7 Days Free Trial; no credit card required


Looking for tools to compare outputs from AI models like GPT-4, Claude, or LLaMA? Here’s what you need to know:
These tools simplify decision-making by helping users identify the best-performing and most cost-effective models for their needs. Below is a quick comparison of their features.
| Tool | Key Features | Real-Time Monitoring | Model Coverage | Security/Compliance |
|---|---|---|---|---|
| Prompts.ai | Side-by-side comparisons, cost tracking, agent chaining | Yes | 35+ models (e.g., GPT-4, Claude) | Enterprise-grade governance |
| Deepchecks | Automated validation, drift detection | Yes | Targeted assessments | On-premises deployment |
| DeepEval | Custom evaluations, local processing | Yes | Community insights | Local-only data handling |
| LLM Leaderboard | Benchmarks cost, speed, intelligence | Yes | 100+ models | Public data review |
Choose based on your team’s budget, security needs, and workflow priorities.
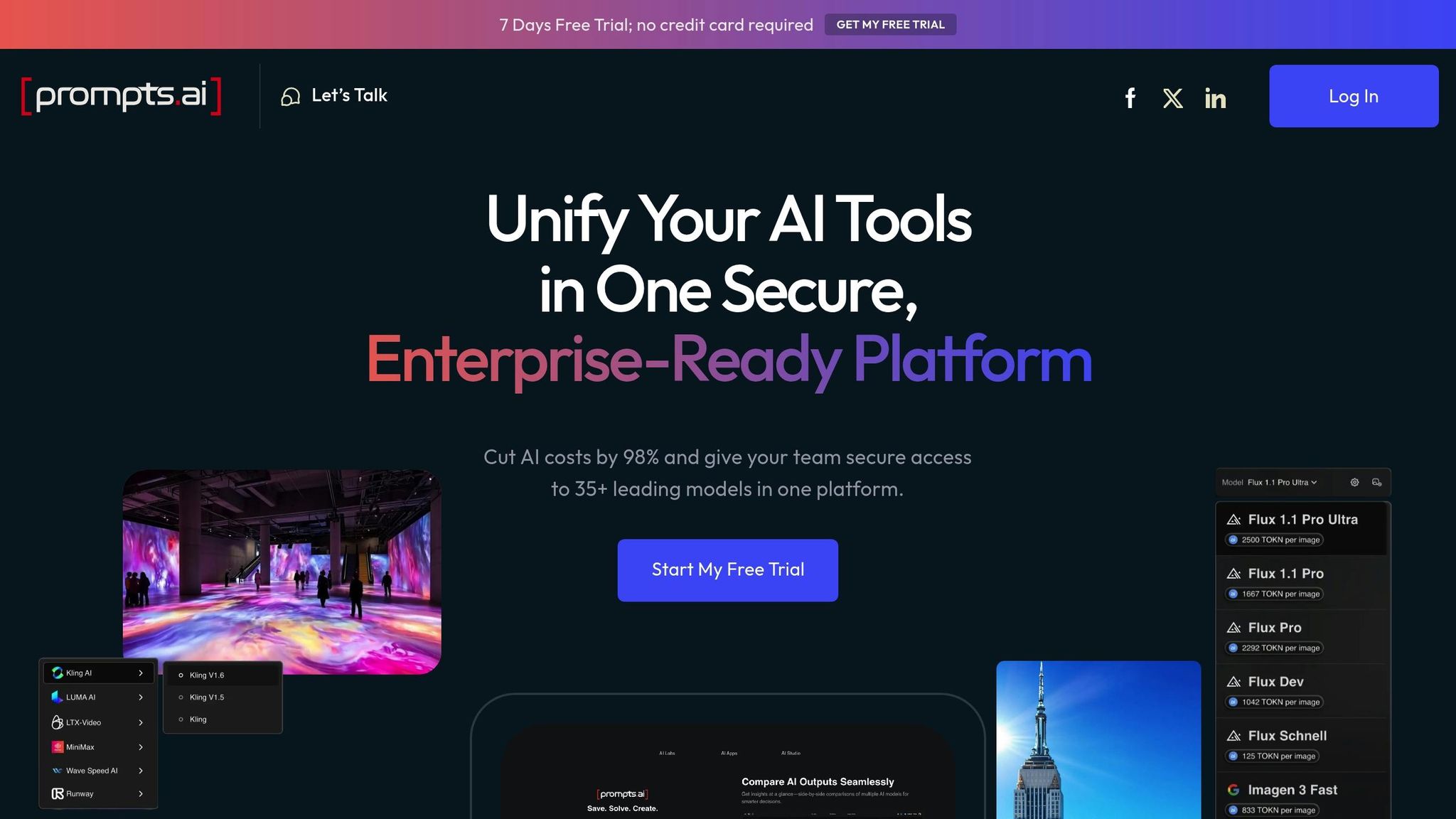
Prompts.ai is an enterprise-level platform that brings together over 35 leading LLMs in a single, secure interface, eliminating the hassle of juggling multiple tools.
