Pay As You Go7 दिन का फ़्री ट्रायल; किसी क्रेडिट कार्ड की आवश्यकता नहीं


टेक्स्ट डेटा को प्रीप्रोसेस करना प्रभावी बड़े भाषा मॉडल (एलएलएम) के प्रशिक्षण की रीढ़ है। यहां मुख्य बातें बताई गई हैं: मॉडल के बेहतर प्रदर्शन के लिए स्वच्छ, संरचित और उच्च-गुणवत्ता वाला डेटा आवश्यक है। प्री-प्रोसेसिंग में गन्दे टेक्स्ट को साफ करना, शोर को दूर करना और इसे ऐसे प्रारूप में तैयार करना शामिल है, जिसे एलएलएम कुशलतापूर्वक प्रोसेस कर सकें। इसमें निम्न तक की खपत हो सकती है किसी प्रोजेक्ट की 80% टाइमलाइन, लेकिन अदायगी बेहतर सटीकता और तेज मॉडल अभिसरण है।
प्लेटफ़ॉर्म जैसे prompts.ai सफाई, टोकनाइजेशन, और त्रुटि का पता लगाने, समय बचाने और मैन्युअल प्रयास को कम करने जैसे चरणों को स्वचालित करें।
बॉटम लाइन: यह सुनिश्चित करने के लिए कि आपका एलएलएम मज़बूती से प्रदर्शन करता है और सटीक परिणाम देता है, प्रीप्रोसेसिंग में समय निवेश करें।
कच्चा टेक्स्ट अक्सर गन्दा और अव्यवस्थित होता है, यही वजह है कि विश्लेषक अपना 80% से अधिक समय इसे साफ करने में लगाते हैं। यहां लक्ष्य इस अराजक डेटा को एक सुसंगत प्रारूप में बदलना है, जिसे आपका मॉडल कुशलतापूर्वक प्रोसेस कर सके।
प्रीप्रोसेसिंग में पहला कदम उन तत्वों को हटाना है जो आपके विश्लेषण में योगदान नहीं करते हैं। चूंकि सफ़ाई करना काफ़ी कार्य-विशिष्ट है, इसलिए इसमें गोता लगाने से पहले अपने अंतिम लक्ष्यों को स्पष्ट करना ज़रूरी है।
उदाहरण के लिए, एआई-संचालित प्लेटफॉर्म स्टडी फ़ेच को सर्वेक्षण डेटा को साफ़ करते समय वास्तविक दुनिया की चुनौती का सामना करना पड़ा। उनके फ्री-फॉर्म “अकादमिक प्रमुख” फ़ील्ड में “एंथ्रोपोलॉजी केम ई कंप्यूटर साइंस बिज़नेस और लॉड्रामासिम्ब” जैसी प्रविष्टियाँ शामिल थीं। OpenAI के GPT मॉडल का उपयोग करते हुए, उन्होंने इन अराजक प्रतिक्रियाओं को मानकीकृत श्रेणियों में सफलतापूर्वक वर्गीकृत किया।
एक बार डेटा साफ हो जाने के बाद, अगला कदम बेहतर मॉडल प्रदर्शन के लिए इसे मानकीकृत करना है।
टेक्स्ट को मानकीकृत करना स्थिरता सुनिश्चित करता है, जिससे बड़े भाषा मॉडल (एलएलएम) विसंगतियों के बजाय पैटर्न पर ध्यान केंद्रित कर सकते हैं। पुनर्प्राप्ति और जनरेशन सटीकता में सुधार के लिए यह कदम महत्वपूर्ण है।
