Pay As You Go7 天免费试用;无需信用卡


In a crowded AI landscape, choosing the right large language model (LLM) can be overwhelming. With models like GPT-5, Claude, and Gemini excelling in different areas, comparison platforms simplify the decision-making process by offering side-by-side analyses of performance, costs, and use cases. Here's what you need to know:
These platforms cater to different needs - whether you're optimizing costs, ensuring safety, or evaluating coding capabilities. Below is a quick comparison to help you decide.
| Platform | Model Focus | Key Features | Update Frequency | Cost Transparency |
|---|---|---|---|---|
| Prompts.ai | 35+ LLMs | Unified dashboard, cost tracking | Rapidly integrates new models | Real-time token usage |
| Artificial Analysis | Proprietary & open-source | Standardized benchmarks, weighted scoring | Regular updates | Not specified |
| LMSYS Chatbot Arena | Conversational models | Blind pairwise comparisons, user feedback | Continuous updates | Not specified |
| Vellum AI Leaderboard | Enterprise-ready models | Business-specific evaluation | Monthly | Detailed cost breakdown |
| LiveBench | Mixed (49+ models) | Contamination-resistant benchmarks | Every six months | Not specified |
| LLM-Stats | Aggregated benchmarks | Statistical insights | Not disclosed | Not disclosed |
| OpenRouter Rankings | Real-world use cases | Usage-based metrics | Regular | Focus on cost-performance |
| Hugging Face Leaderboard | Open-source models | Standardized testing | Continuous | Computational requirements |
| Scale AI SEAL | Enterprise safety-focused | Safety & alignment evaluations | Quarterly | Total cost of ownership |
| APX Coding LLMs | Coding models | Code-specific tasks, security standards | Monthly | Cost-per-token for coding |
Choosing the right platform depends on your goals - whether it's reducing costs, ensuring safety compliance, or enhancing productivity. Platforms like Prompts.ai stand out for enterprises managing multiple LLMs, while APX Coding LLMs is perfect for developers. Each tool offers a unique perspective to guide your AI strategy.

Prompts.ai is an enterprise AI platform designed to simplify the process of comparing and deploying large language models (LLMs). By consolidating over 35 leading LLMs into a single, unified dashboard, the platform eliminates the need for juggling multiple tools. This streamlined setup not only reduces complexity but also enables teams to make well-informed decisions by comparing models on performance, cost, and integration speed - all in one place.
Prompts.ai offers access to a wide range of state-of-the-art AI models, including GPT-5, Claude, LLaMA, Gemini, Grok-4, Flux Pro, and Kling, among others. This extensive library allows users to assess models with varying strengths and specialties without the hassle of switching platforms or managing multiple API keys.
The platform's ability to aggregate these models ensures users can evaluate them based on real-world applications. Whether it’s testing coding efficiency, creative writing skills, or expertise in specific domains, the side-by-side comparison feature enables simultaneous testing of identical prompts across multiple models.
Prompts.ai takes a user-first approach to model evaluation, offering flexibility that goes beyond generic benchmarks. Instead of relying on pre-set metrics, users can create personalized evaluation scenarios tailored to their unique needs, using their own prompts and data.
The platform’s interface displays results side by side, offering a clear view of output quality, response times, and methodologies. This approach is especially beneficial for businesses that need to test models against proprietary datasets or industry-specific challenges that standard benchmarks fail to address.
Prompts.ai integrates a FinOps layer that provides real-time tracking of token usage across all models. By monitoring token consumption, teams can directly compare performance and financial implications, making it easier to evaluate which models deliver the best value.
The platform’s Pay-As-You-Go TOKN credit system ensures that costs align with actual usage, potentially reducing expenses by up to 98%. For organizations managing tight budgets or allocating resources across multiple AI projects, this level of cost clarity supports smarter, data-driven decisions.
Prompts.ai keeps its users ahead of the curve by rapidly integrating new models as they become available. Its architecture is built for agility, ensuring emerging models are added quickly, so users don’t face delays in accessing the latest advancements.
Beyond new models, the platform also rolls out updates and optimizations seamlessly. As models improve and new versions are released, users can rely on Prompts.ai to provide uninterrupted access to these enhancements, enabling them to stay competitive in an ever-evolving AI landscape.