Designed for Fortune 500 companies, agencies, and research labs, Prompts.ai can reduce AI costs by as much as 98% while maintaining top-tier enterprise security. From one unified dashboard, teams can access models like GPT-4, Claude, LLaMA, and Gemini.
One standout feature of Prompts.ai is its side-by-side comparison tool. This allows users to run the same prompts across different models simultaneously, making it easy to identify the best-performing option without the need for constant switching between platforms or manually tracking results.
The platform also includes instant model toggling, which retains the context of your work. This is especially useful for testing how different models handle the same task or for optimizing specific outcomes, such as creativity, accuracy, or cost-efficiency.
Another powerful feature is agent chaining, where the output from one model can feed into another. This is ideal for building complex workflows and testing how various model combinations perform together to achieve specific goals. These capabilities integrate seamlessly with real-time monitoring to streamline the evaluation process.
Prompts.ai delivers real-time feedback on performance, helping teams make faster and more informed decisions during evaluations.
The platform includes a built-in FinOps layer that tracks every token used across all models. This transparency allows teams to fully understand their AI costs and allocate resources more effectively. By providing detailed cost insights for specific tasks, teams can balance their performance goals with budget considerations.
With real-time usage analytics, teams gain actionable insights into model performance trends. This turns what might otherwise be ad-hoc testing into a structured evaluation process that supports better long-term decision-making. The combination of these features ensures transparency and efficiency throughout the evaluation process.
Prompts.ai supports over 35 leading LLMs, offering tools for tasks like code generation, creative writing, and data analysis. The platform’s library is continuously updated to ensure access to the latest models.
This extensive selection allows teams to benchmark performance across various AI providers and model types. Whether the focus is on technical tasks, creative projects, or analytical needs, Prompts.ai provides the right tools for a thorough evaluation.
Prompts.ai prioritizes enterprise-grade security, ensuring sensitive data remains protected and reducing the risk of third-party exposure.
The platform includes built-in governance tools and audit trails for every workflow, making compliance with regulatory requirements simpler. Teams can track which models were accessed, the prompts used, and the outputs generated, creating a detailed record for accountability and regulatory purposes.
With its Pay-As-You-Go TOKN credits, the platform eliminates the need for recurring subscription fees. Instead, costs are aligned directly with actual usage, giving organizations greater flexibility and control over their AI spending. This model allows teams to scale their usage up or down based on their project needs, ensuring cost-effectiveness and adaptability.

Deepchecks is an open-source platform designed for continuous testing and monitoring of machine learning models. By applying principles of traditional software testing, it ensures a structured approach to evaluating outputs from large language models (LLMs). This tool serves as a rigorous validation option, complementing enterprise platforms like Prompts.ai.
Unlike enterprise-focused platforms, Deepchecks prioritizes thorough model validation. It includes automated validation suites that allow users to compare model outputs based on custom criteria and batch analyses. With features like drift detection and the ability to define custom metrics, it helps identify deviations from expected behavior.
Deepchecks actively tracks production performance, using automated alerts tied to quality thresholds. Its robust analytics and anomaly detection systems make it easier to identify and address unexpected behaviors quickly.
To protect sensitive data, Deepchecks supports on-premises deployment. Additionally, it provides an audit trail to document testing activities, ensuring alignment with compliance requirements.
