7 Days Free Trial; no credit card required


Large Language Models (LLMs) are transforming industries, but comparing their outputs across thousands of prompts and datasets is a challenge. Tools like Prompts.ai, SmythOS, and Tool Y provide solutions to automate and streamline this process. Here's what you need to know:
| Feature | Prompts.ai | SmythOS | Tool Y |
|---|---|---|---|
| Batch Prompt Execution | Handles thousands of prompts | Supports large-scale workflows | Limited |
| Multi-Model Switching | 35+ models, conditional routing | Decoupled architecture | Basic |
| Automated Output Comparison | Advanced tools, custom scoring | Unified framework via APIs | Limited |
| Conversation History | No | No | Retains full history |
| Cost Optimization | Cuts AI costs by up to 98% | N/A | N/A |
For high-volume operations, Prompts.ai offers the most comprehensive features, while Tool Y is better suited for conversational analysis. SmythOS balances scalability and automation for enterprises managing diverse AI models.
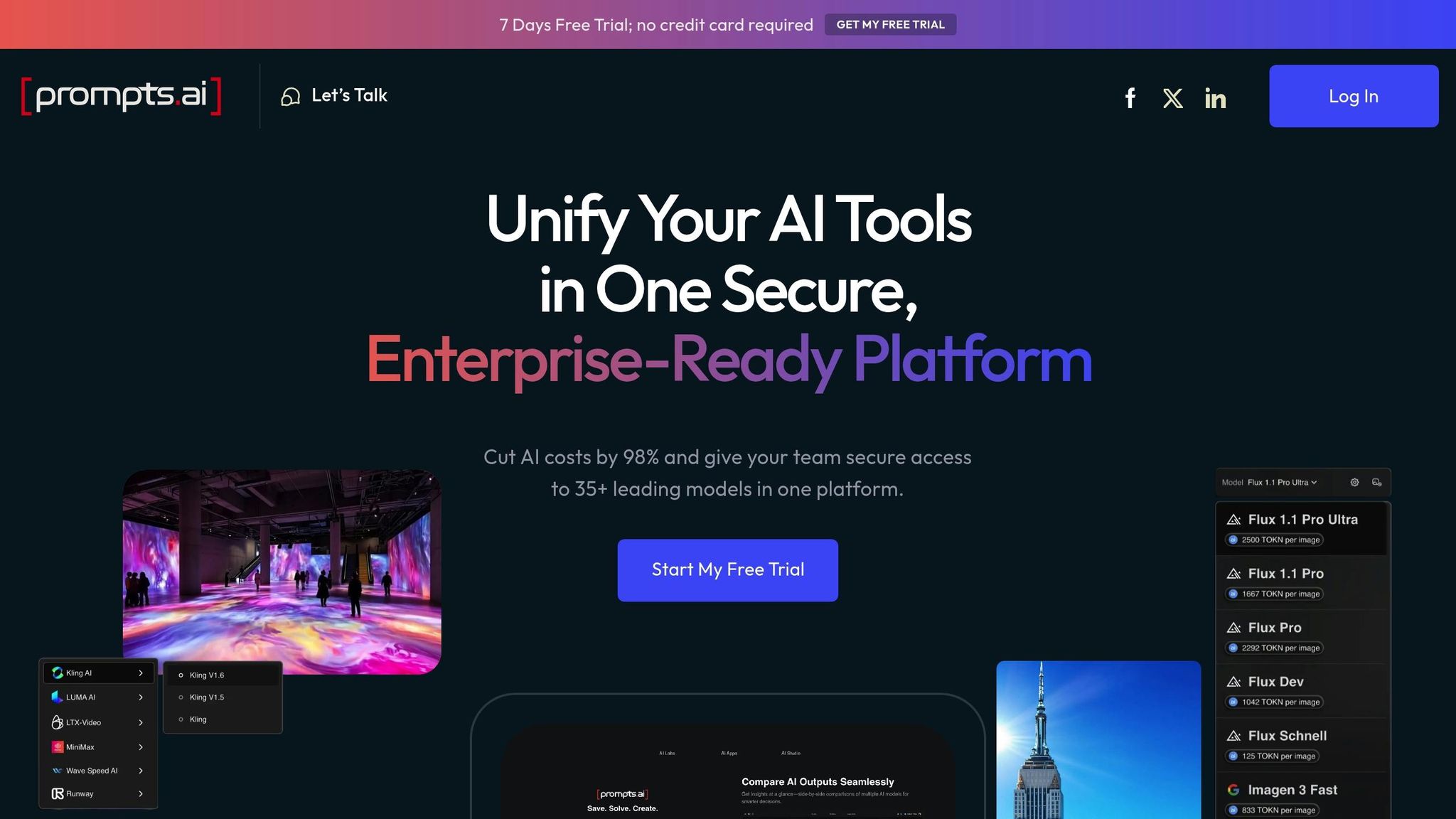
Prompts.ai is a platform designed to simplify and optimize the use of over 35 large language models (LLMs) within a single, secure interface. It tackles the challenges of managing multiple tools and workflows, helping users cut AI costs by up to 98% while ensuring enterprise-grade governance and security.
