Pay As You GoEssai gratuit de 7 jours ; aucune carte de crédit requise


Astuce rapide: Un processus de test structuré et reproductible garantit non seulement une meilleure sélection de modèles, mais favorise également l'évolutivité et la gouvernance de vos projets d'IA.
Le choix du bon modèle de langage étendu (LLM) dépend de l'évaluation des indicateurs qui ont un impact direct sur les performances. En se concentrant sur des facteurs mesurables, les équipes peuvent prendre de meilleures décisions et éviter des faux pas coûteux. Le défi consiste à identifier les indicateurs les plus importants pour votre cas d'utilisation spécifique et à comprendre comment ils se traduisent en performances pratiques.
En matière de précision, plusieurs critères de référence sont couramment utilisés pour évaluer les capacités d'un LLM :
L'écart de performance entre les modèles peut être important. Par exemple, GPT-4 a atteint une précision de 95,3 % sur Hellas Swag en 2024, alors que le GPT-3 n'a enregistré qu'un taux de réussite de 58 % avec TruthfulQA, contre un taux de référence humain de 94 %. Bien que ces points de référence constituent un point de départ solide, les équipes doivent également concevoir des tests spécifiques à un domaine qui correspondent à leurs besoins commerciaux uniques.
Le temps de réponse et les coûts liés aux jetons sont des indicateurs critiques qui influencent à la fois l'expérience utilisateur et le budget. Un modèle dont la réponse ne prend que quelques secondes peut être utile pour les recherches internes, mais peut ne pas convenir aux applications destinées aux clients. De même, les coûts de jetons élevés peuvent devenir une dépense importante dans les scénarios à volume élevé.
Les exigences de vitesse dépendent de l'application. Les cas d'utilisation en temps réel nécessitent souvent des temps de réponse inférieurs à la seconde, tandis que les tâches de traitement par lots peuvent supporter des délais plus longs. Les indicateurs clés à surveiller incluent le temps de réponse (délai jusqu'au premier jeton) et le nombre de jetons par seconde, afin d'aider les équipes à trouver un équilibre entre performances et coûts.
Lorsque vous évaluez les coûts, ne vous contentez pas de vous contenter de la tarification symbolique. Tenez également compte des dépenses opérationnelles. Des outils tels que prompts.ai peut aider à suivre ces indicateurs en temps réel, en fournissant des informations sur les compromis entre les coûts et les performances.
Au-delà de la vitesse et du coût, d'autres facteurs tels que la capacité contextuelle et les options de personnalisation jouent un rôle important dans la facilité d'utilisation d'un modèle.
La taille de la fenêtre contextuelle détermine la quantité d'informations qu'un modèle peut traiter en une seule interaction. Par exemple, un modèle avec une fenêtre de 4 000 jetons peut fonctionner pour de courtes conversations, mais le traitement de longs documents tels que des contrats juridiques ou des articles de recherche nécessite souvent une fenêtre de 32 000 jetons ou plus.
Les options de formation personnalisées permettent aux équipes d'affiner les modèles préentraînés pour des tâches spécifiques. Cela améliore à la fois la précision et la pertinence pour un domaine donné. Des techniques telles que le réglage fin efficace des paramètres réduisent les exigences de calcul sans sacrifier les performances. D'autres méthodes, telles que le réglage des instructions et l'apprentissage par renforcement, permettent d'affiner le comportement d'un modèle.
Pour les équipes qui ont besoin d'un accès à des données externes, Retrieval Augmented Generation (RAG) propose une autre solution. RAG intègre des sources de connaissances externes pour étayer les réponses du modèle, contribuant ainsi à réduire les hallucinations et à améliorer la précision. Le choix entre le réglage fin et le RAG dépend de vos besoins : le réglage fin fonctionne mieux lorsque vous disposez de suffisamment de données étiquetées pour personnaliser le modèle, tandis que RAG est idéal pour les scénarios comportant des données limitées et nécessitant des mises à jour continues.
Des plateformes comme prompts.ai peut rationaliser les tests et la validation de ces mesures, ce qui facilite l'évaluation des performances d'un modèle dans des contextes pratiques.
Pour comparer efficacement les grands modèles linguistiques (LLM), il est essentiel de suivre un flux de travail structuré avec des tests répétables qui fournissent des informations claires et exploitables. Un élément clé de ce processus consiste à utiliser des instructions identiques pour tous les modèles afin de mettre en évidence les différences.