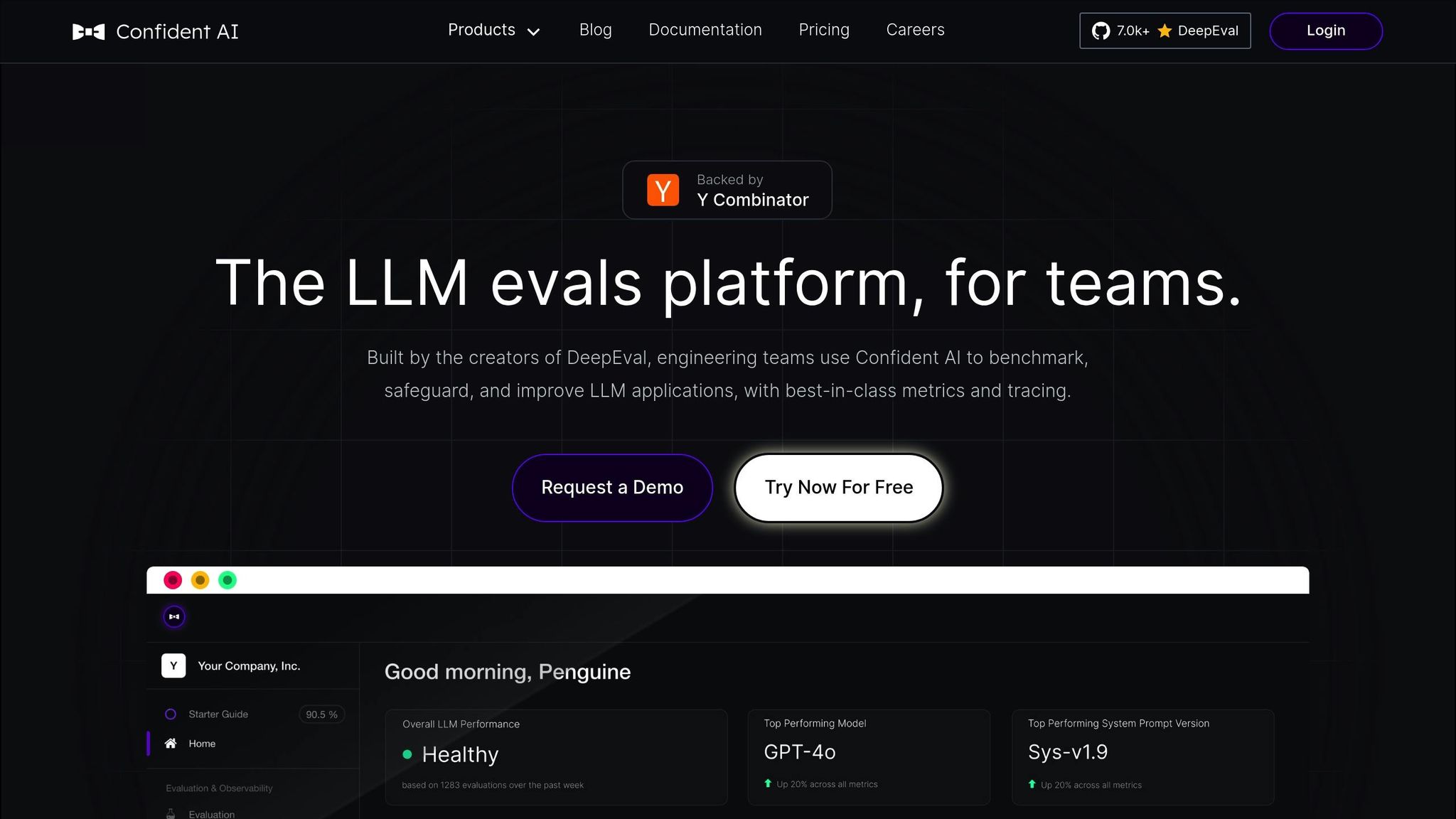
DeepEval is an open-source framework designed to evaluate large language model (LLM) outputs while prioritizing data privacy. It serves as a reliable tool to meet the growing need for secure and accurate LLM evaluations.
DeepEval offers flexible tools for comparing outputs side by side and setting custom evaluation criteria. These features help teams assess model responses with precision, meeting the varied demands of modern AI evaluation.
The framework seamlessly integrates into development workflows, allowing teams to monitor performance in real time and make adjustments as needed.
By running evaluations locally, DeepEval ensures that sensitive data stays protected, providing an added layer of security for users.
