Pay As You Goإصدار تجريبي مجاني لمدة 7 أيام؛ لا يلزم وجود بطاقة ائتمان


تبحث عن أدوات لمقارنة المخرجات من نماذج الذكاء الاصطناعي مثل جي بي تي -4، كلود، أو لاما؟ إليك ما تحتاج إلى معرفته:
تعمل هذه الأدوات على تبسيط عملية صنع القرار من خلال مساعدة المستخدمين على تحديد النماذج الأفضل أداءً والأكثر فعالية من حيث التكلفة لاحتياجاتهم. فيما يلي مقارنة سريعة لميزاتها.
اختر استنادًا إلى ميزانية فريقك واحتياجات الأمان وأولويات سير العمل.
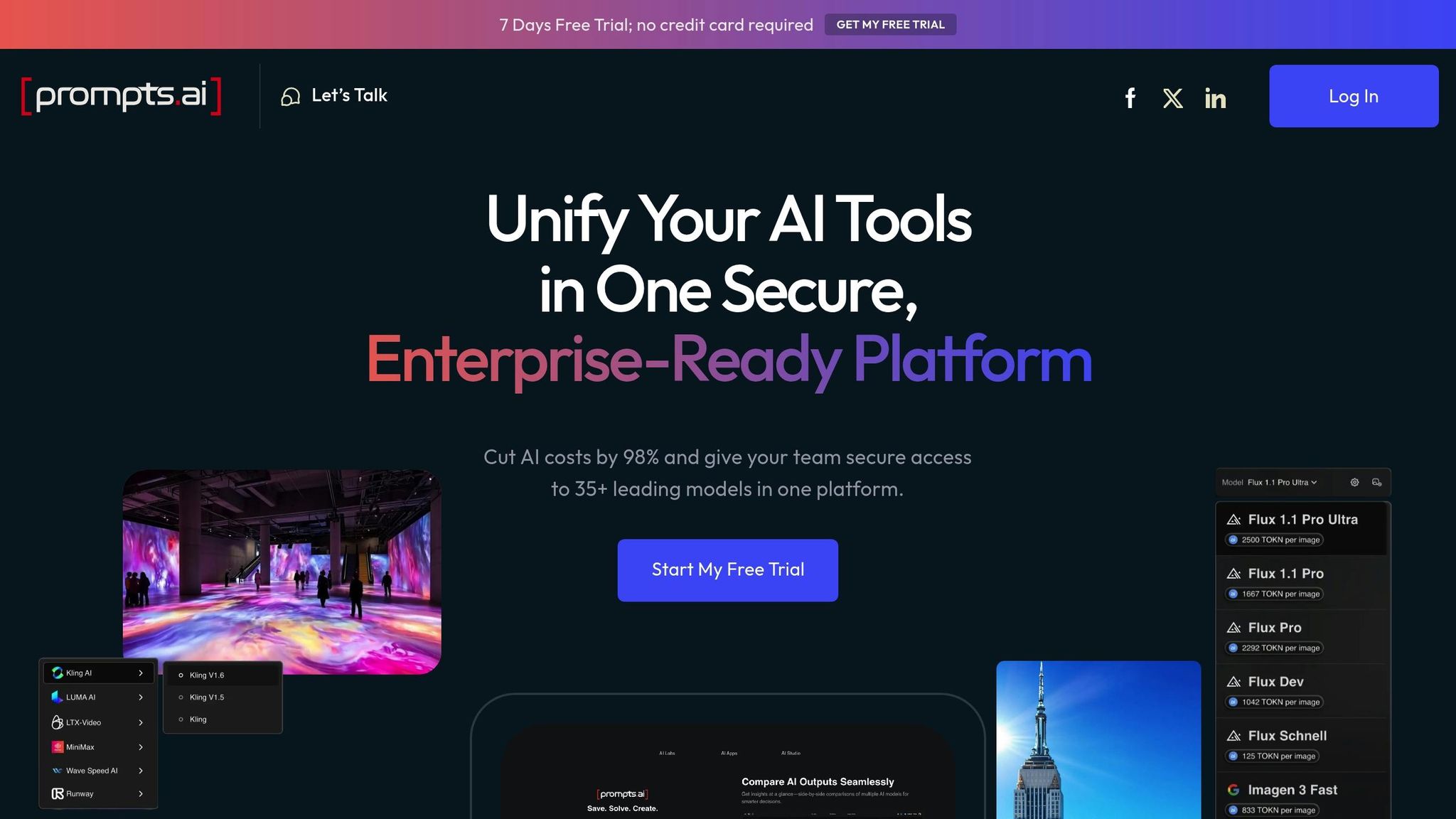
Prompts.ai عبارة عن منصة على مستوى المؤسسة تجمع أكثر من 35 شركة LLM رائدة في واجهة واحدة آمنة، مما يزيل متاعب التوفيق بين أدوات متعددة.
