Pay As You Go7 दिन का फ़्री ट्रायल; किसी क्रेडिट कार्ड की आवश्यकता नहीं


व्यावसायिक उद्देश्यों के साथ गुणवत्ता, विश्वसनीयता और संरेखण सुनिश्चित करने के लिए जनरेटिव AI मॉडल के आउटपुट का मूल्यांकन करना महत्वपूर्ण है। संरचित मूल्यांकन दृष्टिकोण के बिना, विसंगतियां, मतिभ्रम और पूर्वाग्रह खराब प्रदर्शन, अनुपालन जोखिम और विश्वास की हानि का कारण बन सकते हैं। यहां बताया गया है कि आपको क्या जानना चाहिए:
प्लेटफ़ॉर्म जैसे Prompts.ai 35+ प्रमुख मॉडलों में अनुरूप वर्कफ़्लो, साइड-बाय-साइड मॉडल तुलना और संरचित मूल्यांकन की पेशकश करके इस प्रक्रिया को सरल बनाएं। इन उपकरणों के साथ, संगठन आत्मविश्वास से AI समाधानों को लागू कर सकते हैं जो उच्च मानकों को पूरा करते हैं और मापने योग्य परिणाम देते हैं।
ये पांच मेट्रिक्स बड़े भाषा मॉडल (एलएलएम) के प्रदर्शन का आकलन करने के लिए एक संरचित तरीका प्रदान करते हैं, जिससे यह सुनिश्चित होता है कि वे विभिन्न अनुप्रयोगों में अपेक्षाओं को पूरा करते हैं।
तथ्यात्मकता मापता है कि आउटपुट सत्यापित तथ्यों और स्थापित ज्ञान के साथ कितनी अच्छी तरह संरेखित होता है। यह विशेष रूप से तब महत्वपूर्ण होता है जब एलएलएम ग्राहक के प्रश्नों का उत्तर देने, रिपोर्ट तैयार करने, या निर्णय को प्रभावित करने वाली जानकारी प्रदान करने जैसे कार्यों को संभालते हैं। सहीतादूसरी ओर, तार्किक तर्क, सटीक गणना और निर्दिष्ट दिशानिर्देशों के पालन तक फैली हुई है।
तथ्यात्मकता का प्रभावी ढंग से मूल्यांकन करने के लिए, उपयोग करें ग्राउंड ट्रुथ डेटासेट जिसमें आपके आवेदन के अनुरूप सत्यापित जानकारी शामिल है। उदाहरण के लिए, ग्राहक सहायता में, इसमें उत्पाद विवरण, मूल्य निर्धारण और कंपनी की नीतियां शामिल हो सकती हैं। सामग्री निर्माण में, विश्वसनीय स्रोतों या उद्योग डेटाबेस के विरुद्ध तथ्य-जांच महत्वपूर्ण है।
मूल्यांकन विधियों में आउटपुट की तुलना जमीनी सत्य डेटासेट से करना, निश्चित उत्तरों के साथ परीक्षण सेट का उपयोग करना और बहु-चरणीय सत्यापन प्रक्रियाओं को लागू करना शामिल है। इन चरणों से उन सूक्ष्म अशुद्धियों को उजागर करने में मदद मिलती है, जिनका पता नहीं चल पाता।
पूर्वाग्रह का पता लगाना अनुचित व्यवहार या प्रतिनिधित्व के उदाहरणों की पहचान करता है, जबकि विषाक्तता का आकलन आपत्तिजनक, हानिकारक, या अनुचित सामग्री का पता लगाने पर केंद्रित है। ब्रांड की प्रतिष्ठा की रक्षा करने और नैतिक AI मानकों का पालन करने के लिए ये मेट्रिक्स महत्वपूर्ण हैं।
पूर्वाग्रह जनसांख्यिकीय रूढ़ियों या असंवेदनशील प्रतिनिधित्व के रूप में प्रकट हो सकते हैं। विभिन्न परिदृश्यों में विविध संकेतों का उपयोग करके आउटपुट का परीक्षण करने से छिपे हुए पूर्वाग्रहों को प्रकट करने में मदद मिलती है।
