Pay As You Go - AI Model Orchestration and Workflows Platform


Choosing the right AI tool to evaluate large language models (LLMs) can save time, reduce costs, and improve decision-making. With dozens of models available - like GPT-5, Claude, and LLaMA - organizations face challenges in comparing performance, accuracy, and cost-efficiency. Five platforms stand out for simplifying this process:
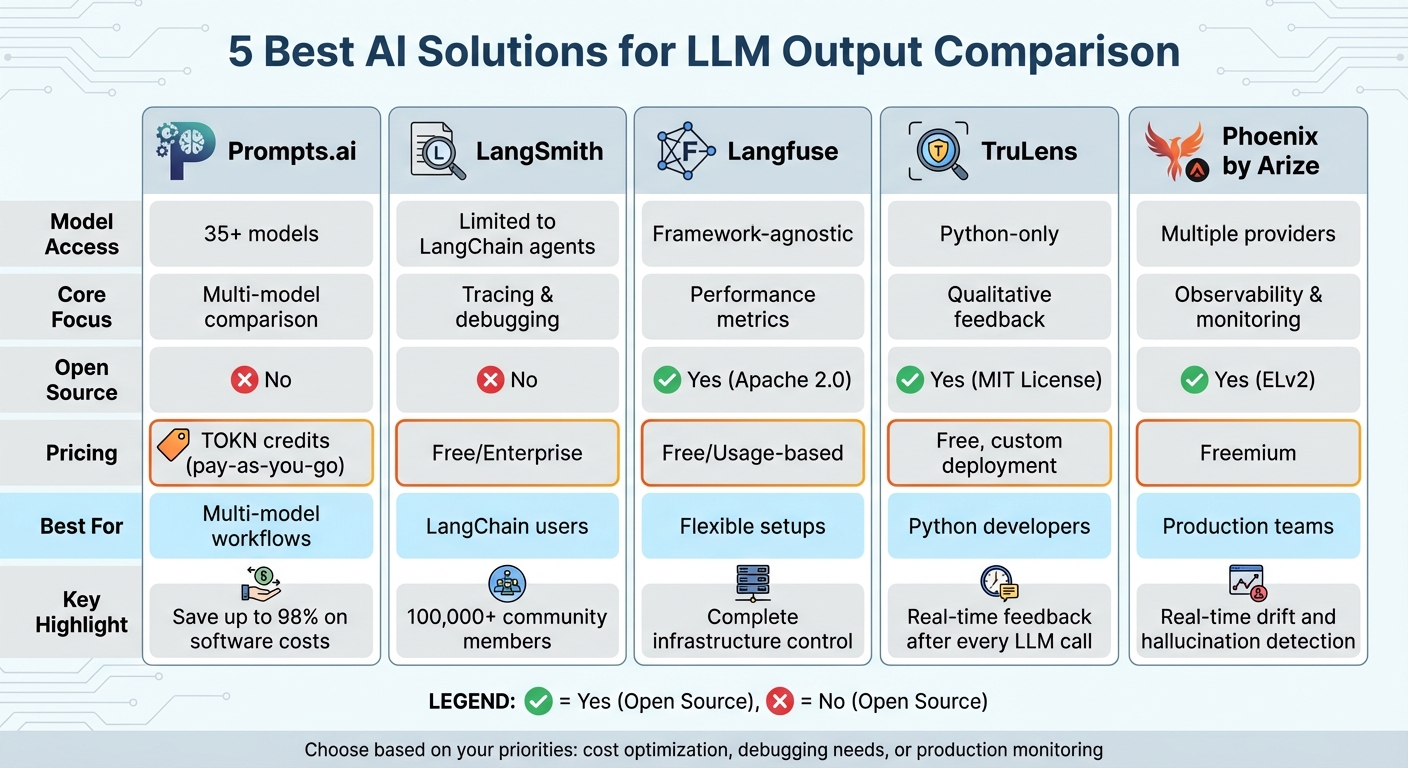
Each platform has strengths tailored to different needs, from cost-saving comparisons to production monitoring. Below is a quick comparison to help you decide.
| Feature | Prompts.ai | LangSmith | Langfuse | TruLens | Phoenix by Arize |
|---|---|---|---|---|---|
| Model Access | 35+ models | Limited to LangChain agents | Framework-agnostic | Python-only | Multiple providers |
| Core Focus | Multi-model comparison | Tracing & debugging | Performance metrics | Qualitative feedback | Observability & monitoring |
| Open Source | No | No | Yes | Yes | Yes |
| Pricing | TOKN credits (pay-as-you-go) | Free/Enterprise | Free/Usage-based | Free, custom deployment | Freemium |
| Best For | Multi-model workflows | LangChain users | Flexible setups | Python developers | Production teams |
These tools help streamline LLM evaluation, ensuring you choose the right model for your goals while managing costs and maintaining high-quality outputs.
