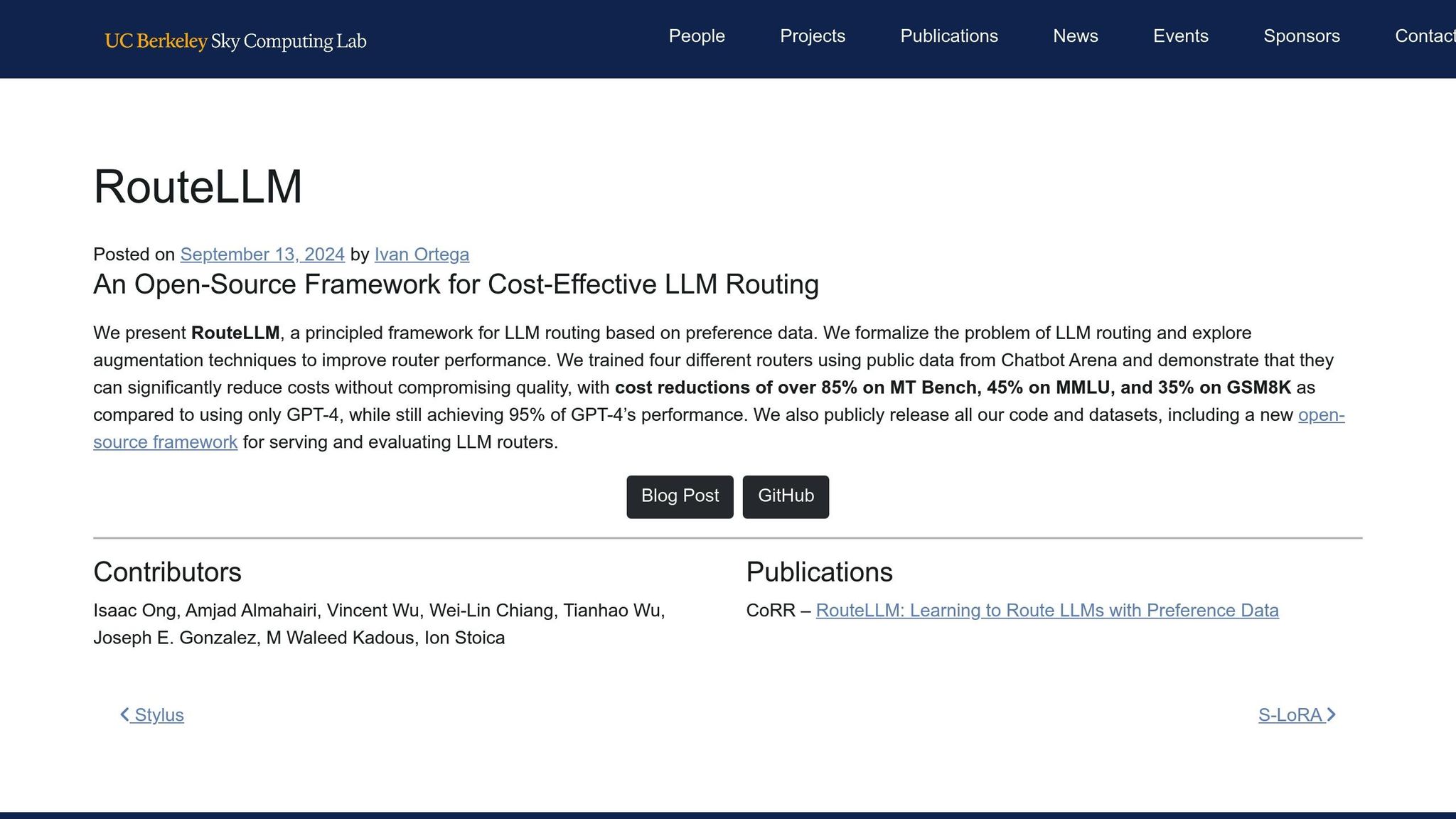
Pay As You GoPrueba gratuita de 7 días; no se requiere tarjeta de crédito


Modelo de enrutamiento para tareas específicas está transformando el funcionamiento de los sistemas de IA. En lugar de confiar en un modelo único para cada tarea, este enfoque asigna las tareas al modelo de IA más adecuado en función de factores como la complejidad, el costo y la precisión requerida. He aquí por qué es importante:
Esta estrategia está remodelando la implementación de la IA al equilibrar el costo y la calidad de manera efectiva, lo que la convierte en una opción inteligente para las organizaciones que amplían sus capacidades de IA.
