Pay As You Goإصدار تجريبي مجاني لمدة 7 أيام؛ لا يلزم وجود بطاقة ائتمان


تعد نماذج اللغات الكبيرة (LLMs) قوية ولكن لا يمكن التنبؤ بها، وغالبًا ما تنتج مخرجات غير متسقة أو مكلفة. ولمواجهة هذه التحديات، تعتمد المؤسسات على أدوات متخصصة للتقييم والمراقبة وإدارة التكاليف. تقدم هذه المقالة خمس منصات التي تبسط تحليل مخرجات LLM:
تتناول كل منصة الجوانب الفريدة لسير عمل LLM، من تحسين الدقة إلى خفض التكاليف وضمان الامتثال.
تعمل هذه المنصات على تبسيط إدارة LLM، مما يضمن عمليات الذكاء الاصطناعي القابلة للتطوير والموثوقة والفعالة من حيث التكلفة.
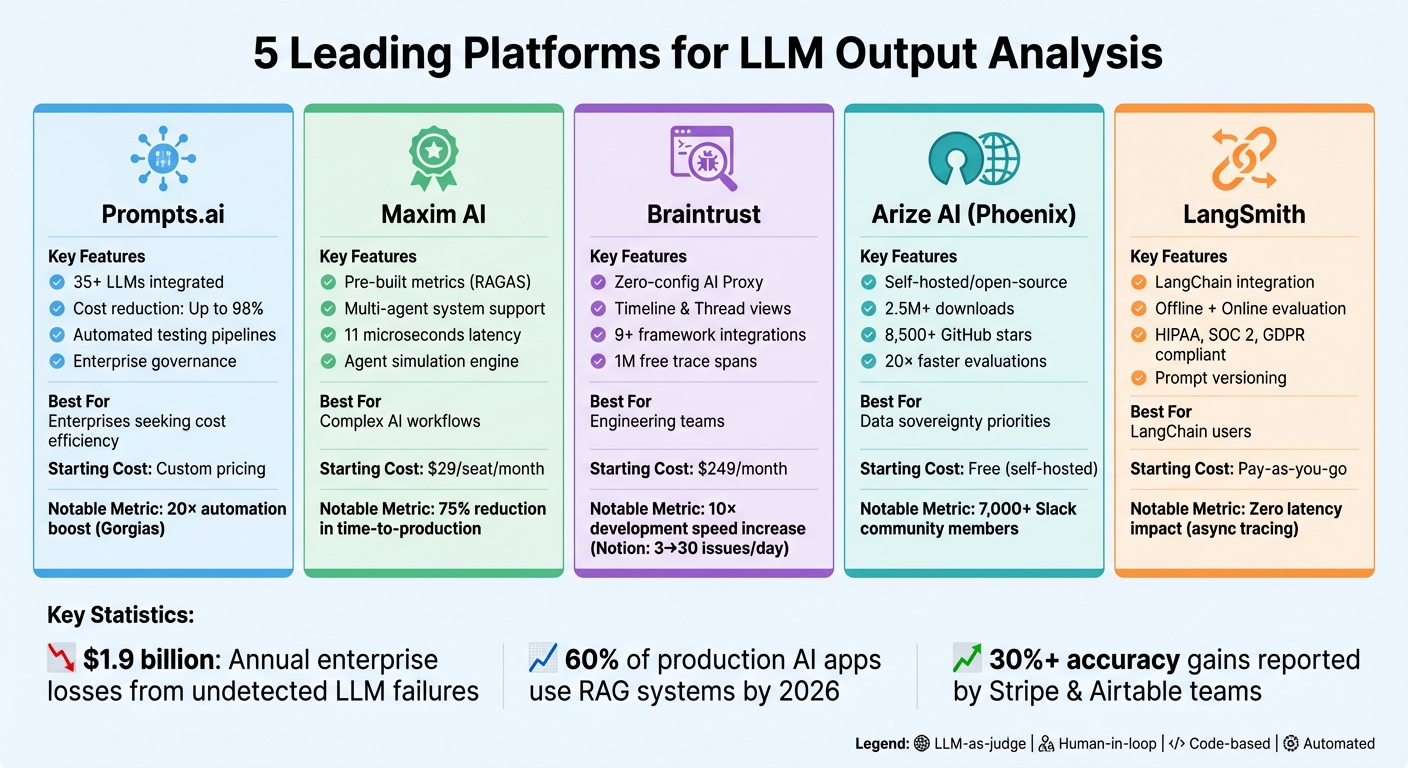
مقارنة منصات تحليل مخرجات LLM: الميزات والتسعير وأفضل حالات الاستخدام
يجمع Prompts.ai أكثر من 35 شركة LLMs من الدرجة الأولى - بما في ذلك GPT‑5 و Claude و LLama و Gemini - في منصة واحدة موحدة مصممة للهندسة السريعة على مستوى المؤسسة وتحليل المخرجات التفصيلي. إنه يبسط التقييم باستخدام خطوط أنابيب الاختبار الآلية.
