Pay As You Go - AI Model Orchestration and Workflows Platform


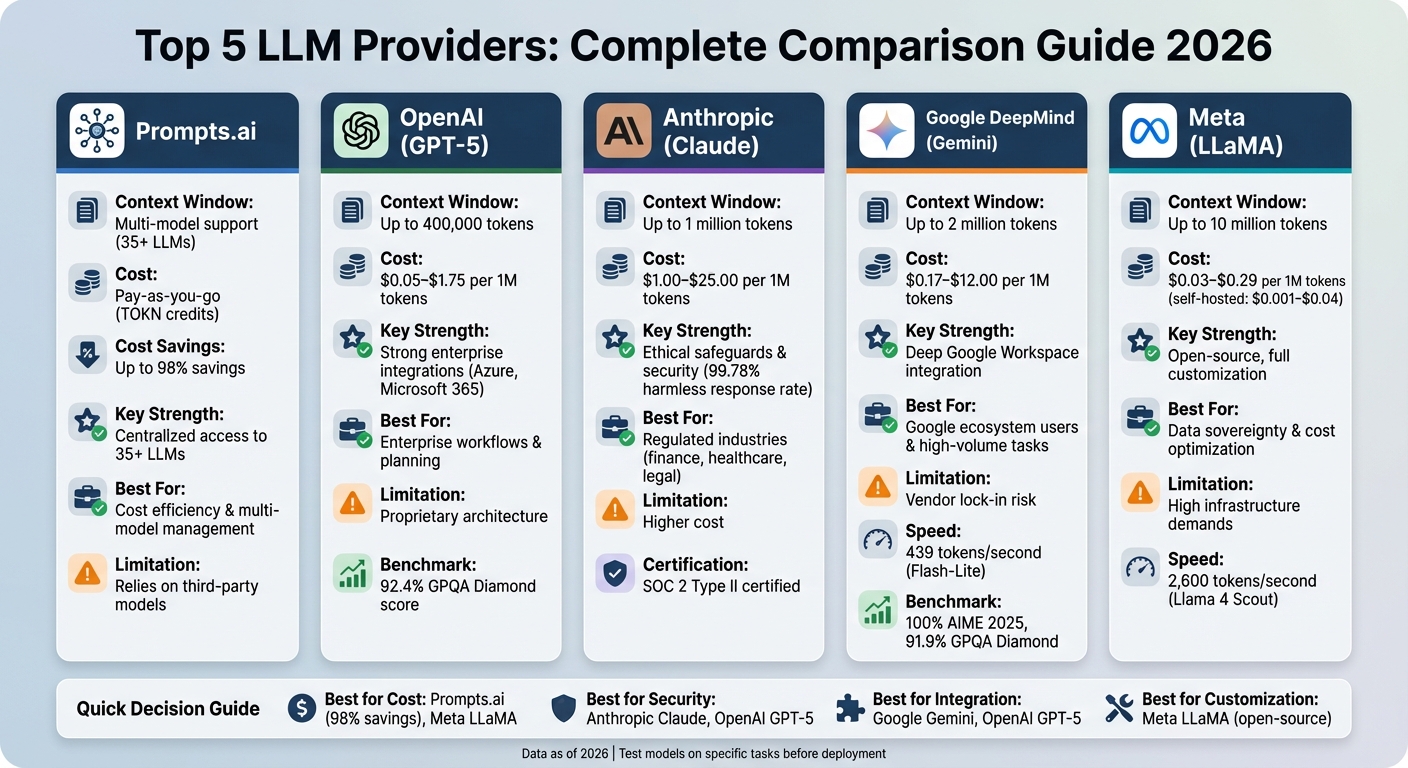
In 2026, businesses have access to over 180 large language models (LLMs) from leading providers like OpenAI, Google DeepMind, Anthropic, Meta, and DeepSeek. Choosing the right LLM is critical for balancing performance, costs, and security. Here's a quick overview of the key players:
| Provider | Context Window | Cost (per 1M tokens) | Key Strengths | Limitations |
|---|---|---|---|---|
| Prompts.ai | Multi-model support | Pay-as-you-go (TOKN) | Centralized access to 35+ LLMs | Relies on third-party models |
| OpenAI | Up to 400,000 tokens | $0.05–$1.75 | Strong enterprise integrations | Proprietary architecture |
| Anthropic | Up to 1M tokens | $1.00–$25.00 | Ethical safeguards, robust security | Higher cost |
| Up to 2M tokens | $0.17–$12.00 | Deep Google Workspace integration | Vendor lock-in risk | |
| Meta | Up to 10M tokens | $0.03–$0.29 | Open-source, full customization | High infrastructure demands |
The right LLM depends on your business needs. For cost savings, consider Prompts.ai or Meta. For advanced security and integrations, OpenAI and Anthropic shine. For scalability and Google ecosystem users, Gemini is a strong choice. Always test models on specific tasks to ensure alignment with your goals.
