Pay As You Go - AI Model Orchestration and Workflows Platform


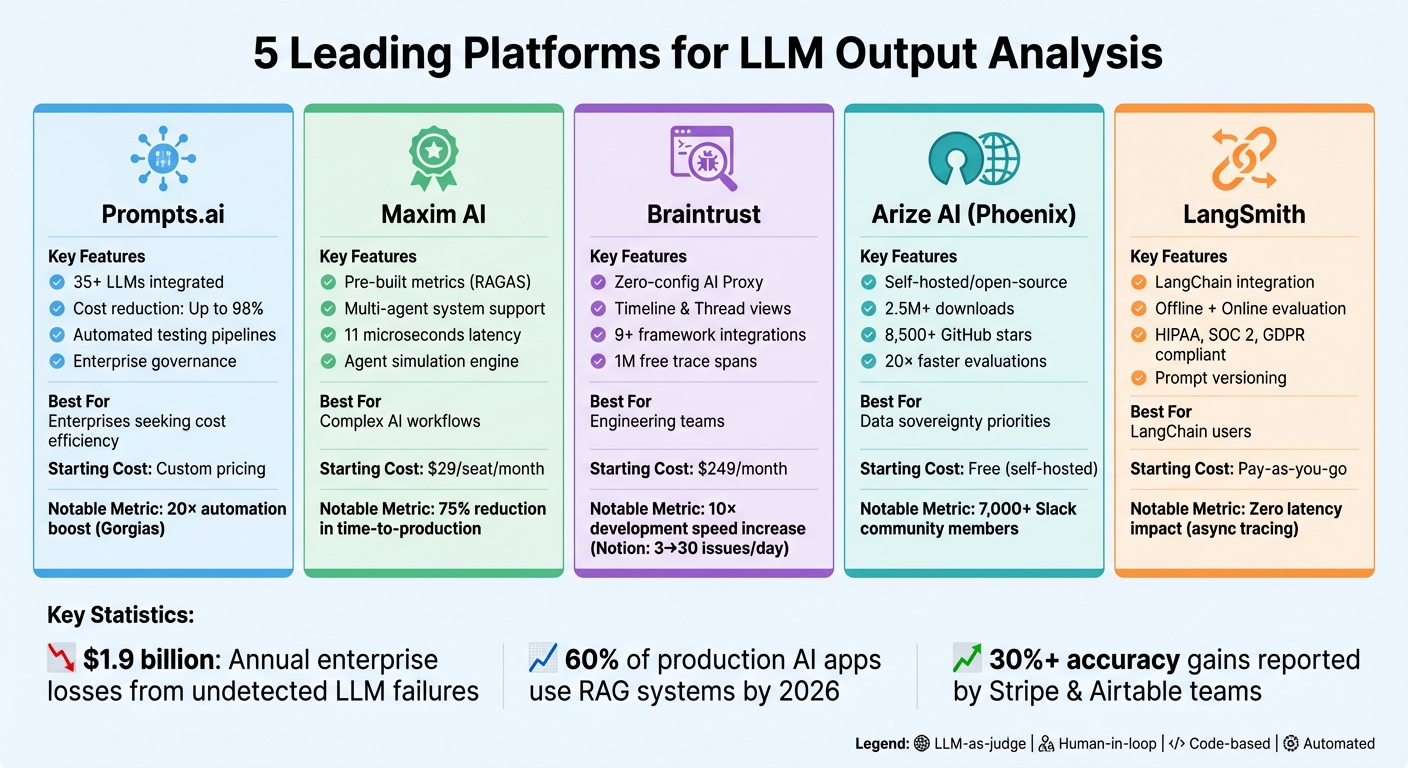
Large Language Models (LLMs) are powerful but unpredictable, often producing inconsistent or costly outputs. To tackle these challenges, organizations rely on specialized tools for evaluation, monitoring, and cost management. This article introduces five platforms that streamline LLM output analysis:
Each platform addresses unique aspects of LLM workflows, from improving accuracy to cutting costs and ensuring compliance.
| Platform | Key Features | Best For | Starting Cost |
|---|---|---|---|
| Prompts.ai | Centralized LLM access, cost-saving FinOps tools | Enterprises seeking cost efficiency | Custom pricing |
| Maxim AI | Pre-built metrics, multi-agent system support | Teams managing complex AI workflows | $29/seat/month |
| Braintrust | Debugging tools, multi-turn conversation testing | Engineering teams | $249/month |
| Arize AI | Open-source, detailed tracing, hallucination checks | Organizations prioritizing data control | Free (self-hosted) |
| LangSmith | LangChain integration, prompt versioning | LangChain users | Pay-as-you-go |
These platforms simplify LLM management, ensuring scalable, reliable, and cost-effective AI operations.
