Pay As You Go - AI Model Orchestration and Workflows Platform


Machine learning powers many tools you use every day, from personalized recommendations to fraud detection. It enables computers to learn from data and improve over time without explicit programming for every task. Here's a quick breakdown:
Machine learning simplifies complex tasks, making predictions faster and more accurate. Whether you're analyzing data or building predictive models, understanding these basics is a great starting point.
Machine learning can be divided into three primary categories, each with its own way of learning from data. Picture these as distinct teaching styles: one relies on clear instructions and examples, another encourages independent discovery, and the third learns through trial and error with feedback. Grasping these approaches is crucial before diving into the specific algorithms that bring them to life.
Supervised learning is akin to a classroom setting where a teacher provides examples paired with correct answers. The system learns from labeled data - datasets where each input is paired with the correct output. Imagine showing a child pictures of animals labeled as "dog" or "cat" to teach them to recognize the difference.
"Analogous learning allows you to associate real-world analogies with complex concepts that help you to stay curious and think creatively." - Kanwal Mehreen, Aspiring Software Developer
Think of it like cooking with a recipe. The recipe acts as the training data, the ingredients are the input features, and the finished dish is the output or label you aim to replicate. Over time, with enough practice, you might learn to prepare similar dishes without needing the recipe at all.
Practical uses of supervised learning include email spam detection, where systems are trained on thousands of emails labeled as "spam" or "not spam" to identify patterns that flag unwanted messages. Similarly, financial institutions use it to predict loan approvals by analyzing historical customer data paired with past loan outcomes.
Unsupervised learning takes a more exploratory approach. Imagine walking into a bookstore for the first time and sorting books into groups based on their similarities - placing mystery novels together, cookbooks on another shelf, and children's books in their own section - without any predefined labels. This method uncovers hidden structures in data.
"The purpose of unsupervised learning is not to recognize or know the label but to understand the structure and relationship with other objects or dataset." - Sarah Nzeshi, Full-Stack Developer
A popular application is customer segmentation. Retailers analyze purchasing habits, website activity, and demographic data to naturally group customers into categories like bargain hunters, premium shoppers, or seasonal buyers. Similarly, recommendation systems use this technique to identify patterns in purchase behavior, generating suggestions like "customers who bought this also bought..." - all without relying on explicit labels.
Reinforcement learning mimics how we learn many skills - by trying, failing, and gradually improving. Instead of relying on examples, the system learns by taking actions and receiving feedback in the form of rewards or penalties.
"Reinforcement learning does not follow pattern recognition or pattern discovery as the other classification of machine learning do but instead it is about trial and error learning." - Sarah Nzeshi, Full-Stack Developer
Think about learning to ride a bike. You don’t start by reading a manual or analyzing every possible scenario - you get on, wobble, fall, and eventually learn to balance through repeated attempts. One example is AWS DeepRacer, a small-scale race car that learns to navigate tracks by receiving rewards for staying on course, maintaining speed, and completing laps efficiently. Another famous case is AlphaGo, developed by DeepMind, which defeated a world champion Go player by refining its strategies through countless trial-and-error games. In gaming, similar methods teach computers to play chess by rewarding them for capturing pieces, defending their own, and ultimately winning matches.
These three approaches - learning from labeled data, uncovering hidden patterns, and improving through feedback - lay the foundation for the algorithms explored in the next section.
Building on the foundational learning types, let's dive into the specific algorithms that bring these concepts to life. Think of these algorithms as the engines driving machine learning - each tailored for unique tasks and data types. By understanding their mechanics, you'll not only be better equipped to explain machine learning but also to determine which algorithm suits a particular problem.
Linear regression is like finding the best-fitting line through a scatter plot of data points. For example, imagine trying to predict house prices based on square footage. You'd plot the data, with size on one axis and price on the other, and draw a line that best represents the trend.
This algorithm fits a line defined by the equation:
y = β₀ + β₁x₁ + … + βᵣxₒ + ε
Here, the coefficients (β) are calculated to minimize the sum of squared errors between the predicted and actual values.
Linear regression can be simple, using just one variable (e.g., predicting salary based on years of experience), or multiple, incorporating several factors like square footage, number of bedrooms, and location. For more complex relationships, polynomial regression adds terms like x² to capture curves in the data.
Using libraries like Python's scikit-learn, you can implement linear regression by preparing your data, training the model, evaluating it (e.g., using R² to measure accuracy), and making predictions. This approach is ideal for tasks like forecasting sales, estimating costs, or predicting any numerical outcome based on measurable factors.