विषाक्तता के लिए, नफरत फैलाने वाले भाषण, उत्पीड़न, स्पष्ट भाषा और अन्य हानिकारक सामग्री के लिए आउटपुट की जांच की जाती है। उपयोग करें स्वचालित उपकरण सूक्ष्म मुद्दों का पता लगाने के लिए मानवीय समीक्षाओं के साथ-साथ चुनौतीपूर्ण संकेतों के साथ नियमित परीक्षण से उपयोगकर्ताओं को प्रभावित करने से पहले कमजोरियों को उजागर किया जा सकता है।
नैतिक विचारों में यह सुनिश्चित करना भी शामिल है कि आउटपुट उपयोगकर्ता की गोपनीयता का सम्मान करते हैं, हेरफेर से बचते हैं और संवेदनशील विषयों पर संतुलित दृष्टिकोण प्रस्तुत करते हैं। पारदर्शिता और निष्पक्षता बनाए रखने के लिए विवादास्पद मुद्दों को संबोधित करते समय आउटपुट में अस्वीकरण या संदर्भ शामिल होने चाहिए।
क्लैरिटी मूल्यांकन करता है कि प्रतिक्रिया समझने में आसान है और कार्रवाई योग्य है या नहीं। उपयुक्तता मापता है कि आउटपुट उपयोगकर्ताओं को अपने लक्ष्यों को प्राप्त करने में कितनी अच्छी तरह मदद करता है, और प्रासंगिकता यह निर्धारित करता है कि दिए गए प्रश्न या संदर्भ के साथ प्रतिक्रिया कितनी बारीकी से मेल खाती है।
संरचना, शब्दावली और प्रवाह की जांच करके स्पष्टता का आकलन किया जा सकता है, अक्सर पठनीयता स्कोर का उपयोग करके। व्यावसायिक अनुप्रयोगों के लिए, सुनिश्चित करें कि तकनीकी शब्दों को स्पष्ट रूप से समझाया गया है और निर्देशों पर कार्रवाई की जा सकती है।
उपयोगिता उपयोगकर्ता की ज़रूरतों को समझने और यह ट्रैक करने पर निर्भर करती है कि प्रतिक्रियाएँ उन्हें कितनी अच्छी तरह पूरा करती हैं। अनुवर्ती प्रश्न, संतुष्टि स्कोर, या कार्य पूर्ण करने की दर जैसे मेट्रिक्स उपयोगिता में अंतराल को उजागर कर सकते हैं। यदि यूज़र अक्सर स्पष्टीकरण चाहते हैं, तो यह सुधार की गुंजाइश को दर्शाता है।
प्रासंगिकता इस बात पर केंद्रित है कि प्रतिक्रिया मूल क्वेरी से कितनी अच्छी तरह मेल खाती है। स्कोरिंग सिस्टम दिए गए संदर्भ के साथ आउटपुट के संरेखण को मापने में मदद कर सकते हैं, यह सुनिश्चित करते हुए कि प्रतिक्रियाएँ विषय पर और संक्षिप्त हैं। संवादात्मक AI में, बनाए रखना प्रासंगिक प्रासंगिकता महत्वपूर्ण है, क्योंकि पिछली बातचीत पर प्रतिक्रियाओं का तार्किक रूप से निर्माण होना चाहिए।
दु: स्वप्न तब होता है जब एलएलएम प्रशंसनीय लगने वाली लेकिन झूठी या मनगढ़ंत जानकारी उत्पन्न करते हैं। यह मीट्रिक एंटरप्राइज़ सेटिंग्स में विशेष रूप से महत्वपूर्ण है, जहाँ सटीकता निर्णय और विश्वास को प्रभावित करती है।
मतिभ्रम का पता लगाने के लिए, सत्यापित स्रोतों के खिलाफ तथ्यों की जांच करें और ट्रैक करें कि मनगढ़ंत सामग्री कितनी बार दिखाई देती है। मतिभ्रम के पैटर्न में नकली उद्धरण, गलत ऐतिहासिक तारीखें या बनाए गए आंकड़े शामिल हो सकते हैं। इन समस्याओं के परीक्षण के लिए विशेष रूप से डिज़ाइन किए गए मूल्यांकन डेटासेट विकसित करें, जिसमें मॉडल की ज्ञान सीमाओं को चुनौती देने वाले संकेत शामिल हैं।