يتميز Prompts.ai بخطوط تقييم قادرة على تشغيل أكثر من 20 اختبارًا على مجموعات البيانات السريعة. وتشمل هذه الأساليب مثل تأكيدات LLM (باستخدام الذكاء الاصطناعي لتقدير المخرجات)، وفحوصات التشابه الدلالي من خلال تشابه جيب التمام، وتقييمات المطابقة التامة، ومطابقة الأنماط القائمة على regex. يمكن للفرق أيضًا دمج التقييمات البشرية في الحلقة من خلال لوحة معلومات سهلة الاستخدام، مما يسمح لخبراء المجال بتقييم المخرجات يدويًا كجزء من التعلم المعزز من الملاحظات البشرية.
على سبيل المثال، استخدمت Gorgias، وهي منصة لدعم العملاء، Prompts.ai لتوسيع نطاق مكتب المساعدة المدعوم بالذكاء الاصطناعي لدعم ملايين المتسوقين. هذا أدى إلى زيادة 20 مرة في الأتمتة. يقوم مهندسو ML وفرق الدعم الخاصة بهم بإجراء اختبارات الانحدار اليومية على مجموعات بيانات backtest لاكتشاف المشكلات المحتملة قبل النشر.
تضمن إمكانات الاختبار الصارمة هذه الاندماج السلس في عمليات سير العمل الحالية.
تتكامل خطوط أنابيب التقييم الخاصة بـ Prompts.ai بسلاسة مع تدفقات عمل CI/CD وتمكن الاختبار العكسي مقابل بيانات الإنتاج التاريخية. تدعم المنصة الاتصالات من خلال نقاط نهاية HTTP الخارجية ونصوص Python/JavaScript المخصصة وإجراءات بروتوكول سياق النموذج (MCP).
استفاد تطبيق Speak، وهو تطبيق لتعلم اللغة، من ميزات التشغيل الآلي هذه لتكثيف أشهر من تطوير المناهج الدراسية في أسبوع واحد فقط. سمحت لهم هذه الكفاءة بإطلاق ميزات تعتمد على الذكاء الاصطناعي في 10 أسواق جديدة في نفس الوقت.
يساعد Prompts.ai أيضًا الفرق على تحسين التكاليف من خلال تقديم طرق عرض مقارنة النماذج جنبًا إلى جنب. تسمح هذه المقارنات للمستخدمين بتقييم المقايضات بين تكاليف API ووقت الاستجابة ودرجات الجودة. يمكن للفرق تلخيص المخرجات أو استخدام نماذج أصغر وأسرع للمهام المتوسطة لتقليل استخدام الرمز المميز. تستخدم NoreDink، التي تخدم 60٪ من المناطق التعليمية في الولايات المتحدة، ميزات توفير التكاليف هذه لتقديم ملاحظات تم إنشاؤها بواسطة الذكاء الاصطناعي حول أكثر من مليون درجة للطلاب، كل ذلك مع الحفاظ على الجودة على مستوى المعلم.
يعزز Prompts.ai التعاون من خلال تزويد جميع أصحاب المصلحة بأدوات لتحسين مخرجات LLM. يتيح المحرر المرئي بدون تعليمات برمجية للمستخدمين غير التقنيين تحرير المطالبات واختبارها دون الاعتماد على المهندسين. يضمن السجل الفوري المركزي الإدارة الفعالة للإصدار.
على سبيل المثال، وفر ParentLab أكثر من 400 ساعة هندسية في ستة أشهر فقط من خلال تمكين خبراء المجال غير التقنيين من إدارة 700 مراجعة سريعة.