Decision trees mimic human decision-making by asking a series of yes-or-no questions. Imagine a flowchart guiding your decision to go outside: "Is it raining? If yes, stay inside. If no, is it above 60°F? If yes, go for a walk. If no, bring a jacket."
The algorithm starts with a root node representing the entire dataset. It systematically selects the best questions (or "splits") to divide the data into more uniform groups. Metrics like Gini Impurity or Information Gain determine which features create the most meaningful splits.
The process continues recursively, creating branches until a stopping condition is met - such as reaching a maximum depth or when the remaining data points are sufficiently similar. The leaf nodes at the ends of the branches contain the predictions, which could be class labels (e.g., "approved" or "denied" for a loan) or numerical values for regression tasks.
One of the standout features of decision trees is their transparency. You can easily trace the path of decisions leading to a prediction, making them highly interpretable.
K-means clustering is an unsupervised learning algorithm that identifies natural groupings in data without predefined labels. It works by grouping data points into clusters based on their similarity.
The algorithm starts by randomly placing k centroids (representing the number of clusters you want). Each data point is assigned to the nearest centroid, and the centroids are recalculated as the mean of their assigned points. This process repeats until the assignments stabilize.
K-means is especially useful for applications like customer segmentation, where businesses group customers based on purchasing behavior, or content recommendations, where streaming platforms cluster users with similar viewing habits. The success of k-means depends on choosing the right number of clusters and scaling the data properly.
Understanding machine learning algorithms is just the starting point. The real magic happens when these algorithms are applied in structured projects, turning raw data into actionable business solutions. Machine learning projects follow a systematic, step-by-step process that ensures success.
The foundation of any machine learning project is high-quality data. Without it, even the most advanced algorithms can falter. This makes data collection and preparation a critical first step.
The process begins by identifying relevant data sources. For instance, building a recommendation system might require user behavior logs, purchase history, product ratings, and demographic details. Data often comes from a mix of sources like databases, APIs, web scraping, sensors, or third-party providers.
Raw data is rarely perfect. It's messy, incomplete, and inconsistent, often containing missing values, duplicate entries, outliers, and mismatched formats. Cleaning this data is essential to ensure reliability.
The preparation phase involves several important tasks. Normalization adjusts features on different scales - like comparing house prices in dollars to square footage in feet - so no single feature dominates the model. Feature engineering creates new variables from existing ones, such as calculating a customer’s average purchase value from their transaction history. Data validation ensures accuracy and completeness, while splitting the data into training, validation, and test sets sets the stage for modeling.
Quality control is non-negotiable here. Teams establish rules for data integrity, implement automated checks, and document everything for future use. After all, it’s true what they say: “garbage in, garbage out.”
Once the data is clean and ready, the next step is training and testing the model.
With the data prepared, the focus shifts to training the model - a phase where algorithms learn patterns from historical data.
During training, the algorithm is fed labeled examples to uncover relationships between inputs and desired outputs. For example, in a spam detection system, the algorithm analyzes thousands of emails labeled as "spam" or "not spam", learning to identify patterns like suspicious keywords, sender details, or unusual message structures.
Data scientists experiment with different algorithms, tweak hyperparameters, and refine feature selections. They might find that a decision tree works better than linear regression for a particular problem or that adding a specific feature significantly boosts accuracy.
Validation happens alongside training. A separate validation dataset - data the model hasn’t seen - helps evaluate performance and prevents overfitting, where the model becomes too tailored to the training data and struggles with new examples.
Testing is the final checkpoint. Using entirely unseen data, this phase assesses how the model performs in real-world scenarios. Metrics like accuracy, precision, recall, and F1-score are common for classification tasks, while regression problems often rely on measures like mean squared error or R-squared.
Cross-validation adds another layer of reliability by testing the model across multiple data splits, ensuring consistent performance regardless of the training data used.
Once the model passes these evaluations, it’s ready for deployment and real-world application.
Deploying a model involves integrating it into business systems with infrastructure designed to handle expected workloads. This could mean embedding a recommendation engine into an e-commerce site, linking a fraud detection model to payment systems, or implementing predictive maintenance tools in manufacturing.
The deployment setup depends on the use case. For example, batch processing works well for tasks like monthly customer segmentation, where immediate results aren’t required. On the other hand, real-time processing is essential for applications like credit card fraud detection, where decisions must be made in milliseconds.
Monitoring begins as soon as the model is live. Teams track metrics such as prediction accuracy, system response times, and resource usage. Data drift monitoring is crucial - it identifies when incoming data starts to differ from the training data, which can degrade the model’s performance over time.