मतिभ्रम दर को मापने में प्रतिनिधि नमूने के भीतर मनगढ़ंत जानकारी वाली प्रतिक्रियाओं के प्रतिशत की गणना करना शामिल है। चूंकि मतिभ्रम के पैटर्न अलग-अलग डोमेन में भिन्न हो सकते हैं, इसलिए निरंतर निगरानी आवश्यक है।
कार्य पूरा करना मापता है कि AI प्रॉम्प्ट में उल्लिखित विशिष्ट अनुरोध या उद्देश्य को पूरा करता है या नहीं। सटीकता यह आकलन करता है कि आउटपुट अपेक्षित परिणामों से कितनी निकटता से मेल खाता है या दी गई आवश्यकताओं का पालन करता है।
कार्य पूर्णता और सटीकता का मूल्यांकन करने के लिए, अपेक्षित परिणामों के साथ आउटपुट की तुलना करें और सफलता दर और त्रुटि आवृत्तियों की गणना करें। उपयोग के प्रत्येक मामले के लिए सफलता मानदंड को स्पष्ट रूप से परिभाषित करें। उदाहरण के लिए, ग्राहक सेवा में, किसी कार्य को तब पूर्ण माना जा सकता है जब उपयोगकर्ता की क्वेरी को पूरी तरह से संबोधित किया जाता है और किसी भी आवश्यक अनुवर्ती कार्रवाई की पहचान की जाती है। सामग्री निर्माण में, सफलता विशिष्ट लंबाई, टोन या फ़ॉर्मेटिंग आवश्यकताओं को पूरा करने पर निर्भर हो सकती है।
सटीकता स्कोरिंग पूर्ण और आंशिक दोनों सफलताओं को प्रतिबिंबित करना चाहिए। उदाहरण के लिए, एक प्रतिक्रिया जो एक बहु-भाग प्रश्न के 80% को संबोधित करती है, वह पूरी तरह से छूट जाने वाले प्रश्नों की तुलना में अधिक मूल्य प्रदान करती है। भारित स्कोरिंग सिस्टम उच्च मानकों की आवश्यकता के साथ आंशिक शुद्धता के लिए क्रेडिट को संतुलित करते हुए इस बारीकियों को पकड़ सकते हैं।
ये पांच मेट्रिक्स एलएलएम के प्रदर्शन का मूल्यांकन करने के लिए एक संपूर्ण ढांचा प्रदान करते हैं। अगला भाग वास्तविक दुनिया के परिदृश्यों में इन मैट्रिक्स को लागू करने के व्यावहारिक तरीकों का पता लगाएगा।
संरचित मूल्यांकन विधियां बड़े भाषा मॉडल (एलएलएम) के प्रदर्शन को मापने के लिए एक सुसंगत और विश्वसनीय तरीका सुनिश्चित करती हैं। इन तरीकों में स्वचालित स्कोरिंग सिस्टम से लेकर मानव निरीक्षण तक शामिल हैं, जो विभिन्न अनुप्रयोगों में गुणवत्ता नियंत्रण सुनिश्चित करते हैं।
संदर्भ-आधारित मूल्यांकन इसमें एलएलएम आउटपुट की तुलना पूर्वनिर्धारित “गोल्डन” उत्तरों या डेटासेट से करना शामिल है। यह विधि स्पष्ट, वस्तुनिष्ठ उत्तरों वाले कार्यों के लिए अच्छी तरह से काम करती है, जैसे कि गणित की समस्याओं को हल करना, तथ्यात्मक प्रश्नों का उत्तर देना या पाठ का अनुवाद करना। उदाहरण के लिए, अनुवाद के लिए BLEU स्कोर या तथ्यात्मक प्रश्नों के लिए सटीक मिलान प्रतिशत जैसे मेट्रिक्स मापने योग्य परिणाम प्रदान करते हैं। ग्राहक सेवा परिदृश्यों में, जेनरेट की गई प्रतिक्रियाओं की तुलना स्वीकृत उत्तरों के डेटाबेस से की जा सकती है ताकि स्थिरता की जांच की जा सके और ज्ञात जानकारी का पालन किया जा सके।