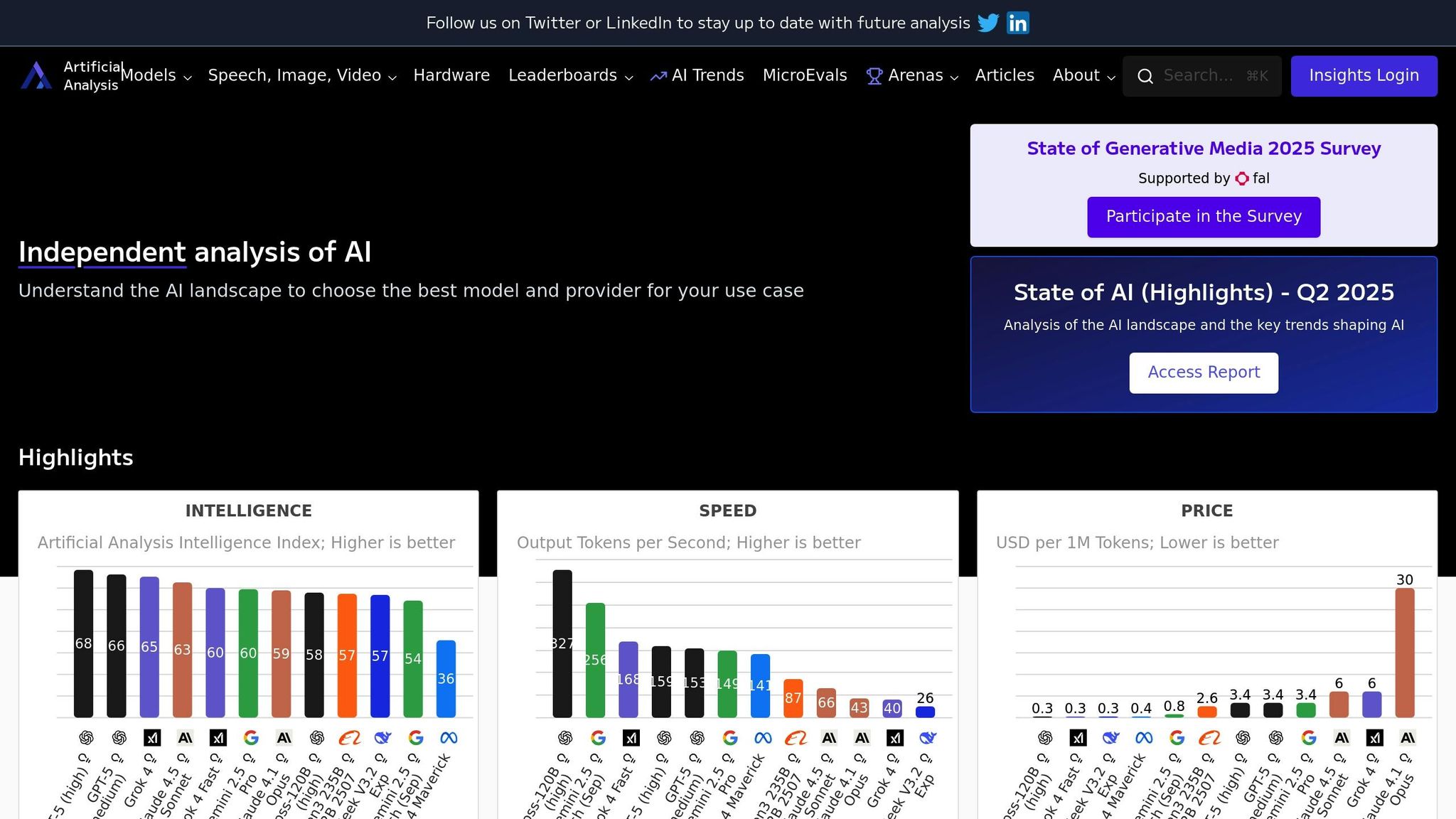
Artificial Analysis focuses on delivering consistent and thorough evaluations of large language models (LLMs) through standardized benchmarks and repeatable testing processes. By adhering to a systematic approach, the platform provides in-depth insights into how different LLMs perform across a variety of cognitive tasks and practical applications.
