Pay As You Go7 天免费试用;无需信用卡


机器学习编排平台 简化 AI 工作流程,降低成本并增强可扩展性。 本指南根据其功能、可用性和成本透明度对10个领先平台进行了评估,以帮助您选择适合业务需求的解决方案。
根据您的优先级选择平台: 节省成本, 可扩展性,或 与现有工具集成。对于 LLM 密集的工作流程, Prompts.ai 处于领先地位。为了满足更广泛的机器学习需求, 气流 要么 Kubeflow 是强大的开源选项。基于云的企业可能更喜欢 天蓝机器学习 要么 顶点人工智能 用于无缝集成。

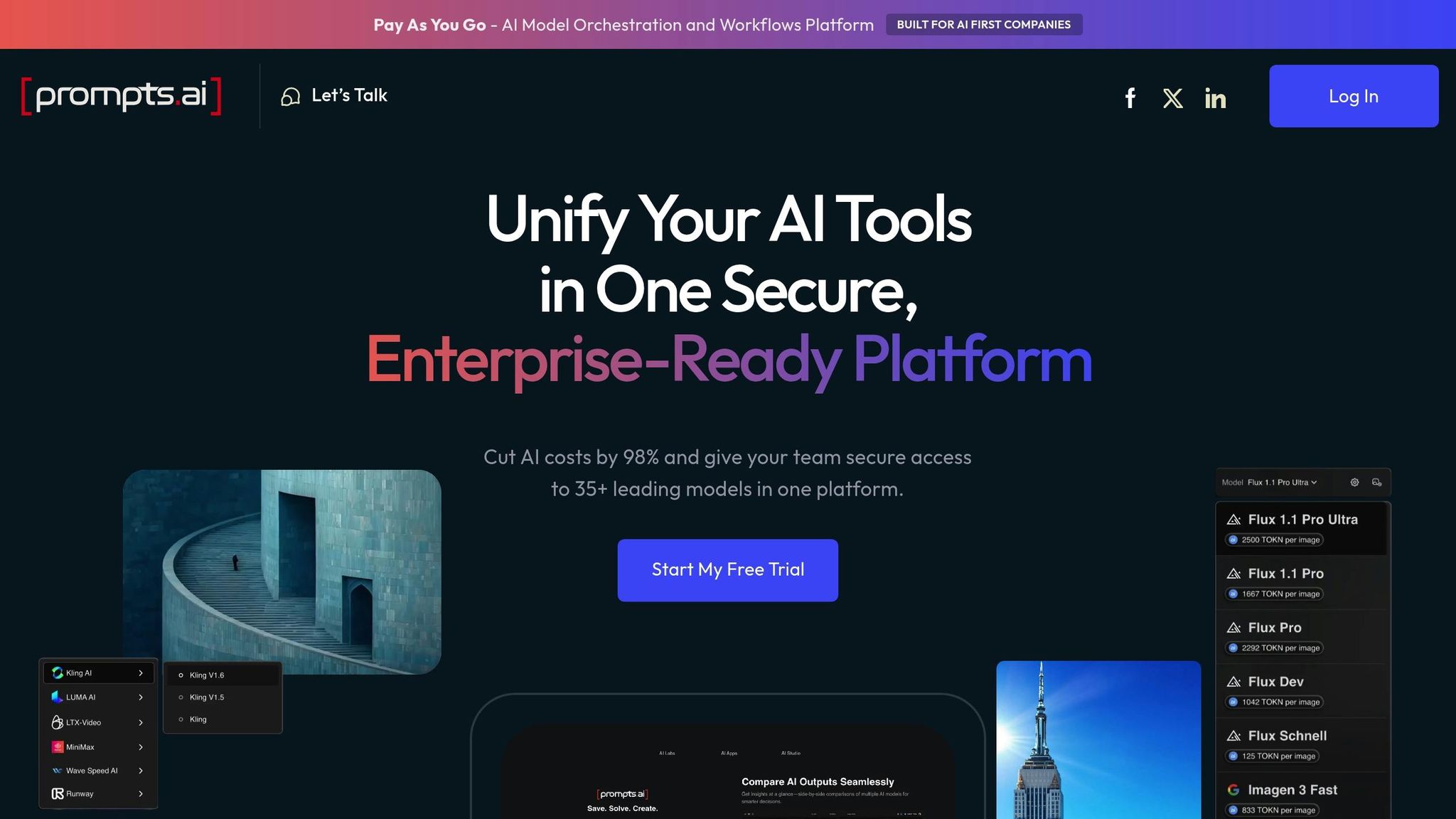
Prompts.ai 是一个 企业级 AI 编排平台 旨在简化 AI 工具的管理。它解决了工具蔓延和隐性开支的挑战,这些挑战通常在人工智能举措能够提供可衡量的结果之前就受到阻碍。
通过专注于互操作性、可扩展性和高效的工作流程管理,Prompts.ai 解决了企业 AI 运营中的关键痛点。
该平台的突出特点是它能够 统一访问超过 35 种领先的大型语言模型 (LLM) -包括 GPT-4、Claude、LLaMa 和 Gemini-通过单一的安全接口实现。这种方法消除了通常会使企业 AI 部署复杂化的分散性。
Prompts.ai 确保 无缝的跨模型兼容性 通过提供适用于各个 LLM 提供商的统一接口。它还集成了广泛使用的商业工具,例如 Slack、Gmail 和 Trello,使其自然适合现有工作流程。
该平台的架构支持不同模型的并排比较,使用户无需多个接口或 API 密钥即可评估性能。这种简化的方法简化了决策,并确保为每个特定用例选择最佳模型。
专为处理而设计 企业级需求,Prompts.ai 采用云原生架构,可以随着团队的成长和人工智能使用量的增加轻松扩展。添加新模型、用户或团队是一个快速而直接的过程,无需对基础架构进行重大更改。
该平台的 即用即付 TOKN 积分系统 取代了固定的月度订阅,使企业更容易根据实际需求扩展 AI 的使用。这种灵活性对于工作负载波动的公司或正在尝试新的自动化机会的公司尤其有价值。
Prompts.ai 将一次性的 AI 任务转换为结构化、可重复的工作流程。团队可以创建标准化的提示工作流程,确保一致的输出,同时减少手动提示工程花费的时间。
此外,该平台支持高级自定义,包括训练和微调 LoRA(低等级适配器)以及创建 AI 代理。这些功能使组织能够构建符合其特定业务目标的量身定制的自动化工作流程。
Prompts.ai 专为 LLM 工作流程而构建,提供用于管理提示、跟踪版本和监控性能的工具。
它还包括 专家设计的 “省时器”,这是由经过认证的即时工程师创建的预建工作流程。这些即用型解决方案可帮助企业快速实施常见用例,同时保持高质量标准。
不可预测的成本是企业采用人工智能的主要障碍,Prompts.ai 通过以下方式解决了这个问题 实时支出见解。该平台跟踪模型和团队中使用的每种代币,使组织可以清楚地了解其人工智能支出。根据公司数据,通过 Prompts.ai 整合 AI 工具最多可以导致 节省 98% 的成本。这些节省来自于减少软件订阅以及根据性能和成本优化模型选择。
该平台的 FinOps 层 将人工智能支出与业务成果联系起来,帮助财务团队证明投资合理性并避免预算超支。此功能可确保 AI 计划在提供可衡量的价值的同时保持财务可行性。
Kubeflow 是一个开源平台,旨在在 Kubernetes 上协调机器学习 (ML) 工作流程。它最初由 Google 开发,现在由 CNCF 社区管理,提供了一套强大的工具,可以高效部署、管理和扩展容器化机器学习工作流程。
