Pague Conforme o Uso - AI Model Orchestration and Workflows Platform

Em um cenário lotado de IA, escolher o modelo de linguagem grande (LLM) certo pode ser complicado. Com modelos como GPT-5, Claude e Gemini se destacando em diferentes áreas, as plataformas de comparação simplificam o processo de tomada de decisão, oferecendo análises lado a lado de desempenho, custos e casos de uso. Aqui está o que você precisa saber:
Essas plataformas atendem a diferentes necessidades – seja para otimizar custos, garantir segurança ou avaliar capacidades de codificação. Abaixo está uma comparação rápida para ajudá-lo a decidir.
A escolha da plataforma certa depende dos seus objetivos – seja reduzir custos, garantir a conformidade com a segurança ou aumentar a produtividade. Plataformas como Prompts.ai se destacam para empresas que gerenciam vários LLMs, enquanto APX Coding LLMs é perfeito para desenvolvedores. Cada ferramenta oferece uma perspectiva única para orientar sua estratégia de IA.
Prompts.ai é uma plataforma empresarial de IA projetada para simplificar o processo de comparação e implantação de grandes modelos de linguagem (LLMs). Ao consolidar mais de 35 LLMs líderes em um painel único e unificado, a plataforma elimina a necessidade de fazer malabarismos com várias ferramentas. Essa configuração simplificada não apenas reduz a complexidade, mas também permite que as equipes tomem decisões bem informadas, comparando modelos de desempenho, custo e velocidade de integração – tudo em um só lugar.
Prompts.ai oferece acesso a uma ampla gama de modelos de IA de última geração, incluindo GPT-5, Claude, LLaMA, Gemini, Grok-4, Flux Pro e Kling, entre outros. Essa extensa biblioteca permite que os usuários avaliem modelos com diversos pontos fortes e especialidades, sem o incômodo de trocar de plataforma ou gerenciar várias chaves de API.
The platform's ability to aggregate these models ensures users can evaluate them based on real-world applications. Whether it’s testing coding efficiency, creative writing skills, or expertise in specific domains, the side-by-side comparison feature enables simultaneous testing of identical prompts across multiple models.
Prompts.ai adota uma abordagem que prioriza o usuário para avaliação de modelos, oferecendo flexibilidade que vai além dos benchmarks genéricos. Em vez de depender de métricas predefinidas, os usuários podem criar cenários de avaliação personalizados, adaptados às suas necessidades específicas, usando seus próprios prompts e dados.
The platform’s interface displays results side by side, offering a clear view of output quality, response times, and methodologies. This approach is especially beneficial for businesses that need to test models against proprietary datasets or industry-specific challenges that standard benchmarks fail to address.
Prompts.ai integra uma camada FinOps que fornece rastreamento em tempo real do uso de tokens em todos os modelos. Ao monitorar o consumo de tokens, as equipes podem comparar diretamente o desempenho e as implicações financeiras, facilitando a avaliação de quais modelos oferecem o melhor valor.
The platform’s Pay-As-You-Go TOKN credit system ensures that costs align with actual usage, potentially reducing expenses by up to 98%. For organizations managing tight budgets or allocating resources across multiple AI projects, this level of cost clarity supports smarter, data-driven decisions.
Prompts.ai keeps its users ahead of the curve by rapidly integrating new models as they become available. Its architecture is built for agility, ensuring emerging models are added quickly, so users don’t face delays in accessing the latest advancements.
Além dos novos modelos, a plataforma também implementa atualizações e otimizações de forma integrada. À medida que os modelos melhoram e novas versões são lançadas, os usuários podem contar com o Prompts.ai para fornecer acesso ininterrupto a essas melhorias, permitindo-lhes permanecer competitivos em um cenário de IA em constante evolução.
A Análise Artificial se concentra em fornecer avaliações consistentes e completas de grandes modelos de linguagem (LLMs) por meio de benchmarks padronizados e processos de teste repetíveis. Ao aderir a uma abordagem sistemática, a plataforma fornece insights aprofundados sobre o desempenho de diferentes LLMs em uma variedade de tarefas cognitivas e aplicações práticas.
The platform maintains an extensive database that includes evaluations of both proprietary and open-source LLMs from leading AI developers like OpenAI, Anthropic, Google, Meta, and newer players in the field. It doesn’t stop at mainstream models but also includes specialized and fine-tuned versions, offering users the chance to explore options tailored to unique or niche requirements. This wide-ranging coverage ensures users can access performance data for virtually any model they might consider.