दूसरी ओर, संदर्भ-मुक्त मूल्यांकन पूर्वनिर्धारित उत्तरों पर भरोसा किए बिना आउटपुट का आकलन करता है। यह दृष्टिकोण रचनात्मक लेखन, विचार-मंथन, या ओपन-एंडेड प्रश्नों जैसे कार्यों के लिए अधिक उपयुक्त है, जहां कई मान्य प्रतिक्रियाएँ संभव हैं। एक “सही” उत्तर पर ध्यान केंद्रित करने के बजाय, मूल्यांकनकर्ता सुसंगतता, प्रासंगिकता और उपयोगिता जैसे कारकों पर विचार करते हैं। आउटपुट की गुणवत्ता का आकलन करने के लिए यह विधि अक्सर प्रशिक्षित मूल्यांकनकर्ता मॉडल या मानवीय निर्णय का उपयोग करती है। उदाहरण के लिए, रचनात्मक लेखन टूल का परीक्षण करते समय, मूल्यांकनकर्ता जेनरेट की गई सामग्री की तथ्यात्मक सटीकता के बजाय उसकी रचनात्मकता और प्रासंगिकता का आकलन कर सकते हैं।
इन विधियों के बीच का चुनाव विशिष्ट उपयोग के मामले पर निर्भर करता है। उदाहरण के लिए, वित्तीय रिपोर्टिंग या चिकित्सा सूचना प्रणाली सटीकता के लिए संदर्भ-आधारित मूल्यांकन की मांग करें, जबकि मार्केटिंग कंटेंट जनरेशन या रचनात्मक लेखन उपकरण टोन और स्टाइल जैसे सूक्ष्म गुणों को पकड़ने के लिए संदर्भ-मुक्त मूल्यांकन से लाभ उठाएं।
कई संगठन अपनाते हैं हाइब्रिड दृष्टिकोण, दोनों तरीकों का संयोजन। संदर्भ-आधारित मूल्यांकन तथ्यात्मक सटीकता को संभाल सकता है, जबकि संदर्भ-मुक्त तरीके रचनात्मकता या टोन जैसे पहलुओं पर ध्यान केंद्रित करते हैं। यह संयोजन एलएलएम के प्रदर्शन का संपूर्ण मूल्यांकन सुनिश्चित करता है, जिसमें मानवीय निरीक्षण से अक्सर शुद्धिकरण की एक अतिरिक्त परत जुड़ जाती है।
जबकि स्वचालित मेट्रिक्स स्थिरता प्रदान करते हैं, मानव निरीक्षण अधिक जटिल, संदर्भ-संवेदनशील मुद्दों को संबोधित करता है। मानव-इन-द-लूप सत्यापन स्वचालित प्रणालियों की दक्षता को सूक्ष्म समझ के साथ मिश्रित करता है जिसे केवल मनुष्य ही सामने ला सकते हैं।
यह दृष्टिकोण विशेष रूप से मूल्यवान है डोमेन-विशिष्ट अनुप्रयोग जैसे मेडिकल एआई, कानूनी दस्तावेज़ विश्लेषण, या वित्तीय सलाहकार उपकरण, जहां विषय वस्तु विशेषज्ञता महत्वपूर्ण है। मानव विशेषज्ञ उद्योग-विशिष्ट त्रुटियों या सूक्ष्मताओं की पहचान कर सकते हैं जो स्वचालित सिस्टम छूट सकती हैं।
मानव भागीदारी को बढ़ाने के लिए, संगठन उपयोग करते हैं नमूना लेने की रणनीतियाँ जैसे कि यादृच्छिक, स्तरीकृत, या विश्वास-आधारित नमूना। उदाहरण के लिए, स्वचालित सिस्टम द्वारा कम आत्मविश्वास के साथ फ़्लैग किए गए आउटपुट को मानव समीक्षा के लिए प्राथमिकता दी जा सकती है। इसके अतिरिक्त, विशेषज्ञ पैनल अक्सर विवादास्पद विषयों या किनारे के मामलों के लिए नियोजित होते हैं, जो नए या जटिल अनुप्रयोगों के लिए मूल्यांकन रूब्रिक को परिष्कृत करने में मदद करते हैं।