Kubeflow 专为专注于 Kubernetes 的组织而构建,它简化了机器学习操作的复杂性,将其转变为简化、可重复的工作流程。让我们来探讨一下它的可扩展性, 工作流程自动化、与大型语言模型 (LLM) 的集成以及它如何帮助管理成本。
Kubeflow 利用 Kubernetes 的横向扩展来管理企业级要求苛刻的机器学习工作负载。通过将计算任务分配到多个节点,它可以高效处理大型数据集和训练复杂的模型。
它的架构旨在支持流行框架的分布式训练,例如 TensorFLOW 和 PyTorch。这使团队可以无缝扩展其工作负载,从单台计算机扩展到多个 GPU,而无需对代码进行任何更改。
Kubernetes 的资源管理功能,例如配额和限制,进一步增强了可扩展性。组织可以将特定的 CPU、内存和 GPU 资源分配给不同的团队或项目,从而确保资源的公平分配,没有单一工作流程给系统带来过重负担。
借助 Kubeflow Pipelines,团队可以使用可视化界面或 Python SDK 创建可重现的工作流程。管道中的每个步骤都是容器化和版本控制的,因此可以在不同的项目中重复使用。
预建的管道模板有助于标准化重复任务,例如数据预处理、模型训练和验证。这不仅缩短了新项目的设置时间,而且还确保了团队之间的一致性。此外,Kubeflow 通过自动记录每次管道运行的参数、指标和工件来简化实验跟踪,使团队更容易比较模型版本和复制成功结果。
Kubeflow 设备齐全,可通过其由 KServe 提供支持的可扩展模型服务功能来支持 LLM 工作流程。这使得部署可以处理高要求的推理端点成为可能。此外,与诸如此类的库集成 拥抱的脸 Transformers 允许团队将预先训练的 LLM 无缝整合到他们的管道中。
Kubeflow 利用 Prometheus 等 Kubernetes 监控工具,提供有关基础设施使用情况的详细见解。通过跟踪 CPU、内存和 GPU 消耗,团队可以获得优化基础架构和有效管理成本所需的可见性。

得益于其专门的扩展,Apache Airflow 已发展成为管理机器学习工作流程的强大平台。这个开源工具最初由爱彼迎于2014年创建,现在在从初创企业到大公司等组织的机器学习运营中发挥着至关重要的作用。
Airflow 的突出特点之一是 有向无环图 (DAG) 框架,它允许用户将复杂的机器学习工作流程设计为代码,从而实现灵活且高度可定制的管道创建。
Airflow 的优势在于它能够与各种机器学习工具和服务无缝集成。它的生态系统是 运算符和挂钩 支持与几乎任何 ML 框架或云平台的顺畅连接。原生集成包括 TensorFlow、PyTorch 和 Scikit-Learn,以及来自 AWS、谷歌云和微软 Azure 的基于云的机器学习服务。
这个 Airflow ML 供应商 该软件包通过为 MLFlow 和 Weights & Biases 等工具提供专业的运算符,进一步增强了这种互操作性。这使团队无需自定义集成代码即可构建连接多个工具的端到端工作流程。例如,单个 DAG 可以从 Snowflake 获取数据,使用 Spark 对其进行预处理,使用 TensorFlow 训练模型,然后将其部署到 Kubernetes,同时保持对每个步骤的完全控制和可见性。
Airflow在数据库连接方面也表现出色,为PostgreSQL、MySQL、MongoDB和许多其他数据源提供内置支持。这使其成为组织管理跨不同数据系统的复杂机器学习工作流程的绝佳选择。
Airflow 的可扩展性由 CeleryExecutor 和 KubernetesExecutor,这允许工作负载在多个工作节点上横向扩展。KubernetesExecutor 特别适合机器学习任务,因为它可以为工作流程的不同阶段动态分配具有特定资源要求的容器。
用它的 任务并行化 功能,Airflow 使团队能够同时进行多个 ML 实验,从而显著缩短了超参数调整和模型比较所需的时间。可以对资源池进行配置,以确保培训等资源密集型任务不会使系统不堪重负,同时较轻的流程可以不间断地继续运行。