L'épine dorsale de toute comparaison LLM consiste à tester la même invite sur plusieurs modèles simultanément. Cette méthode révèle comment chaque modèle aborde des tâches identiques, aidant à identifier des problèmes tels que des hallucinations ou des résultats incohérents.
Par exemple, si quatre modèles fournissent des réponses similaires et que l'un produit un résultat significativement différent, la valeur aberrante peut indiquer une erreur. Les modèles établis s'alignent généralement sur des informations factuelles, de sorte que les écarts mettent souvent en évidence des inexactitudes.
Des outils tels que Prompts.ai simplifiez ce processus en permettant aux équipes de tester des instructions identiques sur plus de 35 modèles de pointe, notamment GPT-4, Claude, LLama et Gémeaux - le tout à partir d'une seule interface. Au lieu de passer manuellement d'une plateforme à l'autre, les utilisateurs peuvent consulter les résultats côte à côte en temps réel.
« Tester votre invite par rapport à plusieurs modèles est un excellent moyen de déterminer quel modèle vous convient le mieux dans un cas d'utilisation spécifique », explique Nick Grato, un artiste de Prompt.
Pour les tâches plus complexes, pensez à les diviser en sous-tâches plus petites à l'aide de chaînage rapide. Cela implique de diviser un objectif plus large en instructions individuelles exécutées dans une séquence prédéfinie. En utilisant une structure à invite fixe, vous garantissez des comparaisons équitables entre les modèles et vous maintenez la cohérence des formats d'entrée. Une fois les réponses recueillies, suivez l'incidence des mises à jour des modèles sur les résultats au fil du temps.
Les fournisseurs mettent fréquemment à jour leurs LLM, ce qui peut avoir un impact sur les performances. Pour garder une longueur d'avance sur ces changements, documentez les détails des versions et surveillez les tendances en matière de performances à l'aide de mesures de référence et de calendriers automatisés.
Prompts.ai répond à ce défi grâce à des évaluations versionnées qui suivent les performances des modèles au fil du temps. Les équipes peuvent définir des indicateurs de référence et recevoir des alertes lorsque des mises à jour entraînent des changements de performances notables, ce qui les aide à s'adapter rapidement. Les programmes de tests automatisés proposent des points de contrôle réguliers, garantissant le maintien des normes de qualité dans les différentes versions des modèles.
Les outils visuels tels que les graphiques et les tableaux permettent de repérer plus facilement les tendances relatives à des indicateurs tels que le temps de réponse, la précision, le coût des jetons et les taux d'hallucinations.
Par exemple, considérez un tableau comparant les indicateurs clés des différents modèles :
Les graphiques, tels que les graphiques linéaires pour suivre les changements de précision ou les diagrammes à barres pour comparer les coûts, constituent un moyen rapide d'analyser les tendances et de prendre des décisions éclairées. Prompts.ai inclut des outils intégrés qui génèrent automatiquement ces visualisations à partir des résultats des tests, réduisant ainsi les efforts manuels et accélérant le processus de prise de décision.
Lorsqu'elles comparent de grands modèles linguistiques (LLM), les équipes doivent souvent choisir entre des outils de test autonomes et des solutions de plateforme intégrées. Chaque option a son propre impact sur l'efficacité des tests et la qualité des résultats.
Des outils spécialisés sont couramment utilisés pour évaluer les performances du LLM. Prendre Harnais LM, par exemple, il fournit un cadre pour exécuter des benchmarks standardisés sur différents modèles. Il est particulièrement efficace pour les benchmarks académiques tels que MMLU et ARC. Cependant, sa mise en œuvre nécessite une solide formation technique, ce qui peut représenter un défi pour certaines équipes.
Un autre exemple est le Classement OpenLLM, qui classe publiquement les modèles sur la base de tests standardisés. Ces classements donnent un aperçu rapide des performances globales du modèle. Mais voici le hic : les modèles qui donnent de bons résultats sur les benchmarks publics ne répondent pas nécessairement aux exigences de cas d'utilisation commerciaux spécifiques.
L'un des principaux inconvénients des outils de test traditionnels est leur recours à un affinement manuel rapide, ce qui peut entraîner des incohérences et des inefficacités. Leurs interfaces génériques manquent souvent de flexibilité, ce qui rend plus difficile l'adaptation à des scénarios de test uniques. Cette approche fragmentée met en évidence les limites des outils autonomes et la nécessité d'une solution plus unifiée.