LLM Provider Comparison: Features, Pricing, and Context Windows 2026

Prompts.ai acts as a central hub for AI orchestration, combining over 35 top-tier large language models like GPT-5, Claude, LLaMA, Gemini, and more into a single, easy-to-use platform. Instead of managing multiple subscriptions and navigating various vendor portals, teams can access all major LLM providers through one dashboard. This approach simplifies operations, cuts costs, and reduces the complexity of deploying AI solutions.
What sets Prompts.ai apart is its streamlined integration of multiple LLM providers. The platform’s unified interface supports all major LLMs and APIs with minimal adjustments. Teams simply update a base URL and add an authentication header to get started. It also includes model transition management, which tracks baseline performance metrics, runs comparative tests using identical prompts across models, and gradually shifts traffic between providers. This process ensures smooth transitions and optimal cost management.
Prompts.ai uses a pay-as-you-go TOKN credit system, eliminating the need for recurring subscription fees. Costs are directly tied to usage, allowing organizations to save up to 98% compared to maintaining separate subscriptions for each provider. With its built-in FinOps layer, the platform offers real-time insights into token consumption and links spending to business outcomes, giving teams a clear view of their AI-related expenses.
Designed with enterprises in mind, Prompts.ai provides advanced governance tools, including complete audit trails for every AI interaction. Organizations can monitor which models are used, the prompts executed, and how resources are allocated. The platform also offers a Prompt Engineer Certification program and access to expert-designed workflow templates, enabling teams to adopt best practices and speed up deployment. With its unified ecosystem, Prompts.ai sets a high standard for modern AI workflow management.
GPT-5 has made strides in reducing factual inaccuracies, cutting errors by 45% compared to GPT-4o. It comes in several versions - GPT-5.2 Pro, GPT-5.2, GPT-5 mini, and GPT-5 nano - each designed for specific needs. The GPT-5.2 variant stands out with its ability to handle a 400,000-token context window and produce outputs of up to 128,000 tokens, making it well-suited for handling complex workflows and lengthy documents. These features ensure seamless integration into enterprise systems.
GPT-5 is tailored for advanced planning and autonomous execution, supported by the Agents SDK. It connects directly with widely-used enterprise tools like Google Drive, SharePoint, Microsoft OneDrive, GitHub, and Dropbox, enabling context-aware responses that align with existing business processes. Integration with Azure Foundry further enhances deployments by adding managed identities, policy enforcement, and access controls. The unified Responses API simplifies handling text, tools, vision, and state management, allowing the model to break down intricate objectives into structured plans. Notably, in late 2025, Notion utilized GPT-5 to revamp its platform, introducing agentic AI that autonomously manages tasks and documents for users.
Pricing for GPT-5 varies based on the model version and usage. For GPT-5.2, input tokens cost $1.75 per million, with cached inputs significantly reduced to $0.175 per million tokens. GPT-5 nano, the most budget-friendly option, is priced at $0.05 per million tokens. Users can benefit from a 50% discount through the Batch API for asynchronous tasks completed within 24 hours. High-volume workloads gain additional savings through Azure OpenAI's Provisioned Throughput Units (PTUs), which provide stable capacity at reduced rates. Prompt caching further lowers costs, offering up to a 90% discount for repetitive tasks - ideal for large-scale data analysis or overnight document processing. OpenAI also emphasizes strict governance to maintain operational security.
OpenAI prioritizes security and compliance, holding SOC 2 Type 2 certification and encrypting data both at rest (AES-256) and in transit (TLS 1.2+). The platform supports GDPR and HIPAA compliance through Data Processing Addendums and Business Associate Agreements. Rigorous testing has improved model reliability, with deception rates reduced from 4.8% to 2.1% and sycophantic replies lowered from 14.5% to under 6%. By default, OpenAI does not train models on business data from ChatGPT Enterprise, Team, Edu, or API users. For added security, eligible API users can request Zero Data Retention, ensuring no data is stored beyond the immediate request. GPT-5 underwent extensive testing, with 5,000 hours of red-teaming alongside partners like the UK AISI to address risks related to biology, chemistry, and cybersecurity.