对于处理大型数据集的组织,Airflow 的处理方式是 回填 和 迎头赶上 操作确保在引入新模型或功能时可以高效处理历史数据。
Airflow 将 ML 工作流程转换为 有文档记录的、受版本控制的管道 使用基于 Python 的 DAG 定义。每个步骤都经过明确定义,包括依赖关系、重试逻辑和故障处理,从而确保稳健的管道能够自动从错误中恢复。
该平台的 传感器操作员 使事件驱动的工作流程成为可能,在新数据到达或模型性能下降到可接受的阈值以下时触发再训练流程。这种自动化对于在数据经常变化的动态生产环境中保持模型的准确性至关重要。
通过管理 任务依赖关系,Airflow 确保工作流程按正确的顺序执行。下游任务会自动等待上游流程成功完成,从而降低出错的风险,例如在不完整或损坏的数据上训练模型。这消除了复杂管道中通常需要的大部分手动协调。
尽管 Airflow 最初并不是为大型语言模型 (LLM) 设计的,但最近的开发扩展了其处理能力 微调管道 适用于 BERT 和 GPT 变体等模型。Airflow 现在可以管理数据准备、代币化、训练和评估等任务之间的依赖关系。
它的处理能力 长时间运行的任务 使其成为可能需要数小时甚至数天的 LLM 培训工作的理想之选。Airflow 监控这些进程,在出现问题时发送警报,并自动从检查点重启失败的运行。
适用于实施的组织 检索增强生成 (RAG) 系统,Airflow 可以协调整个过程——从文档摄取和嵌入生成到更新矢量数据库和准备部署模型。此外,Airflow 还提供了控制成本所需的运营见解。
Airflow 优惠详情 任务级记录和监控,让团队可以清楚地了解其工作流程中的资源使用情况。这种精细跟踪可帮助组织更有效地管理计算成本,尤其是在云环境中,成本可能因实例类型和使用情况而异。
该平台的 任务持续时间跟踪 功能可识别管道中的瓶颈,使团队能够优化资源分配并提高效率。对于基于云的部署,这种可见性对于控制与计算密集型任务相关的费用至关重要。
和 SLA 监控,当工作流程超过预期运行时间时,Airflow 会提醒团队,强调可能导致不必要支出的效率低下。这种成本和性能的平衡使得 Airflow 成为旨在优化机器学习运营的组织的宝贵工具。

多米诺数据实验室作为在企业层面协调机器学习的强大平台脱颖而出。它专为处理不断增长的工作负载和大规模部署而打造,为高效的资源管理和可扩展的性能提供了坚实的基础。
多米诺数据实验室的架构旨在适应不断变化的需求。它采用动态资源分配和弹性扩展,根据工作负载需求自动调整资源。通过与集群系统集成,它可以实现从小规模实验到大规模模型训练的平稳过渡。其先进的工作负载调度可确保资源在项目间高效分配,从而在企业环境中提供稳定的性能。

DataRobot 人工智能平台为管理机器学习操作提供了强大的企业级解决方案。它充当集中式情报层,连接各种人工智能系统,使其能够适应一系列技术设置。
DataRobot 在构建时考虑了互操作性,提供了支持各种人工智能策略的开放架构。这种设计允许组织评估和选择根据其独特要求量身定制的生成式 AI 组件。
该平台支持在不同的预测环境中部署原生、自定义和外部模型。这些部署可以在 DataRobot 的基础设施或外部服务器上进行,从而为各种运营需求提供灵活性。
为了简化集成,该平台包含 REST API 和 Python 客户端包。这可确保编码工作流程和可视界面之间的平稳过渡,满足技术和非技术用户的需求。
此外,DataRobot 与领先的云提供商和数据服务无缝集成,可以直接访问实时云环境。这些功能使得 DataRobot 成为简化和统一企业 AI 工作流程的有效工具。