يمكن لـ Prompts.ai، المصمم لشركات Fortune 500 والوكالات والمختبرات البحثية، تقليل تكاليف الذكاء الاصطناعي بنسبة تصل إلى 98٪ مع الحفاظ على أمان المؤسسة من الدرجة الأولى. من لوحة تحكم واحدة موحدة، يمكن للفرق الوصول إلى نماذج مثل GPT-4 و Claude و LLama و الجوزاء.
إحدى الميزات البارزة لـ Prompts.ai هي مقارنة جنبًا إلى جنب أداة. يتيح ذلك للمستخدمين تشغيل نفس المطالبات عبر نماذج مختلفة في وقت واحد، مما يجعل من السهل تحديد الخيار الأفضل أداءً دون الحاجة إلى التبديل المستمر بين الأنظمة الأساسية أو تتبع النتائج يدويًا.
تتضمن المنصة أيضًا التبديل الفوري للنموذج، الذي يحتفظ بسياق عملك. وهذا مفيد بشكل خاص لاختبار كيفية تعامل النماذج المختلفة مع نفس المهمة أو لتحسين نتائج محددة، مثل الإبداع أو الدقة أو كفاءة التكلفة.
ميزة قوية أخرى هي تسلسل الوكيل، حيث يمكن تغذية المخرجات من أحد النماذج إلى نموذج آخر. يعد هذا مثاليًا لبناء عمليات سير عمل معقدة واختبار كيفية أداء مجموعات النماذج المختلفة معًا لتحقيق أهداف محددة. تتكامل هذه القدرات بسلاسة مع المراقبة في الوقت الفعلي لتبسيط عملية التقييم.
يقدم Prompts.ai ملاحظات في الوقت الفعلي حول الأداء، مما يساعد الفرق على اتخاذ قرارات أسرع وأكثر استنارة أثناء التقييمات.
تحتوي المنصة على جهاز مدمج طبقة FinOps يتتبع كل رمز مستخدم في جميع النماذج. تسمح هذه الشفافية للفرق بفهم تكاليف الذكاء الاصطناعي بشكل كامل وتخصيص الموارد بشكل أكثر فعالية. من خلال توفير رؤى تفصيلية حول التكلفة لمهام محددة، يمكن للفرق موازنة أهداف الأداء الخاصة بها مع اعتبارات الميزانية.
مع تحليلات الاستخدام في الوقت الفعلي، تكتسب الفرق رؤى قابلة للتنفيذ حول اتجاهات أداء النموذج. هذا يحول ما قد يكون اختبارًا مخصصًا إلى عملية تقييم منظمة تدعم اتخاذ قرارات أفضل على المدى الطويل. يضمن الجمع بين هذه الميزات الشفافية والكفاءة طوال عملية التقييم.
يدعم Prompts.ai أكثر من 35 LLMs رائدًا، ويقدم أدوات لمهام مثل إنشاء التعليمات البرمجية والكتابة الإبداعية وتحليل البيانات. يتم تحديث مكتبة المنصة باستمرار لضمان الوصول إلى أحدث الموديلات.
يسمح هذا الاختيار الشامل للفرق بقياس الأداء عبر مختلف مزودي الذكاء الاصطناعي وأنواع النماذج. سواء كان التركيز على المهام الفنية أو المشاريع الإبداعية أو الاحتياجات التحليلية، يوفر Prompts.ai الأدوات المناسبة لإجراء تقييم شامل.