Maintaining the model is an ongoing effort. As customer behavior shifts or market conditions evolve, teams may need to retrain the model, update features, or even rebuild it entirely if performance drops below acceptable levels.
Version control plays a key role here. Teams often manage multiple model versions, roll out updates gradually, and keep rollback plans ready in case of issues. A/B testing can also be used to compare the new model against the current one with real user traffic.
This phase turns theoretical models into practical tools, ensuring they deliver real-world results. Production data feeds back into the system, offering insights for future improvements. User feedback can reveal blind spots, and business metrics measure the model’s impact. This creates a continuous improvement loop, ensuring machine learning projects remain valuable over time.
To succeed, teams must view machine learning projects not as one-off tasks but as ongoing initiatives. The best results come from embracing this iterative process, refining models based on real-world feedback and evolving business goals.
Machine learning has become a cornerstone of modern life, influencing everything from personalized streaming recommendations to real-time fraud prevention. Beyond its everyday presence, it serves as a powerful tool for businesses, enabling innovation and improving operational efficiency.
Machine learning is reshaping industries by revolutionizing traditional workflows:
To simplify these varied applications, unified platforms can bring together machine learning processes, making them easier to manage and more efficient.
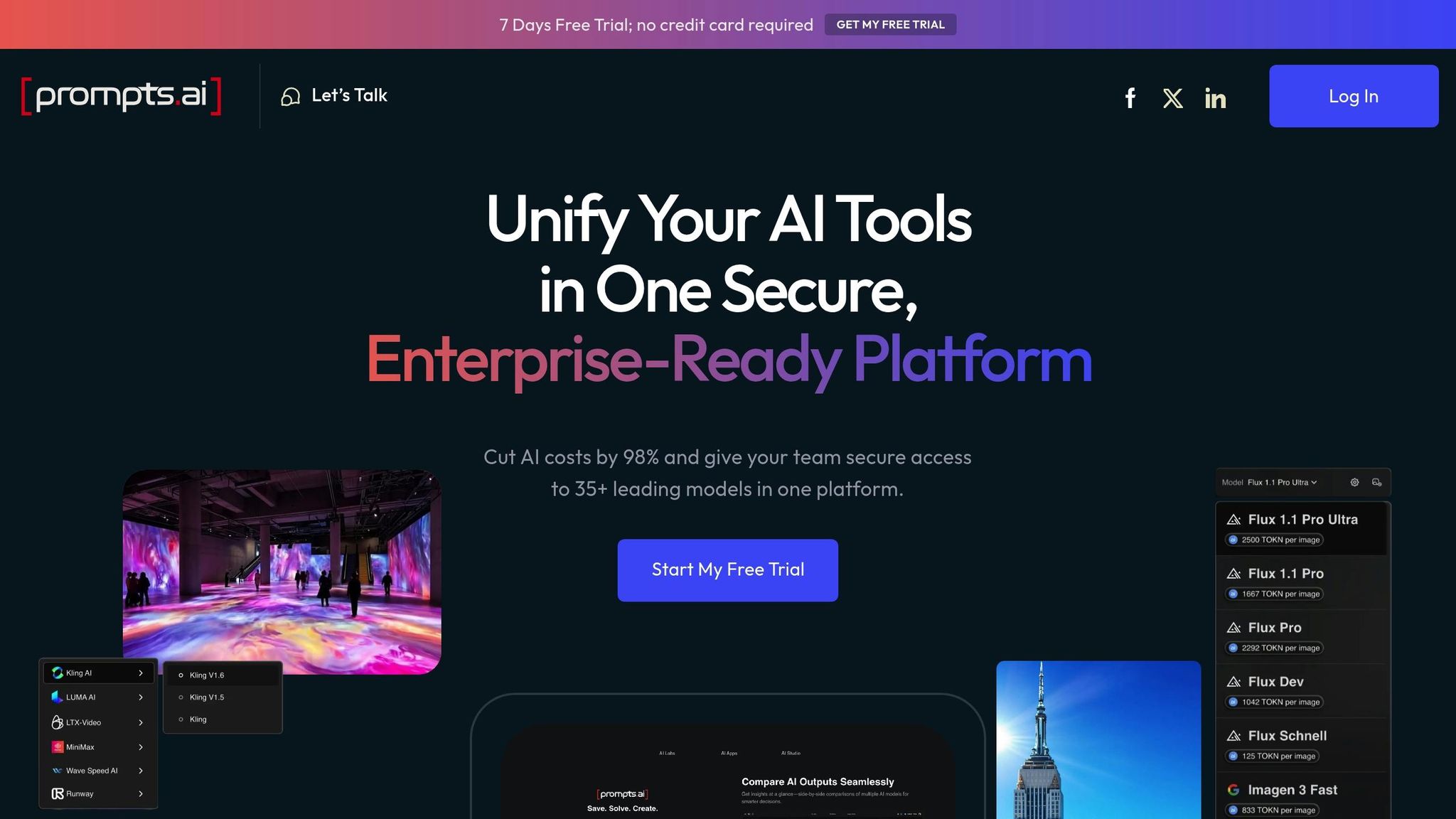
Centralizing machine learning tools within a single platform can significantly improve cost management and operational control. Often, businesses struggle with fragmented systems, inconsistent oversight, and escalating expenses when implementing AI solutions. Prompts.ai addresses these challenges by uniting over 35 leading large language models - including GPT-4, Claude, LLaMA, and Gemini - into one secure, streamlined interface.