Claude Opus 4.6, currently in beta, offers an impressive 1 million token context window, enabling it to handle extensive codebases and process hundreds of pages in a single session. This model is available in three versions - Opus 4.6, Sonnet 4.5, and Haiku 4.5 - each tailored to meet specific enterprise requirements. Notably, Opus 4.6 scored 80.8% on SWE-bench Verified for agentic coding and 99.3% on tool use benchmarks in telecom scenarios, showcasing its ability to handle intricate workflows.
Claude is designed to integrate seamlessly with major cloud platforms, ensuring flexibility for diverse enterprise environments.
The model connects with Amazon Bedrock, Google Cloud's Vertex AI, and Microsoft Azure AI Foundry through its Model Context Protocol (MCP). This allows for smooth interaction with remote servers and external data sources. Additionally, its system interaction capabilities enable it to interface with standard software by taking screenshots and performing mouse and keyboard commands. This makes it compatible with both legacy systems and modern enterprise tools. Prebuilt agent skills support widely used file formats, including Microsoft PowerPoint, Excel, Word, and PDF. In February 2026, Box evaluated Opus 4.6 for high-reasoning tasks involving legal and technical content, where it achieved a 68% success rate, a 10% improvement over their baseline.
The pricing structure is as follows:
For asynchronous tasks, the Batch API offers a 50% discount, and prompt caching further reduces expenses by storing frequently accessed context for either 5 minutes or 1 hour. These cost-saving measures align with its enterprise-focused features.
Claude Opus 4.6 includes an Adaptive Thinking feature, which adjusts its reasoning depth based on the complexity of the task. Users can set effort levels ranging from low to maximum. Early adopters have reported substantial benefits, including an estimated 3-5x ROI across knowledge-based roles. Content marketing teams experienced 40-60% time savings and a 25% boost in content quality scores, while research and analysis teams saw 50-70% time savings and a 30% improvement in analysis depth. The model’s training data cutoff is August 2025, with a knowledge cutoff in May 2025.
Anthropic adheres to a Responsible Scaling Policy (RSP) that assigns AI Safety Levels to its models. Both Claude Opus 4.6 and Sonnet 4.5 meet ASL-3 standards, which include rigorous security protocols to mitigate high-risk scenarios. The model achieved a 99.78% harmless response rate for single-turn violative requests and blocked 99.4% of prompt injection attacks in computer control tests. Anthropic is SOC 2 Type II certified and ensures no customer data from commercial API users is used for training. Regional endpoints via AWS Bedrock and Google Vertex AI provide compliance with US data sovereignty requirements, making it a reliable choice for regulated industries.
Gemini 3 Pro has demonstrated exceptional performance, scoring 100% on the AIME 2025 high school mathematics benchmark and 91.9% on the GPQA Diamond reasoning benchmark. With an intelligence score of 48, it ranks among the top-performing models worldwide. The model offers a context window of up to 2 million tokens for developers and 1 million tokens for advanced users, enabling it to handle large-scale codebases and documents. Additionally, the Gemini 2.5 Flash-Lite model processes outputs at an impressive 439 tokens per second, making it a standout choice for high-volume tasks.
Gemini Enterprise serves as an autonomous platform that seamlessly integrates with company data across Google Workspace, Microsoft 365 (including SharePoint and OneDrive), and business tools like Salesforce, SAP, ServiceNow, Jira, and Confluence. It supports the Model Context Protocol (MCP) for universal data integration and the Agent2Agent (A2A) Protocol to enable communication between different AI agents across platforms. A no-code agent builder allows non-technical teams in marketing, finance, and HR to create custom agents without requiring IT assistance. For developers, the Google Agent Development Kit (ADK) provides tools to integrate Gemini into CI/CD pipelines, streamlining automated testing and code analysis.
| Model | Input (per 1M tokens) | Output (per 1M tokens) |
|---|---|---|
| Gemini 3 Pro | $2.00 ($4.00 > 200k tokens) | $12.00 ($18.00 > 200k tokens) |
| Gemini 3 Flash | $0.50 | $3.00 |
| Gemini 2.5 Flash-Lite | $0.17 | $0.17 |
The Business Edition is priced at $21 per seat per month (for 1–300 seats) with 25 GiB of pooled storage, while the Standard/Plus Editions start at $30 per seat per month (unlimited seats) with up to 75 GiB of storage. The model’s sparse mixture-of-experts architecture separates capacity from serving costs, making Gemini 3 Pro an economical choice for handling complex reasoning tasks. These pricing structures allow enterprises to maximize Gemini’s capabilities across various operational needs.
