Pay As You Go - AI Model Orchestration and Workflows Platform


Generative AI pricing in 2026 focuses on balancing cost, scalability, and transparency as global AI spending surpasses $2.022 trillion. With GPU compute costs and enterprise software expenses rising, businesses are adopting smarter pricing strategies to optimize ROI. Here’s what you need to know:
Platforms like prompts.ai and Platform B showcase how businesses are cutting costs by routing tasks to cost-efficient models, using prompt caching, and leveraging batch processing discounts. For instance, Skywork.ai reduced AI expenses by 66% using tailored workflows.
The key to success lies in choosing a pricing model that aligns with your usage patterns and growth goals while leveraging tools like prompt caching and LLM routers to cut unnecessary expenses.
Generative AI platforms typically rely on four pricing models, each designed to balance scalability and cost management. Here's a closer look at how these models align costs with different usage needs.
Pay-As-You-Go (PAYG) pricing charges based on specific usage metrics like tokens for text, API calls, GPU compute hours, or outputs such as images or audio minutes. This model appeals to developers and small businesses due to its low upfront costs. For instance, OpenAI's GPT-5.2 charges $1.75 per million input tokens and $14.00 per million output tokens under its standard tier. However, users may face revenue fluctuations and unexpected high bills, making budgeting a challenge.
Subscription-based pricing involves paying a fixed recurring fee, often structured into tiers like Basic, Pro, and Enterprise. This model simplifies budgeting, a feature that financial teams appreciate. However, it can lead to inefficiencies when heavy users consume far more resources than lighter users, creating an imbalance in cost versus usage.
Hybrid models combine a fixed subscription fee with a set usage quota and add metered charges for exceeding that quota. By 2023, 41% of enterprise SaaS companies had adopted this approach. This model offers predictable baseline revenue while allowing flexibility to handle spikes in usage during busy periods.
Outcome-based (performance) pricing is a newer approach where customers pay for specific, measurable results rather than raw computational inputs. For example, a platform might charge $0.70 per fully resolved customer support ticket or take 10% of the additional revenue generated. Gartner predicted that by 2025, over 30% of enterprise SaaS solutions would incorporate elements of this model. While it directly ties costs to return on investment, its complexity and unpredictability can make it harder to implement and manage revenue streams effectively.
In line with the push for cost efficiency and scalability in generative AI by 2026, prompts.ai's pricing strategy highlights how tailored models can help businesses achieve a better return on investment.
Prompts.ai combines fixed monthly subscriptions with a credit-based system, offering flexibility for both individuals and businesses. Personal plans include Pay As You Go ($0/month with 30 credits), Creator ($29/month), and Family Plan ($99/month). For businesses, tiers range from Core ($99 per member/month) to Elite ($129 per member/month). This allows solo developers to start with minimal financial risk while enterprises benefit from advanced governance features. Credits are tied directly to usage, eliminating the need to navigate complicated API metrics. This approach makes it easier to control costs while meeting diverse needs.
Prompts.ai provides access to over 30 AI models under a single subscription. Credit usage varies based on computational requirements: GPT-5 Nano uses about 6.25 credits for 5,000 characters, while the full GPT-5 requires 31.25 credits for the same input. For image generation, HiDream-I1 Fast consumes roughly 1.25 credits per image, compared to Imagen 4.0 Ultra, which uses 37.50 credits per image.
One real-world example comes from Skywork.ai, which cut its monthly AI expenses by 66% - from $3,200 to $1,100 - by strategically assigning tasks: classification went to Nano models, content creation to Mini versions, and standard models were reserved for complex reasoning tasks (Source: AI Pricing Master, 2026).
"The organizations winning in 2026 aren't just choosing cheaper models - they're optimizing the entire AI workflow." - AI Pricing Master
This strategy not only reduces costs but also ensures better allocation of resources.
Prompts.ai is designed to scale effortlessly with user needs. The Free plan limits file uploads to 25MB per day, while the Pro plan increases this to 1GB per day, accommodating larger workflows. The platform’s routing system assigns simpler tasks to cost-effective options like GPT-5 Nano, reserving high-performance models for more demanding tasks. Teams can also take advantage of annual billing, which offers a 20% discount - bringing the Pro plan’s cost down from $76.80 to $61.44 per year.
This tiered structure allows users to manage predictable baseline costs while remaining flexible enough to handle spikes in demand during busy periods.