A Análise Artificial emprega uma metodologia robusta de benchmarking de inteligência projetada para avaliar modelos em múltiplas dimensões. Em vez de depender de uma única métrica, a plataforma utiliza um sistema de pontuação ponderada que avalia o raciocínio, a precisão, a criatividade e as capacidades específicas da tarefa. Cada modelo é rigorosamente testado com prompts e conjuntos de dados padronizados, e os resultados são normalizados para garantir comparações justas entre diversas arquiteturas e tamanhos. Uma combinação de pontuação automatizada e avaliações humanas acrescenta profundidade e confiabilidade a essas avaliações.
Acompanhando o cenário de LLM em rápida mudança, a Análise Artificial atualiza frequentemente suas metodologias. A atualização mais recente, Versão 3.0, foi lançada em 2 de setembro de 2025. Essas atualizações regulares garantem que a plataforma continue sendo uma fonte confiável de insights acionáveis e atualizados, permitindo que os usuários tomem decisões informadas ao selecionar o melhor modelo de linguagem para suas necessidades.
O LMSYS Chatbot Arena é uma plataforma colaborativa projetada para avaliar grandes modelos de linguagem (LLMs) por meio de feedback humano em tempo real. Essa abordagem garante que as avaliações permaneçam relevantes, capturando tanto as interações dos usuários quanto as melhorias contínuas nos modelos.
A plataforma hospeda uma seleção diversificada de modelos, incluindo opções proprietárias, de código aberto e experimentais. Isso permite que os usuários testem e comparem o desempenho de diferentes modelos em uma ampla variedade de tarefas e aplicativos.
Para minimizar o viés, os usuários realizam comparações cegas de pares entre modelos. Os resultados são então agregados para classificar os modelos com base na qualidade conversacional, originalidade e utilidade prática.
A tabela de classificação é continuamente atualizada com o feedback dos usuários, garantindo que reflita os últimos lançamentos de modelos e tendências de desempenho.
O Vellum AI Leaderboard oferece insights práticos sobre o desempenho do modelo, adaptados especificamente para aplicações práticas de negócios.
A tabela de classificação apresenta uma seleção escolhida a dedo de modelos comerciais e de código aberto projetados para uso empresarial. Isso inclui ofertas de fornecedores como OpenAI, Anthropic e Google, além de opções de código aberto como Llama 2 e Mistral.
O que diferencia a Vellum é seu foco em modelos prontos para negócios. Em vez de listar opções experimentais ou não comprovadas, destaca modelos que demonstraram confiabilidade e são adequados para implantação comercial.
Vellum avalia modelos usando uma abordagem estruturada em seis categorias principais: raciocínio, geração de código, redação criativa, precisão factual, seguimento de instruções e conformidade de segurança.
Cada modelo é testado com prompts que imitam cenários de negócios do mundo real, combinando pontuação automatizada com revisão humana. Esta avaliação em duas camadas garante que os resultados reflitam a usabilidade prática, em vez de apenas referências teóricas. Atualizações regulares no processo de avaliação garantem que a tabela de classificação permaneça alinhada com os desenvolvimentos mais recentes no espaço LLM.
A tabela de classificação é atualizada mensalmente, com atualizações adicionais para os principais lançamentos de modelos. Este cronograma garante testes completos enquanto se mantém atualizado com os avanços acelerados em grandes modelos de linguagem.
O Vellum também rastreia o desempenho histórico, permitindo aos usuários revisar como os modelos evoluíram ao longo do tempo. Esse recurso ajuda as empresas a tomar decisões informadas sobre quando adotar novos modelos ou atualizar os existentes.
Vellum fornece detalhamentos de custos detalhados, incluindo preços por 1.000 tokens e custos estimados para tarefas como suporte ao cliente, criação de conteúdo e assistência de código.
O LiveBench enfrenta o desafio da contaminação de dados atualizando frequentemente suas questões de benchmark. Isso garante que os modelos sejam avaliados com base em material novo, evitando que eles simplesmente memorizem dados de treinamento.
O LiveBench oferece suporte a uma ampla variedade de modelos, desde sistemas menores com 0,5 bilhão de parâmetros até sistemas enormes com 405 bilhões de parâmetros. Foram avaliados 49 modelos diferentes de grandes linguagens (LLMs), incluindo plataformas proprietárias líderes, alternativas proeminentes de código aberto e modelos especializados de nicho.
