT, GPT variants, or custom fine-tuned models, they can all be deployed on the same infrastructure.
For large-scale inference tasks, SageMaker's Batch Transform is a game-changer. It efficiently handles massive datasets across multiple models, managing resource allocation and job scheduling automatically to optimize compute usage.
SageMaker integrates seamlessly with AWS Cost Explorer, offering detailed tracking of expenses across LLM deployments. Its Spot Training feature can cut training costs by as much as 90% by leveraging unused AWS capacity for model fine-tuning and experiments.
The platform's Auto Scaling feature adjusts compute resources in response to traffic demands, supporting both horizontal and vertical scaling. This ensures that organizations maintain performance while keeping costs under control.
SageMaker's Inference Recommender takes the guesswork out of deployment by analyzing various instance types and configurations. It provides tailored recommendations based on latency, throughput, and budget constraints, helping teams find the most cost-effective setup for their LLM workloads.
SageMaker employs AWS's robust security measures, including encryption both at rest and in transit, to protect model artifacts and data. The platform supports VPC isolation, ensuring that all operations - such as training and inference - are conducted within private network boundaries.
Through IAM integration, organizations can implement fine-grained access controls, assigning role-based permissions for managing models, datasets, and deployment environments. This ensures that access is restricted based on user roles and responsibilities.
The platform also complies with major industry standards, including SOC 1, SOC 2, SOC 3, PCI DSS Level 1, ISO 27001, and HIPAA. Additionally, SageMaker offers comprehensive audit logging to track all model management activities, aiding in both security monitoring and compliance reporting.
SageMaker is built to handle the demands of multi-LLM environments, scaling fine-tuning operations across GPUs and provisioning capacity for both real-time and batch inference. It can handle thousands of concurrent requests while optimizing resource use through data and model parallelism.
Thanks to its container-based architecture, the platform integrates effortlessly with existing MLOps workflows. It also supports custom runtime environments, allowing organizations to deploy models using either pre-built containers or custom setups tailored to specific frameworks and requirements.
Microsoft Azure Machine Learning offers a comprehensive platform for managing large language models (LLMs), seamlessly integrating MLOps tools with Microsoft's cloud infrastructure. This makes it an excellent choice for organizations already utilizing the Microsoft ecosystem.
Azure Machine Learning simplifies LLM management with its Model Registry, which tracks versions, metadata, and artifacts. For those who prefer a no-code approach, the Designer interface allows users to create visual workflows to manage multiple models effortlessly.
The platform’s Automated ML feature takes the hassle out of model selection and hyperparameter tuning, enabling teams to compare various architectures - from transformer-based models to custom fine-tuned versions - through parallel experiments.
For deployment, Azure's Managed Endpoints handle both real-time and batch inference across multiple LLMs. It supports blue-green deployments, letting teams test new models alongside production ones before fully transitioning. This minimizes downtime and reduces risks when managing several models at once.
Azure also enables pipeline orchestration, allowing teams to design workflows where multiple LLMs collaborate. For example, one model can handle text classification while another performs sentiment analysis, all within a unified pipeline.
These orchestration tools are complemented by robust cost management capabilities.
Azure Machine Learning integrates seamlessly with Azure Cost Management, providing detailed expense tracking for LLM deployments. To cut costs, the platform offers Spot Virtual Machines, which use Azure's surplus compute capacity for non-critical tasks like training.
The auto-scaling feature adjusts CPU and GPU resources automatically based on demand, ensuring efficient usage. For predictable workloads, Reserved Instances offer discounted rates compared to pay-as-you-go pricing. Additionally, Cost Allocation Tags let teams monitor expenses by project, department, or model type, helping with budget planning and resource management.
Security is a cornerstone of Azure Machine Learning. The platform ensures end-to-end encryption, safeguarding data and model artifacts both in transit and at rest. Integration with Azure Active Directory supports single sign-on and centralized identity management.
With Virtual Network (VNet) integration, training and inference operations remain within private networks. Teams can also set up Private Endpoints to eliminate internet exposure, meeting stringent security requirements for sensitive applications.
Azure Machine Learning adheres to key industry standards like SOC 1, SOC 2, ISO 27001, HIPAA, and FedRAMP. Tools like Azure Compliance Manager assist with continuous assessment and reporting, while Azure Policy automates governance by enforcing security settings, data retention policies, and access controls for new deployments.