Platform B uses a per-token pricing model, charging per 1 million tokens and breaking costs into input, output, and cached input categories. It offers four processing tiers tailored to different needs:
The platform also provides model options based on complexity. For example, the flagship GPT-5.2 handles advanced tasks at $1.75 per 1M input tokens and $14.00 per 1M output tokens under the Standard tier. For simpler needs, GPT-5-mini costs just $0.25 per 1M input tokens, making it 85% cheaper than GPT-5.2. For high-volume, straightforward tasks, the lightweight GPT-5-nano is available at only $0.05 per 1M input tokens. This tiered approach gives businesses flexibility while delivering opportunities for cost savings.
Platform B introduces Prompt Caching to further reduce costs. Reusing the same context - such as system instructions or shared documents - can cut input token expenses by up to 90%. For instance, on the GPT-5.2 Standard tier, cached input tokens are billed at $0.175 per 1M tokens compared to $1.75 for new input. This feature is particularly useful for applications that repeatedly reference the same knowledge base or guidelines.
In addition, the Batch API offers a straightforward way to cut costs in half compared to Standard pricing. Tasks like nightly evaluations or bulk summarizations can be completed more affordably without altering workflows. To avoid unexpected charges, businesses can also set strict output length limits, as advanced models charge for internal "thinking" tokens included in output calculations.
Platform B’s transparent token tracking system simplifies scaling for businesses. Its tiered pricing structure allows companies to adjust speed and cost based on demand. For instance, critical requests can be routed through the Priority tier, which doubles token costs - $3.50 per 1M input tokens and $28.00 per 1M output tokens - while less urgent tasks can be assigned to the Batch tier at half the price. This flexibility ensures businesses only pay for speed when necessary while maintaining access to premium performance for tight deadlines.
The token-based system also provides clear cost forecasting and control. Different models can be allocated to specific departments: customer-facing chatbots might rely on the affordable and fast GPT-5-mini, while research teams could use the more advanced GPT-5.2 Pro (priced at $21.00 per 1M input tokens and $168.00 per 1M output tokens) for complex analyses. This granular control allows businesses to balance performance and cost as they expand their AI usage.
Platform C, powered by Google Gemini, stands out with its 2-million-token context window, making it ideal for handling large-scale workloads like processing entire codebases or analyzing over 100 PDFs in a single query. The Gemini 1.5 Pro model is priced at $3.50 per 1M input tokens and $10.50 per 1M output tokens (as of January 2026). For businesses prioritizing speed and scale over complex reasoning, the Gemini Flash tier offers a budget-friendly alternative tailored for high-volume tasks.
A key feature of Platform C is its Context Caching, which reduces costs for repeated queries. For example, if you upload a large dataset - such as a 1-hour video or detailed documentation - into the context window, future queries on this cached content are priced at a fraction of the usual input token rate. This is especially advantageous for Retrieval-Augmented Generation (RAG) workflows, where Platform C provides exceptional efficiency for handling extensive document sets. This capability translates into measurable cost savings, as outlined below.
Platform C shines when it comes to managing multimodal tasks or analyzing large-scale documents. Unlike competitors with smaller context windows - like OpenAI's 128k or Anthropic's 200k - which require time-consuming and costly chunking processes, Platform C's 2-million-token capacity allows businesses to process entire datasets in a single operation. This eliminates the need for multiple API calls, significantly reducing overhead for tasks involving legal documents, technical codebases, or comprehensive research materials.
The Context Caching feature further enhances cost efficiency by cutting redundant input token expenses by up to 90% for repeated queries. Instead of paying full input token rates every time, cached tokens are billed at much lower rates, minimizing unnecessary spending. This makes Platform C particularly effective for applications that frequently reference the same knowledge base throughout the day, such as customer service platforms or technical support systems. By offering predictable costs and reducing token waste, Platform C ensures businesses can maximize their return on investment for large-scale data operations.
Platform C’s cost-effective design supports seamless scalability for businesses with diverse operational needs. As of 2026, the focus has shifted from simply lowering prices to optimizing cost efficiency, and Platform C embodies this shift. Many startups now utilize LLM Routers to balance expenses, directing complex tasks to premium models like Gemini 1.5 Pro while routing simpler, high-volume operations to more economical options like Gemini Flash. This approach allows businesses to scale without compromising performance or breaking their budgets.
The platform’s transparent, token-based pricing model simplifies cost forecasting as operations expand. With the 2-million-token context window, businesses can consolidate workflows that would otherwise require multiple API calls on competing platforms. For instance, a company can analyze an entire quarter's worth of customer support tickets or process extensive technical documentation in one pass. This eliminates fragmented charges, providing a straightforward and predictable pricing structure that supports growth without unexpected expenses.