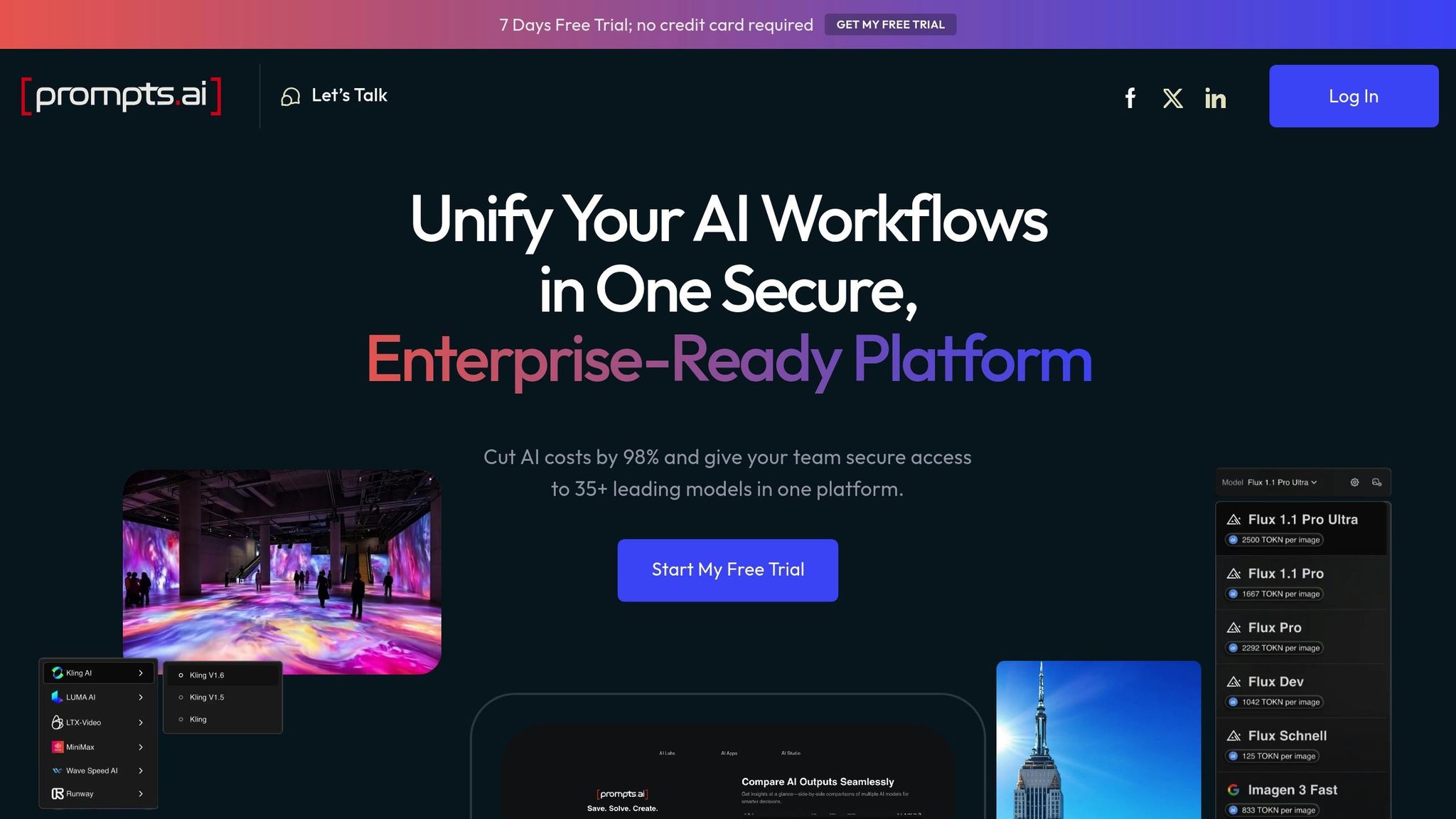
Les plateformes intégrées offrent un moyen plus rationalisé de relever les défis posés par les outils autonomes. Par exemple, Prompts.ai combine les tests, le suivi des coûts et la gouvernance dans une interface unique. Il prend en charge plus de 35 modèles de pointe, dont GPT-4, Claude, LLama et Gemini, le tout dans un environnement sécurisé.