Gemini’s interoperability drives tangible business outcomes in workflow optimization. For instance, in October 2025, Klarna utilized Gemini and Veo to create personalized lookbooks, leading to a 50% increase in orders. Mercari reduced its customer service workload by at least 20%, achieving a projected 500% ROI. Commerzbank used Gemini-powered "Bene" chatbot to manage over two million chats, resolving 70% of all inquiries. Meanwhile, Swarovski reported a 17% increase in email open rates and achieved 10× faster campaign localization using Vertex AI. The platform also offers prebuilt agents like Deep Research, NotebookLM Enterprise, and Gemini Code Assist Standard, enabling immediate deployment for knowledge-intensive workflows.
Gemini Enterprise is designed to meet stringent compliance standards, including HIPAA and FedRAMP High, making it suitable for regulated industries. Security features include VPC-Service Controls (VPC-SC), Customer-Managed Encryption Keys (CMEK), and Access Transparency. The Model Armor feature actively detects and mitigates prompt injection and jailbreaking attempts, while SynthID embeds watermarks into AI-generated content for easy identification. Additionally, Google’s Frontier Safety Framework assesses risks related to CBRN, cybersecurity, and harmful manipulation. Importantly, customer data from the Business, Standard, and Plus editions is neither used to train Google’s models nor sold to third parties, ensuring data sovereignty and privacy for enterprise users. These rigorous governance measures position Gemini as a trusted solution for managing interoperable AI workflows.
Meta's LLaMA series offers an open-weight architecture that allows businesses to download, customize, and deploy models directly within their own infrastructure. At the forefront is the Llama 4 Scout, which boasts a 10 million token context window and processes up to 2,600 tokens per second. With a low latency of 0.33 seconds for the first token, this model is well-suited for tasks like high-volume document processing and real-time operations.
LLaMA's open-source design makes it easy to integrate into existing enterprise systems, ensuring better control over data and compliance. Businesses can deploy the models on-premises, in hybrid setups, or across various cloud providers such as AWS, Google Cloud, Microsoft Azure, and IBM WatsonX. The models also work seamlessly with frameworks like NVIDIA's NeMo, enabling tailored solutions within current tech ecosystems. According to IBM, open-source LLMs give enterprises the flexibility to build and fine-tune applications for specific needs, which is particularly valuable in regulated industries like finance and healthcare where data control is paramount. This integration not only simplifies in-house deployment but also reduces costs significantly.
LLaMA offers a pricing model that provides major savings compared to proprietary options. For instance, the Llama 3.2 1B model is priced at $0.03 per million tokens, while the Llama 4 Scout costs $0.29 per million tokens. For large-scale workloads, self-hosting eliminates per-token API fees altogether. In November 2025, an e-commerce company transitioned its non-critical analytics from proprietary cloud APIs to Meta Llama 4, cutting 82% of LLM-related costs while maintaining accuracy, thanks to the model's extensive context window. Businesses processing 30 million tokens daily can save between 40% and 200% by spreading hardware costs over time. With self-hosted setups, token costs can drop to as low as $0.001 to $0.04 per million tokens, even factoring in electricity costs.
LLaMA strengthens its appeal with a governance framework that applies safeguards at every stage - training, fine-tuning, and application. Tools like Llama Guard 2 use the MLCommons taxonomy to filter prompts and responses, while Code Shield prevents unsafe code outputs during inference. During training, data sources with significant amounts of personal information are excluded. Meta also works with AI Safety Institutes in the U.S. and U.K. to establish robust threat models. Rigorous testing, including red teaming, ensures the model is resistant to risks like chemical, biological, and cybersecurity threats. The open-weight structure allows organizations to host models locally, ensuring full control over sensitive data and meeting stringent compliance standards. By combining flexibility, cost-effectiveness, and security, LLaMA supports the growing demand for self-managed AI solutions.
The following breakdown highlights the core trade-offs of each platform based on their strengths and limitations. OpenAI's GPT-5 is known for its fast API integration and seamless compatibility with Microsoft Azure, making deployment straightforward. However, its proprietary architecture can be a drawback for organizations prioritizing local control and data sovereignty, especially when handling sensitive information. Its pricing sits at a mid-tier level, which aligns with its strong performance, achieving a 92.4% score on the GPQA Diamond benchmarks.
