Pay As You Go - AI Model Orchestration and Workflows Platform


AI model orchestration simplifies managing the entire machine learning lifecycle, bridging the gap between development and production with automation, governance, and scalability. Four key platforms dominate this space: Prompts.ai, TensorFlow Extended (TFX), Kubeflow, and MLflow. Each caters to different needs:
Key Takeaways:
Quick Comparison:
| Tool | Best For | Strengths | Challenges | Pricing |
|---|---|---|---|---|
| Prompts.ai | LLM workflows | Multi-model orchestration, cost control | Limited to NLP tasks | Starts at $0; $99–$129/month |
| TFX | TensorFlow pipelines | Scalable, robust governance | Tied to TensorFlow | Moderate; best on Google Cloud |
| Kubeflow | Kubernetes-based scaling | Handles large clusters | Steep learning curve | High; requires 8 vCPUs, 32 GiB RAM |
| MLflow | Experiment tracking | Framework-agnostic, easy setup | Metadata bottlenecks | Low; SQLite or MySQL/PostgreSQL |
Choose the right platform based on your team's needs. For LLM orchestration, Prompts.ai offers unmatched flexibility and cost efficiency. For TensorFlow users, TFX delivers scalable production pipelines. If you’re managing large Kubernetes clusters, Kubeflow is ideal, while MLflow excels in tracking and managing experiments across frameworks.

AI Model Orchestration Platforms Comparison: Features, Pricing, and Best Use Cases
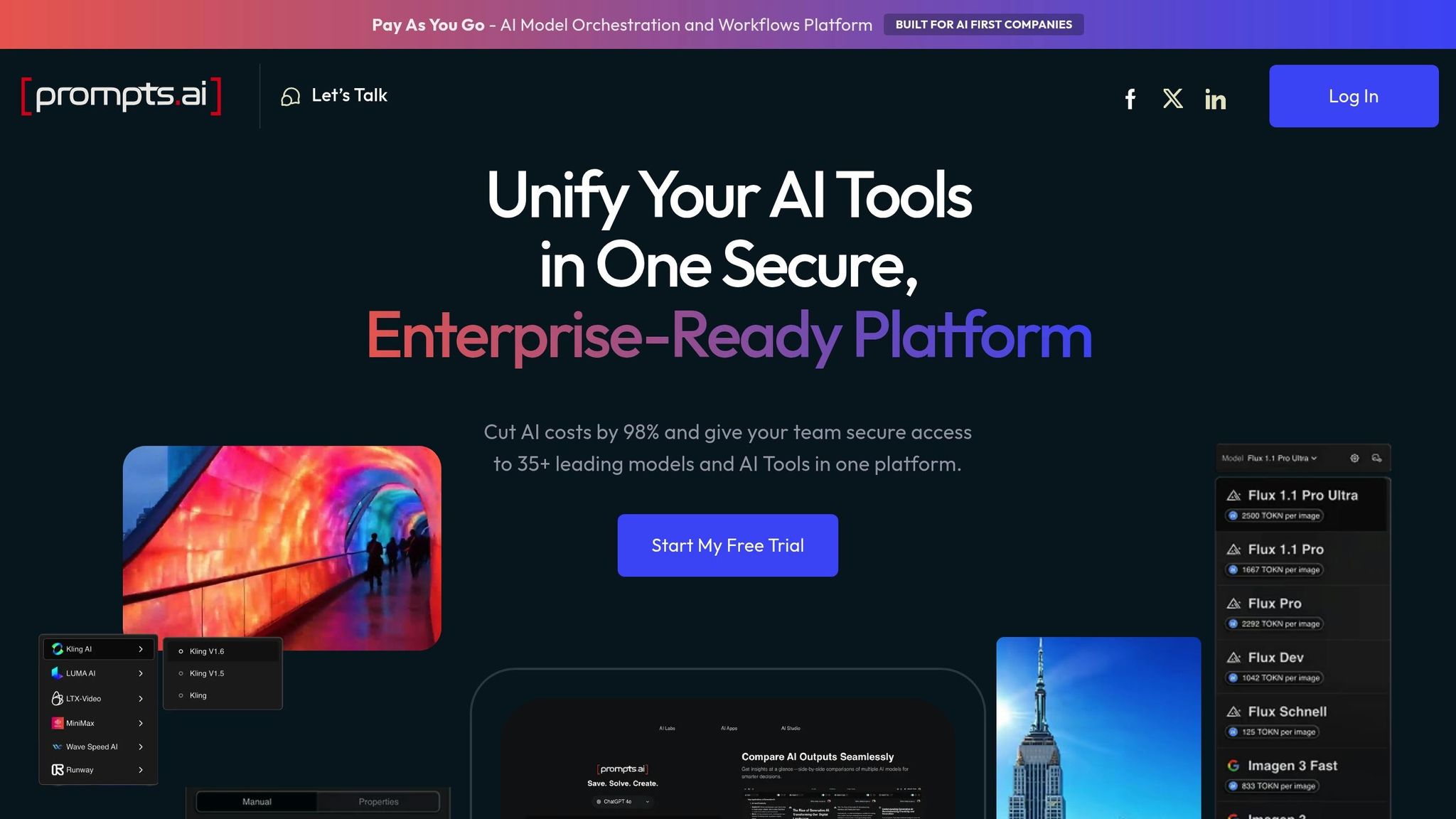
Prompts.ai brings together over 35 leading large language models - including GPT-5, Claude, LLaMA, Gemini, Grok-4, Flux Pro, and Kling - into a single, streamlined platform. This simplifies vendor management and allows for effortless integration.