Azure Machine Learning is built to scale, making it suitable for everything from single-model experiments to enterprise-wide LLM deployments. Its compute clusters can automatically allocate distributed training resources, supporting both data and model parallelism across multiple GPUs.
By integrating with Azure Kubernetes Service (AKS), the platform enables container orchestration for complex, multi-model setups. This allows teams to deploy LLMs as microservices, each with independent scaling and update capabilities.
With availability in over 60 Azure regions, the platform ensures low-latency access for global deployments, while maintaining centralized management and monitoring. Additionally, integration with Azure Cognitive Services allows teams to combine custom LLMs with pre-built AI services, creating hybrid solutions that save time and offer flexibility for specialized needs.

Hugging Face Transformers stands out as an open-source tool designed to simplify the management of large language models (LLMs). By leveraging frameworks like PyTorch and TensorFlow, it provides developers with an intuitive, scalable platform for loading and managing thousands of models with just a single line of code. Its focus on accessibility, efficiency, and scalability makes it a go-to solution for teams juggling multiple LLMs.
At its core, Transformers is built to streamline model access, enabling efficient orchestration and resource management.
The Transformers library simplifies model discovery and loading with concise commands. Using the from_pretrained() function, developers can instantly load models along with their tokenizers, weights, and configurations - no extra setup required.
The Pipeline API further enhances usability by enabling seamless task switching and automatic Git-based versioning. For example, you can easily compare sentiment analysis outputs from models like BERT, RoBERTa, and DistilBERT by adjusting the model parameter in your pipeline. Each model repository tracks a complete history of changes, allowing users to roll back to earlier versions or analyze performance differences across iterations.
When it comes to batch processing and inference, the library includes dynamic batching and attention optimization, ensuring efficient handling of variable-length inputs. Features like gradient checkpointing help manage memory consumption, especially when working with large-scale models.
Hugging Face Transformers provides several tools to optimize compute and memory usage, making it a cost-effective choice for organizations. Model quantization can shrink model sizes by up to 75% while maintaining performance, which is particularly useful for handling multiple models simultaneously.
The library also offers distilled models, such as DistilBERT, which are pre-optimized for faster performance and reduced memory usage. These models run approximately 60% faster and consume 40% less memory compared to their full-sized counterparts, translating to significant savings for large-scale deployments.
Dynamic model loading ensures resources are used efficiently by loading models only when needed, rather than keeping them all in memory at once. Additionally, its model caching strategies strike a balance between memory usage and loading speed, giving teams the flexibility to allocate resources based on demand.
For even greater efficiency, integration with ONNX Runtime enhances performance in CPU-based inference scenarios, a cost-effective option for teams looking to minimize GPU expenses. This adaptability allows organizations to choose deployment strategies that align with their specific needs.
Hugging Face Transformers is designed to scale effortlessly, whether you're running a single experiment or managing a full-scale production environment. It supports multi-GPU setups and model parallelism, enabling the use of models that exceed the memory of a single device.
The library integrates with popular machine learning frameworks like Ray and Dask, making it easy to scale horizontally across multiple machines. This compatibility ensures smooth integration into existing MLOps pipelines, allowing teams to deploy LLMs at scale.
Through the Hugging Face Hub, organizations can centralize their model management with features like private repositories, access controls, and governance policies. This centralization supports team collaboration and ensures effective oversight across a portfolio of LLMs.
For production deployments, Transformers models can be containerized and deployed using tools like Docker, Kubernetes, or cloud-native services. The library's standardized interfaces ensure consistent behavior across different environments, simplifying the deployment of complex multi-model systems.
The extensive community ecosystem is another advantage, offering thousands of pre-trained models, datasets, and user-contributed optimizations. This ecosystem reduces the need to build models from scratch, providing ready-to-use solutions for a wide range of applications.
Comet ML stands out as a robust machine learning platform designed to simplify the tracking, monitoring, and management of multiple large language models (LLMs) throughout their lifecycle. By centralizing experiment tracking, model registry, and production monitoring, it complements the integrated strategies discussed earlier. This makes it an ideal tool for organizations managing numerous LLMs simultaneously.
Comet ML's experiment tracking system captures and organizes data from LLM training runs automatically. It logs hyperparameters, metrics, code versions, and system resource usage in real time, creating a detailed record for comparing performance across various models and configurations.
The platform’s model registry serves as a centralized hub for storing, versioning, and managing multiple LLMs. It includes detailed metadata such as performance benchmarks, training datasets, and deployment requirements, ensuring teams have all the information they need in one place.