يعطي Prompts.ai الأولوية للأمان على مستوى المؤسسة، مما يضمن بقاء البيانات الحساسة محمية ويقلل من مخاطر التعرض لأطراف ثالثة.
تتضمن المنصة أدوات حوكمة مدمجة ومسارات تدقيق لكل سير عمل، مما يجعل الامتثال للمتطلبات التنظيمية أكثر بساطة. يمكن للفرق تتبع النماذج التي تم الوصول إليها، والمطالبات المستخدمة، والمخرجات التي تم إنشاؤها، وإنشاء سجل مفصل للمساءلة والأغراض التنظيمية.
مع أرصدة TOKN للدفع أولاً بأول، تلغي المنصة الحاجة إلى رسوم الاشتراك المتكررة. بدلاً من ذلك، تتماشى التكاليف بشكل مباشر مع الاستخدام الفعلي، مما يمنح المؤسسات مزيدًا من المرونة والتحكم في إنفاقها على الذكاء الاصطناعي. يسمح هذا النموذج للفرق بتوسيع نطاق استخدامها لأعلى أو لأسفل بناءً على احتياجات المشروع، مما يضمن الفعالية من حيث التكلفة والقدرة على التكيف.

Deepchecks عبارة عن منصة مفتوحة المصدر مصممة للاختبار المستمر ومراقبة نماذج التعلم الآلي. من خلال تطبيق مبادئ اختبار البرامج التقليدية، فإنه يضمن اتباع نهج منظم لتقييم المخرجات من نماذج اللغات الكبيرة (LLMs). تعمل هذه الأداة كخيار صارم للتحقق من الصحة، حيث تكمل منصات المؤسسات مثل Prompts.ai.
على عكس المنصات التي تركز على المؤسسات، تعطي Deepchecks الأولوية للتحقق الشامل من النموذج. وهي تتضمن مجموعات التحقق الآلي التي تسمح للمستخدمين بمقارنة مخرجات النموذج بناءً على المعايير المخصصة والتحليلات المجمعة. من خلال ميزات مثل اكتشاف الانجراف والقدرة على تحديد المقاييس المخصصة، فإنه يساعد في تحديد الانحرافات عن السلوك المتوقع.
تتعقب Deepchecks بنشاط أداء الإنتاج، باستخدام التنبيهات الآلية المرتبطة بحدود الجودة. تعمل أنظمة التحليلات القوية واكتشاف العيوب على تسهيل تحديد السلوكيات غير المتوقعة ومعالجتها بسرعة.
لحماية البيانات الحساسة، تدعم Deepchecks النشر المحلي. بالإضافة إلى ذلك، فإنه يوفر مسار تدقيق لتوثيق أنشطة الاختبار، مما يضمن التوافق مع متطلبات الامتثال.
DeepEval هو إطار مفتوح المصدر مصمم لتقييم مخرجات نموذج اللغة الكبيرة (LLM) مع إعطاء الأولوية لخصوصية البيانات. إنه بمثابة أداة موثوقة لتلبية الحاجة المتزايدة لتقييمات LLM الآمنة والدقيقة.
تقدم DeepEval أدوات مرنة لمقارنة المخرجات جنبًا إلى جنب ووضع معايير تقييم مخصصة. تساعد هذه الميزات الفرق على تقييم استجابات النموذج بدقة، وتلبية المتطلبات المتنوعة لتقييم الذكاء الاصطناعي الحديث.
يتكامل الإطار بسلاسة مع سير عمل التطوير، مما يسمح للفرق بمراقبة الأداء في الوقت الفعلي وإجراء التعديلات حسب الحاجة.
من خلال إجراء التقييمات محليًا، يضمن DeepEval حماية البيانات الحساسة، مما يوفر طبقة إضافية من الأمان للمستخدمين.
