Pay As You Go - AI Model Orchestration and Workflows Platform


Managing AI costs can be unpredictable, but tracking token expenses is now easier with specialized platforms. These tools help monitor usage, pinpoint cost drivers, and optimize spending across AI models like GPT-5, Claude, and Gemini. Here's a quick look at five platforms offering real-time insights and cost management features:
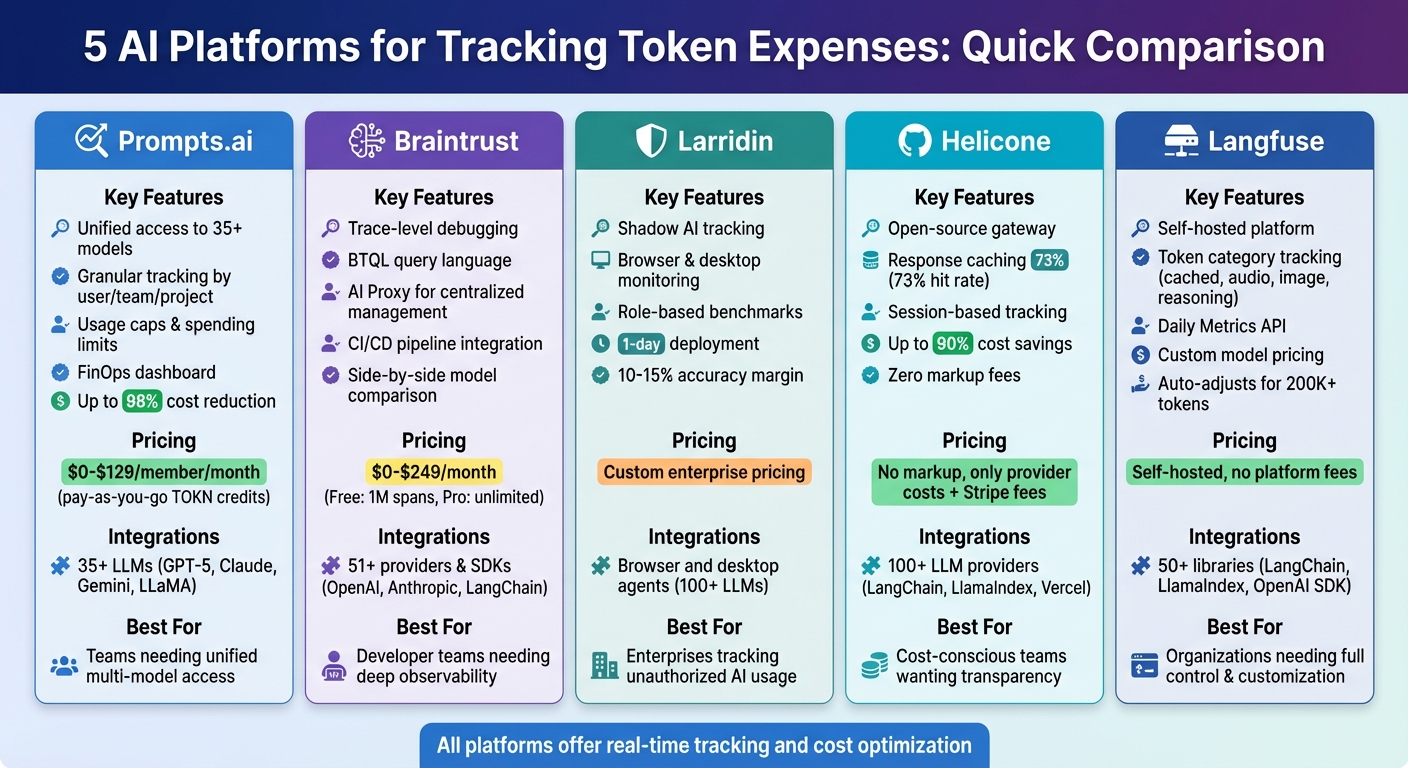
Quick Comparison:
| Platform | Key Features | Pricing | Integrations |
|---|---|---|---|
| Prompts.ai | Granular tracking, usage caps | $0-$129/member/month | 35+ LLMs |
| Braintrust | Trace spans, AI Proxy | $0-$249/month | 51+ providers and SDKs |
| Larridin | Shadow AI tracking, fast deployment | Custom | Browser and desktop agents |
| Helicone | Open-source, caching, routing | No markup, Stripe fees | 100+ LLMs |
| Langfuse | Token category tracking, self-hosted | Self-hosted, no fees | 50+ libraries and frameworks |
These platforms provide actionable insights to manage token expenses effectively, ensuring your AI investments align with your goals.