मानवीय प्रतिक्रिया भी चलाती है निरंतर सुधार के लूप। आवर्ती त्रुटियों या पैटर्न को फ़्लैग करके, मानव समीक्षक मूल्यांकन मानदंडों को परिष्कृत करने और प्रशिक्षण डेटा को बेहतर बनाने में योगदान करते हैं। यह फ़ीडबैक सुनिश्चित करता है कि एलएलएम नए प्रकार के प्रश्नों और उपयोगकर्ता की ज़रूरतों को विकसित करने के लिए अनुकूल हों।
लागतों को प्रबंधित करने योग्य बनाए रखने के लिए, मानव समीक्षा आम तौर पर उच्च प्रभाव वाले निर्णयों, विवादास्पद सामग्री या ऐसे मामलों के लिए आरक्षित होती है, जहां स्वचालित विश्वास स्कोर एक निर्धारित सीमा से नीचे आते हैं। यह लक्षित दृष्टिकोण स्केलेबिलिटी को बनाए रखते हुए मानव विशेषज्ञता का प्रभावी ढंग से लाभ उठाता है।
मानक मूल्यांकन विधियां अक्सर इस बात की अनदेखी करती हैं कि एलएलएम असामान्य या चुनौतीपूर्ण परिदृश्यों को कैसे संभालते हैं। एज केस का परीक्षण कमजोरियों को उजागर करने में मदद करता है और यह सुनिश्चित करता है कि मॉडल कम पूर्वानुमानित परिस्थितियों में मज़बूती से प्रदर्शन करें।
विरोधात्मक प्रोत्साहन कमजोरियों का परीक्षण करने का एक तरीका है, जैसे कि सुरक्षा सुविधाओं को दरकिनार करने का प्रयास, पक्षपाती सामग्री उत्पन्न करना या मनगढ़ंत जानकारी तैयार करना। नियमित प्रतिकूल परीक्षण उपयोगकर्ताओं को प्रभावित करने से पहले इन समस्याओं को पहचानने और उनका समाधान करने में मदद करता है।
मात्रा और जटिलता के साथ तनाव परीक्षण लंबे संकेतों, रैपिड-फायर प्रश्नों, या परस्पर विरोधी सूचनाओं के प्रसंस्करण की आवश्यकता वाले कार्यों का उपयोग करके एलएलएम को उनकी सीमा तक धकेलता है। इस प्रकार के परीक्षण से पता चलता है कि प्रदर्शन कहाँ ख़राब होने लगता है और परिचालन सीमाओं को स्थापित करने में मदद करता है।
डोमेन सीमा परीक्षण यह जांचता है कि एलएलएम अपनी विशेषज्ञता के क्षेत्र से बाहर के संकेतों पर कितनी अच्छी प्रतिक्रिया देते हैं। उदाहरण के लिए, चिकित्सा अनुप्रयोगों के लिए डिज़ाइन किए गए मॉडल का परीक्षण उन संकेतों के साथ किया जा सकता है जो धीरे-धीरे असंबंधित क्षेत्रों में स्थानांतरित हो जाते हैं। इन सीमाओं को समझने से वास्तविक अपेक्षाएं निर्धारित करने और सुरक्षा उपायों को लागू करने में मदद मिलती है।
प्रासंगिक तनाव परीक्षण मूल्यांकन करता है कि विस्तारित वार्तालाप या बहु-चरणीय कार्यों के दौरान एलएलएम कितनी अच्छी तरह सुसंगतता और सटीकता बनाए रखते हैं। यह उन अनुप्रयोगों के लिए विशेष रूप से उपयोगी है जिन्हें निरंतर संदर्भ बनाए रखने की आवश्यकता होती है।
Prompts.ai जैसे प्लेटफ़ॉर्म टीमों को डिज़ाइन करने की अनुमति देकर व्यवस्थित एज केस परीक्षण को सक्षम करते हैं संरचित वर्कफ़्लो जो स्वचालित रूप से चुनौतीपूर्ण परिदृश्य उत्पन्न करते हैं और लगातार मूल्यांकन मानकों को लागू करते हैं। इस स्वचालन से नियमित रूप से तनाव परीक्षण करना, तैनाती से पहले संभावित समस्याओं का पता लगाना आसान हो जाता है।