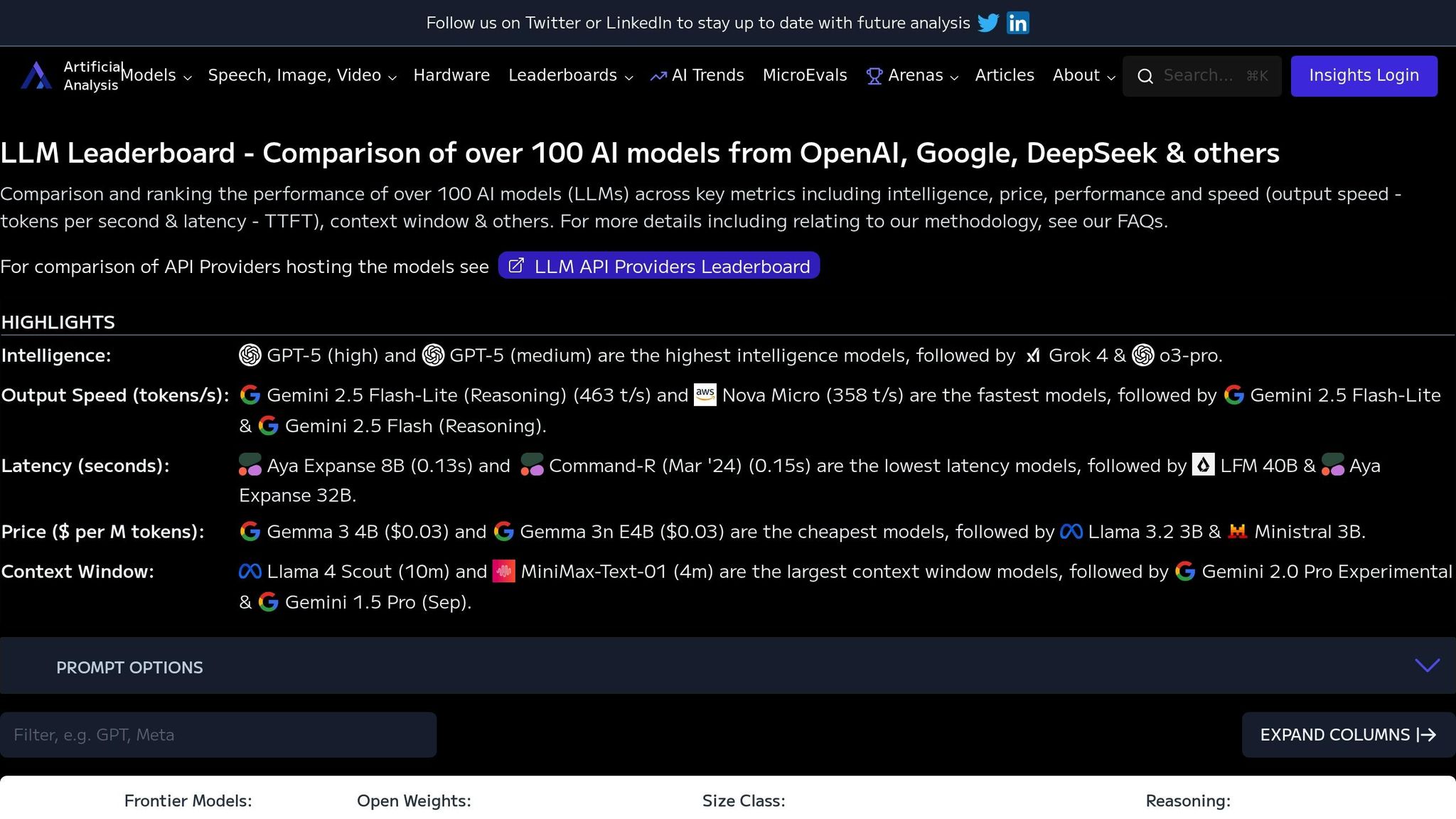
تُعد لوحة LLM Leaderboard من ArtificialAnalysis.ai بمثابة مركز مرجعي لمقارنة أداء أكثر من 100 نموذج من نماذج الذكاء الاصطناعي. وهي تستخدم نظام تقييم يعتمد على البيانات مع مقاييس موحدة، مما يمنح الفرق الوضوح الذي يحتاجون إليه لاتخاذ خيارات النشر الذكية. فيما يلي، نستكشف ميزاته البارزة.