The platform’s robust API compatibility allows seamless evaluation of any model with an OpenAI-compatible endpoint. This includes models from providers like Anthropic, Cohere, Mistral, Together, and Google.
A partir de 9 de outubro de 2025, a tabela de classificação apresenta modelos avançados, como a série GPT-5 da OpenAI (High, Medium, Pro, Codex, Mini, o3, o4-Mini), Claude Sonnet 4.5 e Claude 4.1 Opus da Anthropic, Gemini 2.5 Pro e Flash do Google, Grok 4 da xAI, DeepSeek V3.1 e Qwen 3 Max do Alibaba.
O LiveBench usa uma metodologia resistente à contaminação, testando modelos em 21 tarefas divididas em sete categorias, incluindo raciocínio, codificação, matemática e compreensão da linguagem. Para manter a integridade dos seus benchmarks, a plataforma atualiza todas as questões semestralmente e introduz tarefas mais complexas ao longo do tempo. Por exemplo, a versão mais recente, LiveBench-2025-05-30, adicionou uma tarefa de codificação de agente onde os modelos devem navegar em ambientes de desenvolvimento do mundo real para resolver problemas de repositório.
Para salvaguardar ainda mais o processo de avaliação, cerca de 300 questões de atualizações recentes – cerca de 30% do total – permanecem inéditas. Isso garante que os modelos não possam ser treinados nos dados de teste exatos. Estas medidas, combinadas com atualizações regulares, mantêm o índice de referência relevante e desafiador.
O LiveBench segue um cronograma de atualização rigoroso, lançando novas questões de forma consistente e atualizando todo o benchmark a cada seis meses. Os usuários podem solicitar avaliações para modelos recém-desenvolvidos enviando um problema no GitHub ou entrando em contato com a equipe do LiveBench por e-mail. Isto permite que modelos emergentes sejam avaliados sem esperar pela próxima atualização agendada. Adições recentes de dezembro de 2024 incluem modelos como claude-3-5-haiku-20241022, claude-3-5-sonnet-20241022, gemini-exp-1114, gpt-4o-2024-11-20, grok-2 e grok-2-mini.
LLM-Stats fornece uma maneira baseada em dados para comparar grandes modelos de linguagem, analisando estatísticas agregadas de uma variedade de benchmarks. Embora ofereça informações valiosas sobre o desempenho do modelo, detalhes como a forma como os modelos são categorizados, os métodos de avaliação usados, detalhes de preços e a frequência com que os dados são atualizados não foram compartilhados. Esta abordagem estatística serve como uma contrapartida útil às comparações qualitativas anteriores.
O OpenRouter Rankings adota uma abordagem prática para avaliar o desempenho do modelo de linguagem, concentrando-se no desempenho dos modelos em cenários do mundo real, em vez de depender apenas de benchmarks técnicos. Ao agregar dados do uso diário, destaca quais modelos realmente agregam valor em aplicações práticas. Esta ênfase em métricas do mundo real complementa as avaliações técnicas mais detalhadas fornecidas por outras plataformas.
A plataforma inclui uma variedade de modelos de linguagem, organizados com base em suas aplicações específicas. Ao categorizar os modelos de acordo com seus casos de uso, ajuda os usuários a identificar facilmente as soluções que se alinham às suas necessidades específicas.
OpenRouter Rankings uses a usage-based evaluation system, considering multiple factors like response quality, efficiency, and cost. These metrics are combined into composite scores that provide a clear picture of each model’s overall effectiveness and value.
As classificações são atualizadas regularmente para levar em conta as mudanças no desempenho do modelo e nas tendências de uso, garantindo que os dados permaneçam relevantes e atualizados.
Um foco principal da plataforma está nos fatores econômicos. Ao analisar preços e métricas relacionadas a custos, proporciona clareza sobre o equilíbrio entre custo e desempenho, ajudando os usuários a tomar decisões informadas.
O Hugging Face Open LLM Leaderboard se destaca como uma plataforma dedicada para avaliar o desempenho de modelos de linguagem de código aberto. Projetado por Hugging Face, ele serve como um recurso central para pesquisadores e desenvolvedores que buscam comparar modelos com benchmarks padronizados. Ao concentrar-se exclusivamente em modelos de código aberto, a tabela de classificação alinha-se com as necessidades daqueles que valorizam a transparência e a acessibilidade aberta nas suas soluções de IA. Ele complementa as comparações empresariais e orientadas ao desempenho discutidas anteriormente, oferecendo uma perspectiva única sobre o cenário da IA de código aberto.