Generative AI Pricing Models Comparison 2026: Features, Costs and Best Fit
Pricing models in the AI space come with their own sets of trade-offs, balancing cost, flexibility, and predictability. Token-based pricing stands out for its transparency - you pay strictly for what you use. However, this model carries the risk of unexpected expenses, especially if autonomous agents loop or if tasks requiring complex reasoning consume a large number of tokens. While traditional SaaS businesses often maintain gross margins of 80-90%, AI-driven companies see margins dip to 50-60% due to the variable compute costs linked to token usage.
Hybrid models, which combine a base subscription with usage-based tiers, have gained traction as of 2026. They offer predictable revenue for vendors while allowing for additional charges as customers scale their usage. This makes them particularly appealing to mid-market and enterprise buyers seeking budget stability. However, fixed subscriptions can result in margin erosion if heavy users generate high costs that aren't offset by matching revenue. To address this, prompts.ai uses a pay-as-you-go TOKN credit system, eliminating recurring fees and tying costs directly to actual consumption.
Outcome-based pricing, where payment is tied to results - such as resolved tickets or completed tasks - aligns costs with business outcomes. However, this approach presents challenges in managing cost variability and accurately attributing outcomes.
"AI is no longer just a tool that extends human capacity; it's a productive teammate that completes work autonomously. Products should get paid for outcomes, not access."
Despite its appeal, only 43% of enterprise buyers view outcome-based pricing as a key factor, largely due to the complexities of measuring results.
For organizations with high, steady workloads, on-premises infrastructure can slash costs significantly - up to 18 times cheaper per million tokens compared to cloud services. Breakeven can occur in as little as four months. However, the upfront expense is steep - a Lenovo ThinkSystem SR680a V3 with 8x H200 GPUs costs approximately $277,897.75. Additionally, managing such infrastructure requires technical expertise, making this option suitable only for large, tech-savvy organizations with predictable workloads.
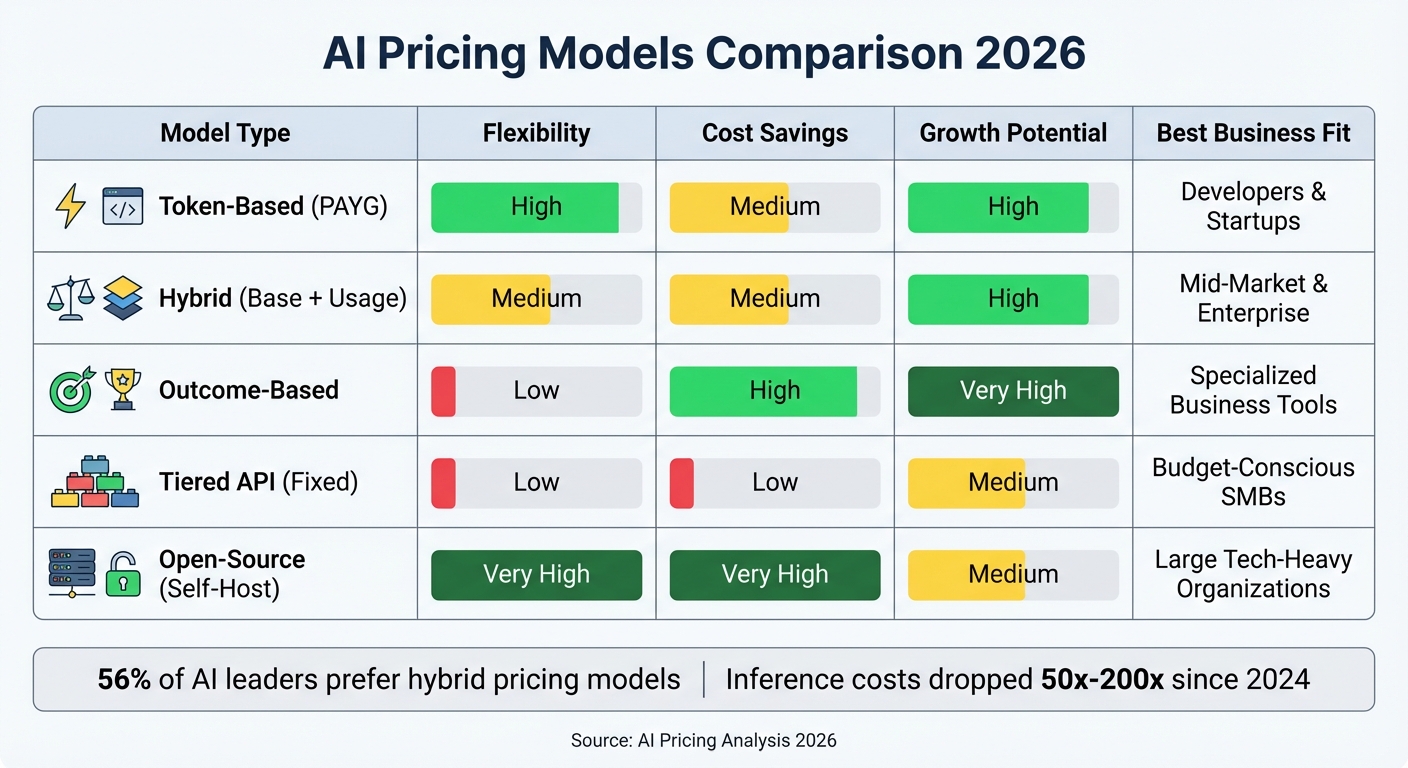
The following table breaks down these pricing models, helping you align them with your organization's needs and priorities:
| Model Type | Flexibility | Cost Savings | Growth Potential | Business Fit |
|---|---|---|---|---|
| Token-Based (PAYG) | High | Medium | High | Developers & Startups |
| Hybrid (Base + Usage) | Medium | Medium | High | Mid-Market & Enterprise |
| Outcome-Based | Low | High | Very High | Specialized Business Tools |
| Tiered API (Fixed) | Low | Low | Medium | Budget-Conscious SMBs |
| Open-Source (Self-Host) | Very High | Very High | Medium | Large Tech-Heavy Organizations |