Prefect Orion 简化了机器学习 (ML) 工作流程的编排,可满足优先考虑可靠机器学习自动化的团队的需求。该平台注重可观察性和直观的开发者体验,使机器学习工作流程的监控和调试变得更加简单。
Prefect Orion 通过其基于装饰器的系统将 Python 函数转换为协调的工作流程。通过应用 @flow 和 @task 装饰者,团队可以将其现有的机器学习代码调整为托管工作流程,而无需进行全面重写。其混合设计支持本地开发和可扩展执行环境之间的无缝过渡,从而确保更轻松地进行测试和调试。此外,内置的重试功能和故障处理机制会在出现问题时自动重启任务。这种自动化与更广泛的编排功能无缝集成。
Prefect Orion 的架构将工作流程逻辑与执行分开,从而实现计算资源的独立扩展。工作流程可以在 Kubernetes 集群、Docker 容器或基于云的计算实例等平台上运行。该平台支持跨多个工作人员执行并行任务,并使用工作队列来优化资源分配。这些功能使团队能够高效管理多样且要求苛刻的机器学习工作负载。
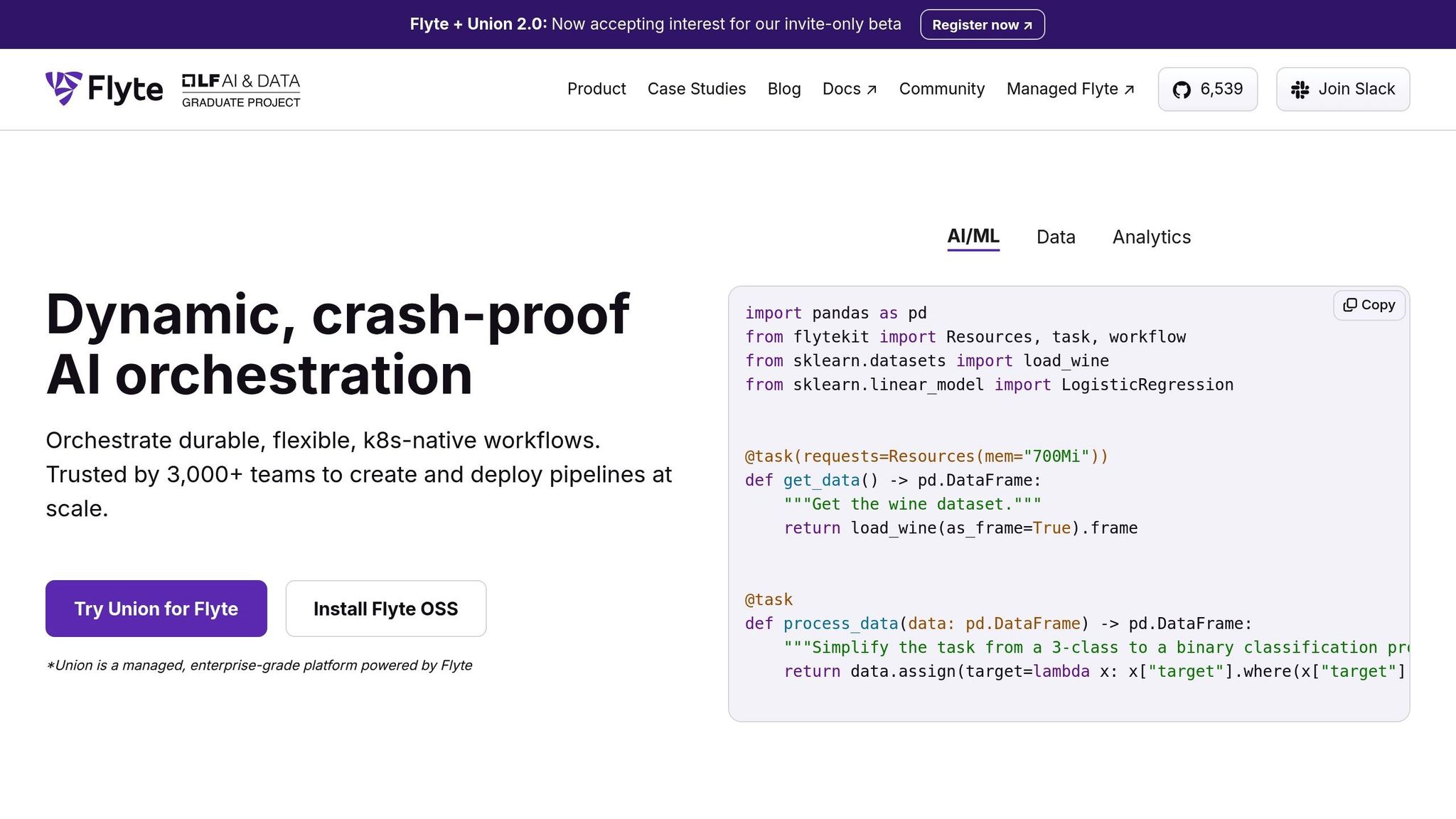
Flyte 通过将 Python 函数转换为类型安全、由装饰器驱动的工作流程来简化机器学习编排。通过编译时验证,可以及早发现错误,隔离的容器执行可确保可靠和一致的结果。
Flyte 使用基于装饰器的方法将 Python 函数转换为工作流程。它会自动跟踪每次执行的数据沿袭情况,从而更容易监控和审核流程。团队可以使用支持条件执行、循环和基于运行时数据的动态任务创建的语法定义复杂的任务依赖关系。
该平台还提供工作流程模板,允许团队创建参数化模板。这些模板可以在不同的配置下重复使用,从而减少了重复的代码,并允许对不同的超参数或数据集进行快速实验。
这些自动化工具可与 Flyte 的扩展功能无缝协作,确保工作流程管理的效率和灵活性。
Flyte 将工作流程定义与其执行分开,从而启用 跨 Kubernetes 集群进行水平扩展。这种设计确保了工作流程的隔离,同时仍允许团队在多租户环境中共享计算资源。
在任务级别,团队可以定义特定的资源需求,例如 CPU、内存或 GPU 需求。Flyte 根据工作负载需求动态配置和扩展这些资源,确保最佳性能。
为了提高成本效益,Flyte 与云提供商整合,使用竞价型实例执行非关键批处理任务。如果竞价型实例中断,其调度程序会自动将任务迁移到按需实例,从而避免中断。
Flyte 支持与 PyTorch、TensorFlow、scikit-learn 和 XGBoost 等流行框架的无缝集成。它还可以使用 Spark 处理大规模任务。
在原型设计和实验方面,Flyte 与 Jupyter 笔记本电脑集成,允许将笔记本电脑单元转换为工作流程任务。此功能弥合了开发和生产之间的差距。
此外,Flyte 的 REST API 可以轻松连接外部系统和 CI/CD 管道。团队可以通过编程方式触发工作流程、监控进度并使用标准 HTTP 接口检索结果,从而提高灵活性和运营效率。
Tecton 是一个功能存储平台,通过可靠地为训练和实时推理提供功能,弥合了数据工程和机器学习之间的差距。通过在不同环境中提供对功能的一致访问权限,从而与其他编排工具互为补充,从而确保机器学习工作流程更加顺畅。
Tecton 使用其基于 Python 的声明式 API 与企业基础架构无缝集成。这允许团队使用熟悉的编码模式定义功能,同时与既定的代码审查和 CI/CD 工作流程保持一致。该平台还支持单元测试和版本控制,使其易于集成到现有的工程管道中。
该平台的 灵活的数据采集选项 可容纳各种数据架构。团队可以从 S3、Glue、Snowflake 和 Redshift 等批量源提取数据,也可以从 Kinesis 和 Kafka 等工具流式传输数据。然后可以通过功能表或低延迟摄取 API 推送数据。