A tabela de classificação organiza uma ampla gama de modelos de código aberto por tamanho de parâmetro - 7B, 13B, 30B e 70B+ - abrangendo projetos experimentais e implementações em larga escala de instituições de pesquisa líderes.
Apresenta contribuições de organizações e desenvolvedores individuais, promovendo um ecossistema diversificado e dinâmico que reflete o estado atual da IA de código aberto. Cada entrada de modelo inclui informações detalhadas sobre arquitetura, dados de treinamento e termos de licenciamento, permitindo que os usuários façam escolhas informadas com base nas necessidades do projeto e nos requisitos de conformidade.
Usando uma estrutura de avaliação padronizada, o Hugging Face avalia modelos em vários benchmarks, oferecendo uma análise completa de suas capacidades. Esses benchmarks abrangem habilidades de raciocínio, retenção de conhecimento, resolução de problemas matemáticos e compreensão de leitura, garantindo uma visão completa do desempenho de cada modelo.
A plataforma emprega pipelines automatizados para manter condições de teste consistentes em todos os modelos. Isso elimina discrepâncias causadas por ambientes ou metodologias variadas, fornecendo aos usuários comparações confiáveis e idênticas para identificar a melhor opção para seus casos de uso específicos.
A tabela de classificação é continuamente atualizada com novos modelos à medida que surgem na comunidade de código aberto. Graças ao seu processo de avaliação automatizado, os modelos podem ser avaliados e classificados rapidamente, sem atrasos causados por intervenção manual.
Além disso, a plataforma reavalia os modelos existentes sempre que as metodologias de benchmark são refinadas. Isto garante que os modelos mais antigos permaneçam representados de forma justa, mantendo a relevância e a confiabilidade da tabela de classificação ao longo do tempo.
While the leaderboard doesn’t provide direct pricing, it includes key details such as model size, memory requirements, and inference speed. These metrics help users estimate the infrastructure costs involved in deploying each model.
Este foco nos requisitos computacionais permite que as organizações tomem decisões conscientes do orçamento, especialmente aquelas que trabalham com recursos limitados ou restrições específicas de hardware. Ao enfatizar modelos de código aberto, a plataforma também elimina taxas de licenciamento contínuas, tornando o custo total de propriedade mais previsível e muitas vezes mais gerenciável em comparação com alternativas proprietárias.
O Scale AI SEAL Leaderboard é dedicado a avaliar a segurança, o alinhamento e o desempenho de grandes modelos de linguagem (LLMs), abordando as principais preocupações empresariais sobre a implantação responsável de IA. Ao contrário dos placares de classificação de uso geral, o SEAL se concentra em avaliar até que ponto os modelos lidam com conteúdo confidencial, aderem às diretrizes éticas e mantêm um comportamento consistente em cenários variados. Isto destaca a importância da segurança e da conformidade ética juntamente com o desempenho bruto em ambientes empresariais. Sua abordagem especializada fornece insights detalhados sobre os recursos do modelo, métodos de avaliação, cronogramas de atualização e custos associados.
SEAL analisa uma combinação de modelos proprietários e de código aberto, com forte foco naqueles comumente usados em aplicações de negócios. A tabela de classificação inclui modelos comerciais de alto perfil como GPT-4, Claude e Gemini, bem como opções populares de código aberto, como variantes Llama 2 e Mistral.
O que distingue o SEAL é a sua ênfase em modelos prontos para empresas, em vez de versões experimentais ou focadas em pesquisa. Cada modelo é testado em vários tamanhos de parâmetros e configurações ajustadas, oferecendo uma compreensão mais profunda de como essas variações impactam o equilíbrio entre segurança e desempenho. A plataforma também avalia modelos especializados adaptados para setores como saúde ou finanças, onde a conformidade regulatória e o gerenciamento de riscos são essenciais.
SEAL utiliza uma estrutura de avaliação completa que combina métricas de desempenho tradicionais com extensos testes de segurança. Os modelos são avaliados quanto à sua capacidade de rejeitar sugestões prejudiciais, manter a precisão factual e evitar produzir resultados tendenciosos ou discriminatórios.