Customizable dashboards enable automated comparisons, allowing teams to quickly identify top-performing models by evaluating metrics like accuracy, inference times, and resource usage. The collaborative workspace further enhances productivity by enabling team members to share experiments, annotate results, and discuss findings efficiently, streamlining communication and decision-making throughout the model lifecycle.
Comet ML provides in-depth resource tracking, monitoring GPU usage, training times, and compute costs for LLM experiments. This data helps identify opportunities to reduce expenses by fine-tuning hyperparameters and optimizing training configurations. A dedicated cost dashboard consolidates spending data across projects and team members, offering clear insights into infrastructure costs and enabling smarter resource allocation decisions.
The platform prioritizes security with features like single sign-on (SSO), role-based access controls, and audit logging to safeguard sensitive model data and training processes. For organizations requiring additional control, private cloud deployment options allow Comet ML to operate within their own infrastructure. These security measures ensure that the platform can scale securely, even in complex, multi-LLM environments.
Comet ML is built to handle the demands of managing multiple LLMs across distributed training setups. It efficiently tracks experiments across multiple GPUs and machines, offering a unified view of training progress and resource usage. API integration ensures seamless incorporation into existing MLOps pipelines, while multi-workspace organization allows large organizations to segment projects by team, department, or use case - maintaining centralized oversight without sacrificing flexibility.
DeepLake combines the adaptability of data lakes with the precision of vector databases, creating a foundation for efficient multi-LLM workflows.
DeepLake is designed for large-scale LLM operations, constantly evolving to meet industry needs. It merges the adaptability of data lakes with the accuracy of vector databases, enabling seamless data flow across multiple LLMs through its "Symbiotic Model Engagement" feature. Additionally, tools like "Agile Evolution" and "Chronological Adaptivity" allow for quick recalibration and real-time synchronization, ensuring workflows remain efficient and up-to-date.
The platform's advanced memory capabilities enhance the retrieval of similar data points and refine vector embeddings, boosting LLM performance. DeepLake also integrates with prominent AI frameworks, supporting applications like Retrieval Augmented Generation and other LLM-driven solutions.
By focusing on dynamic data management, DeepLake strengthens the multi-LLM ecosystem, ensuring continuous support for advanced AI workflows while maintaining cost-effective operations.
DeepLake prioritizes intelligent resource allocation to deliver both performance and cost savings.
Its managed tensor database reduces storage expenses while enabling high-speed, real-time data streaming. Additionally, the platform’s efficient vector storage cuts down computational demands, ensuring smooth operations without unnecessary overhead.
DeepLake incorporates robust security measures under its "Data Fortification" initiative, offering features designed to safeguard data integrity and prevent corruption. It also provides detailed implementation guides to help maintain secure multi-LLM environments. However, its enterprise-level security features are somewhat limited compared to specialized vector database solutions. Organizations with strict compliance needs should evaluate whether its current security offerings meet their requirements. Despite this, DeepLake remains a key player in unified multi-LLM management, balancing security with operational efficiency.
DeepLake’s cloud-focused architecture supports scalable and high-performance multi-LLM workloads. With multi-cloud compatibility and a managed tensor database, it facilitates real-time data streaming and flexible resource allocation. This makes it suitable for a range of applications, from responsive chatbots to complex models processing vast document datasets.
The table below highlights the core features of popular platforms, making it easier to choose the right solution for managing multiple LLMs.