सिंथेटिक डेटा जनरेशन बड़े पैमाने पर विविध, चुनौतीपूर्ण परिदृश्य बनाकर एज केस परीक्षण का भी समर्थन करता है। एलएलएम अपने स्वयं के टेस्ट केस भी उत्पन्न कर सकते हैं, जो मानव परीक्षकों की तुलना में एज केस की एक विस्तृत श्रृंखला पेश करते हैं। यह दृष्टिकोण व्यापक कवरेज सुनिश्चित करता है और टीमों को विभिन्न प्रकार के इनपुटों में कमजोरियों की पहचान करने में मदद करता है।
इन परीक्षणों से प्राप्त अंतर्दृष्टि दोनों का मार्गदर्शन करती है मॉडल का चयन और प्रॉम्प्ट इंजीनियरिंग। टीमें ऐसे मॉडल चुन सकती हैं जो विशिष्ट चुनौतियों के लिए बेहतर तरीके से सुसज्जित हों और त्रुटियों को कम करने के लिए संकेतों को परिष्कृत करें, जिससे विभिन्न अनुप्रयोगों में मजबूत प्रदर्शन सुनिश्चित हो सके।
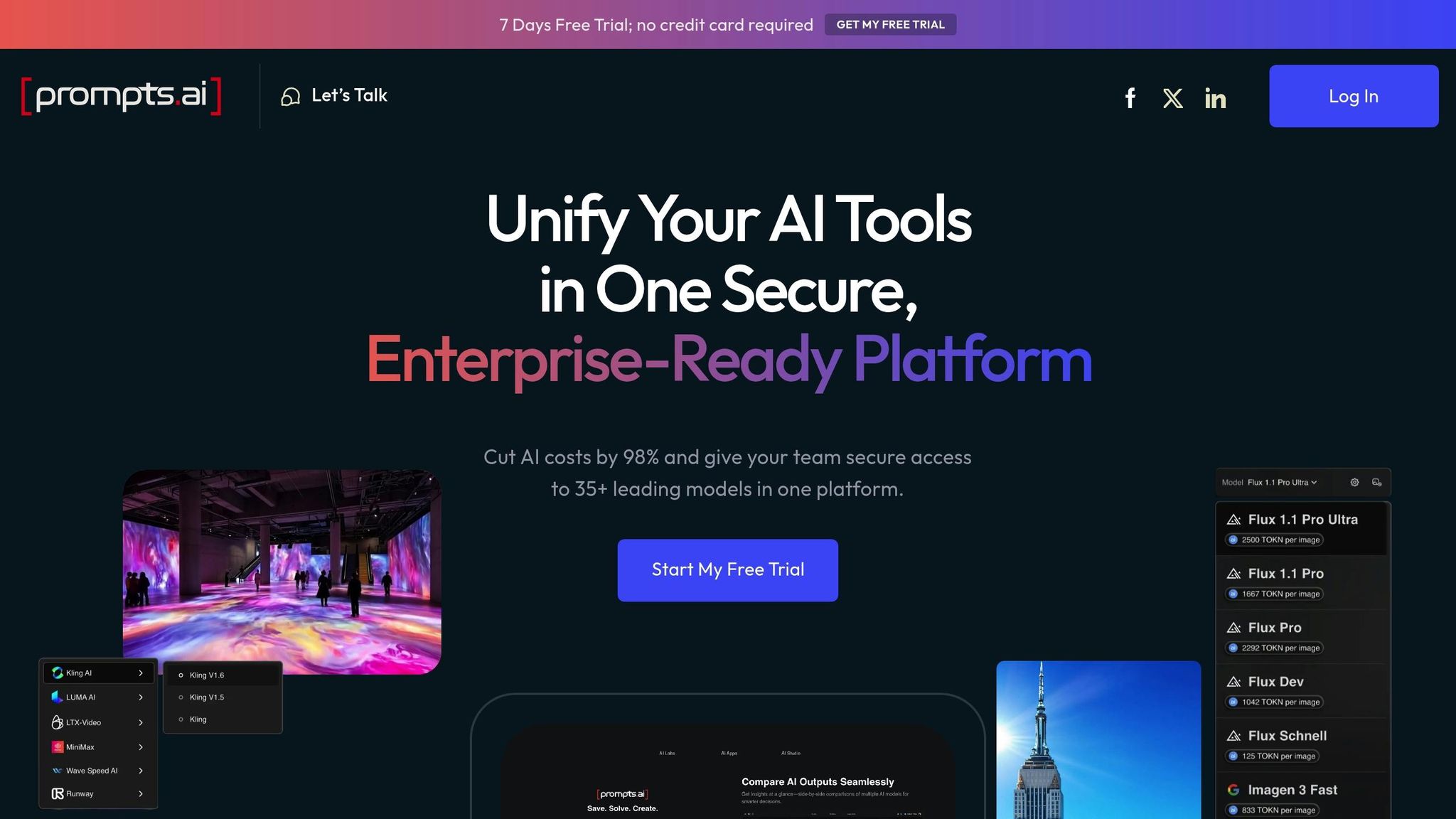
Prompts.ai 35 से अधिक प्रमुख मॉडलों तक पहुंच को एकल, सुरक्षित प्लेटफ़ॉर्म में मर्ज करके बड़े भाषा मॉडल (LLM) के मूल्यांकन को सुव्यवस्थित करता है। यह एकीकृत दृष्टिकोण कई उपकरणों की बाजीगरी की आवश्यकता को समाप्त करता है, जिससे टीमों के लिए - फॉर्च्यून 500 कंपनियों से लेकर अनुसंधान संस्थानों तक - अनुपालन बनाए रखते हुए और जटिलता को कम करते हुए आकलन करना आसान हो जाता है।
Prompts.ai लचीला वर्कफ़्लो प्रदान करता है जो टीमों को उनके विशिष्ट आंतरिक मानकों के साथ संरेखित मूल्यांकन प्रक्रियाओं को डिज़ाइन करने की अनुमति देता है। यह संरचित दृष्टिकोण एलएलएम आउटपुट के सुसंगत और दोहराए जाने वाले आकलन को सुनिश्चित करता है। संगठनों को बजट पर बने रहने में मदद करने के लिए, प्लेटफ़ॉर्म में एकीकृत लागत ट्रैकिंग शामिल है, जो मूल्यांकन खर्चों में वास्तविक समय की अंतर्दृष्टि प्रदान करती है। ये सुविधाएँ एक ऐसा वातावरण बनाती हैं जहाँ क्रॉस-मॉडल तुलनाएँ कुशल और प्रभावी दोनों होती हैं।
प्लेटफ़ॉर्म का इंटरफ़ेस सीधे एलएलएम की तुलना करना आसान बनाता है। उपयोगकर्ता एक ही प्रॉम्प्ट को कई मॉडलों को भेज सकते हैं और पूर्वनिर्धारित मानदंडों के आधार पर अपनी प्रतिक्रियाओं का मूल्यांकन कर सकते हैं। अंतर्निहित गवर्नेंस टूल और पारदर्शी लागत रिपोर्टिंग के साथ, टीमें समय के साथ प्रदर्शन की निगरानी कर सकती हैं और डेटा-संचालित निर्णय ले सकती हैं जो उनके अद्वितीय परिचालन लक्ष्यों के अनुरूप हों।
पहले चर्चा की गई मुख्य मैट्रिक्स और विधियों के आधार पर, सही मूल्यांकन रणनीति का चयन करना आपके विशिष्ट उपयोग के मामले, उपलब्ध संसाधनों और गुणवत्ता की अपेक्षाओं पर निर्भर करता है। सटीकता और दक्षता के बीच संतुलन बनाने के लिए अलग-अलग तरीकों को तौलना आवश्यक है, ताकि यह सुनिश्चित हो सके कि मूल्यांकन विश्वसनीय और सरल बने रहें।
प्रत्येक मूल्यांकन पद्धति की अपनी ताकत और सीमाएं होती हैं, जो उन्हें विभिन्न परिदृश्यों के लिए उपयुक्त बनाती हैं। नीचे दी गई तालिका सामान्य दृष्टिकोणों के प्रमुख पहलुओं की रूपरेखा तैयार करती है:
व्यवहार में, हाइब्रिड दृष्टिकोण अक्सर सबसे अच्छे परिणाम देते हैं। उदाहरण के लिए, कई संगठन स्पष्ट विफलताओं को खत्म करने के लिए स्वचालित स्क्रीनिंग से शुरू करते हैं और फिर सीमा रेखा के मामलों में मानव समीक्षा लागू करते हैं। यह संयोजन गुणवत्ता से समझौता किए बिना दक्षता सुनिश्चित करता है।
बढ़ती मात्रा और जटिलता को प्रबंधित करने के लिए, उच्च-गुणवत्ता वाले मानकों को बनाए रखते हुए बड़े पैमाने पर वर्कफ़्लो डिज़ाइन करना महत्वपूर्ण है। यहां बताया गया है कि इसे कैसे हासिल किया जाए:
बड़े भाषा मॉडल (LLM) का मूल्यांकन करने के लिए एक संरचित दृष्टिकोण अपनाना भरोसेमंद AI वर्कफ़्लो सुनिश्चित करता है जो लगातार व्यावसायिक उद्देश्यों को पूरा करता है। व्यवस्थित मूल्यांकन प्रक्रियाओं को अपनाने वाले संगठनों को मॉडल के प्रदर्शन, कम परिचालन जोखिम, और AI आउटपुट और उनके लक्ष्यों के बीच मजबूत संरेखण में मापने योग्य सुधार प्राप्त होते हैं। यह फाउंडेशन पहले चर्चा की गई स्केलेबल और सटीक मूल्यांकन विधियों का समर्थन करता है।
एड-हॉक टेस्टिंग से दूर जाना संरचित मूल्यांकन ढांचे AI परिनियोजन में क्रांति लाती है। टीमें मॉडल चयन, शीघ्र परिशोधन और गुणवत्ता बेंचमार्क के बारे में सूचित, डेटा-समर्थित निर्णय ले सकती हैं। यह तेजी से आवश्यक हो जाता है क्योंकि AI का विस्तार विभिन्न विभागों और उपयोग के मामलों में होता है।
इन मूल्यांकन मेट्रिक्स के साथ, Prompts.ai स्केलेबल आकलन के लिए एक व्यावहारिक और कुशल समाधान प्रदान करता है। प्लेटफ़ॉर्म कस्टम स्कोरिंग फ़्लो, एज केस सिमुलेशन, और कई प्रमुख मॉडलों में प्रदर्शन ट्रैकिंग के लिए टूल प्रदान करके मूल्यांकन को सरल बनाता है - ये सभी एक एकीकृत सिस्टम के भीतर हैं।
सटीक मूल्यांकन के लाभ तत्काल गुणवत्ता लाभ से काफी आगे तक फैले हुए हैं। मजबूत फ्रेमवर्क वाले संगठन विशिष्ट कार्यों में उत्कृष्ट मॉडल और संकेतों की पहचान करके निवेश पर उच्च रिटर्न (ROI) प्राप्त करते हैं। अनुपालन अधिक सरल हो जाता है क्योंकि प्रत्येक AI इंटरैक्शन को ट्रैक किया जाता है और निर्धारित मानदंडों के अनुसार मापा जाता है। निरंतर प्रदर्शन अनुकूलन प्रतिक्रियाशील सुधारों को बदल देता है, जिससे टीमों को उपयोगकर्ताओं को प्रभावित करने से पहले संभावित समस्याओं को पकड़ने और उनका समाधान करने में मदद मिलती है।
शायद सबसे महत्वपूर्ण बात यह है कि संरचित मूल्यांकन पूरे संगठन में AI को अधिक सुलभ बनाते हैं। जब मूल्यांकन मानदंड स्पष्ट होते हैं और लगातार लागू होते हैं, तो आउटपुट की गुणवत्ता का आकलन करने या सूचित परिनियोजन निर्णय लेने के लिए टीमों को गहन तकनीकी विशेषज्ञता की आवश्यकता नहीं होती है। यह स्पष्टता एंटरप्राइज़ अनुप्रयोगों के लिए आवश्यक उच्च मानकों को बनाए रखते हुए अपनाने को प्रोत्साहित करती है।