By offering centralized access to these AI models, Prompts.ai simplifies operations, ensures consistent governance, and keeps costs in check. The platform’s built-in FinOps tools provide detailed insights into AI spending, helping teams monitor and optimize their budgets. Features like standardized prompt workflows and "Time Savers" offer pre-designed best practices, enabling faster adoption and boosting productivity.
In addition to its technical advantages, Prompts.ai nurtures a collaborative community where prompt engineers can exchange knowledge, earn certifications, and explore real-world use cases. This blend of cost management, governance, and shared expertise transforms experimental AI efforts into scalable, repeatable processes, paving the way for sustainable growth and innovation across businesses.
Machine learning, at its core, is a tool accessible to anyone, not just experts. The ideas we've covered - like supervised and unsupervised learning, decision trees, and linear regression - serve as the building blocks for technologies reshaping industries and everyday life.
Every machine learning project follows a structured process, from collecting data to deploying the final model. Whether you're identifying fraudulent transactions, tailoring shopping experiences, or streamlining supply chains, the same principles apply. At its heart, machine learning is about uncovering patterns in data and using those insights to make smarter predictions or decisions.
The ability of machine learning to scale and automate complex tasks makes it indispensable. A 2020 Deloitte survey found that 67% of companies already use machine learning. This growing adoption highlights its power to solve challenges that would be unmanageable manually, all while improving over time as more data becomes available.
Three key elements - representation, evaluation, and optimization - serve as a roadmap for any machine learning project. These pillars guide the process, from preparing data to fine-tuning performance, ensuring that the solutions created are both effective and reliable.
Ultimately, success in machine learning isn’t about mastering intricate algorithms but about understanding your data and defining clear goals. Start with straightforward questions, collect high-quality data, and opt for the simplest solution that meets your needs. From there, you can gradually expand your skills to tackle more advanced challenges as they arise.
With these concepts broken down, machine learning becomes less daunting and far more approachable, empowering you to explore its possibilities with confidence.
Machine learning is reshaping industries by streamlining processes and boosting efficiency. In healthcare, it plays a key role in early disease detection and crafting personalized treatment plans, enhancing the overall quality of patient care. In the finance sector, machine learning helps identify fraudulent transactions and refine investment strategies, ensuring better security and profitability. Retailers leverage it to deliver tailored product recommendations and manage inventory more effectively. Meanwhile, transportation companies use it to optimize routes and advance autonomous vehicle technologies.
These applications highlight how machine learning tackles practical challenges and sparks innovation across diverse fields, proving its importance in today’s economy.
Choosing the right machine learning algorithm requires a clear understanding of your project’s needs. Begin by pinpointing the type of problem at hand - whether it involves classification, regression, clustering, or another category. From there, take stock of your dataset’s size and quality, the computational power at your disposal, and the level of precision your task demands.
Testing several algorithms on your data can provide valuable insights. Comparing their performance allows you to weigh factors like training time, model complexity, and how easily the results can be interpreted. Ultimately, a mix of experimentation and thorough evaluation will guide you toward the best solution for your specific goals.
To effectively deploy and manage a machine learning model in a business environment, begin by choosing the right infrastructure and conducting thorough testing to confirm the model meets performance benchmarks. Pay close attention to critical metrics like accuracy, latency, and data drift to evaluate how well the model performs over time.
Establish continuous monitoring systems to quickly identify and address any issues, and schedule periodic reviews to uncover potential biases or performance declines. Leverage tools such as automated alerts, version control systems, and MLOps frameworks to ensure the model remains reliable and scalable. Following these practices helps maintain consistent performance and ensures the model provides lasting value in practical use cases.


