The platform’s design makes switching between models easy, without requiring changes to workflows. Users can directly compare outputs from different models side-by-side, making it simple to select the best option based on performance or speed. This is especially useful since some models excel in specific areas - one might be better for technical documentation, while another shines in generating creative content. The platform’s flexibility is further enhanced by its robust cost-saving features, detailed below.
Prompts.ai integrates real-time FinOps tools to monitor token usage and spending at the user, team, and project levels. The platform’s pay-as-you-go TOKN credit system eliminates the need for recurring subscriptions, charging only for actual usage. This approach can cut AI software costs by as much as 98%. Finance teams benefit from detailed insights into which models, prompts, and workflows are driving costs, enabling smarter resource allocation and better budget management.
In addition to its model versatility, Prompts.ai prioritizes security and compliance. The platform includes enterprise-grade security features, such as audit trails that log every interaction, prompt, and model response. Administrators can set access permissions, create approval workflows for sensitive tasks, and ensure data stays within the organization’s security perimeter. These built-in governance tools help meet regulatory and internal compliance requirements without the need for custom solutions.
Prompts.ai’s cloud-native design ensures it can scale effortlessly, whether for a small team or a Fortune 500 company. Organizations can quickly add models, users, or teams to handle growing demands. The platform easily manages workload spikes, such as those during product launches or seasonal surges, without requiring manual infrastructure adjustments. Pricing starts at $0 for individual pay-as-you-go plans, with business plans ranging from $99 per member monthly for the Core tier to $129 per member monthly for the Elite tier.
TFX, developed by Google, is a production-grade machine learning platform designed to simplify workflows through its standardized components like ExampleGen, Trainer, Evaluator, and Pusher. Its architecture is built on three key elements - Driver, Executor, and Metadata Publisher - ensuring smooth operations for tasks like multi-model orchestration, governance, and large-scale deployments.
With its Evaluator component, TFX can compare candidate models against a baseline, while the Pusher deploys multiple model versions across platforms like TensorFlow Serving, TensorFlow Lite, and TensorFlow.js. Its Python-based domain-specific language (DSL) allows pipelines to transition effortlessly between Apache Airflow, Kubeflow Pipelines, and Apache Beam without requiring code modifications.
TFX uses ML Metadata (MLMD) to track every artifact, ensuring traceability for audits and compliance. For example, in March 2023, Vodafone enhanced its governance by combining TensorFlow Data Validation (TFDV) with Google Cloud. To further boost reliability, the InfraValidator performs canary deployments in isolated environments, preventing unservable models from being pushed to production.
TFX achieves scalability through Apache Beam’s data-parallel processing, which operates on distributed systems like Google Cloud Dataflow, Apache Flink, and Apache Spark. It also optimizes performance by caching results in the Driver to avoid redundant computations. In October 2023, Spotify leveraged TFX to optimize its production pipelines for music recommendations, while TensorFlow Serving ensured efficient and distributed model inference.
Kubeflow is a platform designed for Kubernetes environments, tailored to streamline AI model orchestration. It utilizes Kubeflow Pipelines (KFP) to structure workflows as directed acyclic graphs (DAGs), enabling seamless management of tasks from training to deployment. Its architecture supports scaling workloads from a single machine to massive production clusters with thousands of GPUs, all while maintaining consistent APIs. This approach simplifies the transition from development to production for enterprises.
The Model Registry serves as a centralized hub for storing machine learning metadata and artifacts, simplifying the management of multiple models as they move through their lifecycle. Kubeflow supports a variety of frameworks and pre-trained models, such as BERT and Llama, through its unified SDK. This SDK abstracts the complexities of Kubernetes, presenting users with a single set of APIs for easier interaction. Workflows are compiled into a YAML-based intermediate format, ensuring consistent execution across KFP-compliant backends, whether running locally or on cloud platforms like Google Cloud Vertex AI.