The platform maintains an extensive database that includes evaluations of both proprietary and open-source LLMs from leading AI developers like OpenAI, Anthropic, Google, Meta, and newer players in the field. It doesn’t stop at mainstream models but also includes specialized and fine-tuned versions, offering users the chance to explore options tailored to unique or niche requirements. This wide-ranging coverage ensures users can access performance data for virtually any model they might consider.
Artificial Analysis employs a robust Intelligence Benchmarking Methodology designed to evaluate models across multiple dimensions. Instead of relying on a single metric, the platform uses a weighted scoring system that assesses reasoning, accuracy, creativity, and task-specific capabilities. Each model is rigorously tested with standardized prompts and datasets, and the results are normalized to ensure fair comparisons across various architectures and sizes. A combination of automated scoring and human evaluations adds depth and reliability to these assessments.
Keeping up with the rapidly changing LLM landscape, Artificial Analysis frequently updates its methodologies. The most recent update, Version 3.0, was released on September 2, 2025. These regular updates ensure the platform remains a reliable source of up-to-date, actionable insights, enabling users to make informed decisions when selecting the best language model for their needs.
The LMSYS Chatbot Arena is a collaborative platform designed to assess large language models (LLMs) through real-time human feedback. This approach ensures that evaluations stay relevant by capturing both user interactions and ongoing improvements in the models.
The platform hosts a diverse selection of models, including proprietary, open-source, and experimental options. This allows users to test and compare how different models perform across a wide range of tasks and applications.
To minimize bias, users engage in blind pairwise comparisons between models. The results are then aggregated to rank the models based on their conversational quality, originality, and practical usefulness.
The leaderboard is continuously refreshed with user feedback, ensuring it reflects the latest model releases and performance trends.
The Vellum AI Leaderboard offers actionable insights into model performance, tailored specifically for practical business applications.
The leaderboard features a handpicked selection of commercial and open-source models designed for enterprise use. These include offerings from providers like OpenAI, Anthropic, and Google, alongside open-source options such as Llama 2 and Mistral.
What makes Vellum stand out is its focus on business-ready models. Instead of listing experimental or unproven options, it highlights models that have demonstrated reliability and are suitable for commercial deployment.
Vellum evaluates models using a structured approach across six key categories: reasoning, code generation, creative writing, factual accuracy, instruction following, and safety compliance.
Each model is tested with prompts that mimic real-world business scenarios, combining automated scoring with human review. This dual-layered evaluation ensures the results reflect practical usability rather than just theoretical benchmarks. Regular updates to the evaluation process ensure the leaderboard remains aligned with the latest developments in the LLM space.
The leaderboard is refreshed monthly, with additional updates for major model releases. This schedule ensures thorough testing while staying up to date with the fast-paced advancements in large language models.
Vellum also tracks historical performance, allowing users to review how models have evolved over time. This feature helps businesses make informed decisions about when to adopt new models or upgrade existing ones.
Vellum provides detailed cost breakdowns, including pricing per 1,000 tokens and estimated costs for tasks like customer support, content creation, and code assistance.
LiveBench tackles the challenge of data contamination by frequently updating its benchmark questions. This ensures models are evaluated on fresh material, preventing them from simply memorizing training data.
LiveBench supports a wide variety of models, ranging from smaller systems with 0.5 billion parameters to massive ones boasting 405 billion parameters. It has assessed 49 different large language models (LLMs), including leading proprietary platforms, prominent open-source alternatives, and niche specialized models.
The platform’s robust API compatibility allows seamless evaluation of any model with an OpenAI-compatible endpoint. This includes models from providers like Anthropic, Cohere, Mistral, Together, and Google.
As of October 9, 2025, the leaderboard showcases advanced models such as OpenAI's GPT-5 series (High, Medium, Pro, Codex, Mini, o3, o4-Mini), Anthropic's Claude Sonnet 4.5 and Claude 4.1 Opus, Google's Gemini 2.5 Pro and Flash, xAI's Grok 4, DeepSeek V3.1, and Alibaba's Qwen 3 Max.