«لقد كان Prompts.ai بمثابة تغيير لقواعد اللعبة بالنسبة لنا. لقد سمح لفريق المحتوى لدينا بتكرار المطالبات بسرعة والعثور على النغمة الصحيحة ومعالجة الحالات المتطورة، كل ذلك دون إثقال كاهل مهندسينا. «- جون جيلمور، نائب رئيس العمليات في ParentLab
تقوم المنصة أيضًا بجمع تقييمات المستخدمين وترجمتها إلى درجات أداء، مما يخلق حلقة ملاحظات مستمرة لتحسين جودة المخرجات عبر جميع النماذج المتكاملة.
يوفر Maxim AI أدوات اختبار ومراقبة متعمقة، ويمزج التقييمات التي تعتمد على الآلة مع التعليقات البشرية لدعم الفرق التي تدير تدفقات عمل الذكاء الاصطناعي المعقدة. تم تصميم ميزاته لضمان التقييمات الشاملة، والتي تعتبر ضرورية للحفاظ على أداء LLM القوي.
يستخدم Maxim AI إطار تقييم قويًا يتضمن الاختبارات الحتمية والأساليب الإحصائية وأدوات الحكم الآلي. ال متجر المقيم يقدم مقاييس مسبقة الصنع مثل RAGAS، المصممة خصيصًا لأنظمة التوليد المعزز بالاسترجاع - المكونات الرئيسية في حوالي 60٪ من تطبيقات الذكاء الاصطناعي للإنتاج بحلول عام 2026. بالإضافة إلى ذلك، مقاييس مستوى العقدة تساعد في تحديد حالات الفشل في عمليات الاسترجاع والتوليد. المنصة محاكاة الوكيل يتيح المحرك اختبار المحادثة متعددة الأدوار وإنشاء شخصية المستخدم لتقييمات ما قبل النشر. أبلغت شركات مثل Clinc و Mindtickle عن انخفاض بنسبة 75٪ في وقت الإنتاج من خلال اعتماد معايير الجودة هذه.
تتكامل أدوات تقييم Maxim AI بسهولة مع بيئات التطوير الحالية. وهو يدعم حزم SDK في بايثون وتايب سكريبت وجافا وجو، مع توفير التوافق مع منصات مثل LangChain و LangGraph و Crew AI و OpenAI و Anthropic و Mistral و AWS Bedrock. تلتزم المنصة أيضًا بـ افتح القياس عن بُعد معايير التتبع الموزع وتتصل بأدوات مثل Slack و PagerDuty للتنبيهات في الوقت الفعلي. يستفيد مستخدمو المؤسسات من خيارات النشر التي تشمل الاستضافة السحابية والاستضافة داخل VPC، وكلها تلبي متطلبات الامتثال لـ SOC2 و HIPAA و GDPR.
ال بوابة بيفروست LLM يستخدم التخزين المؤقت الدلالي لتقليل النفقات، مع مراقبة استخدام الرمز المميز وتكاليف واجهة برمجة التطبيقات لتحديد ومعالجة عمليات سير العمل المكلفة. هذا يضمن عمليات فعالة مثل مقاييس الإنتاج.
شركة ماكسيم للذكاء الاصطناعي واجهة مستخدم بدون كود يمكّن مديري المنتجات والمصممين من تجربة المطالبات وإجراء التقييمات بشكل مستقل. قالت كيلي مالوني، رئيسة المنتجات في شركة Rise Science:
«الشيء الوحيد الذي أحببناه حقًا هو كيف يساعدنا Maxim في إضفاء الطابع الديمقراطي على عملية كتابة Prompts. لذا فهي تمكّن كل من منتجنا، وهو الدور الذي أقوم به، وكذلك فرق التصميم لدينا من امتلاك العملية حقًا. لذا فقد أدى ذلك حقًا إلى تسريع كل من السرعة التي نكرر بها وجودة المخرجات.»
تتضمن المنصة أيضًا قوائم انتظار التعليقات التوضيحية لمراجعات الإنسان في الحلقة، ونظام إدارة المحتوى الفوري المركزي مع التحكم في الإصدار، و RBAC مع دعم SAML/SSO. حققت الفرق التي تستفيد من أدوات التعاون هذه زيادة بمقدار خمسة أضعاف في سرعة الشحن وتبسيط التكرار وتسريع عمليات إطلاق الإنتاج.