L'un des principaux avantages des plateformes centralisées est la possibilité d'exécuter des instructions identiques sur plusieurs modèles simultanément. Cela garantit des conditions de test cohérentes et élimine les conjectures.
La surveillance des coûts en temps réel change également la donne, car elle élimine le besoin de suivi manuel et permet d'optimiser les dépenses.
Les fonctionnalités de gouvernance, telles que les évaluations versionnées, garantissent la conformité et la cohérence dans le temps. En tant que Conor Kelly, responsable de la croissance chez Boucle humaine, le dit :
« Les entreprises qui investissent dans de grands modèles linguistiques doivent reconnaître que les mesures d'évaluation LLM ne sont plus facultatives, mais essentielles pour des performances fiables et une conformité robuste ».
Les avantages ne s'arrêtent pas aux sessions de tests individuelles. Jack Bowen, fondateur et PDG de CoLoop, ajoute :
« À long terme, je pense que nous verrons l'IA devenir « un simple logiciel », comme les premiers outils SaaS étaient principalement intégrés à des bases de données. Oui, vous pouvez créer n'importe quoi avec Excel, Airtable et Zapier, mais les gens ne le font pas, car ils apprécient le temps, l'assistance et la concentration ».
Les outils d'IA spécialement conçus permettent également de réduire le temps consacré à la recherche, à la configuration et à la maintenance. Pour les équipes effectuant des évaluations fréquentes ou gérant plusieurs projets d'IA, le temps gagné justifie souvent l'investissement. Il s'agit d'une solution pratique pour rester efficace et concentré dans un environnement d'IA de plus en plus complexe.
Même les équipes d'IA les plus expérimentées peuvent échouer lorsqu'elles comparent de grands modèles linguistiques (LLM). Ces faux pas peuvent conduire à choisir le mauvais modèle, à faire exploser les budgets ou même à échouer des déploiements. Pour éviter ces écueils, il est essentiel d'adopter une approche disciplinée en matière de tests. Examinons quelques erreurs et compromis courants auxquels les équipes sont confrontées lors de l'évaluation des LLM.
Choisir entre des LLM open source et des LLM à code source fermé est l'une des décisions les plus importantes que prennent les équipes d'IA. Chaque option possède ses propres forces et défis, qui façonnent directement votre processus de test.
Prenons les modèles open source tels que LLAMA-3-70-B, par exemple. Ils sont nettement moins chers : les jetons d'entrée coûtent environ 0,60$ par million et les jetons de sortie coûtent 0,70$ par million. Comparez cela à ChatGPT-4, qui facture environ 10 dollars par million de jetons d'entrée et 30 dollars par million de jetons de sortie. Pour les équipes chargées d'un traitement de texte intensif, ces différences de coûts peuvent s'accumuler rapidement.
Les modèles open source offrent également une transparence et une flexibilité inégalées. Vous bénéficiez d'un accès complet à l'architecture du modèle et aux données d'entraînement, ce qui vous permet de contrôler totalement le déploiement. Mais voici le hic : vous aurez besoin d'une expertise technique pour gérer l'infrastructure, la sécurité et la maintenance. De plus, au lieu de faire appel à l'assistance d'un fournisseur, vous vous fiez souvent à la communauté open source pour obtenir de l'aide.
D'autre part, les modèles à source fermée tels que GPT-4 et Claude sont connus pour leur fiabilité et leur facilité d'utilisation. Ils offrent des performances constantes, sont assortis d'accords de niveau de service et gèrent pour vous des problèmes critiques tels que la sécurité, la conformité et l'évolutivité.
Il est intéressant de constater que le marché évolue. Les modèles à source fermée dominent actuellement avec 80 % à 90 % de la part, mais l'avenir semble plus équilibré. En fait, 41 % des entreprises prévoient de renforcer leur utilisation de modèles open source, tandis que 41 % sont prêtes à changer si les performances correspondent à celles des modèles fermés.
Le Dr Barak Or le résume bien :
« Dans un monde où l'intelligence est programmable, le contrôle est une stratégie. Et la stratégie n'est ni ouverte ni fermée, c'est les deux, à dessein. »
De nombreuses équipes adoptent désormais des stratégies hybrides. Ils utilisent des modèles à source fermée pour les applications destinées aux clients où la fiabilité est essentielle, tout en expérimentant des modèles open source pour des outils internes et des projets exploratoires.