Choosing the right pricing model for AI investments depends on your organization's size, how predictable your AI usage is, and the pace at which you’re growing. For startups, token-based pay-as-you-go (PAYG) models offer flexibility. Mid-sized businesses often benefit from hybrid approaches, while committed-use or self-hosted solutions are typically better suited for large enterprises. This framework lays the foundation for a scalable and sustainable AI pricing strategy.
AI pricing is changing quickly. Inference costs are dropping dramatically - by as much as 50x to 200x annually - and global AI spending is expected to hit $2.022 trillion by 2026. With cost becoming as important as performance, businesses using multiple pricing models are growing 30% faster, and 56% of AI leaders now lean toward hybrid pricing strategies.
For advanced solutions like autonomous agents or end-to-end systems, outcome-based pricing links costs directly to results. However, only 43% of enterprise buyers currently prioritize this model due to the challenges of measuring outcomes effectively. On top of that, for every $1 spent on AI models, companies typically invest an additional $5–$10 in areas like data engineering, security, and monitoring. To manage expenses, building real-time usage dashboards early on is crucial. Other tactics include routing 70–80% of routine tasks to smaller, cost-efficient models, leveraging batch processing for non-urgent tasks to unlock discounts of up to 50%, and using prompt caching to reduce input costs by as much as 90%.
The right pricing strategy doesn’t just manage costs today - it sets the stage for long-term scalability and protects your margins as you grow. Platforms like prompts.ai, which eliminate recurring fees and align costs with actual usage through pay-as-you-go TOKN credits, help maximize ROI while providing clear operational visibility. By adopting transparent and tailored pricing models, you can streamline scalability and ensure your AI-powered workflows remain efficient and cost-effective.
To select the most suitable AI pricing model, start by analyzing your cost structure - this could include expenses like GPU usage or API fees - and understanding your customer usage patterns. If usage is steady and predictable, fixed subscription tiers are often a good fit. On the other hand, for fluctuating or unpredictable usage, pay-as-you-go or hybrid models might be more effective. Incorporate AI-specific metrics, such as tokens or compute units, to fine-tune your approach. Testing a hybrid model can provide insights, allowing you to adjust pricing based on actual customer behavior and usage data.
To keep token costs under control and avoid surprises, make it a habit to monitor your usage frequently. Set up usage limits or alerts to stay informed, and consider strategies like caching or batching to optimize how tokens are consumed. These practices can help you balance cost management with maintaining strong performance.
Self-hosting starts to make financial sense when the total costs of infrastructure, hardware, staffing, and upkeep fall below what you'd spend on subscription or usage fees from cloud providers. The exact point where this shift occurs depends on factors such as the size of your operations, specific requirements, and how efficiently you manage resources.

