AI LLM Output Comparison Tools: Feature Comparison Chart
Prompts.ai brings together 35+ top-tier models, including GPT‑5, Claude, LLaMA, and Gemini, into one streamlined platform. This setup allows teams to compare how different large language models (LLMs) respond to the same prompt in real time. Whether you're focused on technical documentation, crafting creative content, or fine-tuning for speed and precision, Prompts.ai helps you identify the best model for the task. Its unified interface lays the groundwork for powerful output comparison tools, which are explained in detail below.
One of the standout features of Prompts.ai is its ability to test multiple models simultaneously within a single interface. By running identical prompts across various LLMs, users can easily compare responses side by side, highlighting differences in reasoning, tone, and accuracy. This eliminates the hassle of switching between tools or manually consolidating data into spreadsheets. Architect June Chow shared that using Prompts.ai for side-by-side comparisons has significantly sped up design workflows and sparked creative solutions. Additionally, the platform offers an Analytics feature - available in the Creator ($29/month) and Problem Solver ($99/month) plans - which tracks performance trends over time.
Security is a key focus at Prompts.ai. The platform initiated its SOC 2 Type 2 audit process on June 19, 2025, and adheres to practices aligned with SOC 2 Type II, HIPAA, and GDPR standards. Partnering with Vanta for continuous control monitoring, Prompts.ai ensures full auditability for all AI interactions. This means every prompt, response, and model selection is logged, creating a comprehensive record for internal reviews or external audits. For transparency, users can check the platform’s real-time security status at https://trust.prompts.ai/, which provides updates on policies, controls, and compliance progress.
Prompts.ai operates on a pay-as-you-go TOKN system, allowing users to avoid recurring fees for individual models. This flexible structure is particularly helpful for U.S. organizations managing dollar-based budgets, especially during the experimental phase of working with multiple LLMs. By centralizing access and reducing the need for separate subscriptions, the platform can cut software costs by up to 98%. The shared workspace also simplifies team collaboration, enabling seamless access to experiments, results, and governance tools.
LangSmith, introduced in July 2023, is a tracing tool built into LangChain. Since its launch, it has gained traction with over 100,000 community members. For LangChain users, it simplifies the process by automatically uploading LLM traces to its cloud service without requiring additional setup. This seamless integration makes collecting and analyzing traces more efficient.
LangSmith provides two straightforward methods for evaluating LLM outputs: manual review by teams or automated evaluation using LLMs. The platform also includes tools for cost analysis and usage analytics, though these features are currently limited to OpenAI integrations.
LangSmith operates as a cloud-based SaaS platform, offering a free tier that includes up to 5,000 traces per month. For larger organizations, a self-hosted Enterprise option is available. Furthermore, LangSmith extends its support to agents beyond the LangChain ecosystem, enhancing its flexibility and usability.

Langfuse is an open-source platform licensed under Apache 2.0, offering teams complete control over their LLM evaluation infrastructure. Designed to work independently of specific models or frameworks, it ensures compatibility across various LLMs and development tools. This flexibility enables thorough output comparison and evaluation, complementing the analytical capabilities of similar platforms.
Langfuse enables both human and AI-driven evaluation of model outputs. This dual approach ensures teams can accurately gauge the quality of content generated by LLMs.
The platform includes performance metrics dashboards that help developers measure and debug LLM outputs. These dashboards provide actionable insights to refine and improve model performance.
Langfuse integrates seamlessly with key tools in the LLM development ecosystem. It supports OpenTelemetry, LangChain, the OpenAI SDK, and LlamaIndex. While its core features remain free and open source, the platform also offers a cloud service with a usage-based pricing model.
TruLens is an open-source tool, licensed under the MIT License, designed to help teams perform qualitative analysis of LLM responses within Python-based development environments. Its flexibility makes it a valuable resource for developers aiming to evaluate the quality of language model outputs effectively.
TruLens enables qualitative analysis by providing feedback after every LLM call. This process examines the initial output in real-time, allowing teams to assess quality immediately and refine their models as needed.
The platform uses standalone feedback models to evaluate the initial LLM responses. These models apply multiple criteria to ensure a thorough quality review. This structured approach also aligns well with deployment needs, offering insights that can guide operational decisions.