Para evaluar el éxito del modelo de enrutamiento para tareas específicas, es esencial realizar un seguimiento de las métricas que destaquen tanto el impacto financiero como la calidad del desempeño. Sin una medición adecuada, las organizaciones corren el riesgo de perder oportunidades para optimizar sus estrategias o identificar las áreas que necesitan mejoras.
El costo de generar los tokens puede variar ampliamente. Por ejemplo, el GPT-4 funciona 60 USD por millón de fichas, mientras que Llama-3-70B cuesta aproximadamente 1 dólar por millón de fichas. Con una diferencia de precio tan marcada, las decisiones de enrutamiento desempeñan un papel importante en la gestión eficaz de los presupuestos.
Una métrica clave es el porcentaje de consultas dirigidas a modelos más pequeños y menos costosos. Desviar las tareas a estos modelos rentables puede reducir los costos de inferencia hasta 85%. Algunas implementaciones han reportado reducciones en los costos de las API de 40%, mientras que los sistemas híbridos han conseguido 37— 46% reducciones en el uso junto con una latencia mejorada.
Más allá de los costos de las API, las organizaciones también deben tener en cuenta gastos operativos. Estos incluyen los costos de infraestructura, las herramientas de monitoreo y la sobrecarga de administrar varios modelos. Dado que los costos pueden fluctuar según la forma en que se entrenen e implementen los modelos, monitorear de cerca estas variables es crucial para optimizar la frecuencia y la duración de las llamadas a la API.
El seguimiento de estas métricas financieras sienta las bases para evaluar los resultados cualitativos de las tareas enrutadas.
La evaluación de la calidad en sistemas multimodelo requiere ir más allá de las puntuaciones de precisión estándar. Si bien precisión de la tarea sigue siendo una medida clave, las métricas adicionales, como la relevancia de la respuesta y las puntuaciones de satisfacción de los usuarios, proporcionan una imagen más matizada de la forma en que las decisiones de enrutamiento cumplen con las expectativas de los usuarios.
Métricas que evalúan cualidades subjetivas - como la amabilidad, el humor, el tono y la formalidad - son especialmente importantes en las aplicaciones prácticas. Por ejemplo, los estudios comparativos sugieren que Llama-3 suele resultar más atractivo e interactivo, mientras que GPT-4 y Claude se inclinan por un estilo más formal o basado en la ética. Curiosamente, los datos sobre las preferencias de los usuarios muestran que las respuestas más largas tienden a recibir una mayor aprobación, incluso cuando no necesariamente ofrecen mejores respuestas.
El examen de los patrones de error también puede mejorar la lógica de enrutamiento. Al identificar las entradas o las condiciones que provocan fallas, los equipos pueden refinar sus sistemas para mejorar la confiabilidad. Los métodos de evaluación modernos hacen hincapié en adaptar las evaluaciones de calidad a los contextos de usuario específicos, en lugar de basarse únicamente en puntos de referencia genéricos.
El rendimiento no solo se basa en el costo y la calidad, sino que también depende de la velocidad y la confiabilidad.
Latencia mide el tiempo que lleva procesar un aviso y entregar una respuesta completa. Las evaluaciones eficaces de la latencia tienen en cuenta factores como la complejidad inmediata y la eficiencia de todo el proceso de solicitudes. Comparar la latencia con la de la competencia ayuda a identificar el mejor modelo para una tarea determinada.