يجمع Braintrust بين التجارب غير المتصلة بالإنترنت والتسجيل عبر الإنترنت لمنح الفرق رؤية كاملة لأداء LLM من التطوير إلى النشر.
يوفر Braintrust طرقًا متعددة لتقييم جودة المخرجات على مقياس من 0 إلى 1. يمكن للفرق استخدام الهدافين الآليين لمهام مثل عمليات التحقق من الحقائق والتشابه، أو الاعتماد على تقييمات LLM-as-a-Judge، أو تنفيذ منطق التعليمات البرمجية المخصص المصمم وفقًا لاحتياجاتهم الخاصة. تتضمن المنصة مشاهدات المخطط الزمني مع مخططات جانت لتحديد الاختناقات، مشاهدات الموضوع لتصحيح أخطاء المحادثات متعددة الأدوار، ومرئيات التتبع القائمة على اللغة الطبيعية المعروضة كمكونات React في وضع الحماية. كما أنه يدعم إجراء تجارب متعددة لكل إدخال، مما يساعد الفرق على قياس التباين والحفاظ على الاتساق.
يتكامل Braintrust بسلاسة مع أطر الذكاء الاصطناعي الرائدة، ويقدم دعمًا محليًا لـ أكثر من 9 أطر رئيسية، مثل أوبن تيليميتري، فيرسل AI SDK، أوبن إيه آي وكيل SDK، إنستراكتور، لانغتشين، لانغغراف، غوغل أدك، ماسترا، وبيدانتيك إيه آي. يستخدم نهج «الالتفاف» للتكامل - تشمل الأمثلة WrapaisDK لـ Vercel AI SDK (تغطي الإصدارات من v3 إلى v6 beta) و wrap_openai للمدرب. تلتزم المنصة بـ اتفاقيات OpenTelemetry الدلالية لـ GenAI، تعيين التفاصيل تلقائيًا مثل استخدام الرمز المميز ومعرفات النماذج إلى حقول Braintrust. وهو يعمل بسلاسة مع مزودي LLM الرئيسيين، بما في ذلك OpenAI و Anthropic و Google Gemini. يمكن للمطورين أيضًا استخدام إيفال (1) وظيفة CLI مع --ساعة وضع علامة لإعادة تشغيل التقييمات تلقائيًا عندما يتم تحديث الملفات أثناء التطوير.
يتجاوز Braintrust التقييم من خلال تعزيز تعاون الفريق باستخدام الأدوات المضمنة. إنها المزامنة ثنائية الاتجاه يضمن أن مديري المنتجات والمهندسين يمكنهم العمل على المطالبات بالتبادل بين الكود وواجهة المستخدم. ال ملعب يوفر مساحة خالية من التعليمات البرمجية حيث يمكن للفرق اختبار المطالبات ومقارنة النماذج جنبًا إلى جنب ومشاركة التكوينات للتكرارات السريعة. تسمح أدوات التعليقات التوضيحية المخصصة للفرق بتقديم ملاحظات بشرية في الحلقة، وإضافة تسميات أو تصحيحات مباشرة إلى الآثار ومخرجات النموذج. يمكن دعوة المعلقين الخارجيين لتقييم الجودة عبر إصدارات النماذج المختلفة، في حين تعمل عمليات التقييم المشتركة على تركيز مجموعات البيانات ونماذج تقييم الدرجات، مما يلغي الحاجة إلى التتبع اليدوي لجداول البيانات.
Phoenix من Arize AI عبارة عن منصة مفتوحة المصدر مصممة لمنح الفرق تحكمًا شاملاً في تقييم نماذج اللغات الكبيرة (LLMs). تم تصميم Phoenix باستخدام OpenTelemetry في جوهره، وقد اجتذب الاهتمام بأكثر من 2.5 مليون عملية تنزيل وأكثر من 8500 نجم على GitHub. يوفر تتبعًا تفصيليًا لتتبع كل خطوة من خطوات سير عمل LLM، مما يسهل تحديد مكان ظهور المشكلات.