एक बार डेटा साफ और मानकीकृत हो जाने के बाद, अगला कदम शोर को कम करना है - बड़े भाषा मॉडल (एलएलएम) की सटीकता में सुधार के लिए एक आवश्यक प्रक्रिया। टेक्स्ट डेटा में शोर पैटर्न की नकल करके एलएलएम को भ्रमित कर सकता है, जिससे मतिभ्रम जैसे मुद्दे हो सकते हैं और आउटपुट में सटीकता कम हो जाती है।
जबकि स्थैतिक शोर (स्थानीय विकृतियों) का मामूली प्रभाव पड़ता है, गतिशील शोर (व्यापक त्रुटियां) एलएलएम की प्रभावी ढंग से प्रदर्शन करने की क्षमता को काफी प्रभावित कर सकती हैं।
टेक्स्ट डेटा में अक्सर टाइपोग्राफ़िकल गलतियों, असंगत स्वरूपण, व्याकरण संबंधी त्रुटियों, उद्योग शब्दजाल, गलत अनुवाद या अप्रासंगिक जानकारी के रूप में शोर होता है। इससे निपटने के लिए, एडवांस तकनीकें जैसे कि डीप डेनोइज़िंग ऑटोएन्कोडर्स, प्रिंसिपल कंपोनेंट एनालिसिस (PCA), फूरियर ट्रांसफ़ॉर्म या कॉन्ट्रास्टिव डेटासेट वास्तविक पैटर्न को शोर से अलग करने में मदद कर सकते हैं।
शोर में कमी के केंद्र में निहित है गुणवत्ता फ़िल्टरिंग। इसे दो मुख्य तरीकों से हासिल किया जा सकता है:
ये रणनीतियां प्रारंभिक सफाई के बाद डेटा को और परिष्कृत करती हैं, जिससे उन्नत प्रसंस्करण शुरू होने से पहले न्यूनतम विसंगतियां सुनिश्चित होती हैं।
शोर में कमी के लिए एक व्यवस्थित दृष्टिकोण अपनाना महत्वपूर्ण है। सैंटियागो हर्नांडेज़, मुख्य डेटा अधिकारी, सरलता के महत्व पर ज़ोर देते हैं:
“मेरा सुझाव है कि आप उस समस्या पर अपना ध्यान केंद्रित रखें जिसे हल करने की आवश्यकता है। कभी-कभी, डेटा पेशेवरों के रूप में, हम एक प्रक्रिया को इस हद तक ओवर-इंजीनियर करते हैं कि हम इसे निष्पादित करने के लिए अतिरिक्त काम करना शुरू कर देते हैं। हालांकि कई टूल डेटा क्लींजिंग की प्रक्रिया में मदद कर सकते हैं, खासकर जब आपको मशीन लर्निंग मॉडल को प्रशिक्षित करने की आवश्यकता होती है, तो प्रक्रिया को अधिक जटिल बनाने से पहले बुनियादी बातों को प्राथमिकता देना महत्वपूर्ण है.”