Rendimiento, por otro lado, mide la capacidad de procesamiento del sistema, a menudo expresada en fichas por segundo, solicitudes por minuto o consultas por segundo. Si bien la latencia se centra en los tiempos de respuesta individuales, el rendimiento refleja la eficacia con la que el sistema gestiona varias solicitudes simultáneamente. La mejora del rendimiento suele implicar la optimización del hardware, el procesamiento por lotes y una mejor administración de los recursos.
Tasas de error son otra métrica de confiabilidad crítica. Estos capturan problemas como las solicitudes fallidas, los tiempos de espera, los resultados con formato incorrecto y las interrupciones. Estos errores influyen directamente en las decisiones de enrutamiento. Como dijo acertadamente James R. Schlesinger, exsecretario de Defensa de los Estados Unidos:
«La fiabilidad es, después de todo, ingeniería en su forma más práctica».
Plataformas como prompts.ai aborde estos desafíos ofreciendo análisis en tiempo real y seguimiento de la tokenización. Su infraestructura de pago por uso conecta grandes modelos lingüísticos y proporciona información útil sobre las métricas de costos y rendimiento sin sacrificar la calidad.
Cuando se trata de enrutar las tareas entre varios modelos de IA, las organizaciones tienen varias estrategias diferentes entre las que elegir. Cada método tiene su propio conjunto de puntos fuertes y débiles, y la mejor elección a menudo depende de factores como el presupuesto, los objetivos empresariales y el nivel de calidad deseado.
Este método asigna las tareas en función de su complejidad. Las consultas sencillas, como las preguntas básicas del servicio de atención al cliente o las búsquedas sencillas de datos, se gestionan mediante modelos ligeros y rentables. Por otro lado, las tareas más complejas se asignan a modelos avanzados, como el GPT-4 o el Claude 3.5 «Sonnet» de Anthropic. ¿Cuál es el beneficio? Una estructura de costos predecible. Al clasificar las tareas por adelantado, las empresas pueden estimar los gastos con mayor facilidad. Sin embargo, este enfoque puede tener problemas con las consultas que no se ajustan perfectamente a las categorías predefinidas, lo que hace que sea menos adaptable a situaciones inesperadas. Estas limitaciones suelen llevar a las organizaciones a explorar enfoques de enrutamiento más flexibles.
El enrutamiento de consultas híbrido lleva las cosas un paso más allá al combinar reglas deterministas con la toma de decisiones probabilística. En esta configuración, las consultas sencillas siguen reglas claras, mientras que las ambiguas se direccionan mediante decisiones basadas en la probabilidad. Este enfoque dual permite realizar ajustes dinámicos en función de la complejidad de las consultas entrantes.
Las investigaciones muestran que los sistemas híbridos pueden reducir los costos hasta en un 75% y, al mismo tiempo, conservar alrededor del 90% de la calidad que ofrecen los modelos premium. Por ejemplo, una implementación logró reducir entre un 37 y un 46% el uso general del modelo de lenguaje de gran tamaño (LLM), mejoró la latencia entre un 32 y un 38% y redujo los costos de procesamiento de la IA en un 39%. Además, los sistemas híbridos pueden reducir las llamadas a modelos caros como el GPT-4 hasta en un 40%, con una pérdida mínima o nula en la calidad de salida.
marcianoEl cofundador de AI Routing destaca los beneficios de este enfoque:
«La elección automática del modelo correcto consulta por consulta significa que no siempre es necesario utilizar un modelo grande para tareas sencillas, lo que se traduce en un mayor rendimiento general y menores costos al adaptar el modelo al trabajo».
Este método ofrece un equilibrio entre la rentabilidad y la calidad, lo que lo convierte en una opción sólida para las empresas que necesitan flexibilidad sin complicar demasiado sus sistemas.