O processo de avaliação inclui exercícios de equipe vermelha e análises humanas para descobrir vulnerabilidades e preconceitos sutis que os testes automatizados podem ignorar. Ao combinar avaliações automatizadas e manuais, o SEAL garante que as considerações de segurança tenham o mesmo peso que as métricas de desempenho.
A tabela de classificação do SEAL é atualizada trimestralmente, refletindo a natureza detalhada e centrada na segurança de suas avaliações. Cada atualização incorpora modelos recém-lançados e reavalia os existentes em relação aos padrões e padrões de segurança em evolução.
Além dessas atualizações programadas, a Scale AI lança relatórios provisórios quando ocorrem atualizações significativas de modelo ou incidentes relacionados à segurança na comunidade de IA. Esta abordagem adaptativa garante que os utilizadores empresariais tenham acesso atempado às avaliações de segurança mais recentes, o que é especialmente importante dado o ritmo rápido dos avanços dos modelos. Essas atualizações regulares também fornecem dados valiosos para analisar os custos de implantação.
While SEAL doesn’t disclose direct pricing, it offers insights into the total cost of ownership, including factors like content moderation, compliance requirements, and liability risks. This helps enterprises weigh the costs of safety measures against operational expenses.
A plataforma também fornece orientação sobre as necessidades de infraestrutura para diversas configurações de segurança, ajudando as organizações a compreender as compensações entre maior segurança e custos operacionais. Para usuários corporativos, o SEAL estima economias potenciais com a redução dos esforços de moderação de conteúdo ao implantar modelos com recursos de segurança integrados robustos.
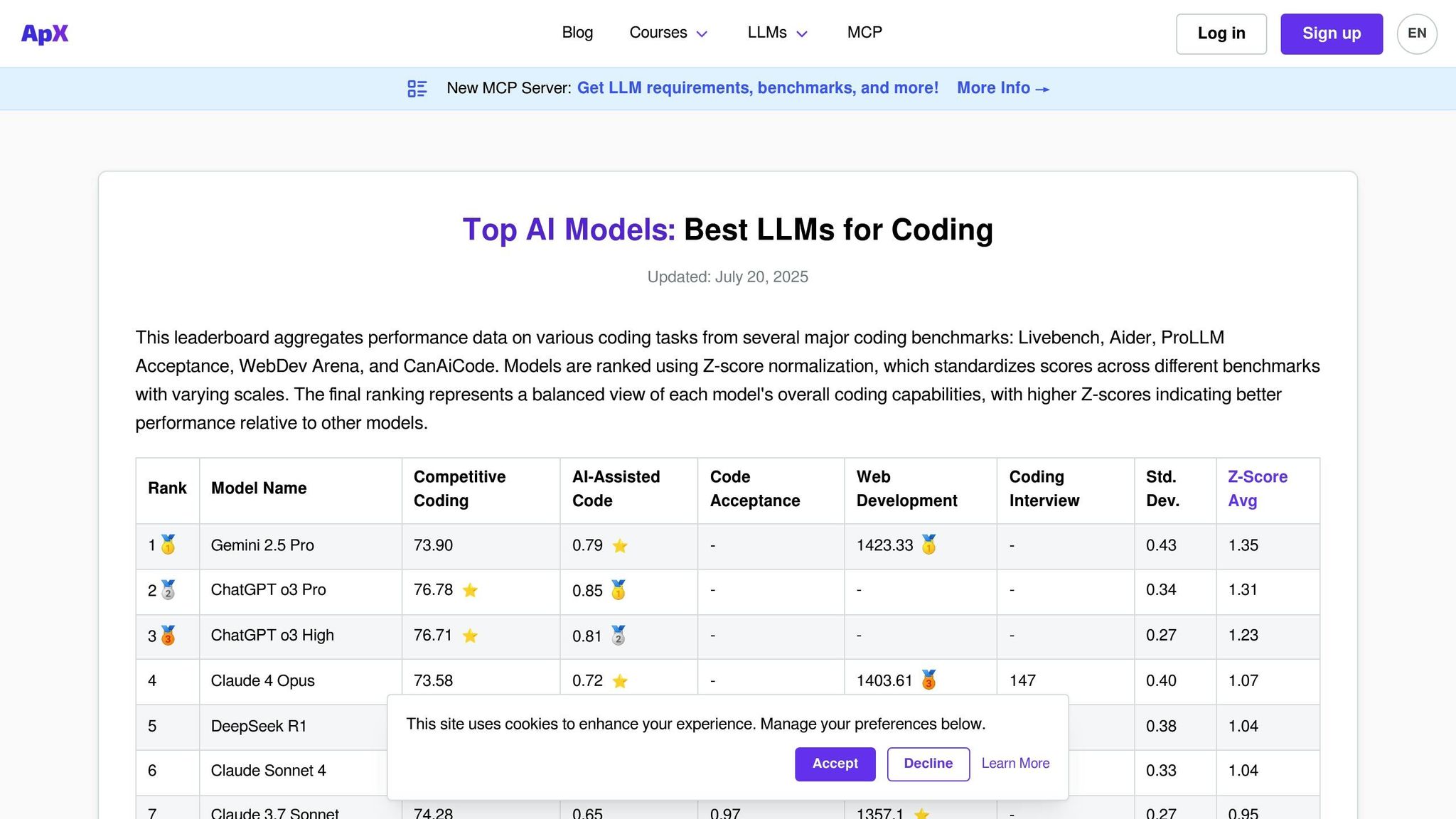
APX Coding LLMs é uma plataforma projetada especificamente para avaliar as capacidades de codificação de modelos de linguagem. Ao contrário dos placares de classificação de uso geral que se concentram em uma ampla gama de habilidades de conversação, o APX se concentra em áreas como geração de código, depuração, implementação de algoritmos e solução de problemas técnicos. Esse foco o torna uma ferramenta essencial para desenvolvedores, equipes de engenharia e organizações que desejam integrar assistentes de codificação com tecnologia de IA em seus fluxos de trabalho.
A plataforma avalia como os modelos lidam com desafios práticos de programação em diversas linguagens e estruturas. Semelhante a outras plataformas de avaliação, o APX simplifica o processo de avaliação, mas com grande foco no desempenho e na segurança do código.