LiveBench uses a contamination-resistant methodology, testing models across 21 tasks divided into seven categories, including reasoning, coding, mathematics, and language understanding. To maintain the integrity of its benchmarks, the platform refreshes all questions every six months and introduces more complex tasks over time. For instance, the latest version, LiveBench-2025-05-30, added an agentic coding task where models must navigate real-world development environments to resolve repository issues.
To further safeguard the evaluation process, around 300 questions from recent updates - roughly 30% of the total - remain unpublished. This ensures models cannot be trained on the exact test data. These measures, combined with regular updates, keep the benchmark relevant and challenging.
LiveBench follows a strict update schedule, releasing new questions consistently and refreshing the entire benchmark every six months. Users can request evaluations for newly developed models by submitting a GitHub issue or contacting the LiveBench team via email. This allows emerging models to be assessed without waiting for the next scheduled update. Recent additions from December 2024 include models like claude-3-5-haiku-20241022, claude-3-5-sonnet-20241022, gemini-exp-1114, gpt-4o-2024-11-20, grok-2, and grok-2-mini.
LLM-Stats provides a data-driven way to compare large language models by analyzing aggregated statistics from a variety of benchmarks. While it offers valuable insights into model performance, specifics such as how models are categorized, the evaluation methods used, pricing details, and how often the data is updated have not been shared. This statistical approach serves as a useful counterpart to the earlier qualitative comparisons.
OpenRouter Rankings takes a practical approach to evaluating language model performance, focusing on how models perform in real-world scenarios rather than relying solely on technical benchmarks. By aggregating data from everyday use, it highlights which models truly deliver value in practical applications. This emphasis on real-world metrics complements the more detailed technical evaluations provided by other platforms.
The platform includes a variety of language models, organized based on their specific applications. By categorizing models according to their use cases, it helps users easily identify the solutions that align with their particular needs.
OpenRouter Rankings uses a usage-based evaluation system, considering multiple factors like response quality, efficiency, and cost. These metrics are combined into composite scores that provide a clear picture of each model’s overall effectiveness and value.
The rankings are updated regularly to account for changes in model performance and usage trends, ensuring the data remains relevant and up-to-date.
A key focus of the platform is on economic factors. By analyzing pricing and cost-related metrics, it provides clarity on the balance between cost and performance, helping users make informed decisions.
The Hugging Face Open LLM Leaderboard stands out as a dedicated platform for evaluating the performance of open-source language models. Designed by Hugging Face, it serves as a central resource for researchers and developers looking to compare models against standardized benchmarks. By focusing exclusively on open-source models, the leaderboard aligns with the needs of those who value transparency and open accessibility in their AI solutions. It complements the enterprise and performance-driven comparisons discussed earlier, offering a unique perspective on the open-source AI landscape.
The leaderboard organizes a wide range of open-source models by parameter size - 7B, 13B, 30B, and 70B+ - spanning both experimental designs and large-scale implementations from leading research institutions.
It features contributions from organizations and individual developers, fostering a diverse and dynamic ecosystem that reflects the current state of open-source AI. Each model entry includes detailed information on architecture, training data, and licensing terms, enabling users to make informed choices based on their project needs and compliance requirements.
Using a standardized evaluation framework, Hugging Face assesses models on multiple benchmarks, offering a thorough analysis of their capabilities. These benchmarks cover reasoning skills, knowledge retention, mathematical problem-solving, and reading comprehension, ensuring a well-rounded view of each model's performance.
The platform employs automated pipelines to maintain consistent testing conditions across all models. This eliminates discrepancies caused by varying environments or methodologies, providing users with reliable, apples-to-apples comparisons to identify the best fit for their specific use cases.
The leaderboard is continuously updated with new models as they emerge in the open-source community. Thanks to its automated evaluation process, models can be assessed and ranked quickly without delays caused by manual intervention.
Additionally, the platform re-evaluates existing models whenever benchmark methodologies are refined. This ensures older models remain fairly represented, maintaining the leaderboard's relevance and trustworthiness over time.
While the leaderboard doesn’t provide direct pricing, it includes key details such as model size, memory requirements, and inference speed. These metrics help users estimate the infrastructure costs involved in deploying each model.