AI Token Tracking Platforms Comparison: Features, Pricing and Integrations
Prompts.ai is an enterprise-grade AI orchestration platform that brings together over 35 leading large language models (LLMs), including GPT-5, Claude, LLaMA, and Gemini, all within a single interface. It streamlines workflows by reducing tool sprawl and provides teams with full transparency into token usage and costs for every AI interaction.
With Prompts.ai, you get real-time insights into token consumption across all connected models. The platform allows you to monitor usage at granular levels - whether by individual team members, specific projects, or even particular prompt iterations. This level of detail helps identify which workflows, users, or API calls are driving expenses. Its integrated FinOps dashboard highlights usage patterns and spending trends, making it easier to detect and address anomalies before they escalate into costly issues.
The platform integrates cost-saving measures directly into your workflows, enabling organizations to reduce AI software expenses by up to 98%. You can implement usage caps, set spending limits, and receive alerts when thresholds are approached. By linking spending to business outcomes, the system ensures that cost reductions don’t compromise performance but instead strike a balance between efficiency and results.
Prompts.ai supports seamless integration with 35+ top LLMs, such as GPT-5, Grok-4, Claude, LLaMA, Gemini, Flux Pro, and Kling. This multi-model capability allows you to compare performance and costs side-by-side, then assign tasks to the most cost-effective model without needing to switch tools. Teams can onboard new models in minutes, and the platform’s unified interface ensures consistent governance and audit trails across all integrations.
Prompts.ai offers pricing plans designed to accommodate a variety of team sizes and needs. Personal plans start at $0/month with a pay-as-you-go model for exploration, while the Creator plan is $29/month and the Family Plan is $99/month. For businesses, the Core plan costs $99 per member/month, and the Elite plan is $129 per member/month. The platform’s TOKN credit system operates on a pay-as-you-go basis, eliminating recurring fees and ensuring you only pay for the resources you actually use. This approach aligns costs with usage, providing flexibility and control over your budget.
Braintrust serves as an AI observability platform, trusted by companies like Notion, Stripe, Zapier, Instacart, Vercel, and Airtable to track token usage with precision. It operates through "trace spans", which are the basic units representing operations such as LLM API calls or prompt rendering. Each function call generates metadata, including token counts and latency metrics, giving users complete insight into their AI-related expenses.
With Braintrust, you can analyze production logs using BTQL, a query language designed to break down token expenses across specific projects or traces. Each output links directly to a specific prompt version, allowing you to trace token usage back to individual iterations of your AI setup. Dashboards combine metrics for cost, quality, and latency, offering real-time monitoring. Detailed usage reports are accessible via "View usage details" in Settings > Billing, which opens the Orb usage portal for in-depth cost monitoring. This level of granularity helps identify inefficiencies early, aiding in cost control.
Braintrust builds on its token tracking capabilities to streamline costs through centralized management of AI provider deployments using its AI Proxy. This tool allows you to compare models side by side, enabling evaluations like testing GPT-4o against GPT-4o Mini to assess performance relative to cost. The platform supports deployment across development, staging, and production environments, ensuring cost-effectiveness is validated before a full rollout. Integration with CI/CD pipelines via GitHub Actions flags quality and cost regressions directly in pull requests, simplifying monitoring.
Braintrust supports 51+ integrations spanning AI providers, SDKs, and developer tools. Supported providers include OpenAI, Anthropic, Gemini, AWS Bedrock, Azure OpenAI, Mistral, Perplexity, and Groq. Framework integrations cover tools like Vercel AI SDK, LangChain, LlamaIndex, CrewAI, Pydantic AI, and LiteLLM. The AI Proxy acts as a centralized hub, allowing you to switch between providers without modifying your code. Official SDKs are available for a variety of programming languages, including TypeScript/JavaScript, Python, Go, Ruby, Java, C#, and Kotlin.
Braintrust offers three pricing tiers tailored to different team needs:
Larridin’s Scout platform leverages browser plugins and desktop agents to monitor AI tool usage across enterprises. This includes both approved tools and "shadow AI" - those installed by employees without IT approval. Deployment data often reveals organizations are using 3–5 times more AI tools than they initially expected.
The Scout platform delivers detailed analytics across teams, applications, and time periods. At the team level, it identifies heavy users and unusual consumption patterns. At the application level, it distinguishes between simple chatbot interactions and more complex, token-heavy tasks like document analysis. Since external providers rarely share direct token data, Larridin uses proxy metrics - such as usage frequency, session duration, and application behavior - to estimate token consumption. These estimates, with a 10-15% margin of accuracy, are enough to pinpoint major cost drivers and detect anomalies.
Research shows that 85% of enterprises exceed their AI infrastructure budgets by over 10%. Larridin’s platform helps set realistic consumption benchmarks by role and establish departmental budgets based on typical usage trends. It also tracks which AI models, like GPT-4o or GPT-4o Mini, are being used for specific tasks, ensuring premium models are reserved for situations where they’re truly needed. By identifying temporal usage patterns, the platform quickly flags and addresses any unexpected spikes.