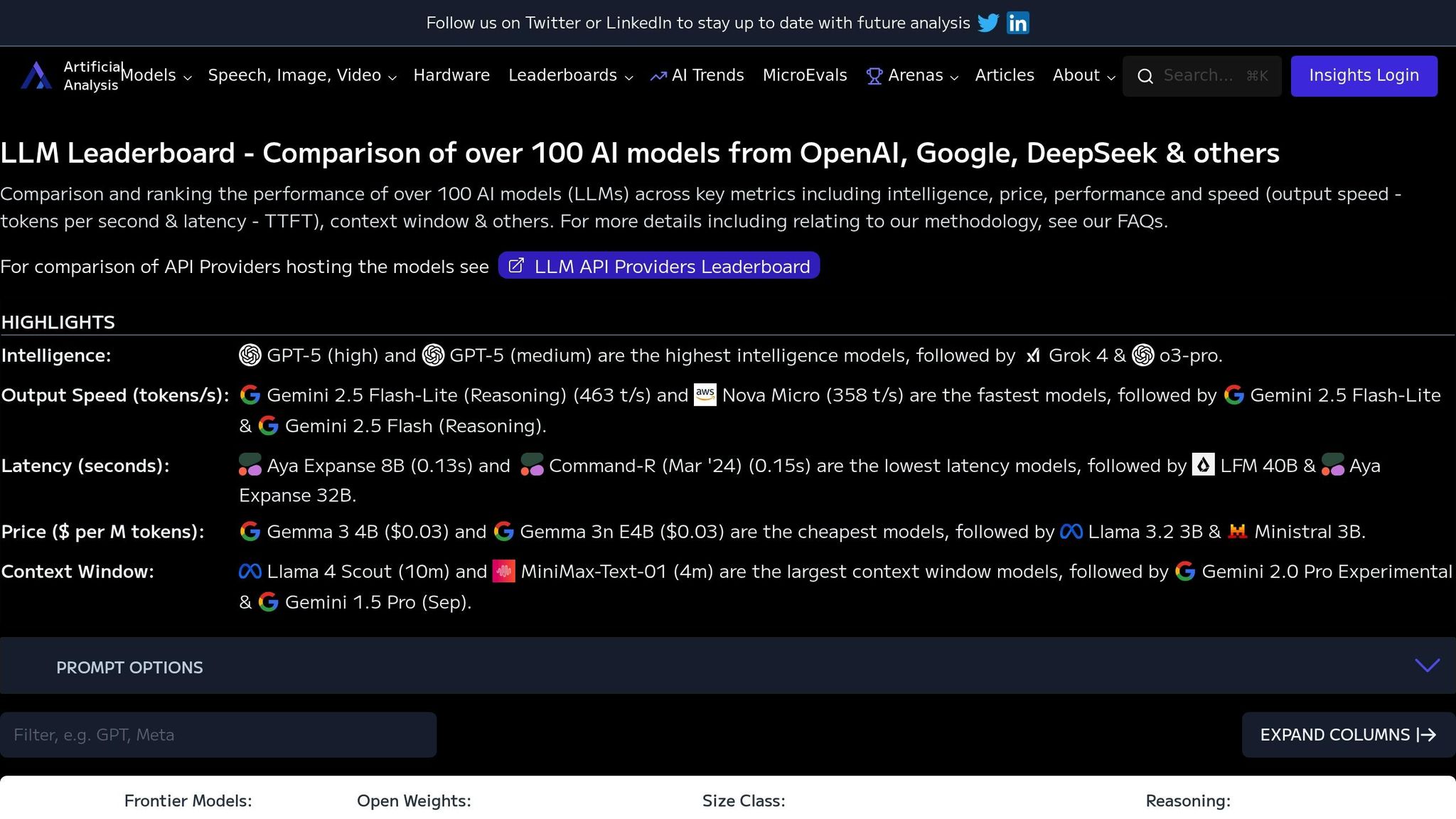
The LLM Leaderboard by ArtificialAnalysis.ai serves as a benchmarking hub, comparing the performance of over 100 AI models. It uses a data-driven evaluation system with standardized metrics, giving teams the clarity they need to make smart deployment choices. Below, we explore its standout features.
The platform evaluates models based on three key areas: intelligence, cost, and output speed.
These metrics create a shared framework for comparing AI capabilities, enabling teams to assess models objectively and select the best fit for their needs.
The Leaderboard provides live performance tracking, ensuring users have access to the most up-to-date data. Metrics are refreshed frequently - eight times daily for single requests and twice daily for parallel requests - using data collected over the past 72 hours. This real-time monitoring ensures that any shifts in performance are quickly visible, helping organizations make deployment decisions with confidence.