在编排方面,Tecton 提供物化工作和 触发的物化 API,支持与 Airflow、Dagster 或 Prefect 等外部工具集成,以满足自定义日程安排需求。
2025 年 7 月,Tecton 宣布与之建立合作伙伴关系 Modelbit 展示其在现实场景中的互操作性。这种合作使机器学习团队能够建立端到端的管道,Tecton 可以在其中管理动态功能和 Modelbit 处理模型部署和推断。欺诈检测示例突显了这种协同作用:Tecton 提供交易历史和用户行为等功能,而 Modelbit 部署推理管道,将它们组合成一个用于实时欺诈检测的低延迟 API。
接下来,让我们探讨 Tecton 的架构如何扩展以处理要求苛刻的 ML 工作负载。
Tecton 的架构设计可扩展,提供了 灵活的计算框架 它支持 Python(Ray & Arrow)、Spark 和 SQL 引擎。这种灵活性使团队可以根据自己的需求选择正确的工具,无论是简单的转换还是更复杂的功能工程。
该平台的最新版本包含 DuckDB 和 Arrow 以及现有的基于 Spark 和 Snowflake 的系统。这种设置提供了快速的本地开发,同时保持了大规模生产部署所需的可扩展性。
Tecton 可扩展性的影响在现实用例中显而易见。例如, Atlassian 显著缩短了功能开发时间。约书亚·汉森,首席工程师 Atlassian,分享了:
“当我们第一次开始构建自己的功能工作流程时,花了几个月(通常是三个月)将功能从原型投入生产。如今,有了 Tecton,在一天之内构建一个功能是完全可行的。Tecton 在工作流程和效率方面都改变了游戏规则。”
这种可扩展性优势也为 Tecton 有效自动化功能工作流程的能力奠定了基础。
Tecton 可自动执行整个功能生命周期,包括实现、版本控制和世系跟踪,从而最大限度地减少手动工作并提高效率。
一个突出的功能是 Tecton 的 开发者工作流程体验。约瑟夫·麦卡利斯特,高级工程师 coinbase的 ML 平台,指出:
“Tecton 的亮点是功能工程体验——开发人员的工作流程。从一开始,当你在 Tecton 上引入新的数据源和构建功能时,你就是在处理生产数据,这使得快速迭代变得非常容易。”
HelloFresh 这是 Tecton 影响力的又一个例子。机器学习工程高级经理 Benjamin Bertincourt 描述了他们在采用 Tecton 之前面临的挑战:
“在 Tecton 之前,我们的功能是通过单独的 Spark 管道独立生成的。它们不是为共享而构建的,通常不进行编目,而且我们缺乏为实时推理提供功能的能力。”
Tecton 即将与 AI 集成,正在为人工智能的未来做准备 Databricks。该合作伙伴关系于 2025 年 7 月宣布,将把 Tecton 的实时数据服务功能直接嵌入到 Databricks 工作流程和工具。通过将 Tecton 的功能服务与 Databricks'Agent Bricks,团队将能够更有效地构建、部署和扩展个性化的人工智能代理 Databricks 生态系统。
这种集成专门解决了LLM应用程序中对实时功能服务的需求,在这些应用程序中,必须快速获取用户特定的上下文数据,以支持个性化的人工智能交互。它增强了人工智能工作流程的编排,确保了跨平台的无缝集成。
Azure 机器学习提供强大的基于云的平台,旨在管理企业级别的机器学习工作流程。作为微软生态系统的一部分,它与Azure服务无缝集成,同时还支持数据科学团队常用的各种开源工具和框架。
Azure ML 因其与开源技术的广泛兼容性而脱颖而出。它支持数千个 Python 包,包括 TensorFlow、PyTorch 和 scikit-learn 等流行框架,以及 R 支持。该平台通过提供针对这些框架优化的预配置环境和容器来简化环境设置。为了跟踪实验和管理模型,Azure ML 与 MLFlow 集成,提供紧密的体验。开发人员可以灵活地选择工具,无论是 Python SDK、Jupyter 笔记本电脑、R、CLI 还是 Visual Studio Code 的 Azure 机器学习扩展。