One standout feature is the ability to handle batch prompt execution on a massive scale. Users can upload thousands of prompts at once and execute them simultaneously. For instance, a customer support team could upload a CSV file containing 5,000 customer queries and process them across multiple models in just a few hours, a task that would typically take days of manual effort.
This capability is especially useful for organizations needing to evaluate LLM outputs on large datasets or test various prompt versions. By automating these tasks, the platform not only simplifies the process but also provides structured output logs, making analysis faster and reducing the time spent on manual tasks.
Prompts.ai also makes comparing different LLMs seamless with its multi-model switching feature. Users can easily evaluate outputs from models like OpenAI GPT-4, Anthropic Claude, LLaMA, Gemini, and open-weight models side by side, all within the same workflow. This eliminates the hassle of duplicating workflows for each model, as identical prompts and datasets can be applied across providers.
Adding to this, the platform’s conditional routing feature automates the process of directing prompts to specific models based on input characteristics. This allows organizations to assess performance, accuracy, and cost-effectiveness across different models without manual intervention, making it easier to choose the best model for a given task.
The platform further streamlines the evaluation process with tools for automated output comparison. Users can leverage features like side-by-side displays, difference highlighting, and automated flagging to identify responses that don’t meet predefined quality standards, such as relevance or factual accuracy.
Reusable prompt templates add another layer of efficiency. These templates can be customized and applied across datasets or models, ensuring consistency and saving time when setting up new experiments. By allowing users to store, version, and reuse templates, the platform supports standardized testing and reproducibility.
Prompts.ai goes beyond comparisons by offering a scoring system that assigns metrics-based evaluations to LLM outputs. Whether using built-in metrics like accuracy, relevance, and completeness, or custom rubrics tailored to specific business needs (e.g., compliance or tone consistency), the scoring system provides actionable insights.
Every prompt execution, model selection, and output result is automatically logged, creating a detailed audit trail. This ensures traceability, supports reproducibility, and helps with compliance requirements. Users can review past runs, compare historical data, and export logs for further analysis. By aggregating scores across batches, the platform provides data-driven insights that guide decisions on model selection and prompt optimization, replacing guesswork with measurable results.
SmythOS stands out as a powerful tool for comparing high-volume outputs from large language models (LLMs). By coordinating multiple AI models through an intuitive visual interface, it enables organizations to harness the strengths of each model within streamlined workflows. This approach supports scalable and automated comparisons, making complex tasks more manageable.
With its decoupled architecture, SmythOS simplifies the management of multiple AI models. It supports seamless model switching, failover handling, and upgrades, ensuring uninterrupted operations. Its routing system evaluates both content and performance to identify the best-suited model for each task. Additionally, the visual builder allows users to create advanced AI pipelines, making it easier for organizations to design and deploy sophisticated workflows. This capability is essential for automating and optimizing output comparisons.
Through robust API integrations, SmythOS efficiently combines outputs from various models into a unified framework. This integration allows teams to gather data from multiple sources and process it across different models, fostering a cohesive and efficient operational environment.
SmythOS takes performance monitoring a step further by continuously scoring model outputs. It uses this data to refine routing decisions, ensuring that the most effective models are prioritized. This ongoing evaluation provides teams with actionable insights into model performance, helping them make informed decisions over time.
Tool Y takes the concept of advanced model switching a step further by emphasizing the preservation of conversation history. It simplifies the process of evaluating large language models (LLMs) by allowing seamless multi-model switching while keeping each model's settings and conversation history intact.
What sets Tool Y apart is its ability to retain complete conversation histories. This feature provides a richer understanding of how models perform over time. By maintaining the full context of conversations, users can compare how different models handle the same inputs in a continuous dialogue. This approach offers a more accurate and meaningful way to assess performance, going beyond the limitations of traditional, isolated comparisons.
When evaluating tools for large-scale LLM output analysis, it's essential to weigh their strengths against their limitations. Each platform brings unique capabilities to the table, but certain constraints may affect their suitability for specific operational needs.
