Pay As You Go - AI Model Orchestration and Workflows Platform


Speech-to-text (STT) technology transforms spoken words into text with remarkable speed and accuracy, making it a key component in multimodal workflows. By converting audio into text, STT enables businesses to analyze spoken content alongside other data types like images, videos, and documents. This integration enhances productivity, accessibility, and collaboration across industries.
STT drives efficiency in healthcare, retail, customer service, and more by turning unstructured audio into actionable insights. Tools like OpenAI Whisper, Google Cloud Speech-to-Text, and Prompts.ai streamline integration, offering cost savings and enterprise-ready features. With STT, teams can unify diverse data streams, reduce manual tasks, and create seamless workflows for modern operations.

Speech-to-Text Processing Types: Cost Efficiency and Use Cases Comparison
Speech-to-text (STT) technology plays a crucial role in multimodal workflows by enhancing contextual analysis. By converting spoken language into text, STT enables models to generate summaries, identify action items, and update CRM systems. It goes a step further by cross-referencing spoken content with documents, images, and other data sources, offering a more comprehensive decision-making framework.
Modern STT models also excel in handling industry-specific language through domain keyword biasing. For instance, technical terms like "angioplasty" in the medical field are accurately transcribed, avoiding errors in interpretation. Google's Chirp 3 model exemplifies this capability, with its training on 28 billion sentences across more than 100 languages, ensuring improved contextual accuracy across diverse vocabularies.
STT doesn’t just provide context - it delivers real-time transcription that’s immediately actionable. Streaming STT processes audio in tiny chunks (20–100 milliseconds), delivering partial results within 200–300 milliseconds. This speed enables instant searches, automated triggers, or even real-time corrections. Deepgram's Nova-3 model, for example, achieves a median Word Error Rate of just 6.8%, outperforming the 14–18% error rates seen in many cloud-based ASR systems, all while maintaining sub-300 millisecond latency.
The technology also bridges language gaps through its multilingual capabilities. The same models that transcribe English can handle over 100 languages, making simultaneous transcription and translation possible during international meetings or conferences. As Stephen Oladele from Deepgram highlights:
The surest way to stay under the human turn-taking threshold (≈800 ms) is the proven STT → NLP → TTS pipeline.
STT enhances accessibility in ways that go beyond typical meeting scenarios. For example, warehouse staff can update inventory, surgeons can access patient records, and technicians can operate machinery - all without needing to use their hands. Additionally, remote participants benefit from detailed, searchable, and timestamped transcripts, ensuring they stay on the same page as those physically present.
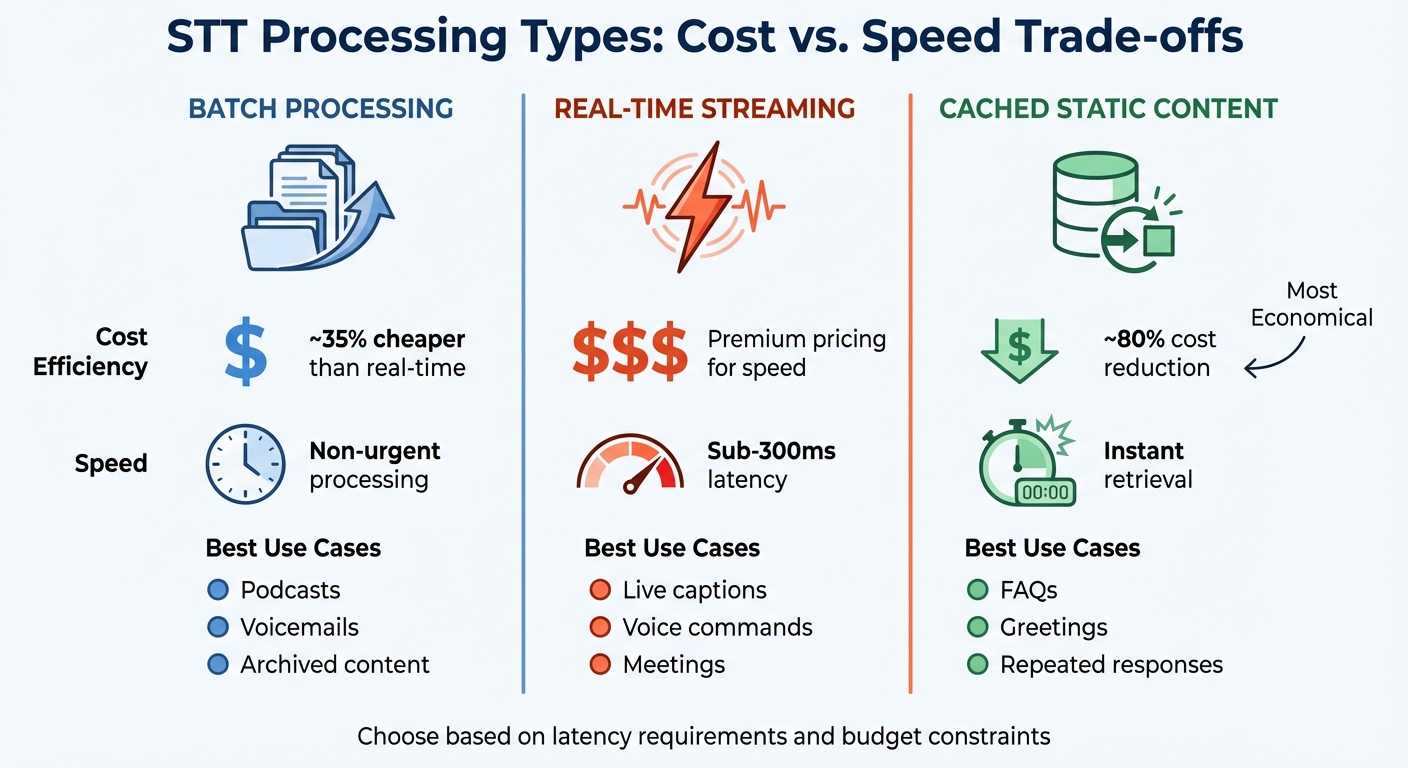
For enterprises managing large volumes of audio data, batch processing offers a cost-effective alternative for non-urgent tasks. It can be approximately 35% cheaper than real-time streaming while still providing accurate transcripts for voicemails, archived interviews, or training sessions.