TruLens is built for on-premise Python deployments and does not include a self-service cloud option. For cloud-based needs, teams must coordinate custom deployment solutions to integrate TruLens into their workflows.
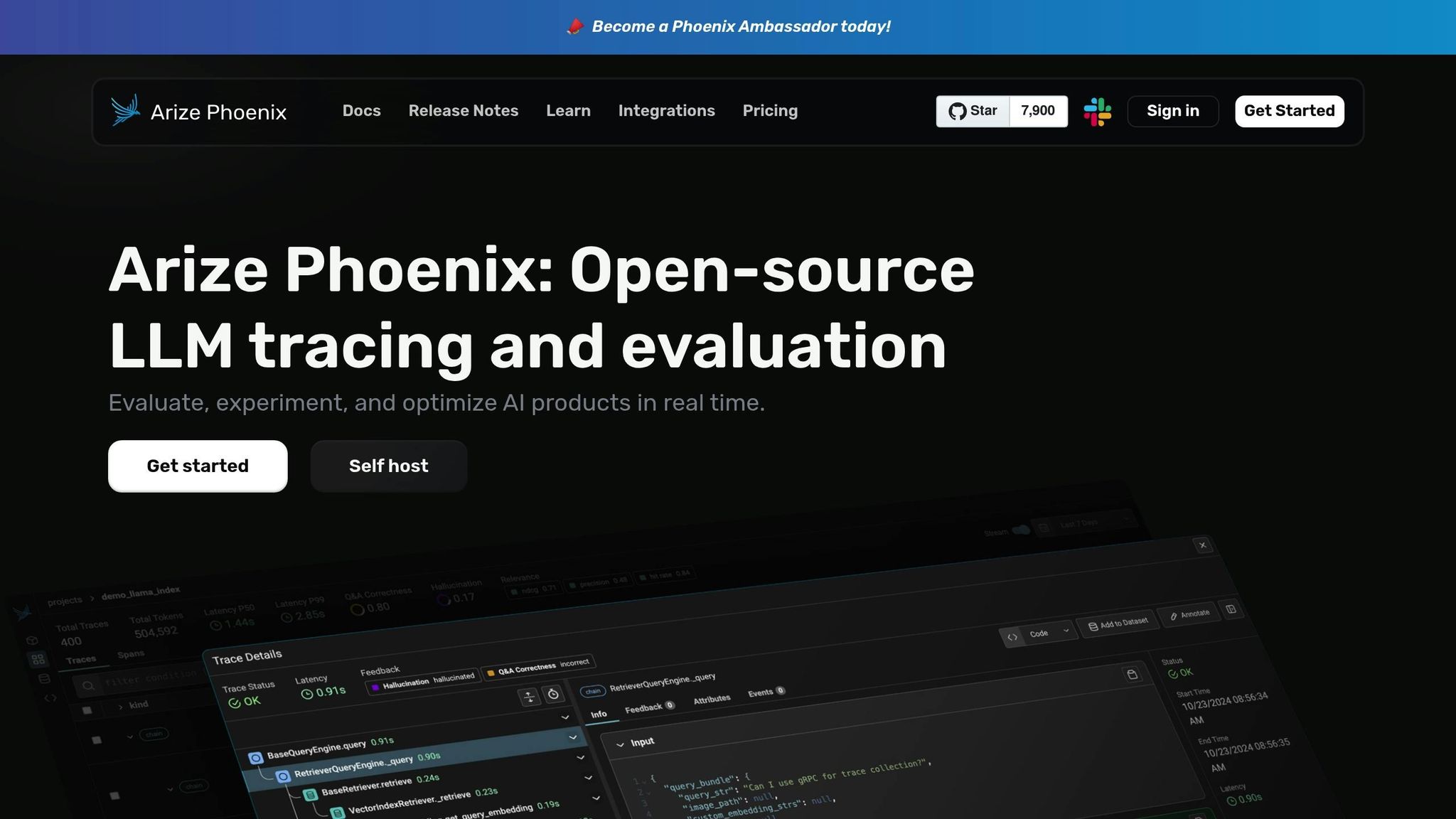
Observability in production is just as important as direct output comparison when evaluating AI systems. Phoenix by Arize, an open-source platform licensed under ELv2, focuses on providing AI observability and monitoring tools for production environments. Operating on a freemium model, it equips teams with detailed insights into their LLM systems' performance across different scenarios and deployments.
Phoenix takes a deep dive into LLM performance by segmenting responses and pinpointing areas where models may struggle. This includes challenges like dialect variations and rare linguistic cases. It also employs embedding analysis to compare semantic similarity, enabling precise tracking of performance across outputs.