Covering a wide range of AI models, the platform offers an extensive view of the current AI ecosystem. This broad scope not only helps professionals pinpoint the most appropriate solutions but also encourages progress among developers by promoting transparency and healthy competition through performance metrics.
After examining the tools in detail, let’s break down their main strengths and limitations. Each platform has its own set of trade-offs, making it essential for teams to weigh their specific needs when choosing the right evaluation tool. Below is a closer look at the standout features and areas where these tools might fall short.
Prompts.ai stands out as a robust enterprise solution, offering a unified platform to compare over 35 leading LLMs, all accessible through a single interface. Its real-time FinOps controls provide detailed cost insights, helping organizations reduce AI software expenses by up to 98% through transparent token tracking and optimized spending. The platform also simplifies complex AI operations with agent chaining and integrated workflow management, reducing reliance on multiple tools. However, these advanced features come at a premium, which might pose challenges for smaller teams with limited budgets.
Other platforms cater to more specialized needs. Some prioritize model reliability and safety, offering tools for performance monitoring, while others focus on customization, ease of use, or benchmarking. These options, while valuable, may involve a steeper learning curve or require significant configuration efforts to meet specific requirements.
Here’s a quick comparison of their core features:
| Tool | Output Comparison Features | Real-Time Monitoring | Model Coverage | Security/Compliance |
|---|---|---|---|---|
| Prompts.ai | Unified model comparison | FinOps tracking and cost control | 35+ leading LLMs (e.g., GPT-4, Claude, LLaMA, Gemini) | Enterprise governance and audit trails |
| Deepchecks | Automated validation suites | Performance alerts | Targeted assessments | On-premises deployment |
| DeepEval | Custom evaluation criteria | Pipeline integration | Community insights | Local data processing |
| LLM Leaderboard | Standardized benchmarks | Regular updates | Broad model tracking | Public data review |
When deciding, consider your team’s budget, technical expertise, and workflow demands. Prompts.ai offers a proven enterprise solution with cost management and streamlined workflows, while other platforms shine in areas like safety, developer flexibility, or benchmarking depth. Each tool brings something valuable to the table, so the choice ultimately depends on your specific priorities.
After evaluating each tool's capabilities and trade-offs, one solution clearly rises above the rest for enterprise AI orchestration. Prompts.ai offers a unified interface that integrates more than 35 models, including GPT-4, Claude, LLaMA, and Gemini, all while providing real-time cost controls that can slash AI expenses by as much as 98%. Its flexible pay-as-you-go TOKN credit system eliminates the burden of recurring subscription fees, and its built-in governance features, including detailed audit trails, ensure compliance for organizations ranging from Fortune 500 companies to creative agencies and research labs.
With Prompts.ai, teams gain transparent cost management, robust governance, and efficient AI operations - all in one platform. By consolidating AI evaluation and orchestration into a single, powerful solution, Prompts.ai meets the demands of enterprise-scale workflows while simplifying the complexities of managing multiple testing environments. For teams aiming to streamline their operations and maximize value, this platform delivers the tools and reliability they need.
Prompts.ai enables businesses to slash AI expenses by as much as 98%, thanks to its streamlined platform that consolidates AI operations into one centralized system. By offering a unified interface for prompt testing and evaluation, it removes the hassle of juggling multiple disconnected tools, saving both time and valuable resources.
A key feature of Prompts.ai is its prompt caching system, which reuses identical prompts instead of processing them repeatedly. This smart strategy drastically reduces operational costs, allowing businesses to fine-tune their AI workflows without overspending.
Prompts.ai prioritizes top-tier security to meet enterprise-level standards. It employs end-to-end encryption to protect data during transmission, multi-factor authentication (MFA) for added login security, and single sign-on (SSO) to simplify and secure access management.
The platform also includes detailed audit logs to monitor activity comprehensively and uses data anonymization to protect sensitive information. By adhering to critical compliance frameworks like SOC 2 and GDPR, Prompts.ai ensures your data stays protected while keeping your organization aligned with regulatory requirements.
The agent chaining feature in Prompts.ai simplifies the evaluation process for AI models by dividing complex tasks into smaller, more manageable steps. This approach enables sequential processing and multi-step testing, offering a detailed way to assess model performance.
By automating these linked steps, agent chaining boosts reliability and delivers more comprehensive insights into how models navigate complicated workflows. This not only improves the quality of evaluations but also saves teams significant time and effort.


