| Processing Type | Cost Efficiency | Best Use Case |
|---|---|---|
| Batch Processing | ~35% cheaper | Podcasts, voicemails, archived content |
| Real-Time Streaming | Premium for speed | Live captions, voice commands, meetings |
| Cached Static Content | ~80% cost reduction | FAQs, greetings, repeated responses |
When selecting a speech-to-text (STT) tool, your choice depends on specific needs like live transcription, converting archived audio, or supporting multiple languages. OpenAI Whisper is a standout option, offering flexibility and translation capabilities across 98 languages. To ensure quality, only languages with a Word Error Rate below 50% are officially supported. Whisper also adjusts to the style of your prompts, maintaining proper capitalization and punctuation when provided.
Google Cloud Speech-to-Text is designed with enterprise users in mind, offering compliance features and regional data residency options in locations such as Singapore and Belgium. Its pricing starts at approximately $0.016 per minute for multi-region deployments. Additional perks include customer-managed encryption keys and up to $300 in free credits for new users.
Azure Speech Services adds value with advanced features like speaker diarization and word-level timestamp metadata, which are particularly useful for meeting transcriptions and video editing workflows. When assessing STT tools, key considerations include real-time versus batch processing, speaker diarization, and the ability to adapt models using custom prompts to recognize domain-specific terms more accurately .
Most major STT tools support common audio formats like .wav, .mp3, .m4a, .webm, and .flac . However, file uploads often cap at 25 MB, requiring chunking for longer recordings. Leveraging these tools effectively can be further enhanced by integrating them into a unified orchestration platform for streamlined workflows.

Integrating various STT models into a single platform not only simplifies workflows but also improves accuracy and collaboration across different data types. Prompts.ai brings together over 35 leading models - including GPT-5, Claude, LLaMA, and Gemini - within a secure, unified interface. This eliminates the need for juggling multiple API keys, billing accounts, and compliance requirements.
The platform includes real-time FinOps tools that monitor token usage, providing clear insights into the cost-efficiency of each STT model. For large-scale, straightforward tasks, you can optimize costs by routing transcription through smaller, specialized models. For sensitive or regulated workloads, Prompts.ai ensures compliance by orchestrating tools with features like data residency and customer-managed encryption keys.
Prompts.ai also enhances transcription quality through built-in prompting techniques. For instance, it ensures accurate recognition of uncommon terms and technical acronyms, such as "DALL·E". The platform supports automated diarization and speaker-aware models, delivering detailed metadata for meeting recordings, so you can easily track who said what and when. By unifying model selection and prompt workflows, Prompts.ai transforms one-off experiments into consistent, compliant processes - reducing AI costs by up to 98% while maintaining enterprise-level security and reliability.