Les biais dans les tests peuvent faire échouer même les meilleurs efforts d'évaluation. Il est facile de tomber dans le piège qui consiste à concevoir des conditions de test qui favorisent les points forts d'un modèle tout en ignorant les autres, ce qui entraîne des résultats faussés.
Par exemple, une start-up a lancé un chatbot à l'aide d'un LLM basé sur le cloud sans tester son évolutivité. À mesure que le nombre d'utilisateurs augmentait, les temps de réponse se sont considérablement ralentis, ce qui a frustré les utilisateurs et terni la réputation du produit. Une évaluation plus approfondie, y compris des tests d'évolutivité, aurait pu les amener à choisir un modèle plus léger ou une configuration hybride.
Se fier uniquement aux scores de référence est une autre erreur courante. Les modèles qui brillent lors de tests standardisés tels que MMLU ou ARC peuvent ne pas fonctionner correctement dans vos scénarios spécifiques. Les critères académiques ne reflètent souvent pas les exigences de domaines spécialisés ou de styles rapides uniques.
Le biais des données de formation constitue une autre source de préoccupation. Cela peut donner lieu à des stéréotypes néfastes ou à des réponses inappropriées pour certaines communautés. Pour y remédier, les équipes doivent créer des ensembles de données de test diversifiés et représentatifs qui correspondent à des cas d'utilisation réels, y compris des cas extrêmes et des instructions variées.
Et n'oubliez pas les coûts cachés, un autre domaine dans lequel les équipes se trompent souvent.
Se concentrer uniquement sur la tarification par jeton peut donner aux équipes une fausse idée du coût total de possession. Les modèles open source, par exemple, peuvent sembler gratuits à première vue, mais les coûts d'infrastructure peuvent rapidement s'accumuler. Les GPU, les instances cloud, les transferts de données et les systèmes de sauvegarde font tous grimper la facture.
Un fournisseur SaaS l'a appris à ses dépens. Ils ont choisi un LLM propriétaire avec facturation par jeton, s'attendant à une utilisation modérée. Mais à mesure que leur application gagnait en popularité, les coûts mensuels sont montés en flèche, passant de centaines à des dizaines de milliers de dollars, ce qui a réduit leurs bénéfices. Une approche hybride, utilisant des modèles open source pour les tâches de base et des modèles premium pour les requêtes complexes, aurait pu maîtriser les coûts.
Parmi les autres facteurs négligés, citons les retards des API, les problèmes de fiabilité liés à de lourdes charges et les défis d'intégration qui peuvent allonger les délais de déploiement. Les conditions de licence, les exigences de conformité et les mesures de sécurité peuvent également entraîner des dépenses imprévues.
Pour éviter ces surprises, les équipes doivent bien planifier. Mappez les fonctionnalités du modèle en fonction de vos cas d'utilisation réels, estimez des charges d'utilisateurs réalistes et évaluez le coût total de possession. En abordant la sécurité et la conformité dès le départ, vous serez mieux placé pour prendre des décisions éclairées qui résisteront à l'épreuve du temps.
L'évaluation systématique des grands modèles linguistiques (LLM) n'est pas seulement un exercice technique, c'est une décision stratégique qui peut influencer de manière significative les retour sur investissement, gouvernance, et évolutivité. Les équipes qui adoptent des processus d'évaluation structurés constatent souvent d'importantes réductions de coûts et de meilleurs résultats en termes de performance.
Voici un exemple de l'impact potentiel : le passage à une configuration de modèle mieux optimisée pourrait permettre d'économiser des dizaines de milliers de dollars chaque mois tout en fournissant des réponses plus rapides et une latence plus faible pour les applications d'IA conversationnelle.
La gouvernance devient beaucoup plus simple lorsque vous centralisez les données relatives aux performances, aux coûts et à l'utilisation des modèles. Au lieu de vous fier à des décisions ponctuelles et incohérentes, vous créerez une piste d'audit claire qui favorise la conformité et la responsabilité. Cela est particulièrement important pour les secteurs où les réglementations exigent une documentation détaillée de chaque décision liée à l'IA.
Une fois la gouvernance maîtrisée, la mise à l'échelle devient beaucoup plus facile. La comparaison systématique favorise naturellement l'évolutivité. Au fur et à mesure que vos efforts en matière d'IA s'intensifieront, vous n'aurez pas à réinventer la roue pour chaque nouveau projet. Les benchmarks, les mesures et les flux de travail que vous avez déjà développés peuvent être réutilisés, ce qui permet d'accélérer les décisions et de minimiser les risques. Les nouveaux membres de l'équipe peuvent rapidement comprendre pourquoi des modèles spécifiques ont été sélectionnés et comment les alternatives sont évaluées.