APX apresenta uma extensa linha de modelos comerciais e de código aberto testados por sua experiência em codificação. A plataforma avalia regularmente modelos de codificação conhecidos, como os modelos GPT subjacentes do GitHub Copilot, CodeT5, StarCoder e variantes Code Llama. Também inclui modelos de uso geral com fortes capacidades de programação, como GPT-4, Claude e Gemini.
Um diferencial importante do APX é a inclusão de modelos de codificação especializados que podem não aparecer em tabelas de classificação mais amplas, mas se destacam em áreas de programação de nicho. Esses modelos são testados em vários tamanhos de parâmetros e versões ajustadas, incluindo variantes específicas de domínio para linguagens como Python, JavaScript, Java, C++, Rust e Go. A plataforma também avalia o desempenho com frameworks como React, Django, TensorFlow e PyTorch.
Esta cobertura abrangente garante que o APX forneça testes rigorosos e práticos para necessidades de codificação do mundo real.
APX emprega uma estrutura de testes detalhada adaptada a cenários de codificação do mundo real. Ele avalia modelos em aspectos como correção de código, eficiência, legibilidade e adesão a padrões de segurança por meio de uma combinação de testes automatizados e análises de especialistas.
Os cenários de teste incluem desafios de algoritmo, depuração de código defeituoso, tarefas de refatoração e geração de documentação. Os modelos também são avaliados quanto à sua capacidade de explicar conceitos complexos de código e sugerir otimizações.
Incorporating industry-standard coding practices, APX evaluates whether models follow established conventions for naming, commenting, and structuring code. Additionally, it tests the models’ ability to recognize and avoid common security vulnerabilities, making it especially valuable for enterprises where secure coding is a priority.
A tabela de classificação APX é atualizada mensalmente para acompanhar o cenário em rápida evolução das ferramentas de codificação de IA. As atualizações incluem a adição de modelos recém-lançados e reavaliações dos existentes, garantindo o alinhamento com os mais recentes desafios e padrões de programação.
A plataforma também oferece rastreamento de desempenho em tempo real para atualizações significativas de modelos, dando aos desenvolvedores acesso imediato aos recursos mais recentes. Quando os principais modelos focados em codificação são lançados, o APX conduz ciclos de avaliação especiais para fornecer insights oportunos sobre seu desempenho.
O APX fornece uma análise detalhada do custo por token, adaptada especificamente para tarefas de codificação. Esta análise ajuda os usuários a compreender as implicações de custos de diferentes modelos para vários casos de uso. Os custos são divididos por linguagem de programação e complexidade da tarefa, oferecendo insights claros sobre quais modelos oferecem o melhor valor.