Getting audio data ready for transcription is crucial. Ensure audio is captured at 16,000 Hz (or 24,000 Hz for 16-bit PCM if required). Convert multi-channel recordings to mono and save files in standard formats like MP3, FLAC, or WAV for smooth processing .
For real-time WebSocket streaming, raw PCM (pcm16), G.711 (u-law/a-law), or Opus formats are typically required . If your audio files exceed 25 MB, break them into smaller chunks before transmission. For low-latency real-time workflows, stream audio in 128 ms to 256 ms increments .
Avoid resampling audio from lower-quality sources. For example, converting 8,000 Hz audio to 16,000 Hz can introduce artifacts, reducing transcription accuracy.
Use Voice Activity Detection (VAD) to filter out background noise and detect when a speaker has finished talking. This minimizes errors and prevents processing silence or ambient sounds, saving resources . For headerless audio files, always define metadata like encoding, sample rate, and language code (e.g., "en-US" using BCP-47 identifiers) to ensure proper API decoding.
Once your audio is optimized, the next step is to integrate these tools into your multimodal pipeline.
After preparing the audio, connect your STT tools to the multimodal pipeline. A common setup involves an STT → LLM → TTS cascade to keep latency low. Depending on your needs, you can choose from three connection methods:
Advanced models like Gemini 2.0 can handle audio directly as part of a multimodal prompt, performing transcription, analysis, and reasoning in a single operation. Gemini 2.0 Flash supports up to 1 million input tokens and can process up to 8.4 hours of audio in one go. To ensure compatibility with enterprise systems, configure outputs to return data in structured JSON formats .
Latency plays a key role in conversational applications. The human turn-taking threshold is around 800 ms - exceeding this can lead to users abandoning interactions.
"The surest way to stay under the human turn-taking threshold (≈800 ms) is the proven STT → NLP → TTS pipeline." - Stephen Oladele, Deepgram
For real-time workflows, use micro-batching, streaming LLM tokens every 180 characters to speed up subsequent processing. Always prioritize security by redacting or hashing Personally Identifiable Information (PII) before sending transcripts to LLMs for further analysis or reasoning.
Once the tools are connected, the focus shifts to scaling and automating workflows for enterprise-level performance.
To maintain efficiency as your workload grows, scale and automate your STT workflows. Design your system as a stateless microservice and containerize applications using tools like Docker. Deploy on platforms such as Cloud Run, ECS Fargate, or Kubernetes, using Horizontal Pod Autoscalers to manage fluctuating request volumes. Monitor key metrics like 95th-percentile latency, Time-to-First-Byte (TTFB), and Word Error Rate (WER) with tools like Prometheus and Grafana.
For resilience, implement exponential back-off to handle socket drops and fallback mechanisms like "interim" transcripts for delayed results. Use simple acknowledgments (e.g., "Sure!") during processing lags to keep conversations fluid.
Platforms like Prompts.ai simplify orchestration with real-time FinOps tools. These tools monitor token usage across STT models, allowing you to route basic transcription tasks to smaller, more cost-effective models. For bandwidth efficiency, opt for Opus encoding over PCM for WebSocket streams, reducing bandwidth needs by up to 4x.
Security is paramount at scale. Rotate API keys weekly using CI secret stores, and enforce consistent data residency and encryption policies through Prompts.ai's unified interface. By centralizing model selection, workflows, and cost controls, Prompts.ai turns experimental setups into reliable, repeatable processes - cutting AI costs by up to 98% while maintaining enterprise-grade security.
A top-tier medical transcription platform implemented Deepgram's Nova-3 Medical model on AWS to ease the documentation workload for clinicians. This solution achieved a 30% reduction in word error rates and lowered processing costs from 7.4¢ to less than 0.5¢ per minute. It supports real-time note-taking through guided prompts or ambient scribe features, seamlessly updating Electronic Health Records (EHR). With its medical-grade speech-to-text (STT) capabilities, the system accurately differentiates between similar-sounding medications and ensures precise dosage details, enabling the creation of well-structured prescriptions.
"In the healthcare industry, administrative burden has become one of the most pressing challenges facing clinicians today. From clinical documentation to order entry and scheduling, manual workflows slow down care, increase costs, and contribute to burnout." - Zach Frantz, Deepgram
These advancements in healthcare settings highlight the potential for similar efficiency gains across other industries.
In retail, speech-to-text technology is reshaping customer interactions by enhancing engagement and uncovering insights. Voice-activated search is becoming a game-changer for e-commerce platforms, particularly on mobile and smart devices, ensuring smooth and intuitive customer experiences. Retailers utilize keyword biasing to improve recognition of product names and brand-specific terms. Once voice data is transcribed, it can be analyzed by large language models to identify customer sentiment, intent, and trends, helping businesses address pain points and spotlight popular products. With support for over 125 languages and dialects, these systems also deliver personalized, localized experiences for global audiences.