LLM Output Analysis Platforms Comparison: Features, Pricing, and Best Use Cases
Prompts.ai brings together 35+ top-tier LLMs - including GPT‑5, Claude, LLaMA, and Gemini - into one unified platform designed for enterprise-level prompt engineering and detailed output analysis. It simplifies evaluation with automated testing pipelines.
Prompts.ai features evaluation pipelines capable of running over 20 tests on prompt datasets. These include methods like LLM assertions (using AI to grade outputs), semantic similarity checks through cosine similarity, exact match evaluations, and regex-based pattern matching. Teams can also incorporate human-in-the-loop evaluations through a user-friendly dashboard, allowing domain experts to manually assess outputs as part of reinforcement learning from human feedback.
For instance, Gorgias, a customer support platform, used Prompts.ai to scale its AI-powered helpdesk to support millions of shoppers. This led to a 20× boost in automation. Their ML engineers and support teams run daily regression tests on backtest datasets to catch potential issues before deployment.
These rigorous testing capabilities ensure smooth integration into current workflows.
Prompts.ai’s evaluation pipelines seamlessly integrate with CI/CD workflows and enable backtesting against historical production data. The platform supports connections through external HTTP endpoints, custom Python/JavaScript scripts, and Model Context Protocol (MCP) actions.
Speak, a language learning app, leveraged these automation features to condense months of curriculum development into just one week. This efficiency allowed them to launch AI-driven features in 10 new markets at the same time.
Prompts.ai also helps teams optimize costs by offering side-by-side model comparison views. These comparisons allow users to weigh trade-offs between API costs, latency, and quality scores. Teams can summarize outputs or use smaller, faster models for intermediate tasks to reduce token usage. NoRedInk, which serves 60% of U.S. school districts, uses these cost-saving features to provide AI-generated feedback on over 1 million student grades, all while maintaining teacher-level quality.
Prompts.ai enhances collaboration by equipping all stakeholders with tools to refine LLM outputs. A no-code visual editor lets non-technical users edit and test prompts without relying on engineers. The centralized Prompt Registry ensures efficient version management.
ParentLab, for example, saved over 400 engineering hours in just six months by enabling non-technical domain experts to manage 700 prompt revisions.
"Prompts.ai has been a game-changer for us. It has allowed our content team to rapidly iterate on prompts, find the right tone, and address edge cases, all without burdening our engineers." - John Gilmore, VP of Operations at ParentLab
The platform also gathers user ratings and translates them into performance scores, creating a continuous feedback loop to improve output quality across all integrated models.
Maxim AI provides in-depth testing and monitoring tools, blending machine-driven evaluations with human feedback to support teams managing intricate AI workflows. Its features are designed to ensure thorough assessments, which are crucial for maintaining strong LLM performance.
Maxim AI uses a robust evaluation framework that includes deterministic testing, statistical methods, and automated judgment tools. The Evaluator Store offers pre-built metrics like RAGAS, tailored for retrieval-augmented generation systems - key components in about 60% of production AI applications by 2026. Additionally, node-level metrics help identify failures in retrieval and generation processes. The platform’s Agent Simulation engine enables multi-turn conversation testing and user persona creation for pre-deployment assessments. Companies such as Clinc and Mindtickle have reported a 75% reduction in time-to-production by adopting these quality standards.
Maxim AI’s evaluation tools integrate effortlessly with today’s development environments. It supports SDKs in Python, TypeScript, Java, and Go, while offering compatibility with platforms like LangChain, LangGraph, Crew AI, OpenAI, Anthropic, Mistral, and AWS Bedrock. The platform also adheres to OpenTelemetry standards for distributed tracing and connects with tools like Slack and PagerDuty for real-time alerts. Enterprise users benefit from deployment options that include Cloud and In-VPC hosting, all meeting SOC2, HIPAA, and GDPR compliance requirements.