توظف فينيكس ماجستير في القانون كقاض النهج، باستخدام النماذج الأساسية من OpenAI و Anthropic و Gemini لتقييم تطبيقات LLM الأخرى لعوامل مثل الملاءمة والسمية والأداء العام. يأتي مع مقيّمين تم تصميمهم مسبقًا للمهام الشائعة مثل الجيل المعزز للاسترجاع (RAG) واستدعاء الوظائف. الميزة البارزة هي القدرة على الشرح، حيث توفر نماذج التقييم أسبابًا واضحة وراء درجاتها، مما يساعد المطورين على فهم المنطق الكامن وراء كل تقييم. تتضمن الأدوات الإضافية عمليات التحقق المحددة المستندة إلى التعليمات البرمجية والتعليقات التوضيحية البشرية مباشرة داخل الواجهة و تجميع مجموعة البيانات يستخدم التضمين لتجميع الأسئلة والإجابات المتشابهة لغويًا بشكل مرئي. تساعد هذه المجموعة على عزل المناطق التي يكون فيها أداء النماذج ضعيفًا.
«تستهدف فينيكس [الهلوسة] من خلال تصور عملية صنع القرار المعقدة في LLM والإبلاغ عن متى وأين تفشل النماذج أو تسوء أو تعطي ردودًا ضعيفة أو تعمم بشكل غير صحيح.» - شوبهام شارما، VentureBeat
تتكامل أدوات التقييم هذه بسلاسة مع النظام البيئي للتطوير الأوسع للمنصة.
تدعم فينيكس الأجهزة التلقائية لأطر العمل الشائعة مثل LLAmaIndex و LangChain و dSpy و Mastra و Vercel AI SDK. إنه يعمل مع Python و TypeScript و Java، ويضمن تصميم OpenTelemetry-الأصلي التوافق مع أدوات الملاحظة الحالية دون تقييد المستخدمين في بائعين محددين. يمكن للفرق أيضًا دمج التقييمات من مكتبات الجهات الخارجية مثل Ragas أو Deepeval أو Cleanlab، مما يوفر المرونة عبر سير العمل.
تم تصميم Phoenix لتحقيق الكفاءة والتسليم عمليات تقييم أسرع تصل إلى 20 مرة من خلال التزامن والتجميع. يوفر Prompt Playground بيئة اختبار حيث يمكن للفرق تحسين المطالبات ومقارنة متغيرات النموذج جنبًا إلى جنب قبل النشر، مما يقلل من مخاطر أخطاء الإنتاج المكلفة.
وباعتبارها منصة مفتوحة المصدر بالكامل وقابلة للاستضافة الذاتية، تضمن Phoenix احتفاظ الفرق بالسيطرة الكاملة على بياناتها. ميزات مثل قوائم انتظار التعليقات التوضيحية البشرية السماح بإضافة ملصقات الحقيقة الأساسية مباشرة إلى الآثار، مما يعزز التعاون بشكل أفضل. ال برومبتو هاب يدير الإصدار الفوري والتخزين والنشر عبر البيئات، بينما دردشة سبان تتيح الأداة للفرق تقييم مقاطع سير عمل محددة ومناقشتها للكشف عن مشكلات الأداء. من خلال مجتمع Slack الذي يضم أكثر من 7,000 عضو، يمكن للمستخدمين الوصول إلى شبكة لاستكشاف الأخطاء وإصلاحها ومشاركة الأفكار.
«اندمجت Phoenix في عمليات سير عمل علوم البيانات الحالية لفريقنا ومكنت من استكشاف البيانات النصية غير المهيكلة لتحديد الأسباب الجذرية لمدخلات المستخدم غير المتوقعة واستجابات LLM الإشكالية والفجوات في قاعدة معارفنا.» - Yuki Waka، مطور التطبيقات، Klick
LangSmith عبارة عن منصة متعددة الاستخدامات مصممة للعمل بسلاسة مع LangChain أو بدونها، مما يجعلها قابلة للتكيف مع أي مجموعة LLM. إنه يتصل بسهولة بأدوات مثل OpenAI و Anthropic و CreWAI و Vercel AI SDK و Pydantic AI، مما يوفر المرونة للفرق التي تستخدم بالفعل أطر عمل محددة. تفي المنصة بمعايير الامتثال مثل HIPAA و SOC 2 Type 2 و GDPR، وتستخدم عملية غير متزامنة لإرسال الآثار، مما يضمن عدم وجود وقت استجابة إضافي للمستخدمين النهائيين.