在 CI/CD 方面,Azure ML 与 Azure DevOps 和 GitHub Actions 集成,实现了高效的 MLOps 工作流程。此外,Azure 数据工厂可以协调 Azure ML 中的训练和推理管道。对于大规模部署,该平台利用 Azure 容器注册表来管理 Docker 镜像,利用 Azure Kubernetes 服务 (AKS) 进行容器化部署。它还通过与 Horovod 的集成来支持分布式深度学习。
Azure ML 专为轻松扩展而构建,从小型本地项目到企业级部署。它与 Azure Kubernetes 服务 (AKS) 的集成确保了机器学习工作负载可以根据需求动态增长。对于边缘计算场景,Azure ML 与 Azure IoT Edge 配合使用,并使用 ONNX 运行时来优化推理。作为微软Fabric的一部分,它受益于统一的分析平台,该平台汇集了为数据专业人员量身定制的各种工具和服务。这种可扩展性与自动化功能相结合,可以高效管理复杂的机器学习工作流程。
该平台擅长自动化复杂的机器学习工作流程。通过与 Azure 数据工厂集成,它支持任务的自动化,例如训练和推理管道以及数据处理活动。这种自动化确保了数据准备、模型训练和部署阶段的顺畅协调,从而减少了手动工作并提高了效率。
Azure ML 支持通过 Horovod 进行具有分布式训练功能的大型语言模型 (LLM) 训练。它还利用 ONNX Runtime 来优化推理,使其成为对话式 AI 和文本处理等应用的理想之选。
谷歌 Vertex AI Pipelines 为管理机器学习 (ML) 工作流程提供了强大的解决方案,将 Kubeflow Pipelines 的强大功能与谷歌云的高级基础设施相结合。它弥合了实验与生产之间的差距,提供了由谷歌人工智能专业知识支持的无缝体验。
Vertex AI Pipelines 专为在更广泛的 ML 生态系统中轻松运行而构建。它支持流行的编程语言,包括 Python,使团队可以轻松地坚持使用熟悉的工具。此外,它还集成了TensorFlow、PyTorch、XGBoost和scikit-learn等广泛使用的机器学习框架,确保团队能够不受干扰地利用其现有代码和专业知识。
该平台以 Kubeflow 管道为基础,可确保容器化工作流程的顺畅管理。团队可以将机器学习组件打包为 Docker 容器,从而在不同的环境中实现一致的执行。对于那些喜欢基于笔记本的开发的人来说,Vertex AI Pipelines与Jupyter笔记本电脑和Vertex AI Workbench无缝集成,为实验提供了一个熟悉的环境。这种凝聚力的集成为机器学习开发创建了一个可扩展且高效的平台。
Vertex AI Pipelines 由谷歌云的基础设施和谷歌 Kubernetes 引擎 (GKE) 提供支持,旨在轻松处理要求苛刻的机器学习工作负载。它支持跨多个 GPU 和 TPU 的分布式训练,使其成为大规模深度学习项目的绝佳选择。TensorFlow 用户可通过张量处理单元 (TPU) 进一步受益于专业加速。
对于工作负载需求可变的组织,该平台提供抢占式实例,以削减容错任务的成本。它与 Google Cloud 全球网络的集成可确保无论身在何处都能以低延迟的方式访问数据和计算资源。
Vertex AI Pipelines 通过管道即代码功能简化机器学习工作流程。团队可以使用预建的组件在 Python 中定义工作流程,从而实现快速且可重复使用的管道创建。