This focus on computational requirements allows organizations to make budget-conscious decisions, especially those working with limited resources or specific hardware constraints. By emphasizing open-source models, the platform also eliminates ongoing licensing fees, making the total cost of ownership more predictable and often more manageable compared to proprietary alternatives.
The Scale AI SEAL Leaderboard is dedicated to evaluating the safety, alignment, and performance of large language models (LLMs), addressing key enterprise concerns about deploying AI responsibly. Unlike general-purpose leaderboards, SEAL focuses on assessing how well models handle sensitive content, adhere to ethical guidelines, and maintain consistent behavior across varied scenarios. This highlights the importance of safety and ethical compliance alongside raw performance in enterprise environments. Its specialized approach provides detailed insights into model capabilities, evaluation methods, update schedules, and associated costs.
SEAL reviews a mix of proprietary and open-source models, with a strong focus on those commonly used in business applications. The leaderboard includes high-profile commercial models like GPT-4, Claude, and Gemini, as well as popular open-source options such as Llama 2 and Mistral variants.
What distinguishes SEAL is its emphasis on enterprise-ready models rather than experimental or research-focused versions. Each model is tested across various parameter sizes and fine-tuned configurations, offering a deeper understanding of how these variations impact the balance between safety and performance. The platform also evaluates specialized models tailored for industries like healthcare or finance, where regulatory compliance and risk management are critical.
SEAL uses a thorough evaluation framework that blends traditional performance metrics with extensive safety tests. Models are assessed on their ability to reject harmful prompts, maintain factual accuracy, and avoid producing biased or discriminatory outputs.
The evaluation process includes red-teaming exercises and human reviews to uncover vulnerabilities and subtle biases that automated testing might overlook. By combining automated and manual assessments, SEAL ensures that safety considerations are given equal weight alongside performance metrics.
The SEAL Leaderboard is updated quarterly, reflecting the detailed and safety-centered nature of its evaluations. Each update incorporates newly released models and re-evaluates existing ones against evolving safety benchmarks and standards.
In addition to these scheduled updates, Scale AI releases interim reports when significant model updates or safety-related incidents occur within the AI community. This adaptive approach ensures that enterprise users have timely access to the latest safety assessments, which is especially important given the rapid pace of model advancements. These regular updates also provide valuable data for analyzing deployment costs.