El enrutamiento dinámico basado en el presupuesto se adapta en tiempo real, teniendo en cuenta los precios, la demanda y los límites presupuestarios. En lugar de basarse en una estrategia fija, este método desvía el tráfico hacia modelos menos costosos a medida que se acercan los umbrales presupuestarios. Por ejemplo, si una empresa establece un límite para el uso de modelos premium durante un mes, el sistema dará prioridad a las alternativas más baratas a medida que el gasto se acerque a ese límite.
Soluciones como Mezcla LLM y OPTLLM ilustre este enfoque en acción. Mezcla LLM ofrece el 97,25% de la calidad del GPT-4 a solo el 24% del costo, mientras que OptLLM logra el 96,39% de la calidad a alrededor del 33% del costo. Si bien este método responde en gran medida a las cambiantes condiciones empresariales, requiere algoritmos avanzados y una supervisión de calidad rigurosa para garantizar unos resultados consistentes.
Plataformas como prompts.ai mejoran esta estrategia al ofrecer análisis en tiempo real y un seguimiento de los tokens de pago por uso, que ayudan a mantener un equilibrio entre el costo y la calidad.
Cada método tiene su lugar. El enrutamiento por niveles es ideal para patrones de consulta predecibles y tareas claramente definidas. El enrutamiento híbrido brilla cuando la flexibilidad es una prioridad, pero la complejidad debe seguir siendo manejable. El enrutamiento dinámico es perfecto para las empresas que se enfrentan a cargas de trabajo fluctuantes y presupuestos estrictos, aunque exige sistemas más sofisticados para mantener la calidad.
La aplicación práctica de estrategias de enrutamiento para tareas específicas resalta su capacidad para reducir los costos de manera significativa y, al mismo tiempo, mantener resultados de alta calidad. Estos ejemplos y datos del mundo real muestran cómo las empresas aprovechan estos sistemas para optimizar tanto los gastos como el rendimiento.
Los números hablan por sí solos en lo que respecta al ahorro de costes. En marzo de 2025, Arcee AIlos sistemas de enrutamiento demostraron impresionantes ganancias de eficiencia en varias aplicaciones. Tomemos, por ejemplo, un equipo de marketing que utiliza Modo automático de Arcee Conductor (Arcee-Blitz) para generar publicaciones en LinkedIn. Redujeron sus costos de envío rápido de 0,003282 dólares a solo 0,00002038 dólares por anuncio, logrando una asombrosa reducción de costos del 99,38%. Esto se traduce en un ahorro de 17,92$ por millón de fichas, lo que equivale a casi 21.504$ al año para un equipo que procesa 100 millones de fichas al mes.
Del mismo modo, un equipo de ingeniería que utiliza SLM Virtuoso-Medium de Arcee AI para las consultas rutinarias de los desarrolladores, se ahorró un 97,4% por mensaje, lo que redujo los costos de 0,007062 USD a 0,00018229 USD. En las aplicaciones financieras, Arcee-Blitz supuso una reducción de costes del 99,67% en las tareas de análisis mensuales y, al mismo tiempo, procesó los datos un 32% más rápido que Claude-3,7-Soneto.
Las pruebas internas de Amazon con Enrutamiento rápido inteligente de Bedrock reveló resultados igualmente impresionantes. Al dirigir el 87% de las solicitudes a las más asequibles Haiku Claude 3.5, lograron un ahorro de costos promedio del 63,6% y, al mismo tiempo, mantuvieron una calidad de respuesta comparable a Claude Sonnet 3.5 V2. Cuando se aplica a los conjuntos de datos de generación aumentada de recuperación (RAG), el sistema preservó de manera consistente la precisión de referencia.
Una empresa de tecnología legal también obtuvo beneficios rápidos después de su implementación Enrutamiento rápido inteligente de AWS Bedrock. En tan solo 60 días, redujeron los costos de procesamiento en un 35% y mejoraron los tiempos de respuesta para tareas ligeras en un 20%. Esto se logró dirigiendo las consultas más sencillas a modelos más pequeños, como Claude Haiku, al tiempo que reserva tareas más complejas para modelos más grandes, como Titán. Estos resultados subrayan cómo el ahorro de costos puede ir de la mano con las mejoras en el rendimiento.