शोर को प्रभावी ढंग से कम करने के लिए, इसके स्रोत की पहचान करना महत्वपूर्ण है। चाहे शोर वेब स्क्रैपिंग कलाकृतियों, OCR त्रुटियों, उपयोगकर्ता-जनित सामग्री में विसंगतियों, या एन्कोडिंग समस्याओं से उत्पन्न हो, मूल कारण को संबोधित करने से एक स्वच्छ, अधिक विश्वसनीय डेटासेट सुनिश्चित होता है। शोर से जल्दी निपटने से, सटीक बाहरी पहचान और डाउनस्ट्रीम मॉडल प्रशिक्षण के लिए डेटा को बेहतर तरीके से तैयार किया जाता है।
डेटा तैयार करने का एक अन्य महत्वपूर्ण पहलू गोपनीयता की सुरक्षा करना है। व्यक्तिगत रूप से पहचाने जाने योग्य जानकारी (PII) - जैसे कि नाम, पता, फ़ोन नंबर, सामाजिक सुरक्षा नंबर और ईमेल पते - को हटाना आवश्यक है। यह कदम न केवल व्यक्तियों की सुरक्षा करता है, बल्कि मॉडल को अनजाने में संवेदनशील विवरणों को याद रखने और पुन: प्रस्तुत करने से भी रोकता है।
PII के अलावा, संवेदनशील या हानिकारक सामग्री की स्क्रीनिंग करना और उसे हटाना महत्वपूर्ण है, जिसमें अभद्र भाषा और भेदभावपूर्ण भाषा शामिल है। अपने डोमेन की खास ज़रूरतों के आधार पर ऐसी सामग्री की पहचान करने के लिए स्पष्ट मानदंड स्थापित करें, और प्रासंगिक नियमों का अनुपालन करने के लिए अपनी गोपनीयता और सुरक्षा प्रोटोकॉल का अच्छी तरह से दस्तावेजीकरण करें।
गतिशील, वैश्विक शोर को प्रीट्रेनिंग और फाइन-ट्यूनिंग दोनों चरणों के दौरान फ़िल्टर किया जाना चाहिए, क्योंकि यह मॉडल के प्रदर्शन के लिए एक महत्वपूर्ण खतरा है। हालांकि, चेन-ऑफ-थॉट (CoT) डेटा में कम से मध्यम स्थैतिक शोर को हटाने की आवश्यकता नहीं हो सकती है और यदि शोर का स्तर प्रबंधन योग्य रहता है तो मॉडल की मजबूती को भी बढ़ा सकता है।
शोर को कम करने के बाद, टेक्स्ट डेटा तैयार करने का अगला चरण आउटलेर्स की पहचान करना और उनका प्रबंधन करना है। यह प्रक्रिया पहले की शोर कम करने की रणनीतियों पर आधारित है और बड़े भाषा मॉडल (LLM) के प्रशिक्षण के लिए एक स्वच्छ, विश्वसनीय डेटासेट सुनिश्चित करती है। संख्यात्मक आउटलेर्स के विपरीत, टेक्स्ट आउटलेयर भाषा की जटिल, संदर्भ-संचालित प्रकृति के कारण अद्वितीय चुनौतियां पेश करते हैं।