"Without visibility into AI token consumption, finance leaders operate blind while costs accumulate." - Jim Larrison, Larridin's founder
This focus on cost management ties seamlessly into Larridin’s fast deployment and integration capabilities.
Larridin prioritizes ease of deployment. Its browser-based monitoring can be set up in just one day, with desktop agents added soon after for more detailed insights. The platform tracks usage at both the application and aggregate levels, offering financial oversight without compromising employee privacy.
Larridin’s pricing details are not publicly available. For a custom enterprise quote tailored to your organization’s size and monitoring needs, you’ll need to contact their sales team directly.
Helicone offers an open-source, transparent solution for managing AI costs, complementing other token tracking tools. This observability platform supports over 100 LLM providers through a single endpoint and provides two tracking options: 100% accurate tracking via its AI Gateway using Model Registry v2, and "Best Effort" tracking for direct provider integrations. The latter relies on an open-source repository that includes over 300 models. Unlike competitors that tack on markup fees, Helicone charges no markup - users pay only what their provider bills, plus standard Stripe processing fees. This approach simplifies cost management while ensuring clarity in AI workflows.
Helicone organizes related API requests into Sessions, offering insights into the total cost of entire workflows rather than individual calls. For instance, it can compare the cost of handling a full support ticket workflow with that of a single query. Custom properties enable segmentation of cost data by factors like user tier, feature, or environment. Weekly automated reports sent via Email or Slack provide a summary of spending, highlight key cost drivers, and suggest ways to optimize usage.
The AI Gateway helps cut costs by routing requests to the most affordable provider for the selected model. Response caching further reduces expenses by avoiding redundant API calls for repeated queries. An internal test showed a 73% cache hit rate, saving $1,247 in a single month. Helicone also assists in aligning task complexity with the appropriate model tier, ensuring that simpler tasks don’t unnecessarily use high-cost models like GPT-4.5 when a more economical option like GPT-4o Mini would suffice. By leveraging all of Helicone's optimization tools, users can reduce LLM costs by as much as 90%, with caching alone typically saving 15-30%. These features integrate seamlessly with widely-used AI tools, detailed below.
Helicone works with popular AI frameworks such as LangChain, LangGraph, LlamaIndex, Vercel AI SDK, and Zapier. To start tracking costs, simply update the baseURL to https://ai-gateway.helicone.ai and add your API key. The platform also supports BYOK (Bring Your Own Key), allowing organizations to use existing credits from providers like AWS Bedrock or Azure before incurring additional expenses. Additionally, users can set up smart alerts at thresholds like 50%, 80%, and 95% of their budget to prevent unexpected spending spikes.
Helicone’s open-source nature ensures a zero-markup pricing structure. Users rely on their existing provider keys and are billed directly by those providers at their standard rates, with only standard payment processing fees applied. This model keeps costs straightforward and predictable.
Langfuse stands out as an open-source platform designed to track token usage and expenses across AI workflows with exceptional detail. It goes beyond basic metrics like input and output, offering insights into specific token types like cached_tokens, audio_tokens, image_tokens, and reasoning_tokens. This level of granularity allows businesses to pinpoint exactly where their AI spending occurs.
Langfuse provides detailed cost breakdowns through its Daily Metrics API, which organizes data by application type, userId, or custom tags. This enables precise cost attribution, making it easier to bill individual users or enforce rate limits. For models with large context windows, such as Claude 3.5 Sonnet or Gemini 1.5 Pro, Langfuse automatically adjusts for conditional pricing when token usage exceeds 200,000. To ensure accuracy, the platform employs specific tokenizers: o200k_base for GPT-4o, cl100k_base for other GPT models, and @anthropic-ai/tokenizer for Claude models.
Langfuse simplifies cost estimation for popular models using built-in tokenizers, while prioritizing explicit cost data when available. For businesses using self-hosted or fine-tuned models, the platform allows custom pricing configurations for different token types through Project Settings > Models. This flexibility ensures that new traces are automatically accounted for, helping organizations monitor their budgets closely and avoid unexpected expenses.
With support for over 50 libraries and frameworks, Langfuse integrates seamlessly into various AI workflows. It offers native support for tools like LangChain, LlamaIndex, OpenAI SDK, LiteLLM, and OpenRouter. The Python SDK uses @observe() decorators for automatic tracing, while JavaScript/TypeScript implementations rely on context managers. For reasoning models like OpenAI's o1 family, users need to manually provide token usage data, as these models do not expose internal reasoning token counts. Meanwhile, LiteLLM and OpenRouter integrations directly capture cost details from responses, making it easier to manage expenses without additional effort.