El enrutamiento por tareas específicas no solo ahorra dinero, sino que también mejora la calidad al aprovechar los puntos fuertes de los diferentes modelos. Al asignar las tareas al modelo más adecuado, las organizaciones pueden maximizar la eficiencia sin sacrificar la precisión.
Por ejemplo, los sistemas de enrutamiento híbridos pueden reducir la dependencia de modelos caros como el GPT-4 hasta en un 40%, conservando el 90% de la calidad del GPT-4 y reduciendo los costos hasta en un 75%.
«¿Cuál es el modelo mínimo que puede gestionar bien esta consulta con confianza?» — Cofundador de AI Routing de Martian
Esta filosofía garantiza que cada consulta coincida con los recursos computacionales correctos. Plataformas como Solicitud ejemplifique este enfoque al enrutar las tareas de codificación a un Variante «Sonnet» de Anthropic Claude 3.5, al tiempo que utiliza otros modelos para consultas de uso general. Esto no solo mejora la precisión de la respuesta, sino que también acelera los tiempos de procesamiento.
Otro ejemplo destacado es el uso de enrutadores ponderados por similitud, que ajustan dinámicamente los umbrales para equilibrar el costo y la calidad. Estos sistemas han logrado una mejora del 22% en Brecha de rendimiento promedio recuperada (APGR) mediante enrutamiento aleatorio, lo que reduce las llamadas a modelos caros en un 22%, con solo una caída de calidad del 1%.
La siguiente tabla muestra cómo las diferentes implementaciones de enrutamiento equilibran el costo, la calidad, la velocidad y la complejidad:
Estos ejemplos muestran cómo las organizaciones gestionan tareas rutinarias a gran escala, como el equipo de marketing que utiliza Arcee-Blitz - puede lograr una eliminación de costos casi total para casos de uso específicos.
Los modelos de IA premium son innegablemente caros en comparación con las alternativas más pequeñas. Sin embargo, al usar un router LLM para dirigir las consultas a modelos más pequeños y eficientes, las empresas pueden reducir los costos de procesamiento hasta en un 85% en comparación con confiar únicamente en los modelos más grandes. Estos hallazgos coinciden con los de informes reales, en los que las reducciones de costos oscilan entre el 20 y el 85%, según la combinación de consultas y la complejidad del sistema de enrutamiento [5, 14].
El enrutamiento para tareas específicas proporciona un camino claro para reducir los costos y, al mismo tiempo, mejorar el rendimiento y la experiencia del usuario. Al asignar estratégicamente las consultas entre los modelos, las organizaciones pueden ofrecer respuestas más rápidas, reducir los gastos y mantener una calidad de servicio confiable.
La configuración de un enrutamiento eficaz para tareas específicas requiere una planificación cuidadosa, una supervisión continua y una implementación cuidadosa. El objetivo es crear sistemas que puedan gestionar la evolución de las demandas sin comprometer la rentabilidad ni la calidad.
Las plataformas de IA modernas deben adaptarse a varios modelos sin fricción. Esto es especialmente importante para dirigir diferentes tipos de consultas a modelos especializados. Las plataformas que ofrecen acceso a la API y son compatibles con varios modelos lingüísticos garantizan una integración fluida y flujos de trabajo eficientes para las empresas.
Los flujos de trabajo modulares y escalables son fundamentales a medida que las empresas crecen. Por ejemplo, las plataformas con herramientas de colaboración en equipo han registrado una reducción del 40 al 60% en los errores humanos. Esto demuestra cómo la infraestructura adecuada puede mejorar directamente la eficiencia operativa.