टेक्स्ट आउटलेयर मॉडल को भ्रमित करने वाले या भाषा की समझ को विकृत करने वाले अप्रत्याशित पैटर्न पेश करके एलएलएम प्रशिक्षण को महत्वपूर्ण रूप से बाधित कर सकते हैं। इन विसंगतियों का पता लगाना मुश्किल है क्योंकि टेक्स्ट डेटा में संख्यात्मक डेटासेट में अक्सर पाई जाने वाली स्पष्ट सांख्यिकीय सीमाओं का अभाव होता है। इसके बजाय, वैध भाषाई विविधताओं और समस्याग्रस्त विसंगतियों के बीच अंतर करने के लिए अधिक सूक्ष्म तरीकों की आवश्यकता होती है, जो मॉडल के प्रदर्शन को कमजोर कर सकती हैं।
सांख्यिकीय तकनीकें टेक्स्ट डेटा से निकाली गई मात्रात्मक विशेषताओं का विश्लेषण करके आउटलेर्स का पता लगाने के लिए एक संरचित तरीका प्रदान करती हैं। एक सामान्य तरीका यह है कि Z- स्कोर विधि, जो मापता है कि डेटासेट माध्य से डेटा बिंदु कितना दूर भटकता है। सामान्य वितरण में, लगभग 99.7% डेटा पॉइंट तीन मानक विचलनों के अंतर्गत आते हैं। एक और व्यापक रूप से इस्तेमाल किया जाने वाला तरीका है इंटरक्वेर्टाइल रेंज (IQR), जो आउटलेर्स को Q1 - 1.5 × IQR या Q3 + 1.5 × IQR से ऊपर के बिंदुओं के रूप में फ़्लैग करता है। टेक्स्ट कॉर्पोरा में अक्सर देखे जाने वाले विषम वितरणों को संभालने के लिए यह विधि विशेष रूप से प्रभावी है।
सिंगल आउटलेर्स का पता लगाने के लिए, ग्रब्स का परीक्षण परिकल्पना परीक्षण का उपयोग करता है, जबकि डिक्सन का क्यू टेस्ट छोटे डेटासेट के लिए बेहतर अनुकूल है। कई सुविधाओं के साथ काम करते समय, महालनोबिस की दूरी मूल्यांकन करता है कि भाषाई चर के बीच संबंधों के लिए लेखांकन करते हुए एक नमूना माध्य से कितना दूर भटकता है।
मशीन लर्निंग के दृष्टिकोण जैसे पृथक वन और एक श्रेणी का एसवीएम एक महत्वपूर्ण भूमिका भी निभाते हैं। ये एल्गोरिदम डेटा वितरण के बारे में सख्त धारणाओं पर भरोसा किए बिना उच्च-आयामी टेक्स्ट डेटा में विसंगतियों का पता लगाने के लिए डिज़ाइन किए गए हैं।
एक बार आउटलेर्स की पहचान हो जाने के बाद, अगला कदम उन्हें संबोधित करने के लिए सही रणनीति चुनना है। आउटलेर्स मॉडल के प्रदर्शन को कैसे प्रभावित करते हैं, इस पर निर्भर करते हुए विकल्पों में सुधार, निष्कासन, ट्रिमिंग, कैपिंग, डिस्क्रिटाइजेशन और सांख्यिकीय परिवर्तन शामिल हैं।
एलएलएम प्रीप्रोसेसिंग के लिए, मजबूत मशीन लर्निंग मॉडल का लाभ उठाना बाहरी पहचान के दौरान विशेष रूप से उपयोगी हो सकता है। सपोर्ट वेक्टर मशीन, रैंडम फ़ॉरेस्ट, और एन्सेम्बल मेथड्स जैसे एल्गोरिदम आउटलेर्स के लिए अधिक लचीले होते हैं और वास्तविक विसंगतियों और मूल्यवान एज केस के बीच अंतर करने में मदद कर सकते हैं। उच्च डेटा गुणवत्ता बनाए रखने के लिए इन तरीकों का व्यापक रूप से विभिन्न डोमेन में उपयोग किया जाता है।