该平台还集成了Vertex AI功能商店,简化了功能工程和服务。这确保了训练和部署环境之间的一致性,减少了错误并提高了效率。
Vertex AI Pipelines 通过连接 Vertex AI Model Garden 和 PalM API 来支持大型语言模型 (LLM) 的工作流程。这种集成允许团队使用自己的数据微调预训练的语言模型,同时通过自动化管道管理流程。使用 TPU 基础架构支持 LLM 的分布式训练,采用模型和数据并行等技术来克服单个设备上的内存限制。
为了推断,该平台与 Vertex AI Prediction 配合使用,后者提供自动扩展的端点来处理波动的请求负载。批量预测功能可以轻松处理大型文本数据集以执行情感分析或文档分类等任务。
为了帮助团队管理开支,Vertex AI Pipelines集成了谷歌云成本管理工具。这些工具提供有关机器学习支出的详细见解,并允许用户设置预算提醒,从而确保成本的可预测性和可控性。
本节平衡地概述了各种平台的优势和挑战,帮助您根据组织的需求做出明智的决策。此处总结了详细平台审查的关键要点。
Prompts.ai 是企业级 AI 编排的绝佳选择,为超过 35 种领先的大型语言模型 (LLM) 提供了统一接口。其即用即付的TOKN系统可节省高达98%的成本,而实时的FinOps控制和强大的治理可以解决工具蔓延的问题。但是,它对LLM编排的关注可能不适合严重依赖传统机器学习(ML)工作流程的组织,因此非常适合那些将成本效率置于更广泛的机器学习灵活性之上的组织。
带有 ML 扩展的 Apache Airf 广泛用于管理机器学习管道、协调训练作业、部署 AI 模型和处理检索增强生成 (RAG) 工作流程。它的集成涵盖了 GCP、AWS 和 Azure 机器学习服务,由成熟的生态系统和强大的社区提供支持。但是,扩展可能会带来复杂性,其人工智能原生功能依赖于扩展,这可能会增加维护开销。
多米诺数据实验室 擅长为数据科学团队量身定制的 AI/ML 模型的端到端管理。它的优势在于协作和生命周期管理,但这些都带来了高昂的许可成本和复杂程度,可能会使小型团队不堪重负。
DataRobot 人工智能平台 将自动化模型训练与编排相结合,提供治理和偏差检测工具。尽管它简化了机器学习管道,但与开源替代方案相比,其高昂的价格和有限的灵活性可能是缺点。
猎户座省长 是基于 Python 的 AI 堆栈的绝佳选择,可实现机器学习流水线的无缝集成并有效地处理动态工作流程。但是,其较小的生态系统和缺乏企业级功能可能会使其对大型组织的吸引力降低。
Flyte 专为机器学习和数据工作流程而构建,为 TensorFlow 和 PyTorch 等框架提供原生支持。它大规模处理容器化机器学习工作流程,但需要Kubernetes的专业知识,并且在仍在开发的生态系统中运行,这对于刚接触容器编排的团队来说可能具有挑战性。
Tecton 专门从事实时机器学习编排和功能操作,非常适合以功能为中心的工作流程。但是,其狭窄的重点和较高的成本可能不适合小型团队或需要更广泛工作流程能力的项目。
Azure 机器学习编排 为企业级 AI 编排提供强大的套件,与 Azure 生态系统紧密集成,包括数据工厂和 Synapse 等工具。其高级功能,例如微软AutoGen和SynapseML,支持复杂的分布式人工智能工作流程。主要挑战包括供应商锁定和定价复杂性,这可能会使成本预测变得困难。
谷歌 Vertex AI 管道 受益于 Google 的全球基础设施,提供可靠的性能和 TPU 支持。但是,它对谷歌云服务的依赖以及大量使用可能导致的成本增加可能会使一些组织望而却步。
下表重点介绍了每个平台的主要优势和局限性:
选择正确的平台取决于你的 组织的优先事项、技术专长和预算。对于专注于 LLM 编排的注重成本的团队来说, Prompts.ai 是一个有力的竞争者。如果传统 ML 工作流程的灵活性至关重要, 阿帕奇气流 要么 Flyte 可能是更好的选择。已经致力于特定云生态系统的企业团队可能会倾向于 天蓝机器学习 要么 顶点人工智能,尽管有人担心供应商的锁定。
技术专长 是另一个关键因素。像这样的平台 Flyte 需要 Kubernetes 知识,而 猎户座省长 对 Python 开发人员来说更容易访问。对于寻求以最少配置实现自动化的组织, 数据机器人 提供了简化的解决方案,但限制了自定义。
最后, 预算方面的考虑 发挥重要作用。开源平台,例如 阿帕奇气流 可以节省成本,但需要更多的内部资源来进行设置和维护。商业解决方案虽然功能更丰富且受支持,但许可成本也更高。除了前期支出外,还要考虑总拥有成本,包括培训、维护和潜在的供应商依赖关系。
选择正确的机器学习编排平台需要仔细平衡组织的需求、资源和专业知识。以下是我们深入平台评测的关键要点摘要。
Prompts.ai 因其在 LLM 编排和成本管理方面的领导地位而脱颖而出。凭借支持超过35种型号的统一接口及其即用即付的TOKN信用系统,它可节省多达98%的费用,同时减少工具蔓延并保持对敏感应用程序的强大治理。
对于那些寻求更广泛的机器学习工作流程灵活性的用户,Apache Airflow 及其机器学习扩展提供了强大的多云生态系统。但是,其扩展时的复杂性可能需要额外的资源和专业知识。
评估总拥有成本至关重要。尽管像Apache Airflow这样的开源平台的前期成本较低,但它们需要大量的内部资源。另一方面,诸如DataRobot和多米诺数据实验室之类的商业平台提供了广泛的功能,但价格却更高。将平台与团队的技术优势相匹配——例如,Flyte非常适合精通Kubernetes的团队,Prefect Orion适合以Python为中心的群组,而像DataRobot这样的自动化解决方案可以很好地满足最低配置需求。
对于深度集成到特定云环境的组织,Azure ML Orchestration 和 Google Vertex AI Pipelines 等平台可提供无缝兼容性。但是,请注意潜在的供应商锁定和定价挑战。
归根结底,适合贵组织的最佳平台取决于您的独特优先事项——无论是成本效率、工作流程灵活性、企业级功能还是云集成。仔细评估您的用例、团队能力和预算,以做出明智的决定。
在选择机器学习编排平台时,重要的是要关注几个关键方面: 可扩展性, 用户友好度,以及 兼容性 使用您当前的工具。一个好的平台应该简化数据预处理、模型训练、部署和监控等流程,同时还要足够灵活以匹配团队的技术技能。
同样重要的是成本清晰度——实时费用跟踪等功能可以使管理人工智能相关预算的效率大大提高。寻找强调的平台 安全, 合规,以及轻松集成新模型,确保您的工作流程在需求增长时保持流畅和适应性。
Prompts.ai 可大幅降低成本-高达 98% -通过将超过35种大型语言模型整合到一个简化的平台中。这种方法消除了与处理多个工具相关的麻烦和浪费。
该平台还具有集成功能 FinOps 层,它持续实时监控和调整成本。这可确保企业从投资中获得最大价值,同时保持卓越的人工智能性能。
Apache Airflow 和 Kubeflow 等开源平台为协调机器学习工作流程提供了强大的解决方案,但它们并非没有障碍。一个值得注意的问题是性能——用户可能会遇到较慢的执行速度和更高的延迟,这可能会影响整体效率。此外,它们错综复杂的架构会导致依赖关系膨胀,从而延长构建时间和增加复杂性。
另一个挑战在于将这些平台与不同的执行环境集成在一起。这通常需要高水平的专业知识和大量的努力来确保兼容性。高效的资源管理也可能成为痛点,尤其是在扩展工作流程或满足独特的计算要求时。尽管这些平台提供了很大的灵活性,但它们可能并不总是最适合所有场景。


