Al seleccionar una plataforma, tenga en cuenta qué tan bien se integra con sus sistemas actuales. Dado que el 83% de las API públicas dependen de la arquitectura REST, elegir soluciones que se ajusten a las prácticas de integración estándar puede ahorrar tiempo y recursos al evitar reconstrucciones extensas.
Un buen ejemplo es Prompts.ai, que ofrece flujos de trabajo interoperables que conectan varios modelos lingüísticos en una sola plataforma. Sus funciones incluyen flujos de trabajo de inteligencia artificial multimodales e integración de bases de datos vectoriales para aplicaciones de generación aumentada (RAG), lo que proporciona la flexibilidad necesaria para las estrategias de enrutamiento avanzadas. Las herramientas de colaboración en tiempo real y los informes automatizados permiten a los equipos ajustar aún más las configuraciones y, al mismo tiempo, supervisar el rendimiento y los costos.
Mantener los costos bajo control comienza con la supervisión en tiempo real del uso, la latencia y los gastos de los tokens. Para las implementaciones de LLM a nivel de producción, es esencial realizar un seguimiento de la actividad en las capas de cliente, puerta de enlace y backend.
Las métricas clave que se deben monitorear incluyen el total de tokens por solicitud, la latencia de respuesta, el costo por solicitud y las tasas de error. Añadir metadatos personalizados, como los identificadores de usuario o los nombres de las funciones, puede proporcionar información aún más detallada. Por ejemplo, una empresa emergente de SaaS redujo sus costos mensuales de LLM en un 73% al analizar las solicitudes ineficientes y optimizarlas con análisis detallados.
Para evitar gastos inesperados, considera la posibilidad de implementar alertas y límites de gastos en tiempo real. Dirigir las tareas no críticas a modelos más rentables y almacenar en caché las respuestas comunes son estrategias adicionales para administrar los costos de manera eficaz.
Prompts.ai simplifica este proceso con el seguimiento de la tokenización integrado en su modelo de pago por uso. Esta función brinda a las empresas una visibilidad detallada de los costos en diferentes modelos y casos de uso. Los informes automatizados garantizan que los equipos se mantengan informados sobre las tendencias de uso y los gastos sin necesidad de realizar un seguimiento manual.
La información en tiempo real sienta las bases para los flujos de trabajo automatizados, que son esenciales para crear sistemas de enrutamiento escalables. Cuando se implementa cuidadosamente, la automatización del flujo de trabajo mediante IA puede aumentar la productividad entre un 30 y un 40%.
Una evaluación exhaustiva de las capacidades actuales es clave para una automatización exitosa. Las organizaciones que evalúan la eficiencia del flujo de trabajo, la calidad de los datos y la preparación de la infraestructura tienen 2,3 veces más probabilidades de cumplir sus objetivos de automatización a tiempo. Un enfoque gradual de la implementación también puede minimizar los riesgos.
Por ejemplo, una empresa mejoró su latencia de P95 2,3 veces al pasar de reglas estáticas a una toma de decisiones automatizada basada en datos de rendimiento en tiempo real.
Para prepararse para el crecimiento futuro, diseñe flujos de trabajo modulares que puedan ampliarse y adopte herramientas de IA capaces de superarse a sí mismas. Dado que el 74% de los usuarios de la IA planean integrarla en todas las aplicaciones empresariales en un plazo de tres años, su sistema de enrutamiento debe estar preparado para adaptarse. Las empresas que utilizan sistemas de control de calidad basados en la inteligencia artificial han registrado una disminución del 20 al 30% en el número de defectos, lo que subraya el valor de la supervisión continua y los ciclos de retroalimentación. Establecer KPI claros ayudará a medir el éxito y el ROI de sus esfuerzos de automatización.