आउटलेर्स को संबोधित करने के साथ, एलएलएम प्रशिक्षण के लिए डेटासेट को और परिष्कृत करने के लिए प्रभावी टोकन विधियों का चयन करने पर ध्यान केंद्रित किया जा सकता है।
आउटलेर्स को संबोधित करने के बाद, अगला चरण टेक्स्ट को टोकन में विभाजित करना है जिसे बड़े भाषा मॉडल (LLM) प्रोसेस कर सकते हैं। टोकनाइजेशन कच्चे पाठ को छोटी इकाइयों में परिवर्तित करने की प्रक्रिया है - जैसे शब्द, वाक्यांश, या प्रतीक - जो कि एक मॉडल भाषा को समझने और उत्पन्न करने के तरीके के लिए बिल्डिंग ब्लॉक के रूप में काम करता है।
टोकनाइजेशन के लिए आपके द्वारा चुनी गई विधि का आपके मॉडल के प्रदर्शन पर बड़ा प्रभाव पड़ता है। यह कम्प्यूटेशनल दक्षता से लेकर मॉडल जटिल भाषाई पैटर्न को कितनी अच्छी तरह से संभालता है, सब कुछ प्रभावित करता है। एक सोची-समझी टोकनाइजेशन रणनीति का मतलब ऐसे मॉडल के बीच का अंतर हो सकता है, जो दुर्लभ शब्दों से लड़खड़ाता है और जो विशिष्ट शब्दावली को आसानी से संभालता है।
सही टोकनाइजेशन दृष्टिकोण का चयन करने में शब्दावली आकार, भाषा विशेषताओं और कम्प्यूटेशनल दक्षता जैसे संतुलन कारक शामिल हैं। आमतौर पर, 8,000 से 50,000 टोकन के बीच के शब्दावली आकार अच्छी तरह से काम करते हैं, लेकिन आदर्श आकार आपके विशिष्ट उपयोग के मामले पर निर्भर करता है।
यहां कुछ सामान्य टोकन विधियां दी गई हैं:
चिकित्सा या कानूनी ग्रंथों जैसे विशिष्ट क्षेत्रों के लिए, अपने टोकननाइज़र को फिर से प्रशिक्षित करना अक्सर आवश्यक होता है। यह सुनिश्चित करता है कि मॉडल डोमेन की विशिष्ट शब्दावली और संदर्भ के अनुकूल हो।
“टोकनाइजेशन एक मूलभूत प्रक्रिया है जो बड़े भाषा मॉडल (एलएलएम) को मानव भाषा को टोकन नामक सुपाच्य टुकड़ों में विभाजित करने की अनुमति देती है... यह इस बात के लिए मंच तैयार करती है कि एलएलएम भाषा, संदर्भ और यहां तक कि दुर्लभ शब्दावली में बारीकियों को कितनी अच्छी तरह पकड़ सकता है।” - साहिन अहमद, डेटा साइंटिस्ट