The Bifrost LLM Gateway uses semantic caching to reduce expenses, while monitoring token usage and API costs to identify and address expensive workflows. This ensures efficient operations as production scales.
Maxim AI’s no-code UI empowers product managers and designers to experiment with prompts and conduct evaluations independently. Kellie Maloney, Product Lead at Rise Science, shared:
"One thing we've really loved is just how Maxim helps us democratize the process of writing Prompts. So it empowers both our product, which is the role I am in, as well as our design teams to really own the process. So it's really accelerated both the speed at which we iterate and the quality of the output."
The platform also includes annotation queues for human-in-the-loop reviews, a centralized Prompt CMS with version control, and RBAC with SAML/SSO support. Teams leveraging these collaboration tools have achieved a fivefold increase in shipping velocity, streamlining iteration and speeding up production rollouts.
Braintrust combines offline experiments with online scoring to give teams a full view of LLM performance from development to deployment.
Braintrust provides multiple ways to evaluate output quality on a scale from 0 to 1. Teams can use automated scorers for tasks like factuality and similarity checks, rely on LLM-as-a-judge evaluations, or implement custom code logic tailored to their specific needs. The platform includes Timeline views with Gantt charts to identify bottlenecks, Thread views for debugging multi-turn conversations, and natural language-driven trace visualizations displayed as sandboxed React components. It also supports running multiple trials for each input, helping teams measure variance and maintain consistency.
Braintrust integrates smoothly with leading AI frameworks, offering native support for 9+ major frameworks, such as OpenTelemetry, Vercel AI SDK, OpenAI Agent SDK, Instructor, LangChain, LangGraph, Google ADK, Mastra, and Pydantic AI. It uses a "wrap" approach for integration - examples include wrapAISDK for Vercel AI SDK (covering versions v3 through v6 beta) and wrap_openai for Instructor. The platform adheres to OpenTelemetry GenAI semantic conventions, automatically mapping details like token usage and model identifiers to Braintrust fields. It works seamlessly with major LLM providers, including OpenAI, Anthropic, and Google Gemini. Developers can also use the Eval() function or the CLI with the --watch flag to re-run evaluations automatically whenever files are updated during development.
Braintrust goes beyond evaluation by fostering team collaboration with built-in tools. Its bidirectional synchronization ensures that product managers and engineers can work on prompts interchangeably between code and UI. The Playground offers a no-code space where teams can test prompts, compare models side by side, and share configurations for quick iterations. Dedicated annotation tools allow teams to provide human-in-the-loop feedback, adding labels or corrections directly to traces and model outputs. External annotators can be invited to assess quality across different model versions, while shared evaluation backlogs centralize datasets and scoring rubrics, eliminating the need for manual spreadsheet tracking.
Arize AI's Phoenix is an open-source platform designed to give teams comprehensive control over evaluating large language models (LLMs). Built with OpenTelemetry at its core, Phoenix has garnered attention with over 2.5 million downloads and 8,500+ GitHub stars. It offers detailed tracing to track every step of an LLM workflow, making it easier to identify where issues arise.
Phoenix employs the LLM-as-a-judge approach, using foundation models from OpenAI, Anthropic, and Gemini to assess other LLM applications for factors like relevance, toxicity, and overall performance. It comes with pre-built evaluators for common tasks such as Retrieval-Augmented Generation (RAG) and function calling. A standout feature is its explanation capability, where evaluation models provide clear reasoning behind their scores, helping developers understand the logic behind each assessment. Additional tools include deterministic code-based checks, human annotations directly within the interface, and dataset clustering that uses embeddings to visually group semantically similar questions and responses. This clustering helps isolate areas where models underperform.
"Phoenix targets [hallucination] by visualizing complex LLM decision-making and flagging when and where models fail, go wrong, give poor responses or incorrectly generalize." - Shubham Sharma, VentureBeat
These evaluation tools integrate seamlessly with the platform's broader development ecosystem.
Phoenix supports auto-instrumentation for popular frameworks like LlamaIndex, LangChain, DSPy, Mastra, and Vercel AI SDK. It works with Python, TypeScript, and Java, and its OpenTelemetry-native design ensures compatibility with existing observability tools without locking users into specific vendors. Teams can also incorporate evaluations from third-party libraries such as Ragas, Deepeval, or Cleanlab, offering flexibility across their workflows.