A análise de custos considera fatores como frequência de chamadas de API durante tarefas típicas de codificação, padrões de uso de token e economia potencial com a redução do tempo de depuração. A APX ainda estima o custo total de propriedade para equipes que adotam assistentes de codificação de IA, comparando os ganhos de produtividade com as taxas de assinatura e uso. Este nível de detalhe torna o APX um recurso valioso para avaliar o impacto financeiro de soluções de codificação orientadas por IA.
Plataformas de comparação lado a lado para grandes modelos de linguagem (LLMs) atendem a uma variedade de necessidades. Prompts.ai se destaca por oferecer acesso a mais de 35 modelos de primeira linha, aliados a ferramentas centralizadas para gerenciamento de custos e garantia de governança. Isso o torna uma excelente escolha para organizações maiores que precisam de fluxos de trabalho seguros e compatíveis com supervisão robusta.
Embora Prompts.ai enfatize a gestão de custos e governança, outras plataformas se concentram em prioridades diferentes. Estes podem incluir feedback da comunidade, benchmarks técnicos ou métricas especializadas, como segurança e alinhamento. Essas plataformas variam em suas seleções de modelos, métodos de avaliação, cronogramas de atualização e transparência nos preços.
This summary complements earlier in-depth analyses, helping you identify the tools that best fit your goals. Whether your focus is budget, technical depth, or specific use cases, it’s worth noting that many organizations rely on a mix of platforms to achieve a well-rounded understanding of both technical and business needs.
When evaluating platforms for large language model (LLM) comparison, the best choice ultimately hinges on balancing factors like cost, performance, and compliance. The decision should align with your organization’s specific needs, technical capabilities, and workflow demands.
For enterprises seeking a unified AI orchestration solution, Prompts.ai offers a compelling option. With access to over 35 leading LLMs, integrated cost management tools, and enterprise-grade governance controls, it’s designed to simplify operations for organizations overseeing multiple teams and complex projects.
That said, the LLM platform landscape is diverse, and there’s no universal solution that fits every scenario. Many organizations adopt a mix of tools to address both research and production requirements. By focusing on your primary goals - whether it’s reducing costs, enhancing performance, or ensuring compliance - you can refine your platform selection process and streamline AI implementation.
A escolha das ferramentas certas de orquestração e comparação pode levar a melhorias mensuráveis em suas iniciativas de IA e gerar resultados de negócios significativos.
Prompts.ai simplifica o desafio de avaliar vários modelos de linguagem de grande porte (LLMs), fornecendo insights claros e práticos sobre seu desempenho, escalabilidade e economia. Isso permite que os usuários façam escolhas informadas, selecionando o modelo que melhor atenda às suas necessidades, mantendo-se dentro do orçamento.
Com ferramentas projetadas para avaliar o equilíbrio entre custo e desempenho, bem como a eficiência operacional, Prompts.ai garante que as empresas possam evitar despesas desnecessárias e se concentrar na implementação das soluções mais eficazes, adaptadas às suas necessidades específicas.
As plataformas que oferecem ferramentas para personalizar comparações para grandes modelos de linguagem (LLMs) são inestimáveis porque permitem que os usuários ajustem as avaliações para atender aos seus objetivos exclusivos. Ao aprimorar aspectos críticos como desempenho, recursos e aplicações práticas, essas ferramentas simplificam o processo de identificação do modelo mais adequado, eliminando suposições.
Essas ferramentas de comparação também oferecem benchmarking mais detalhados, oferecendo insights valiosos para pesquisadores, desenvolvedores e empresas. Esteja você refinando uma solução para uma tarefa específica ou avaliando diversas opções, essas plataformas tornam a tomada de decisões mais rápida e eficaz.
A atualização regular dos métodos de avaliação e dos bancos de dados de modelos é essencial para manter a precisão, a confiabilidade e a credibilidade nas plataformas de IA. Essas atualizações permitem que os modelos permaneçam atualizados, incorporando novos dados, adaptando-se às tendências e abordando novos casos de uso, aumentando, em última análise, o desempenho e a tomada de decisões.
O refinamento consistente das metodologias permite que as plataformas enfrentem preconceitos, melhorem a adaptabilidade do modelo e atendam às mudanças nos padrões do setor. Essa dedicação ao progresso garante que as soluções de IA permaneçam eficientes, compatíveis e equipadas para atender às necessidades dos usuários em um ambiente em rápida evolução.



