सबसे अच्छी टोकनकरण विधि आपकी भाषा और कार्य पर निर्भर करती है। मॉर्फोलॉजिकल रूप से समृद्ध भाषाएं सबवर्ड या कैरेक्टर-लेवल टोकनाइजेशन से लाभान्वित होती हैं, जबकि सरल भाषाएं शब्द-स्तरीय दृष्टिकोणों के साथ अच्छी तरह से काम कर सकती हैं। जिन कार्यों के लिए गहरी अर्थपूर्ण समझ की आवश्यकता होती है, वे अक्सर सबवर्ड टोकनाइजेशन के साथ बेहतर परिणाम प्राप्त करते हैं, जो शब्दावली के आकार और भाषा की जटिलता को संतुलित करता है।
प्रभावी टोकनकरण सिमेंटिक संदर्भ को संरक्षित करने में भी महत्वपूर्ण भूमिका निभाता है, जो सटीक मॉडल भविष्यवाणियों के लिए आवश्यक है। यहां लक्ष्य यह सुनिश्चित करना है कि शब्दों के बीच संबंध बरकरार रहें और सार्थक पैटर्न हाइलाइट किए जाएं।
सिमेंटिक टेक्स्ट सेगमेंटेशन निश्चित नियमों पर भरोसा करने के बजाय, पाठ को उसकी सामग्री और संदर्भ के आधार पर सार्थक भागों में विभाजित करके इसे एक कदम आगे ले जाता है। यह विधि विशेष रूप से किसके लिए उपयोगी है रिट्रीवल-ऑगमेंटेड जेनरेशन (RAG) सिस्टम, जहां पुनर्प्राप्त की गई जानकारी को स्पष्ट और प्रासंगिक होना चाहिए। उदाहरण के लिए, वेक्टर डेटाबेस या एलएलएम के साथ काम करते समय, सटीक खोजों के लिए आवश्यक जानकारी को बनाए रखते हुए उचित चंकिंग यह सुनिश्चित करती है कि टेक्स्ट संदर्भ विंडो के भीतर फिट बैठता है।
कुछ उन्नत रणनीतियों में शामिल हैं:
अधिकांश अनुप्रयोगों के लिए, निश्चित आकार के चंकिंग से शुरू करना एक ठोस आधार रेखा प्रदान करता है। जैसे-जैसे आपकी ज़रूरतें बढ़ती हैं, आप दस्तावेज़ पदानुक्रम और शब्दार्थ सीमाओं को शामिल करने वाले अधिक परिष्कृत तरीकों का पता लगा सकते हैं।
prompts.ai जैसे टूल में, संदर्भ बनाए रखते हुए विविध सामग्री को संभालने के लिए प्रभावी टोकननाइज़ेशन महत्वपूर्ण है। विचारशील रणनीतियां यह सुनिश्चित करती हैं कि एलएलएम अनुप्रयोगों में बेहतर प्रदर्शन के लिए मंच तैयार करते हुए, कम्प्यूटेशनल दक्षता से समझौता किए बिना अर्थ संरक्षित रहे।
बड़े भाषा मॉडल (एलएलएम) के लिए प्रीप्रोसेसिंग की जटिलता के कारण इन वर्कफ़्लो को स्वचालित करने वाले प्लेटफ़ॉर्म का उदय हुआ है। इन उपकरणों का उद्देश्य यह सरल बनाना है कि अन्यथा एक थकाऊ और समय-गहन प्रक्रिया क्या होगी, इसे एक सुव्यवस्थित और दोहराए जाने योग्य सिस्टम में बदल दिया जाएगा। प्लेटफ़ॉर्म जैसे: prompts.ai सभी प्रीप्रोसेसिंग चरणों को एक एकीकृत ढांचे में एकीकृत करके इस प्रवृत्ति का उदाहरण दें।