Prompts.ai stands out for its enterprise-level orchestration, offering unified access to over 35 leading models, such as GPT-4, Claude, LLaMA, and Gemini. It includes advanced workflow features like conditional routing and reusable prompt templates. A key advantage is its real-time FinOps cost controls, which allow organizations to monitor token usage and expenses, potentially reducing AI costs by as much as 98%. However, its extensive feature set might feel overwhelming for smaller teams unfamiliar with batch evaluation processes.
Tool Y is particularly strong in assessing conversational quality. It supports multi-model switching and enables evaluations tailored for conversational use cases. However, its capacity for large-scale batch processing and detailed automated output comparisons is limited, which may hinder its use in high-volume environments.
Some platforms rely on API proxying, which can lead to performance issues, such as increased latency and higher costs during large batch executions. In contrast, direct infrastructure integration minimizes these inefficiencies, making it an ideal choice for teams handling high-volume processing. By storing prompts independently and executing them directly within existing infrastructure, organizations can achieve greater scalability and reliability.
| Feature | Prompts.ai | Tool Y |
|---|---|---|
| Batch Prompt Execution | Direct infrastructure integration with minimal latency | Limited batch capabilities |
| Multi-Model Switching | Seamless access to 35+ models | Basic multi-model switching |
| Automated Output Comparison | Advanced comparison tools with custom scoring | Basic comparison functionality |
| Result Scoring | Comprehensive scoring with integrated cost tracking | Limited scoring capabilities |
The table above highlights the functional differences that define each platform’s strengths. These distinctions reveal trade-offs between platforms designed for high-volume batch processing and those tailored for interaction-focused evaluations.
Choosing the right tool depends on the specific needs of your team. For organizations requiring thorough evaluation across multiple models and prompt variations, a platform with robust batch execution and detailed scoring tools is essential. On the other hand, teams prioritizing conversational quality may benefit from a more specialized tool, even if it lacks broader functionality.
Cost transparency is another critical factor. AI expenses often become obscured across multiple vendor relationships, making real-time cost tracking invaluable. This is especially true for enterprises managing large-scale AI deployments, where token costs can spiral without proper oversight. Platforms offering built-in cost optimization provide a clear advantage, ensuring alignment with organizational goals and scalability needs.
Comparing large language models (LLMs) effectively requires tools that go beyond basic functionality, offering enterprise-level orchestration and clear cost management. Prompts.ai delivers on these fronts, providing access to over 35 models, advanced FinOps controls that can cut AI expenses by up to 98%, and features like conditional routing and reusable prompt templates. These capabilities simplify complex workflows while ensuring strict governance - an essential combination for scalable enterprise operations.
Many tools emphasize conversational quality but struggle when it comes to handling thousands of prompt variations in batch processing. For enterprises managing high-volume deployments, a solid infrastructure that integrates seamlessly with existing workflows is critical.
Transparent cost management plays a key role in successful AI implementation. For instance, 87% of organizations view AI as essential, and those using integrated orchestration report an average ROI of 25%. By adopting AI orchestration frameworks, companies gain better visibility into expenses and optimize resource use, which is crucial for long-term efficiency.
Smaller teams and startups can take advantage of free tiers to establish foundational tracking systems before scaling up. The right tool for your organization will depend on your specific needs, but for high-volume operations, platforms like Prompts.ai offer the batch processing capabilities and cost controls necessary for success.
With the AI market projected to hit $190 billion by 2025, choosing tools that can adapt and grow alongside your organization is more important than ever.
Prompts.ai slashes AI operation costs by as much as 98% through the use of batch processing for API calls. Instead of handling requests one by one, tasks are grouped together, significantly reducing the overall expense.
Additionally, the platform automates essential workflows, such as prompt management and approval processes. This eliminates the need for extensive manual effort, reducing operational overhead. By simplifying these labor-intensive tasks, Prompts.ai boosts efficiency and enables scalable, budget-friendly AI experimentation.
Prompts.ai makes handling large-scale batch prompt execution straightforward and efficient. It provides structured workflows that include tools like conditional routing, reusable prompt templates, and detailed output logging. These features are designed to help you manage and automate prompt testing across various models and datasets, cutting down on time and minimizing manual mistakes.
The platform simplifies experimentation, enabling quicker and more dependable comparisons. Whether you're fine-tuning internal AI assistants or assessing advanced language models, Prompts.ai ensures a smooth, scalable process tailored for high-volume LLM output testing.
The conditional routing feature in Prompts.ai simplifies the process of evaluating multiple language models by automatically directing each prompt to the model best suited for the task. This approach improves processing efficiency and ensures higher-quality responses by avoiding overloading models that are less equipped for specific prompts.
By taking care of this decision-making automatically, conditional routing reduces the need for manual adjustments. This not only saves time but also makes it easier to experiment seamlessly with different models and datasets.



