Langfuse is self-hostable, offering flexibility and control without recurring platform fees. It also includes enterprise-grade security and administrative tools. Users can manage model pricing configurations programmatically using the Models API (/api/public/models), giving them full control over cost tracking and ensuring that the platform adapts to their specific needs.
This section examines key features like token tracking, integration simplicity, and pricing models across various platforms. Here's how they stack up in real-time tracking, integration capabilities, and cost management.
Prompts.ai offers unified access to over 35 models, including GPT-5, Claude, Gemini, and LLaMA, with built-in FinOps controls that track token usage in real time. Spending is directly tied to users, teams, and projects, making cost attribution straightforward. Its pay-as-you-go TOKN credits eliminate recurring subscription fees, reducing AI software costs by up to 98%. Additionally, it allows side-by-side performance comparisons across models, giving users a clear view of their options.
Braintrust specializes in trace-level debugging, offering custom pricing maps to define input and output costs per 1 million tokens. It provides detailed breakdowns, including specific categories like cache reads and reasoning tokens. Larridin focuses on usage-based attribution for over 100 LLMs, tracking expenses tied to API keys, teams, and users. Helicone acts as a gateway proxy, calculating costs immediately at the request level, making it a quick solution for teams seeking instant FinOps insights. Langfuse provides open-source flexibility, automatically calculating costs during ingestion and adapting to token categories like cached_tokens, audio_tokens, and image_tokens, all without platform fees.
Accuracy in cost tracking varies across platforms. Braintrust and Langfuse allow manual cost adjustments, which are essential for models like Gemini that use tiered pricing structures where standard token counts may not align with actual billing. Helicone’s gateway approach offers instant visibility, though its token-based estimates may require cross-checking with provider dashboards for confirmation.
Integration capabilities are another key factor. Prompts.ai simplifies this process by consolidating over 35 models into a single interface, eliminating the hassle of managing multiple API keys and billing accounts. Langfuse integrates seamlessly with more than 50 libraries, such as LangChain, LlamaIndex, OpenAI SDK, LiteLLM, and OpenRouter, using Python’s @observe() decorators for automatic tracing. Braintrust employs @traceable decorators to automatically generate expense data, while Helicone’s proxy setup requires minimal code changes, enabling quick deployment.
When it comes to cost management, these platforms offer diverse pricing models to suit different organizational needs. Options range from pay-as-you-go credits to tiered subscriptions and self-hosted solutions, allowing users to select the structure that aligns best with their financial strategies. Efficient token tracking and cost monitoring are central to these platforms, ensuring better control over AI-related expenses.
Managing token expenses has become a top priority for decision-makers. As spending on generative AI takes up a larger share of operational budgets, these platforms tackle the critical need for visibility and control over costs, which can fluctuate depending on factors like prompt length, retrieval size, and tool usage.
Each platform offers distinct solutions to common challenges. Whether you’re looking for tools to enhance visibility with caching and routing, need trace-level debugging for complex workflows, or prefer a unified interface to simplify API key and billing management, there’s an option tailored to your needs. Observability tools that link costs to specific prompt versions help identify and address inefficiencies before they escalate.
The key to effective expense tracking is connecting spending to success metrics. The best platforms go beyond cutting costs - they help you evaluate whether your spending is driving meaningful results. This includes monitoring accuracy, reliability, and performance alongside financial data to ensure each token contributes to your goals.
Start by pinpointing your primary challenge, whether it’s fragmented data, unpredictable cost surges, or a lack of attribution. Then, choose a platform with features designed to address that issue. With AI gross margins typically lower than traditional SaaS (50–60% compared to 80–90%), tracking true costs from the beginning is essential for scaling effectively. These tools enable you to align spending with measurable outcomes, ensuring your AI investments deliver real value.
To find the right platform, look for features that make managing token usage simple and efficient. Key aspects include detailed tracking of token usage - whether by request, user, or team - along with real-time monitoring through dashboards. The platform should also offer easy integration options, such as SDKs or APIs, to fit seamlessly into your workflow. Make sure it supports multiple models and providers, enabling better cost management and oversight. Keeping these priorities in mind will help you control token expenses while meeting your specific requirements.
The fastest way to keep tabs on token usage across your applications is through a tool like Prompts.ai. With its real-time token tracking built right into the prompt editor and compatibility with more than 35 models, it’s easy to get started. Just log in, and you can begin monitoring usage instantly. This helps you pinpoint inefficient prompts, cut costs, and simplify workflows - all without dealing with a complex setup.
AI platforms, such as prompts.ai, offer tools that allow administrators to track token costs in real time, breaking them down by users, projects, or specific features. This level of detail makes it easier to pinpoint what’s driving costs and manage budgets with greater precision. Additionally, these platforms include alerts for unexpected spikes in usage, helping to maintain transparency and stay ahead of potential budget overruns.



