Les évaluations versionnées et répétables constituent la base d'une stratégie d'IA fiable. L'exécution de demandes identiques sur plusieurs LLM et le suivi de leurs réponses au fil du temps renforcent les connaissances institutionnelles. Cette approche vous permet de détecter rapidement les problèmes de performances, de découvrir des opportunités de réduction des coûts et de prendre des décisions éclairées concernant les mises à niveau ou les modifications de modèle.
Commencez dès aujourd'hui avec votre tableau de bord de comparaison LLM en explorant des plateformes comme prompts.ai. Concentrez-vous sur vos cas d'utilisation les plus critiques, établissez des indicateurs de référence tels que la précision, la latence et le coût par million de jetons, et comparez au moins cinq modèles côte à côte. De tels outils vous permettent de surveiller les réponses, de signaler les hallucinations et de maintenir le contrôle des versions, révolutionnant ainsi la façon dont vous abordez la sélection des modèles. Cette stratégie unifiée améliore non seulement la sélection des modèles, mais renforce également la gouvernance de l'IA.
Investir dès maintenant dans des méthodes d'évaluation structurées permettra à votre équipe de se démarquer. Ceux qui accordent la priorité à une infrastructure d'évaluation appropriée aujourd'hui seront les leaders de leur secteur de demain, en profitant des avantages d'une précision accrue, d'une gouvernance simplifiée et d'une évolutivité sans effort.
Lors de l'évaluation de grands modèles linguistiques (LLM), il est important d'utiliser mesures standardisées afin de garantir une comparaison équitable. Des indicateurs tels que la précision (par exemple, MMLU, ARC, TruthfulQA), la latence, le coût par million de jetons et la taille de la fenêtre contextuelle constituent une base solide pour évaluer les performances. Au-delà des indicateurs, les tests devraient impliquer flux de travail cohérents et reproductibles, où des instructions identiques sont exécutées sur différents modèles pour détecter les incohérences ou les hallucinations.
L'utilisation d'outils conçus pour des tests rapides à grande échelle peut aider à maintenir les comparaisons objectif et bien documenté. Il est essentiel d'éviter les pièges tels que le fait de sélectionner des instructions ou d'évaluer des modèles sur des tâches qui ne sont pas prévues. Une approche systématique et équitable permet de mettre clairement en évidence les forces et les limites de chaque modèle.
À l'aide d'une plateforme telle que prompts.ai permet de tester et de comparer de grands modèles de langage (LLM) beaucoup plus simples. Il garantit que les évaluations de plusieurs modèles sont cohérentes et répétables, ce qui permet des comparaisons justes et impartiales. En centralisant le processus de test, vous pouvez facilement surveiller les réponses des modèles, détecter les problèmes tels que les hallucinations et évaluer les indicateurs de performance clés, notamment la précision, le temps de réponse et le coût.
Cette méthode efficace permet non seulement de gagner un temps précieux, mais elle permet également de prendre de meilleures décisions lorsqu'il s'agit de choisir le modèle adapté à vos besoins. Grâce à des fonctionnalités de gestion des versions et de gestion de tests à grande échelle, des outils tels que prompts.ai permettent aux équipes d'IA de déployer des solutions plus fiables et plus efficaces.
Les grands modèles linguistiques (LLM) open source peuvent sembler économiques à première vue, mais ils comportent souvent des coûts cachés. Il s'agit notamment des dépenses liées à la configuration de l'infrastructure, à la maintenance continue et à la mise à l'échelle. Les équipes peuvent également rencontrer des obstacles tels qu'une complexité technique accrue, des options de support limitées et des failles de sécurité potentielles. Le dépannage et l'hébergement de tels modèles peuvent rapidement faire grimper les coûts opérationnels.
D'un autre côté, les LLM à code source fermé offrent généralement des systèmes de support plus robustes, des mises à jour plus rapides et des garanties de performances cohérentes. Cependant, ces avantages s'accompagnent de frais de licence. Pour choisir entre les deux, vous devez examiner attentivement les capacités techniques, les contraintes budgétaires et les objectifs à long terme de votre équipe.


