Anthropic's Claude stands out in industries like finance, law, and healthcare due to its Constitutional AI framework, which enforces strict ethical safeguards. The platform integrates effectively with popular enterprise tools such as Slack, Notion, and Microsoft 365. A notable achievement of Claude Opus 4.6 is identifying over 500 zero-day vulnerabilities, demonstrating its technical robustness. However, its higher cost can pose challenges for organizations managing large-scale workloads.
Google DeepMind's Gemini provides seamless integration with Google Cloud Vertex AI and Workspace tools like Docs and Gmail, along with an impressive 2 million+ token context window. Its pricing remains competitive, but its reliance on the Google Cloud ecosystem could lead to potential vendor lock-in, reducing flexibility for hybrid or alternative deployments.
Meta's LLaMA offers unmatched flexibility with its open-weight architecture, allowing teams to download, customize, and self-host models on their own infrastructure. Llama 4 Scout features an expansive 10 million token context window and provides cost-effective options, especially when self-hosted. However, this flexibility comes with operational challenges, as deploying and maintaining LLaMA requires significant internal infrastructure and technical expertise. Additionally, organizations with over 700 million monthly users must navigate specific licensing agreements.
Below is a table summarizing the key strengths and weaknesses of each platform:
| Company | Key Strengths | Primary Weaknesses |
|---|---|---|
| OpenAI (GPT-5) | Fast API integration; Azure enterprise support; multimodal capabilities | Proprietary architecture; limited data control; mid-tier pricing |
| Anthropic (Claude) | Ethical safeguards for regulated industries; enterprise tool compatibility; strong security | High cost; proprietary restrictions |
| Google (Gemini) | Google Cloud/Workspace integration; 2M+ token context window; competitive pricing | Risk of vendor lock-in with Google Cloud ecosystem |
| Meta (LLaMA) | Open weights; full customization; low cost; 10M token context window | High infrastructure demands; technical expertise required; licensing constraints for large-scale use |
When selecting a large language model (LLM), focus on how well it aligns with your business needs rather than relying solely on benchmark scores. For tasks like workflow automation and multi-step reasoning, OpenAI's GPT-5 and Google's Gemini 2.5 Pro offer structured reasoning and precise outputs. On the other hand, creative endeavors are better suited to models like Claude 4.5 Sonnet and GPT-5. These differences highlight the importance of matching model capabilities to specific operational goals.
If data sovereignty and customization are top priorities, Meta's Llama 4 and Mistral Large 2.1 are strong contenders. These open-weight models allow full self-hosting on private infrastructure, eliminating vendor lock-in. However, this flexibility comes with added demands, such as technical expertise and GPU cluster costs ranging from $5,000 to $15,000 per month. For teams handling extensive document analysis, certain models excel at processing high volumes efficiently.
"The best AI platform is the one your team can standardize on." – Maya R. Patel, AI Tools & Automation Editor
Strategically routing tasks to the right models can lead to substantial savings and improved efficiency. For instance, organizations can cut costs by 40–60% by assigning simpler tasks to budget-friendly models like DeepSeek V3.2 while reserving high-performing models, such as Claude Opus 4.5, for complex reasoning tasks. Testing each model on 20 specific tasks relevant to your business before a full rollout ensures the best fit for your needs.
When building automated agents, prioritize models that offer robust API support for structured outputs and function calling. With nearly 60% of consumers using AI tools powered by LLMs daily - and research and summarization being the most common use case for 56% of users - the platform you choose should be able to scale alongside your team’s evolving needs and the rapid advancements in AI capabilities through 2026 and beyond.
To select the most suitable large language model (LLM), start by identifying your specific requirements - whether it's generating creative content, automating workflows, or improving customer interactions. Key considerations include performance, cost, context window size, and support for multimodal inputs. Ensure the chosen model aligns with your existing infrastructure for seamless integration. Leveraging orchestration platforms can simplify managing multiple models while keeping costs under control, especially for enterprise-level applications.
A larger context window enables a large language model (LLM) to handle more text simultaneously, which helps it stay consistent across extended conversations or documents. This capability enhances tasks such as summarization, logical reasoning, and multi-turn dialogues by offering a wider "memory" of the input. It minimizes the need to manually break text into smaller sections and ensures outputs are more cohesive and accurate, particularly when dealing with lengthy or intricate content.
To get a clear picture of LLM deployment costs, start by reviewing pricing details from different providers and models. Leverage tools such as pricing calculators or comparison tables to break down expenses like token costs, API usage, and model-specific parameters. These tools allow you to simulate workloads, giving you a better understanding of potential costs and helping you make well-informed decisions before investing in an LLM.