Phoenix is built for efficiency, delivering up to 20x faster evaluation runs through concurrency and batching. Its Prompt Playground provides a testing environment where teams can refine prompts and compare model variants side-by-side before deployment, reducing the risk of expensive production mistakes.
As a fully open-source and self-hostable platform, Phoenix ensures teams maintain complete control over their data. Features like human annotation queues allow ground truth labels to be added directly to traces, fostering better collaboration. The Prompt Hub manages prompt versioning, storage, and deployment across environments, while the Span Chat tool enables teams to evaluate and discuss specific workflow segments to uncover performance issues. With a Slack community of over 7,000 members, users have access to a network for troubleshooting and sharing insights.
"Phoenix integrated into our team's existing data science workflows and enabled the exploration of unstructured text data to identify root causes of unexpected user inputs, problematic LLM responses, and gaps in our knowledge base." - Yuki Waka, Application Developer, Klick
LangSmith is a versatile platform designed to work seamlessly with or without LangChain, making it adaptable to any LLM stack. It connects effortlessly with tools like OpenAI, Anthropic, CrewAI, Vercel AI SDK, and Pydantic AI, providing flexibility for teams already using specific frameworks. The platform meets compliance standards such as HIPAA, SOC 2 Type 2, and GDPR, and uses an asynchronous process to send traces, ensuring no added latency for end users.
LangSmith offers two evaluation modes to suit different needs: Offline Evaluation for testing curated datasets during development and Online Evaluation for monitoring live production traffic. It supports four types of evaluators:
The platform includes advanced analysis tools like Diff View, which highlights differences between model outputs and reference texts, and side-by-side comparisons for performance benchmarking. It also provides metadata grouping, enabling analysis of metrics like accuracy or cost by categories such as subject area or user type. LangSmith integrates with the open-source openevals package, offering pre-built evaluators for assessing correctness and brevity.
These features make it easy to integrate LangSmith into existing workflows and development tools.
LangSmith simplifies tracing with the @traceable decorator or client wrappers that automatically capture inputs and outputs. It supports integration with Python and TypeScript/JavaScript SDKs, a REST API, and testing frameworks like pytest, Vitest, and Jest, making it easy to embed evaluations into CI/CD pipelines. Additionally, OpenTelemetry integration allows teams to send traces from existing observability pipelines directly to LangSmith.
LangSmith enhances team collaboration with intuitive feedback and annotation tools. Annotation Queues enable automatic routing of specific runs to subject-matter experts for manual review and scoring based on custom criteria. The Prompt Hub serves as a centralized space for teams to iterate on, version, and share prompts, complete with change tracking and rollback features to maintain consistency throughout development. Inline annotation capabilities let team members flag issues or provide targeted feedback on response quality, improving both evaluation accuracy and workflow efficiency.
The platform also offers detailed user management and workload isolation, ensuring smooth collaboration across teams. Users can sign up for free at smith.langchain.com - no credit card required. For production use, LangSmith operates on a pay-as-you-go basis, with enterprise plans available for self-hosting on Kubernetes clusters across AWS, GCP, or Azure.
When evaluating platforms for LLM assessment, it's essential to consider technical compatibility, cost, and evaluation methods. Here's a closer look at the options:
Prompts.ai brings together 35+ leading models under one secure interface, offering FinOps controls that can reduce AI software costs by up to 98%. Braintrust simplifies setup with a zero-configuration AI Proxy, capturing logs via a single base URL. It includes 1 million trace spans free, with paid plans starting at $249/month. Maxim AI integrates seamlessly with existing observability stacks, focusing on quality scoring over full tracing. It offers a free plan for up to 10,000 logs per month and paid plans starting at $29 per seat/month. Arize Phoenix supports self-hosting for data privacy, integrating with tools like RAGAS and Giskard for deeper metric analysis. LangSmith is tailored for LangChain users, providing advanced observability, though enterprise support pricing varies. Notably, Notion improved its development velocity tenfold with Braintrust, increasing from resolving 3 issues daily to 30.