عروض لانج سميث وضعين للتقييم لتناسب الاحتياجات المختلفة: التقييم دون اتصال بالإنترنت لاختبار مجموعات البيانات المنسقة أثناء التطوير والتقييم عبر الإنترنت لمراقبة حركة الإنتاج المباشر. يدعم أربعة أنواع من المقيّمين:
تتضمن المنصة أدوات تحليل متقدمة مثل عرض الفرق، الذي يسلط الضوء على الاختلافات بين مخرجات النموذج والنصوص المرجعية، والمقارنات جنبًا إلى جنب لقياس الأداء. كما يوفر تجميع البيانات الوصفية، مما يتيح تحليل المقاييس مثل الدقة أو التكلفة حسب الفئات مثل مجال الموضوع أو نوع المستخدم. يتكامل LangSmith مع المصدر المفتوح الفتحات الحزمة، التي تقدم مقيّمين تم تصميمهم مسبقًا لتقييم الصحة والإيجاز.
هذه الميزات تجعل من السهل دمج LangSmith في عمليات سير العمل وأدوات التطوير الحالية.
يبسط LangSmith عملية التتبع باستخدام @traceable أغلفة الديكور أو العميل التي تلتقط المدخلات والمخرجات تلقائيًا. وهو يدعم التكامل مع حزم SDK الخاصة بـ Python و TypeScript/JavaScript وواجهة برمجة تطبيقات REST وأطر الاختبار مثل pytest و Vitest و Jest، مما يجعل من السهل تضمين التقييمات في خطوط أنابيب CI/CD. بالإضافة إلى ذلك، يسمح تكامل OpenTelemetry للفرق بإرسال آثار من خطوط أنابيب المراقبة الحالية مباشرة إلى LangSmith.
يعزز LangSmith تعاون الفريق من خلال التعليقات البديهية وأدوات التعليقات التوضيحية. قوائم انتظار التعليقات التوضيحية تمكين التوجيه التلقائي لعمليات تشغيل محددة إلى خبراء الموضوع للمراجعة اليدوية والتسجيل بناءً على معايير مخصصة. ال برومبتو هاب يعمل كمساحة مركزية للفرق لتكرار المطالبات وإصدارها ومشاركتها، مع استكمال ميزات تتبع التغييرات والتراجع للحفاظ على الاتساق طوال عملية التطوير. تتيح إمكانات التعليقات التوضيحية المضمنة لأعضاء الفريق الإبلاغ عن المشكلات أو تقديم ملاحظات مستهدفة حول جودة الاستجابة، مما يؤدي إلى تحسين دقة التقييم وكفاءة سير العمل.
توفر المنصة أيضًا إدارة مفصلة للمستخدم وعزل عبء العمل، مما يضمن التعاون السلس بين الفرق. يمكن للمستخدمين التسجيل مجانًا على smith.langchain.com - لا حاجة لبطاقة ائتمان. للاستخدام في الإنتاج، تعمل LangSmith على أساس الدفع أولاً بأول، مع خطط المؤسسة المتاحة للاستضافة الذاتية على مجموعات Kubernetes عبر AWS أو GCP أو Azure.
عند تقييم منصات تقييم LLM، من الضروري مراعاة التوافق الفني والتكلفة وأساليب التقييم. فيما يلي نظرة فاحصة على الخيارات:
Prompts.ai يجمع أكثر من 35 طرازًا رائدًا تحت واجهة واحدة آمنة، مما يوفر عناصر تحكم FinOps التي يمكن أن تقلل من تكاليف برامج الذكاء الاصطناعي بنسبة تصل إلى 98٪. بريتراست يعمل على تبسيط عملية الإعداد باستخدام وكيل AI بدون تكوين، مما يؤدي إلى التقاط السجلات عبر عنوان URL أساسي واحد. يتضمن مليون عملية تتبع مجانًا، مع خطط مدفوعة تبدأ من 249 دولارًا في الشهر. ماكسيم آي يتكامل بسلاسة مع مجموعات المراقبة الحالية، مع التركيز على تسجيل الجودة عبر التتبع الكامل. يقدم خطة مجانية لما يصل إلى 10000 سجل شهريًا وخططًا مدفوعة تبدأ من 29 دولارًا لكل مقعد/شهر. أريز فينيكس يدعم الاستضافة الذاتية لخصوصية البيانات، ويتكامل مع أدوات مثل RAGAS و Giskard لتحليل متري أعمق. لانج سميث تم تصميمه لمستخدمي LangChain، مما يوفر إمكانية ملاحظة متقدمة، على الرغم من اختلاف أسعار دعم المؤسسة. والجدير بالذكر أن Notion حسنت سرعة تطويرها بعشرة أضعاف مع Braintrust، حيث زادت من حل 3 مشكلات يوميًا إلى 30.