जनरेटिव AI मॉडल के आउटपुट का मूल्यांकन करना कोई छोटा काम नहीं है। चुनौतियां जैसे तथ्यात्मक अशुद्धियाँ, पक्षपात, दु: स्वप्न, और असंगत प्रतिक्रियाएँ बड़े भाषा मॉडल (एलएलएम) के अप्रत्याशित व्यवहार के कारण उत्पन्न हो सकता है।
इन मुद्दों से प्रभावी ढंग से निपटने के लिए एक संरचित दृष्टिकोण महत्वपूर्ण है। विभिन्न मैट्रिक्स का संयोजन - जैसे कि तथ्यात्मक सटीकता, स्पष्टता और व्यावहारिक उपयोगिता - के साथ मानवीय निर्णय अधिक संतुलित और गहन मूल्यांकन प्रदान करता है। इसके अतिरिक्त, परिभाषित प्रोटोकॉल का उपयोग करके एज केस और यथार्थवादी परिदृश्यों के तहत मॉडल का परीक्षण कमजोरियों को उजागर कर सकता है और उनकी प्रतिक्रियाओं की विश्वसनीयता में सुधार कर सकता है। ये रणनीतियां मूल्यांकन को अधिक सटीक और कार्रवाई योग्य बनाने में मदद करती हैं, जिससे बेहतर प्रदर्शन का मार्ग प्रशस्त होता है।
Prompts.ai इसके साथ LLM आउटपुट का मूल्यांकन सरल बनाता है संरचित स्कोरिंग टूल और अनुकूलन योग्य मूल्यांकन रूब्रिक। बैच प्रॉम्प्ट एक्जीक्यूशन और एजेंट चेनिंग जैसी क्षमताओं के साथ, यूज़र को जटिल कार्यों को छोटे, आसानी से संभालने वाले चरणों में तोड़कर उनसे निपटने में सक्षम बनाती हैं। यह दृष्टिकोण सुनिश्चित करता है कि मूल्यांकन सुसंगत, मापनीय और सटीक बने रहें।
35 से अधिक एलएलएम के समर्थन के साथ, प्लेटफ़ॉर्म विभिन्न मॉडलों से आउटपुट की तुलना करने और उनका आकलन करने के लिए एक लचीला समाधान प्रदान करता है। यह रिसर्च लैब्स, AI ट्रेनर्स और QA लीड के लिए विशेष रूप से उपयुक्त है, जिन्हें तथ्यात्मक सटीकता, स्पष्टता और पूर्वाग्रह जैसे प्रमुख पहलुओं का मूल्यांकन करने के लिए भरोसेमंद तरीकों की आवश्यकता होती है - साथ ही वे मतिभ्रम दर को कम करने के लिए भी काम करते हैं।
बैलेंसिंग स्वचालित उपकरण साथ मानव समीक्षा बड़े भाषा मॉडल (एलएलएम) से आउटपुट का पूरी तरह से मूल्यांकन करने के लिए आवश्यक है। बड़ी मात्रा में डेटा को तेज़ी से प्रोसेस करने, पैटर्न का पता लगाने और गुणवत्ता में कम होने वाली प्रतिक्रियाओं को फ़्लैग करने में स्वचालित टूल बेजोड़ हैं। हालांकि, वे सूक्ष्म पूर्वाग्रहों, प्रासंगिक बारीकियों, या जटिल अशुद्धियों जैसे बारीक विवरणों से चूक सकते हैं।
यह वह जगह है जहाँ मानवीय निर्णय आता है। मनुष्य आलोचनात्मक सोच और संदर्भ की गहरी समझ लाते हैं, जिससे यह सुनिश्चित होता है कि आउटपुट न केवल सटीक हों बल्कि निष्पक्ष और व्यावहारिक भी हों। स्वचालन की दक्षता को मानव निरीक्षण के विचारशील विश्लेषण के साथ जोड़कर, यह दृष्टिकोण सुनिश्चित करता है कि मूल्यांकन भरोसेमंद और संपूर्ण दोनों हों। साथ में, वे एलएलएम के प्रदर्शन का प्रभावी ढंग से आकलन करने के लिए सही संतुलन बनाते हैं।


