Kubeflow Pipelines offers tools for tracking pipeline definitions, runs, experiments, and artifacts, ensuring traceability and compliance. Much like TFX, it provides audit capabilities that help maintain accountability. The Profile Controller manages user profiles and isolates environments to support secure multi-tenancy. Additionally, the Kubeflow Central Dashboard provides an authenticated interface to access various platform components securely. With over 258 million PyPI downloads and contributions from more than 3,000 developers, Kubeflow operates under the oversight of the Kubeflow Steering Committee (KSC), ensuring structured governance.
Kubeflow is built to handle workloads that require extensive computational resources. The Kubeflow Trainer facilitates distributed training for models that exceed the capacity of a single GPU, making it particularly effective for fine-tuning large language models (LLMs). Tasks are executed in parallel, with caching mechanisms reducing costs and processing times. For production models, KServe manages scalable online and batch inference, while Kubernetes' native features allow the platform to dynamically scale microservices based on demand. This design ensures efficient scaling across different infrastructures.
MLflow simplifies the entire AI model lifecycle, from development to deployment. With over 30 million downloads each month and contributions from more than 850 developers worldwide, it drives AI production workloads for thousands of enterprises globally. The latest version, 3.0, introduced new features to handle complex workflows that integrate traditional machine learning, deep learning, and generative AI into one cohesive system.
The "LoggedModel" feature in MLflow packages everything - code, prompts, LLM parameters, and retrieval logic - into a single artifact. This framework-agnostic setup supports over 20 generative AI libraries alongside popular frameworks like scikit-learn, PyTorch, TensorFlow, and XGBoost. MLflow Tracing records inputs, outputs, and intermediary states throughout multi-step workflows, making it easier to evaluate and debug hybrid RAG systems. Automated instrumentation, such as mlflow.llama_index.autolog(), synchronizes agent behaviors and tool interactions, cutting down on manual coding efforts. Using MLflow's LLM judges for systematic evaluation has boosted retrieval relevance in customer-facing applications from 65% to 91%.
In addition to managing models, MLflow provides tools to monitor and optimize operational costs.
MLflow Tracing offers insight into the cost and latency of each request, enabling teams to fine-tune resource allocation. Some production setups have reduced response times by over 50% through parallelized workflows and filtered processing. The Prompt Registry uses Git-style versioning and visual comparisons to prevent costly regressions during updates. Teams can also use the mlflow.log_input() API to track evaluation datasets and custom metrics as governed assets, ensuring resources are used efficiently across projects.
While cost control is crucial, governance features play a key role in ensuring reliable and secure workflows.
Unity Catalog powers MLflow’s governance capabilities, providing centralized access control and detailed audit trails. The Model Registry automatically links model versions to their corresponding MLflow runs, code versions, and training datasets, ensuring full reproducibility and traceability. Role-based access control allows for precise permissions across teams. Sam Chou, Principal Engineer at Barracuda, highlighted the importance of these features:
"MLflow 3.0's tracing has been essential to scaling our AI-powered security platform. It gives us end-to-end visibility into every model decision, helping us debug faster, monitor performance, and ensure our defenses evolve as threats do."
The Model Registry also supports aliases like @champion or @staging, enabling seamless updates to production models without requiring changes to downstream code.
MLflow’s distributed architecture ensures scalability by storing metadata in production-grade databases like PostgreSQL or MySQL and model weights in object storage such as Amazon S3. It integrates with KServe and Seldon Core to enable autoscaling, canary rollouts, and A/B testing for Kubernetes-based deployments. MLServer, an alternative to the default FastAPI-based server, offers enhanced scalability for inference tasks. Built on OpenTelemetry, MLflow’s tracing infrastructure is optimized for large-scale observability with minimal performance overhead. Unified APIs allow for seamless deployment to managed services like Amazon SageMaker, Azure ML, and Databricks Model Serving, which handle scaling automatically.
These robust features make MLflow a key player in enabling efficient, secure, and scalable AI workflows.
Examining the strengths and weaknesses of these orchestration platforms sheds light on their roles in simplifying AI workflows. Each tool comes with specific trade-offs that organizations must weigh when building and deploying AI models efficiently.
Prompts.ai is a standout for LLM orchestration, offering support for over 35 models and excelling in NLP-focused applications. However, its specialization in NLP means it’s not as effective for traditional machine learning tasks.
TensorFlow Extended (TFX) is known for its end-to-end production pipelines, offering strong data validation and model serving capabilities. That said, its reliance on the TensorFlow ecosystem can be a limitation for teams that prefer other frameworks like PyTorch.