"Voice users now expect sub-second back-and-forth. Miss that mark, and they tap the screen instead." - Stephen Oladele, Deepgram
Speech-to-text technology is also revolutionizing customer service, enabling instant, multimodal support. By combining STT with text and video analytics, customer service teams create unified, seamless support systems. Using an STT → NLP → TTS pipeline, these solutions maintain conversational flows that feel nearly instantaneous. Chatbots equipped with STT capabilities can process data from multiple sources - like documents, audio, and video - offering concise summaries with accurate source references. Features like activity detection trigger agent workflows immediately after a customer speaks, while lifecycle event detection (e.g., "turn_started" and "turn_ended") ensures smooth microphone management during interruptions. For call transcripts, speaker diarization preserves the sequence of conversations, improving the accuracy of analysis and decision-making.
Speech-to-text (STT) technology has become a powerful tool for enterprises, enabling teams to transform unstructured audio into searchable, actionable data. This capability allows organizations to automate documentation, extract real-time insights, and maintain natural conversational flows - staying within the human turn-taking threshold of around 800 milliseconds. Its applications span a wide range of industries, proving its versatility and impact.
"STT now reliably handles mission-critical tasks." - Kelsey Foster, Growth, AssemblyAI
This evolution is reshaping how businesses integrate STT into their workflows, making it a cornerstone of modern operations.
To fully leverage STT, enterprises need seamless orchestration of real-time models. Advanced platforms simplify this process by offering pre-built pipelines that combine STT with large language models (LLMs) and text-to-speech systems. These solutions eliminate the need for complex microservice development, enabling businesses to deploy advanced voice workflows efficiently.
Prompts.ai takes this orchestration to the next level by integrating over 35 leading AI models into one secure platform. With built-in FinOps tools and governance controls, teams can connect STT with multimodal models, monitor latency, and cut AI costs by up to 98%, all while maintaining enterprise-grade security and compliance. This unified system eliminates tool sprawl, turning scattered experiments into structured, auditable workflows. It creates a foundation for scalable, repeatable innovation across multimodal processes.
As speech language models evolve to combine audio processing with richer contextual understanding, organizations that adopt scalable orchestration platforms today will be better positioned to achieve measurable productivity gains and drive innovation. By using unified platforms, businesses can transform conversations into actionable insights and gain a competitive edge through multimodal workflows.
Speech-to-text technology converts spoken words into text instantly, simplifying tasks such as generating live captions, taking meeting notes, or executing hands-free commands. By removing the need for manual transcription, it creates a smooth integration of audio, video, and text into a unified workflow.
This functionality speeds up collaboration and decision-making while improving accessibility. It frees up teams to concentrate on more important tasks, reducing time spent on repetitive, manual efforts.
Real-time speech-to-text (STT) technology instantly transforms spoken words into text, enabling live captions, voice commands, and on-the-spot transcription during conversations. Its low-latency performance eliminates delays, making it a game-changer across numerous fields.
In healthcare, clinicians can effortlessly document patient notes or record telemedicine sessions without breaking their focus. Finance professionals benefit from instant transcription of trading floor discussions and compliance-related calls. Education platforms improve accessibility by providing live captions for lectures and webinars. In media and entertainment, real-time STT powers live subtitles for broadcasts, while customer support teams use it to assist agents with AI-driven insights during calls.
When paired with platforms like Prompts.ai, real-time STT integrates seamlessly into multimodal workflows. By combining it with advanced AI tools such as large language models and analytics, organizations can optimize processes, ensure compliance, and securely handle sensitive information, boosting efficiency and advancing capabilities across industries.
Speech-to-text (STT) technology transforms spoken words into written text in real time, making conversations and information more accessible. For employees who are deaf or hard of hearing, live captions during video calls and webinars ensure they can fully participate without needing separate note-takers or waiting for post-meeting summaries. It also benefits non-native speakers and individuals who prefer reading by offering clear, searchable transcripts.
In team settings, STT serves as a connector, capturing spoken ideas and instantly sharing them across platforms. This minimizes misunderstandings, keeps remote teams on the same page, and accelerates decision-making. When integrated into workflows, STT can automate tasks like taking notes, generating action items, or even triggering specific processes. Platforms like prompts.ai make it easy to deploy these tools, combining STT with advanced AI models to boost productivity while ensuring governance and cost control.