يعمل النهج الفريد لكل منصة على تبسيط عملية صنع القرار بناءً على احتياجات التقييم الخاصة بك. فيما يلي كيفية مقارنتها من حيث طرق التقييم والتكامل والنشر:
يلعب تعقيد التكامل أيضًا دورًا رئيسيًا. يعد إعداد Braintrust المستند إلى البروكسي أمرًا بسيطًا - ما عليك سوى تحديث عنوان URL الأساسي لواجهة برمجة التطبيقات. يتكامل Maxim AI مع أدوات المراقبة الحالية، بينما يلبي تكامل LangChain الضيق من LangSmith احتياجات الملاحظة المتخصصة. تتميز Arize Phoenix بالمؤسسات التي تعطي الأولوية لسيادة البيانات، وتقدم حلاً مستضافًا ذاتيًا ومفتوح المصدر. وفي الوقت نفسه، يوفر Prompts.ai ضوابط حوكمة على مستوى المؤسسة ومسارات تدقيق كاملة للتشغيل الآمن.
«يزيل Braintrust تبديل السياق من خلال الجمع بين المراقبة والتقييم والتجريب. منصة واحدة تعني وقتًا أقل لدمج الأدوات.» - فريق Braintrust
للحصول على رؤى سريعة، تعمل عمليات النشر القائمة على البروكسي والتكامل العميق على تبسيط العملية. سيجد مستخدمو LangChain LangSmith مناسبًا بشكل طبيعي، في حين أن المؤسسات التي تدير البيانات الحساسة قد تميل نحو حلول مفتوحة المصدر مثل Arize Phoenix أو Prompts.ai للحصول على قدرات قوية للحوكمة والتدقيق.
استنادًا إلى التقييمات المقدمة، تقدم كل منصة مزايا متميزة لتحسين تحليل مخرجات LLM. Prompts.ai يوفر للمؤسسات وصولاً مركزيًا إلى النماذج الرائدة، جنبًا إلى جنب مع ضوابط FinOps التي يمكن أن تقلل تكاليف الذكاء الاصطناعي بنسبة تصل إلى 98٪، مع ضمان قدرات الحوكمة والتدقيق القوية. بريتراست تم تصميمه خصيصًا للفرق الهندسية سريعة الوتيرة، حيث أبلغت شركات مثل Notion عن زيادة 10 أضعاف في سرعة التطوير - مما يعزز حل المشكلات من 3 إلى 30 يوميًا. وبالمثل، لاحظت الفرق في Stripe و Airtable مكاسب في الدقة تزيد عن 30٪ في غضون أسابيع من اعتماد المنصة.
بالنسبة لأولئك الذين تم دمجهم بعمق في نظام LangChain البيئي، لانج سميث يوفر تكاملًا سهلًا وخيارات نماذج أولية سريعة. ماكسيم آي يلبي احتياجات الفرق التي تركز على إدارة الأنظمة المعقدة متعددة الوكلاء، ويقدم أدوات تسجيل دقيقة وبوابة منخفضة زمن الوصول تقدم 11 ميكروثانية فقط من النفقات العامة بحجم 5000 طلب في الثانية. وفي الوقت نفسه، أريز فينيكس مثالي للمؤسسات التي تعطي الأولوية لسيادة البيانات، حيث تقدم حلاً مستضافًا ذاتيًا ومفتوح المصدر يتناسب بسلاسة مع أنظمة المراقبة الحالية.
تتناول كل منصة التحديات الحرجة في أداء LLM وإدارة التكاليف. مع الشركات التي تواجه خسائر محتملة 1.9 مليار دولار سنويًا نظرًا لفشل LLM غير المكتشف في الإنتاج، أصبحت الحاجة إلى تجاوز التقييمات الذاتية إلى المقاييس القابلة للقياس والقائمة على البيانات ضرورية لضمان الموثوقية والكفاءة.