While SEAL doesn’t disclose direct pricing, it offers insights into the total cost of ownership, including factors like content moderation, compliance requirements, and liability risks. This helps enterprises weigh the costs of safety measures against operational expenses.
The platform also provides guidance on infrastructure needs for various safety configurations, helping organizations understand the trade-offs between enhanced safety and operational costs. For enterprise users, SEAL estimates potential savings from reduced content moderation efforts when deploying models with robust built-in safety features.
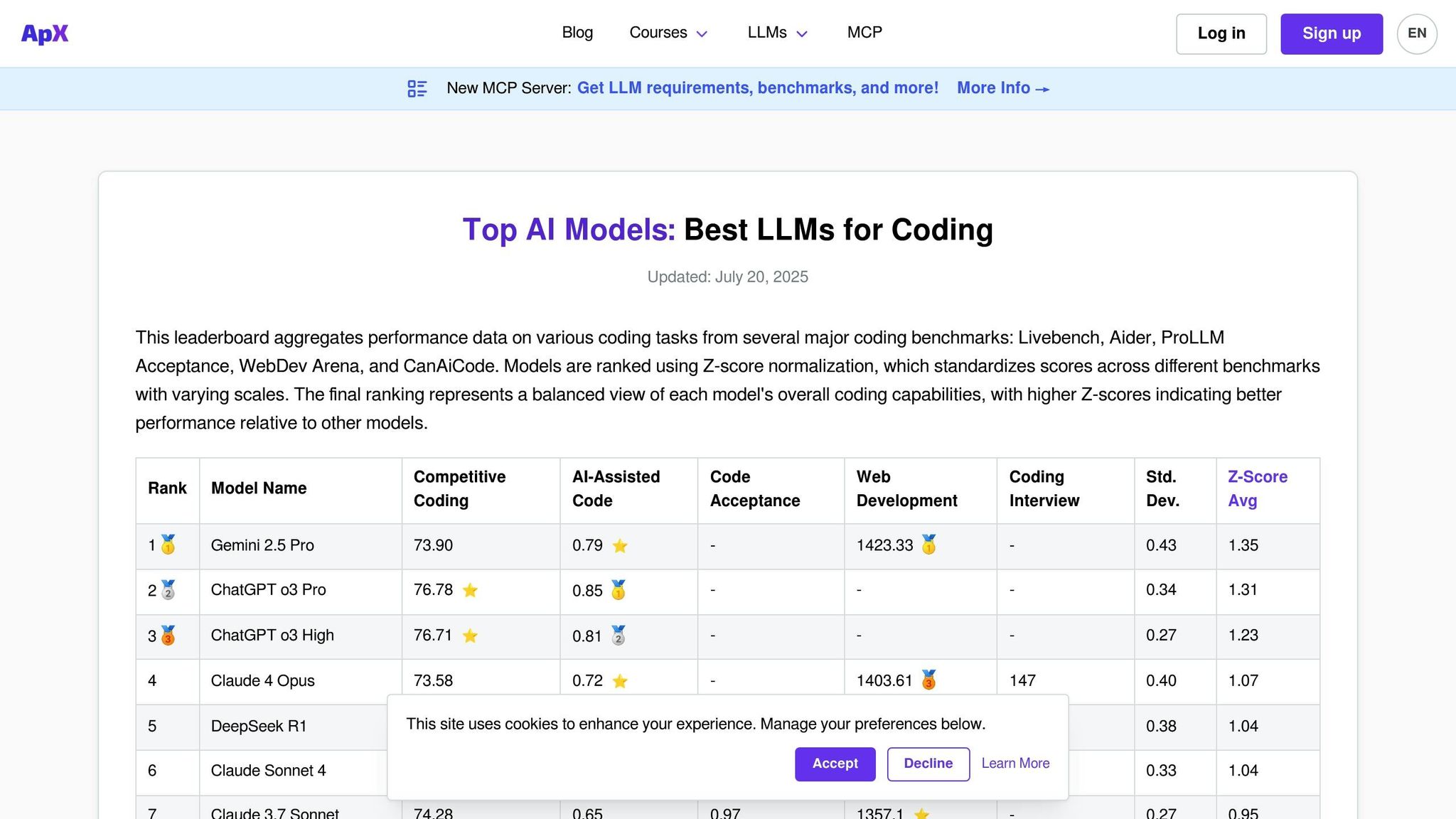
APX Coding LLMs is a platform designed specifically to evaluate the coding capabilities of language models. Unlike general-purpose leaderboards that focus on a wide range of conversational skills, APX zeroes in on areas like code generation, debugging, algorithm implementation, and solving technical problems. This focus makes it an essential tool for developers, engineering teams, and organizations aiming to integrate AI-powered coding assistants into their workflows.
The platform evaluates how models handle practical programming challenges across various languages and frameworks. Similar to other evaluation platforms, APX simplifies the assessment process but with a keen focus on code performance and security.
APX features an extensive lineup of both commercial and open-source models tested for their coding expertise. The platform regularly evaluates well-known coding models such as GitHub Copilot's underlying GPT models, CodeT5, StarCoder, and Code Llama variants. It also includes general-purpose models with strong programming capabilities, like GPT-4, Claude, and Gemini.
A key differentiator for APX is its inclusion of specialized coding models that may not appear on broader leaderboards but excel in niche programming areas. These models are tested across various parameter sizes and fine-tuned versions, including domain-specific variants for languages like Python, JavaScript, Java, C++, Rust, and Go. The platform also evaluates performance with frameworks such as React, Django, TensorFlow, and PyTorch.
This comprehensive coverage ensures that APX provides rigorous and practical testing for real-world coding needs.
APX employs a detailed testing framework tailored to real-world coding scenarios. It evaluates models on aspects such as code correctness, efficiency, readability, and adherence to security standards through a combination of automated tests and expert reviews.
The testing scenarios include algorithm challenges, debugging flawed code, refactoring tasks, and generating documentation. Models are also assessed for their ability to explain complex code concepts and suggest optimizations.