تقوم المنصة بتقييم النماذج بناءً على ثلاثة مجالات رئيسية: ذكاء، التكلفة، و سرعة الإخراج.
تعمل هذه المقاييس على إنشاء إطار عمل مشترك لمقارنة قدرات الذكاء الاصطناعي، وتمكين الفرق من تقييم النماذج بموضوعية واختيار الأنسب لاحتياجاتهم.
توفر لوحة المتصدرين تتبعًا مباشرًا للأداء، مما يضمن وصول المستخدمين إلى أحدث البيانات. يتم تحديث المقاييس بشكل متكرر - ثماني مرات يوميًا للطلبات الفردية ومرتين يوميًا للطلبات الموازية - باستخدام البيانات التي تم جمعها على مدار الـ 72 ساعة الماضية. تضمن هذه المراقبة في الوقت الفعلي رؤية أي تحولات في الأداء بسرعة، مما يساعد المؤسسات على اتخاذ قرارات النشر بثقة.
تغطي المنصة مجموعة واسعة من نماذج الذكاء الاصطناعي، وتوفر رؤية شاملة للنظام البيئي الحالي للذكاء الاصطناعي. لا يساعد هذا النطاق الواسع المحترفين على تحديد الحلول الأكثر ملاءمة فحسب، بل يشجع أيضًا التقدم بين المطورين من خلال تعزيز الشفافية والمنافسة الصحية من خلال مقاييس الأداء.
بعد فحص الأدوات بالتفصيل، دعنا نحلل نقاط القوة والقيود الرئيسية. تحتوي كل منصة على مجموعة المقايضات الخاصة بها، مما يجعل من الضروري للفرق أن تزن احتياجاتها الخاصة عند اختيار أداة التقييم المناسبة. فيما يلي نظرة فاحصة على الميزات البارزة والمجالات التي قد تفشل فيها هذه الأدوات.
Prompts.ai يبرز كحل قوي للمؤسسات، حيث يقدم منصة موحدة لمقارنة أكثر من 35 شركة LLM رائدة، يمكن الوصول إليها جميعًا من خلال واجهة واحدة. توفر عناصر تحكم FinOps في الوقت الفعلي رؤى تفصيلية حول التكلفة، مما يساعد المؤسسات على تقليل نفقات برامج الذكاء الاصطناعي بنسبة تصل إلى 98% من خلال التتبع الشفاف للرموز والإنفاق الأمثل. تعمل المنصة أيضًا على تبسيط عمليات الذكاء الاصطناعي المعقدة من خلال تسلسل الوكلاء وإدارة سير العمل المتكاملة، مما يقلل الاعتماد على أدوات متعددة. ومع ذلك، تأتي هذه الميزات المتقدمة بسعر أعلى، مما قد يشكل تحديات للفرق الصغيرة ذات الميزانيات المحدودة.
منصات أخرى تلبي الاحتياجات الأكثر تخصصًا. يعطي البعض الأولوية لموثوقية النموذج وسلامته، ويقدم أدوات لمراقبة الأداء، بينما يركز البعض الآخر على التخصيص أو سهولة الاستخدام أو القياس. هذه الخيارات، على الرغم من قيمتها، قد تنطوي على منحنى تعليمي أكثر حدة أو تتطلب جهود تكوين كبيرة لتلبية متطلبات محددة.
فيما يلي مقارنة سريعة لميزاتها الأساسية:
عند اتخاذ القرار، ضع في اعتبارك ميزانية فريقك والخبرة الفنية ومتطلبات سير العمل. Prompts.ai يقدم حلاً مؤسسيًا مثبتًا مع إدارة التكاليف وسير العمل المبسط، بينما تتألق المنصات الأخرى في مجالات مثل السلامة أو مرونة المطور أو عمق القياس. تقدم كل أداة شيئًا ذا قيمة إلى الطاولة، لذلك يعتمد الاختيار في النهاية على أولوياتك المحددة.