تعمل هذه الأدوات على رفع تطوير LLM إلى تخصص هندسي منظم. سواء كان تركيزك على التعامل مع تريليونات الأحداث شهريًا، أو تبسيط التعاون بين الفرق، أو الحفاظ على السيطرة على البنية التحتية المستضافة ذاتيًا، فإن اختيار النظام الأساسي المناسب يضمن سير عمل LLM الخاص بك تحقيق الموثوقية والجودة والفعالية من حيث التكلفة المطلوبة لتحقيق أهدافك.
تم تصميم هذه المنصات لمساعدة المؤسسات على خفض نفقات الذكاء الاصطناعي من خلال تقديم أدوات لمراقبة وضبط استخدام نماذج اللغات الكبيرة (LLMs). على سبيل المثال، تسمح حلول مثل Prompts.ai للمستخدمين بتتبع استخدام الرمز المميز في الوقت الفعلي، مما يسهل اكتشاف الاستهلاك غير الضروري للرموز والحد منه. يساعد هذا في تجنب الإنفاق الزائد على مكالمات API المفرطة، مما يؤدي إلى إدارة أفضل للتكلفة.
بالإضافة إلى التحكم في التكلفة، توفر هذه المنصات أيضًا رؤى قيمة حول الأداء وجودة الإنتاج. يمكن أن تساعد في اكتشاف ومنع مشاكل مثل الهلوسة أو الأخطاء، والتي قد تؤدي بخلاف ذلك إلى إعادة صياغة مكلفة. من خلال تحليل اتجاهات الاستخدام وتحديد أوجه القصور، يمكن للمؤسسات تبسيط سير العمل وخفض التكاليف التشغيلية وضمان نتائج متسقة وعالية الجودة. كل هذا يدعم القرارات الأكثر ذكاءً والقائمة على البيانات لإدارة ميزانيات الذكاء الاصطناعي بفعالية.
توفر منصات LLM طرقًا مختلفة للتواصل بسلاسة مع الأدوات وسير العمل، مما يلبي الاحتياجات المختلفة. تدعم العديد من المنصات التكامل الأصلي من خلال حزم SDK مثل Python و JavaScript، جنبًا إلى جنب مع أطر مثل LangChain و LangServe. هذا يجعل تضمين LLMs في التطبيقات المخصصة أمرًا بسيطًا وفعالًا. بالنسبة للمراقبة، غالبًا ما تدعم المنصات المعايير المفتوحة مثل OpenTelemetry، مما يضمن التوافق مع البنية التحتية الحالية.
تتكامل بعض المنصات أيضًا مع أدوات CI/CD مثل GitHub Actions و Jenkins، مما يبسط عمليات الاختبار والنشر. بالنسبة للمؤسسات التي تعطي الأولوية للتحكم في بيئتها، تتوفر خيارات الاستضافة الذاتية، مما يسمح بالتخصيص مع الحفاظ على أمان البيانات. تتيح ميزات التكامل هذه للمستخدمين تعزيز الكفاءة ومراقبة الأداء بفعالية وتنفيذ LLMs بأمان داخل عملياتهم.
بالنسبة لأولئك الذين يضعون علاوة على خصوصية البيانات والتحكم فيها، أون بريم إل إم يقدم حلاً ممتازًا. تم تصميم هذه المنصة خصيصًا للمهام الحساسة للخصوصية، وتسمح لنماذج اللغات الكبيرة (LLMs) بالتعامل مع البيانات السرية أو المقيدة بأمان في الإعدادات غير المتصلة بالإنترنت. من خلال تمكين التنفيذ المحلي بالكامل، فإنه يقلل بشكل كبير من فرص التعرض للبيانات، مع توفير تكامل سحابي اختياري للإعدادات المختلطة عند الضرورة.
من خلال واجهته البديهية الخالية من التعليمات البرمجية، يضمن OnPrem.llm إمكانية الوصول للمستخدمين الذين ليس لديهم خبرة فنية، كل ذلك مع الحفاظ على الإشراف الكامل على إدارة البيانات. وهذا يجعلها خيارًا مثاليًا للمؤسسات في الصناعات المنظمة أو الحساسة حيث تكون حماية المعلومات أولوية قصوى.



