| Feature | Prompts.ai | Amazon SageMaker | Azure Machine Learning | Hugging Face Transformers | Comet ML | DeepLake |
|---|---|---|---|---|---|---|
| Supported LLMs | 35+ models (GPT-5, Claude, LLaMA, Gemini) | Custom and pre-trained models | Integration with OpenAI and custom models | Extensive open-source model library | Framework-agnostic integration | Supports various models via integrations |
| Cost Management | Up to 98% savings with real-time optimization | Usage-based billing | Azure credits and usage tracking | Free library; compute costs apply | Tiered usage-based pricing | Pricing based on storage and compute |
| Security & Compliance | Enterprise-grade governance with audit trails | SOC, HIPAA, PCI DSS compliance | Meets Azure security and RBAC standards | Community-driven security practices | Industry-standard security practices | Built with security-first principles |
| Scalability | Auto-scaling for teams and models | Fully managed, scalable cloud infrastructure | Serverless and scalable compute options | Flexible deployment configurations | Cloud-native scalability | Optimized for data-heavy workflows |
| Deployment Options | Cloud-based SaaS platform | AWS cloud services | Microsoft Azure cloud | Library-based, adaptable to cloud or on-premises | Cloud and on-premises options | Cloud-focused platform |
| Model Comparison | Side-by-side performance analysis | Supports A/B testing | Built-in model comparison tools | Requires manual benchmarking | Comprehensive experiment tracking | Limited direct model evaluation |
| Integration Capabilities | Unified interface for 35+ LLMs | Seamless AWS ecosystem integration | Works with Microsoft services | Easy Python library integration | MLOps tool compatibility | Works with major AI frameworks |
| User Interface | Unified dashboard | AWS console with notebooks | Azure ML Studio | Code-based interface | Web-based experiment dashboard | Intuitive cloud interface |
| Community Support | Includes a Prompt Engineer Certification program and active community | Extensive AWS documentation and forums | Access to Microsoft Learn resources | Large open-source community | Engaged user community | Detailed documentation and guides |
| Pricing Model | Pay-as-you-go TOKN credits | Usage-based pricing | Consumption-based pricing | Free library; compute costs apply | Subscription tiers | Storage and compute-based pricing |
Each platform stands out for its unique strengths. Prompts.ai excels in unified management and cost efficiency. Amazon SageMaker and Azure Machine Learning integrate seamlessly into enterprise ecosystems. Hugging Face Transformers is ideal for code-first experimentation, while Comet ML shines in experiment tracking. DeepLake is tailored for data-intensive workflows.
When deciding, consider your team's expertise, existing infrastructure, and specific needs for managing LLMs. Teams focused on cost efficiency and governance may lean toward platforms with FinOps tools, while those prioritizing experimentation might prefer detailed tracking and performance comparison features. Align these capabilities with your goals to find the best fit for your multi-LLM setup.
Handling multiple large language models effectively calls for integrated tools, a clear strategy, and strong governance. The platforms discussed here emphasize unified interfaces, strict cost management, and enterprise-level security.
When evaluating platforms, it's crucial to align your choice with your organization's unique infrastructure and goals. For teams prioritizing cost management and streamlined oversight, platforms offering real-time FinOps tools and consolidated billing stand out. On the other hand, teams focusing on experimentation and customization may lean toward open-source libraries and flexible deployment options tailored to their needs.
Efficiency in workflows is a cornerstone of success. Features like side-by-side model comparisons, systematic experiment tracking, and standardized prompt management can significantly cut down the time spent juggling tools and managing scattered systems. This kind of efficiency becomes increasingly valuable as teams scale their AI operations and tackle more intricate use cases.
Governance, compliance, and cost transparency remain non-negotiable. Platforms with comprehensive audit trails, role-based access, and clear pricing structures enable organizations to meet regulatory demands while keeping expenses under control. Tools like real-time usage tracking and budget notifications not only prevent overspending but also ensure AI investments deliver maximum value.
As the LLM landscape continues to evolve, selecting platforms that balance immediate needs with scalability is key to staying ahead. The right choice lays a solid foundation, supporting both current projects and the inevitable growth of AI adoption within your organization.
Prompts.ai helps you cut operational costs by as much as 98% while managing multiple large language models. By bringing all your operations under one roof, it simplifies workflows and eliminates unnecessary steps, boosting overall efficiency and performance.
Built with the challenges of complex AI systems in mind, Prompts.ai ensures you extract maximum value from your models without driving up expenses.
Prompts.ai places a strong emphasis on security and regulatory compliance, equipping users with powerful tools to protect and manage large language models (LLMs). Key features include compliance monitoring to meet regulatory requirements, governance tools for managing access and usage, and detailed analytics to evaluate and improve model performance effectively.
The platform also offers centralized storage pooling and administration tools to simplify workflows while maintaining tight control. This ensures that your LLM operations remain secure, efficient, and well-organized at all times.
Prompts.ai makes scaling effortless with tools tailored to efficiently handle multiple large language model (LLM) instances. The platform enables you to coordinate workflows, track performance, and simplify operations - even when managing dozens or hundreds of LLMs at once.
Key features like centralized management, automated workflows, and performance tuning ensure your AI systems remain dependable and adaptable, regardless of the complexity of your setup. It's a go-to solution for developers and AI professionals overseeing extensive, multi-model deployments.


