بعد تقييم قدرات كل أداة ومقايضاتها، من الواضح أن أحد الحلول يتفوق على البقية لتنسيق الذكاء الاصطناعي في المؤسسة. Prompts.ai يوفر واجهة موحدة تدمج أكثر من 35 طرازًا، بما في ذلك GPT-4 و Claude و LLama و Gemini، كل ذلك مع توفير ضوابط التكلفة في الوقت الفعلي التي يمكن أن تخفض نفقات الذكاء الاصطناعي بمقدار 98%. إنه مرن الدفع أولاً بأول يزيل نظام TOKN الائتماني عبء رسوم الاشتراك المتكررة، وتضمن ميزات الحوكمة المضمنة فيه، بما في ذلك مسارات التدقيق التفصيلية، الامتثال للمنظمات التي تتراوح من شركات Fortune 500 إلى الوكالات الإبداعية ومختبرات الأبحاث.
باستخدام Prompts.ai، تكتسب الفرق إدارة التكاليف الشفافة والحوكمة القوية وعمليات الذكاء الاصطناعي الفعالة - كل ذلك في منصة واحدة. من خلال دمج تقييم الذكاء الاصطناعي وتنسيقه في حل واحد قوي، يلبي Prompts.ai متطلبات سير العمل على مستوى المؤسسة مع تبسيط تعقيدات إدارة بيئات الاختبار المتعددة. بالنسبة للفرق التي تهدف إلى تبسيط عملياتها وتعظيم القيمة، توفر هذه المنصة الأدوات والموثوقية التي تحتاجها.
يمكّن Prompts.ai الشركات من خفض نفقات الذكاء الاصطناعي بمقدار 98%، وذلك بفضل منصتها المبسطة التي تدمج عمليات الذكاء الاصطناعي في نظام مركزي واحد. من خلال تقديم واجهة موحدة للاختبار والتقييم الفوريين، فإنه يزيل متاعب التوفيق بين العديد من الأدوات غير المتصلة، مما يوفر الوقت والموارد القيمة.
الميزة الرئيسية لـ Prompts.ai هي التخزين المؤقت الفوري النظام، الذي يعيد استخدام المطالبات المتطابقة بدلاً من معالجتها بشكل متكرر. تعمل هذه الإستراتيجية الذكية على تقليل التكاليف التشغيلية بشكل كبير، مما يسمح للشركات بضبط تدفقات عمل الذكاء الاصطناعي دون زيادة الإنفاق.
يعطي Prompts.ai الأولوية للأمان من الدرجة الأولى للوفاء بالمعايير على مستوى المؤسسة. توظف تشفير من طرف إلى طرف لحماية البيانات أثناء الإرسال، المصادقة متعددة العوامل (MFA) لمزيد من أمان تسجيل الدخول، و تسجيل الدخول الأحادي (SSO) لتبسيط إدارة الوصول وتأمينها.
تتضمن المنصة أيضًا سجلات تدقيق مفصلة لمراقبة النشاط بشكل شامل واستخداماته إخفاء هوية البيانات لحماية المعلومات الحساسة. من خلال الالتزام بأطر الامتثال الهامة مثل سوك 2 و GDPR، يضمن Prompts.ai حماية بياناتك مع الحفاظ على توافق مؤسستك مع المتطلبات التنظيمية.
ال تسلسل الوكيل تعمل الميزة في Prompts.ai على تبسيط عملية التقييم لنماذج الذكاء الاصطناعي من خلال تقسيم المهام المعقدة إلى خطوات أصغر وأكثر قابلية للإدارة. يتيح هذا النهج المعالجة المتسلسلة والاختبار متعدد الخطوات، مما يوفر طريقة مفصلة لتقييم أداء النموذج.
من خلال التشغيل الآلي لهذه الخطوات المرتبطة، تعمل سلسلة الوكلاء على تعزيز الموثوقية وتقديم رؤى أكثر شمولاً حول كيفية تعامل النماذج مع عمليات سير العمل المعقدة. لا يؤدي ذلك إلى تحسين جودة التقييمات فحسب، بل يوفر أيضًا للفرق وقتًا وجهدًا كبيرًا.


