Incorporating industry-standard coding practices, APX evaluates whether models follow established conventions for naming, commenting, and structuring code. Additionally, it tests the models’ ability to recognize and avoid common security vulnerabilities, making it especially valuable for enterprises where secure coding is a priority.
The APX leaderboard is updated monthly to keep pace with the rapidly evolving landscape of AI coding tools. Updates include the addition of newly released models and re-evaluations of existing ones, ensuring alignment with the latest programming challenges and standards.
The platform also offers real-time performance tracking for significant model updates, giving developers immediate access to the latest capabilities. When major coding-focused models are launched, APX conducts special evaluation cycles to provide timely insights into their performance.
APX provides a detailed breakdown of cost-per-token analysis tailored specifically for coding tasks. This analysis helps users understand the cost implications of different models for various use cases. Costs are broken down by programming language and task complexity, offering clear insights into which models deliver the best value.
The cost analysis considers factors such as API call frequency during typical coding tasks, token usage patterns, and potential savings from reduced debugging time. APX even estimates the total cost of ownership for teams adopting AI coding assistants, weighing productivity gains against subscription and usage fees. This level of detail makes APX a valuable resource for assessing the financial impact of AI-driven coding solutions.
Side-by-side comparison platforms for large language models (LLMs) cater to a variety of needs. Prompts.ai stands out by offering access to over 35 top-tier models, paired with centralized tools for managing costs and ensuring governance. This makes it a strong choice for larger organizations that need secure and compliant workflows with robust oversight.
While Prompts.ai emphasizes cost management and governance, other platforms focus on different priorities. These may include community-driven feedback, technical benchmarks, or specialized metrics such as safety and alignment. These platforms vary in their model selections, evaluation methods, update schedules, and transparency in pricing.
This summary complements earlier in-depth analyses, helping you identify the tools that best fit your goals. Whether your focus is budget, technical depth, or specific use cases, it’s worth noting that many organizations rely on a mix of platforms to achieve a well-rounded understanding of both technical and business needs.
When evaluating platforms for large language model (LLM) comparison, the best choice ultimately hinges on balancing factors like cost, performance, and compliance. The decision should align with your organization’s specific needs, technical capabilities, and workflow demands.
For enterprises seeking a unified AI orchestration solution, Prompts.ai offers a compelling option. With access to over 35 leading LLMs, integrated cost management tools, and enterprise-grade governance controls, it’s designed to simplify operations for organizations overseeing multiple teams and complex projects.
That said, the LLM platform landscape is diverse, and there’s no universal solution that fits every scenario. Many organizations adopt a mix of tools to address both research and production requirements. By focusing on your primary goals - whether it’s reducing costs, enhancing performance, or ensuring compliance - you can refine your platform selection process and streamline AI implementation.
Choosing the right orchestration and comparison tools can lead to measurable improvements in your AI initiatives and drive meaningful business results.
Prompts.ai simplifies the challenge of evaluating multiple large language models (LLMs) by delivering clear, actionable insights into their performance, scalability, and cost-efficiency. This empowers users to make informed choices, selecting the model that best fits their needs while staying within budget.
With tools designed to assess the balance between cost and performance, as well as operational efficiency, Prompts.ai ensures businesses can sidestep unnecessary expenses and concentrate on implementing the most effective solutions tailored to their unique requirements.
Platforms offering tools to customize comparisons for large language models (LLMs) are invaluable because they let users fine-tune evaluations to match their unique goals. By honing in on critical aspects like performance, features, and practical applications, these tools simplify the process of identifying the most suitable model, cutting down on the guesswork.
These comparison tools also deliver more detailed benchmarking, offering valuable insights for researchers, developers, and businesses alike. Whether you're refining a solution for a specific task or weighing multiple options, these platforms make decision-making faster and more effective.
Regularly updating evaluation methods and model databases is essential for maintaining precision, dependability, and credibility in AI platforms. These updates enable models to stay current by incorporating fresh data, adapting to trends, and addressing new use cases, ultimately boosting performance and decision-making.
Consistent refinement of methodologies allows platforms to tackle biases, improve model adaptability, and meet shifting industry standards. This dedication to progress ensures AI solutions remain efficient, compliant, and equipped to meet user needs in a fast-moving environment.



