Each platform's unique approach simplifies decision-making based on your specific evaluation needs. Here's how they compare in terms of evaluation methods, integration, and deployment:
Integration complexity also plays a key role. Braintrust's proxy-based setup is straightforward - just update your API base URL. Maxim AI integrates with existing observability tools, while LangSmith's tight LangChain integration caters to specialized observability needs. Arize Phoenix stands out for organizations prioritizing data sovereignty, offering a self-hosted, open-source solution. Meanwhile, Prompts.ai provides enterprise-grade governance controls and complete audit trails for secure operation.
"Braintrust eliminates context switching by combining monitoring, evaluation, and experimentation. One platform means less time integrating tools." - Braintrust Team
For rapid insights, proxy-based deployments and deep integrations streamline the process. LangChain users will find LangSmith a natural fit, while organizations managing sensitive data may lean toward open-source solutions like Arize Phoenix or Prompts.ai for robust governance and auditing capabilities.
Based on the evaluations provided, each platform delivers distinct advantages for refining LLM output analysis. Prompts.ai offers enterprises centralized access to leading models, paired with FinOps controls that can reduce AI costs by as much as 98%, while ensuring robust governance and audit capabilities. Braintrust is tailored for fast-paced engineering teams, with companies like Notion reporting a 10x increase in development speed - boosting issue resolution from 3 to 30 per day. Similarly, teams at Stripe and Airtable observed over 30% accuracy gains within weeks of adopting the platform.
For those deeply integrated into the LangChain ecosystem, LangSmith provides effortless integration and fast prototyping options. Maxim AI caters to teams focusing on managing intricate multi-agent systems, offering precision scoring tools and a low-latency gateway that introduces just 11 microseconds of overhead at a volume of 5,000 requests per second. Meanwhile, Arize Phoenix is ideal for organizations prioritizing data sovereignty, delivering a self-hosted, open-source solution that fits seamlessly into existing observability systems.
Each platform addresses critical challenges in LLM performance and cost management. With enterprises facing potential losses of $1.9 billion annually due to undetected LLM failures in production, the need to move beyond subjective evaluations to measurable, data-driven metrics has become essential for ensuring reliability and efficiency.
These tools elevate LLM development into a structured engineering discipline. Whether your focus is on handling trillions of events monthly, streamlining collaboration across teams, or maintaining control over self-hosted infrastructure, choosing the right platform ensures your LLM workflows achieve the reliability, quality, and cost-effectiveness required to meet your goals.
These platforms are designed to help organizations cut down on AI expenses by offering tools to monitor and fine-tune the use of large language models (LLMs). For example, solutions like Prompts.ai allow users to track token usage in real time, making it easier to spot and reduce unnecessary token consumption. This helps avoid overspending on excessive API calls, leading to better cost management.
Beyond cost control, these platforms also provide valuable insights into performance and output quality. They can help detect and prevent issues like hallucinations or errors, which could otherwise lead to expensive rework. By analyzing usage trends and pinpointing inefficiencies, organizations can streamline workflows, lower operational costs, and ensure consistent, high-quality results. All of this supports smarter, data-driven decisions for managing AI budgets effectively.
LLM platforms provide various ways to connect seamlessly with tools and workflows, catering to different needs. Many platforms support native integration through SDKs like Python and JavaScript, alongside frameworks such as LangChain and LangServe. This makes embedding LLMs into custom applications straightforward and efficient. For monitoring, platforms often support open standards like OpenTelemetry, ensuring compatibility with existing infrastructure.
Some platforms also integrate with CI/CD tools such as GitHub Actions and Jenkins, simplifying testing and deployment processes. For organizations that prioritize control over their environment, self-hosting options are available, allowing customization while maintaining data security. These integration features enable users to boost efficiency, monitor performance effectively, and implement LLMs securely within their operations.
For those who place a premium on data privacy and control, OnPrem.LLM delivers an excellent solution. Designed specifically for privacy-sensitive tasks, this platform allows large language models (LLMs) to handle confidential or restricted data securely in offline settings. By enabling fully local execution, it significantly reduces the chances of data exposure, while also offering optional cloud integration for hybrid setups when necessary.
With its intuitive, no-code interface, OnPrem.LLM ensures accessibility for users without technical expertise, all while maintaining complete oversight of data management. This makes it an ideal choice for organizations in regulated or sensitive industries where safeguarding information is a top priority.



