Prompts.ai admite esta escalabilidad con microflujos de trabajo personalizados y funciones de automatización. Sus laboratorios de inteligencia artificial con la herramienta de sincronización en tiempo real permiten a los equipos experimentar con estrategias de enrutamiento e implementar cambios rápidamente, una capacidad esencial a medida que las empresas crecen y sus necesidades evolucionan. Además, funciones como la protección de datos cifrados y la supervisión avanzada garantizan que los sistemas automatizados permanezcan seguros y, al mismo tiempo, se escalen de forma eficaz. Al tratar las solicitudes como un código y supervisar el control de versiones y el rendimiento, los equipos pueden mantener estándares de alta calidad incluso cuando aumentan las complejidades del enrutamiento.
El modelo de enrutamiento para tareas específicas está transformando la forma en que funcionan los sistemas de IA y ofrece una forma más inteligente de equilibrar la calidad y los costos. Los estudios muestran que este enfoque específico se está convirtiendo en un factor clave para mantener la competitividad con las tecnologías de inteligencia artificial.
Las empresas han registrado ahorros sustanciales, que oscilan entre el 40 y el 85%, gracias al enrutamiento inteligente. Por ejemplo, Arcee AI logró una reducción de costos del 64%, mientras IBM La investigación puso de manifiesto una reducción de los gastos de inferencia de hasta un 85%. Pero no se trata solo de reducir los costos. Estas estrategias de enrutamiento están elevando el rendimiento a nuevos niveles.
En comparación con los modelos de uso general, los modelos de tareas específicas destacan constantemente por su precisión, tiempos de respuesta más rápidos y una mejor comprensión del contexto. De hecho, los modelos compactos pueden gestionar tareas más sencillas a un costo casi 200 veces menor.
El futuro de la IA está en la orquestación inteligente. Para seguir siendo competitivas, las empresas deben centrarse en integrar la analítica avanzada y los flujos de trabajo automatizados en sus operaciones. Aquellos que prioricen la supervisión en tiempo real, la toma de decisiones automatizada y los procesos escalables estarán mejor equipados para prosperar en el creciente ecosistema de inteligencia artificial y, al mismo tiempo, mantener la eficiencia de las operaciones.
La evidencia es clara: el modelo de enrutamiento para tareas específicas es la base para crear sistemas de IA que sean adaptables, escalables y capaces de ofrecer un valor constante en un panorama tecnológico en constante cambio.
El enrutamiento de modelos específicos para tareas ayuda a reducir los costos de implementación de la IA al dirigir las tareas de manera inteligente a modelos que son rentables y capaces de cumplir con los requisitos de rendimiento. Este método garantiza que los recursos se utilicen de manera eficiente, lo que reduce los gastos innecesarios.
Al adaptar el modelo correcto a cada tarea, las organizaciones pueden ahorrar hasta un 75% y, al mismo tiempo, ofrecer resultados de alta calidad. Este enfoque permite que los sistemas de inteligencia artificial sigan siendo eficientes sin sacrificar la precisión ni el rendimiento general.
El enrutamiento por niveles funciona mediante la asignación de modelos a categorías específicas de rendimiento o costo, lo que le brinda una forma uniforme de equilibrar la calidad y los gastos. El enrutamiento híbrido combina diferentes estrategias, lo que lo hace más adaptable a diversos requisitos. Mientras tanto, el enrutamiento dinámico se ajusta sobre la marcha y utiliza datos en tiempo real para lograr el mejor equilibrio entre costo y calidad a medida que cambian las condiciones.
Para mantener respuestas de primera categoría en los sistemas de IA multimodelo, las organizaciones deben priorizar métricas como exactitud, pertinencia, y consistencia en varias tareas. La evaluación comparativa periódica y las evaluaciones específicas de las tareas desempeñan un papel fundamental a la hora de evaluar el rendimiento de forma eficaz.
La incorporación de datos etiquetados para la validación y la realización de comprobaciones de calidad rutinarias pueden aumentar la confiabilidad del sistema. Al refinar las estrategias de evaluación y adaptar los modelos a tareas específicas, las empresas pueden lograr un equilibrio efectivo entre el mantenimiento de la calidad y la administración de los costos.


