The platform goes beyond surface-level monitoring by identifying issues such as performance degradation, data drift, model biases, and hallucinations - where the model generates fabricated outputs - in real time. However, its primary focus is on observability rather than evaluation, offering limited support for comprehensive evaluation datasets.
Phoenix integrates seamlessly with popular frameworks like LlamaIndex, LangChain, DSPy, Haystack, and AutoGen. It also supports a range of LLM providers, including OpenAI, Bedrock, Mistral, Vertex AI, and LiteLLM. Its OpenTelemetry-based instrumentation ensures smooth integration into existing monitoring workflows.
Here’s a breakdown of the strengths and trade-offs for each platform:
prompts.ai brings together over 35 leading models under one interface, making it a standout choice for enterprises juggling multi-model workflows. Its built-in FinOps controls meticulously track token usage, offering substantial cost savings. However, teams focusing exclusively on retrieval-augmented generation may find they need additional specialized tools to meet their needs.
LangSmith is a strong contender for development teams, thanks to its powerful tracing and debugging features. That said, it demands a higher level of technical expertise, which could pose a challenge for less experienced users.
For those seeking flexibility, Langfuse provides open-source deployment options, making it highly adaptable. However, teams may need to rely on supplementary tools to achieve a thorough evaluation of datasets.
TruLens excels in offering detailed, interpretable feedback on LLM outputs through its robust evaluation metrics. Its code-centric design is perfect for data scientists, though it requires more technical know-how compared to platforms with more visual interfaces.
When it comes to production environments, Phoenix by Arize stands out for its real-time monitoring capabilities. It detects issues like performance degradation, data drift, and hallucinations as they happen. However, its focus on observability means its support for evaluation datasets is less extensive.
Choosing the right tool ultimately depends on your priorities. If cost optimization and unified access to multiple models are your goals, platforms with integrated FinOps controls are ideal. For teams focused on debugging and development, tools with advanced tracing features are a better fit. Meanwhile, real-time monitoring platforms are invaluable for production scenarios requiring observability and drift detection.
When selecting an AI platform, it's crucial to find one that aligns with your organization's goals and technical setup. The formula "Quality of metrics × Quality of dataset" serves as the cornerstone for effective LLM evaluation. Prioritize platforms that perform well in both areas to ensure you get the most out of your investment.
Once you've defined your evaluation criteria, focus on integration. Choose a platform that works seamlessly with your existing tools, such as OpenTelemetry, Vercel AI SDK, LangChain, or LlamaIndex. This minimizes setup time and reduces ongoing maintenance efforts. For teams juggling multiple AI frameworks, adopting a unified observability strategy is essential to avoid gaps or inconsistencies in monitoring.
Your choice should also reflect your deployment needs. Startups often benefit from fast logging and flexible testing environments, while large enterprises typically require comprehensive tracking and governance. In production settings, real-time monitoring with advanced tracing and debugging capabilities becomes indispensable.
As highlighted in the platform overviews, striking a balance between visibility and cost is achievable by tailoring monitoring to specific environments and using intelligent span sampling for high-value operations. Additionally, incorporating FinOps controls into multi-model workflows can help keep expenses under control.
When choosing an AI platform to assess outputs from large language models (LLMs), there are a few important aspects to keep in mind. Start with cost transparency - you’ll want a platform that provides clear, upfront pricing without any unexpected charges. Next, review the range of supported models to ensure it aligns with the LLMs you rely on. Lastly, look for platforms that offer seamless integration with your current workflows, which can save you both time and effort.
Focusing on these elements will help you select a platform that streamlines the evaluation process and provides precise, actionable results.
Prompts.ai places a strong emphasis on data security and regulatory compliance, ensuring a trustworthy platform for its users. By utilizing advanced encryption protocols, we protect sensitive information and align with established industry standards for data protection.
We also meet all applicable legal and regulatory requirements, guaranteeing that your data is managed responsibly and with full transparency. This dedication to security allows users to concentrate on analyzing their LLM outputs without worrying about the safety of their data.
Prompts.ai's TOKN system simplifies the evaluation of large language model (LLM) outputs, saving both time and effort. By automating crucial steps in comparison and analysis, it reduces the need for manual work, helping businesses cut operational expenses.
The system also enhances accuracy and efficiency, lowering the risk of errors that might result in expensive corrections or misunderstandings. This approach provides a streamlined, budget-friendly solution for professionals and organizations relying on LLMs.



