Kubeflow shines in Kubernetes-native scalability, capable of managing over 1,000 parallel jobs with resource utilization rates between 85–90% across distributed clusters. However, it comes with significant setup challenges - experienced teams may need 2–3 weeks, while those new to Kubernetes could take 2–3 months. Even a development environment requires at least 8 vCPUs and 32 GiB of RAM, making Kubernetes expertise essential.
MLflow is appealing for its ease of integration and minimal infrastructure requirements, supporting over 50 frameworks for tracking experiments quickly. However, it struggles with metadata bottlenecks when handling more than 100 simultaneous experiments and lacks the production-level orchestration capabilities found in TFX or Kubeflow.
The table below compares these tools across essential deployment factors:
| Tool | Ease of Integration | Scalability | Interoperability | Infrastructure Requirements |
|---|---|---|---|---|
| Prompts.ai | High for LLM tasks; user-friendly interface | Optimized for prompt-based deployments | Focused on LLMs and NLP workflows | Minimal infrastructure needs |
| TFX | Moderate; requires Apache Beam or Dataflow | High; leverages Dataflow for scale | Tightly integrated with TensorFlow | Moderate; works best with Google Cloud |
| Kubeflow | Low; steep learning curve for Kubernetes | Excellent; handles 1,000+ parallel jobs | High; supports TensorFlow, PyTorch, and others | High; needs 8 vCPUs, 32 GiB RAM |
| MLflow | High; supports 50+ frameworks easily | Good; scales horizontally but bottlenecks above 100 experiments | Framework-agnostic; works across Python ML libraries | Low; SQLite or PostgreSQL/MySQL for scaling |
To maximize efficiency, teams often combine these tools. For example, MLflow can handle experiment tracking while Kubeflow manages scalable infrastructure. Similarly, TFX's robust production pipelines can complement MLflow's reproducibility features. This hybrid approach allows organizations to leverage the best of each platform while addressing their unique challenges.
Prompts.ai stands out as the go-to solution for modern AI workflows, designed to tackle the unique challenges teams face in orchestrating language model operations. If your team is grappling with inefficiencies or complexity, this platform offers a way to simplify and optimize your processes.
With integration across 35+ leading language models and built-in real-time FinOps cost controls, Prompts.ai addresses key pain points in AI orchestration. It simplifies multi-model integration, removing the headache of managing multiple vendors. Enterprise-grade governance features ensure compliance and security, while its cloud-native scalability adapts seamlessly to teams of all sizes, from startups to Fortune 500 enterprises - no manual infrastructure tweaks required.
"Choose the platform that removes friction for your specific team composition and infrastructure reality, not the one with the longest feature list." - Arthur C. Codex
The platform's pay-as-you-go TOKN credit system offers a flexible pricing model that can slash AI software costs by up to 98%, all while providing granular insights into resource use by user, team, and project. By unifying experiment tracking, cost management, and production deployment, Prompts.ai eliminates the need for juggling multiple tools, making your workflow smoother and more efficient.
Whether your challenge lies in reproducibility, deployment automation, or scaling infrastructure, Prompts.ai provides targeted solutions. Testing the platform with your actual workflows through a proof of concept ensures it meets your needs. To maximize its benefits, start by standardizing how you log dataset versions and model signatures.
Prompts.ai equips teams with the tools they need to streamline AI model deployment, cut costs, and unlock measurable business value.
AI model orchestration refers to managing and automating the deployment and operation of multiple AI models, systems, and workflows. It brings together elements like data pipelines, computational resources, and models to enable smooth interaction between them. By streamlining tasks such as data processing and model retraining, it boosts efficiency, scalability, and responsiveness, making it a crucial approach for managing complex AI systems and workflows.
Choosing the best orchestration tool hinges on your team’s specific needs, skill set, and existing infrastructure. Key considerations include coding preferences (like Python), the triggers required for your workflows, scalability demands, and whether open-source solutions are a must for your organization. For enterprise-level AI workflows, platforms such as prompts.ai stand out, providing features like cost control, governance, and scalability. To make an informed choice, identify your main objective - whether it’s streamlining data workflows, deploying models, or handling large language models - and let that steer your decision.
For managing governance and controlling costs in AI orchestration, it's crucial to use tools designed to streamline expenses and uphold compliance. Look for features such as credits that help reduce costs and integrated model registries that provide better oversight. Platforms that emphasize reproducibility, auditability, and scalable resource management are essential for maintaining transparency and minimizing waste. Strong governance practices include monitoring workflows, data, and models to ensure compliance while keeping operations efficient.

