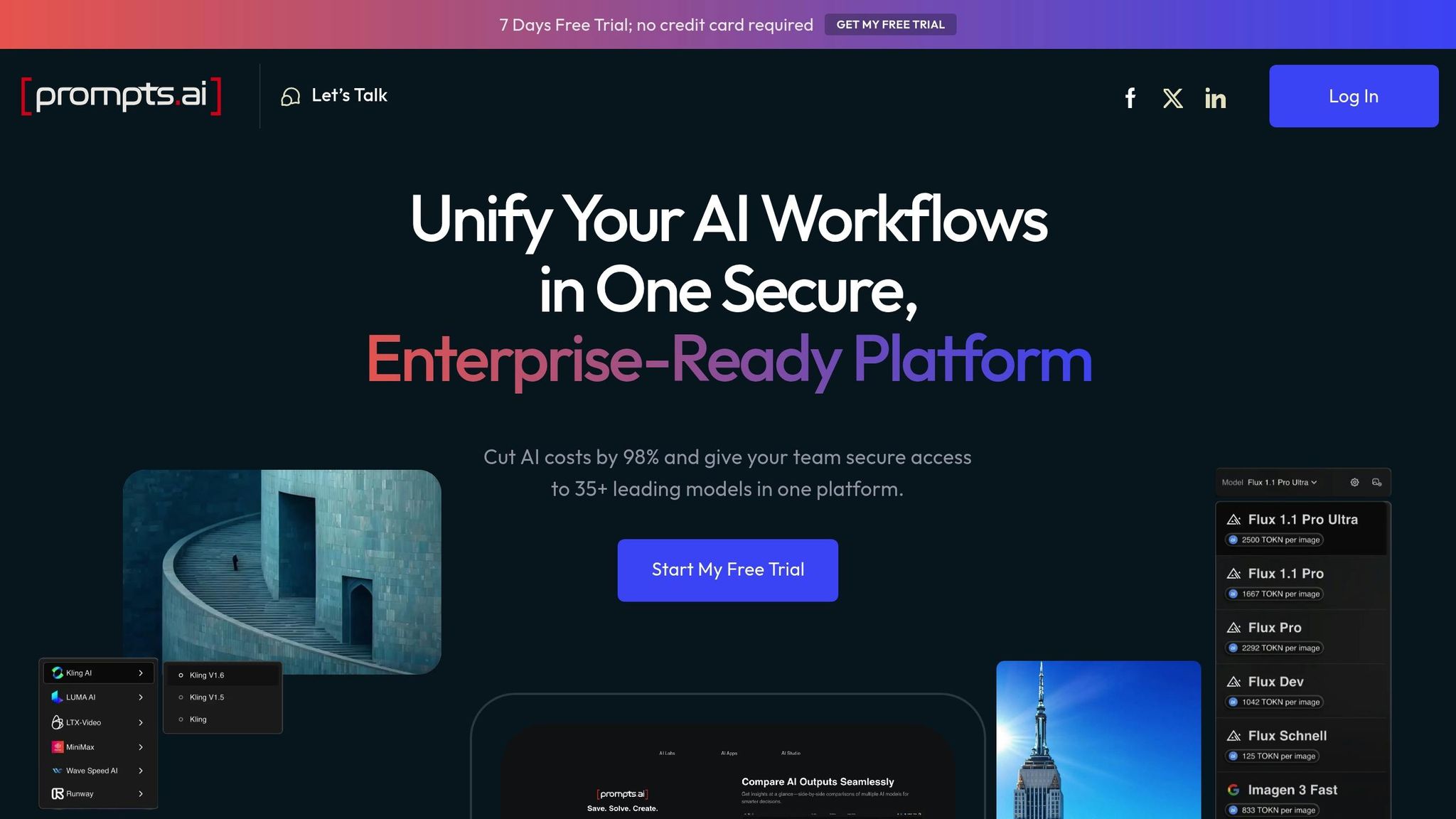
prompts.ai एआई वर्कफ़्लो को केंद्रीकृत करने के लिए डिज़ाइन किया गया है, जो एक ही छत के नीचे कोर प्रीप्रोसेसिंग फ़ंक्शन को एक साथ लाता है। प्लेटफॉर्म के मुताबिक, यह हो सकता है 10 मिनट से कम समय में लागत को 95% तक कम करते हुए 35 से अधिक डिस्कनेक्ट किए गए AI टूल को बदलें। यह अस्पष्टता, गलत वर्तनी और बहुभाषी इनपुट जैसी चुनौतियों से निपटने के लिए सुसज्जित है, साथ ही त्रुटि का पता लगाने, डेटा मानकीकरण, इंप्यूटेशन और डिडुप्लीकेशन जैसी सुविधाएँ भी प्रदान करता है।
prompts.ai की कुछ असाधारण विशेषताएं यहां दी गई हैं:
प्लेटफ़ॉर्म एक लचीली मूल्य निर्धारण संरचना भी प्रदान करता है। योजनाएँ एक से लेकर होती हैं सीमित TOKN क्रेडिट के साथ मुफ्त पे ऐज़ यू गो विकल्प एक के लिए $99 प्रति माह (वार्षिक बिलिंग के साथ $89 प्रति माह) पर प्रॉब्लम सॉल्वर योजना, जिसमें 500,000 TOKN क्रेडिट शामिल हैं।
“अपनी टीमों को एक साथ मिलकर काम करने के लिए कहें, भले ही वे बहुत दूर हों। प्रोजेक्ट से संबंधित संचार को एक ही स्थान पर केंद्रीकृत करें, व्हाइटबोर्ड के साथ विचारों पर विचार-मंथन करें, और सहयोगी दस्तावेज़ों के साथ मिलकर योजनाओं का मसौदा तैयार करें।” - हेनरी डोकानई, UI Design
टोकन प्रबंधन के लिए यह सुव्यवस्थित दृष्टिकोण संदर्भ को बनाए रखने और शब्दावली को अनुकूलित करने जैसे व्यापक लक्ष्यों के साथ जुड़ा हुआ है, जो प्रभावी प्रीप्रोसेसिंग के लिए महत्वपूर्ण हैं।
उन्नत प्लेटफ़ॉर्म एआई-संचालित तकनीकों को शामिल करके स्वचालन को एक कदम आगे ले जाते हैं जो विभिन्न डेटा प्रकारों के अनुकूल होती हैं। इनमें से कई टूल मल्टी-मोडल डेटा प्रोसेसिंग का समर्थन करते हैं, जिससे वे एक ही वर्कफ़्लो के भीतर टेक्स्ट, इमेज, ऑडियो और अन्य प्रारूपों को संभालने में सक्षम होते हैं।
जटिल डेटासेट में आउटलेर्स की पहचान करने के लिए, मशीन लर्निंग तकनीक जैसे आइसोलेशन फ़ॉरेस्ट, लोकल आउटलेयर फ़ैक्टर (LOF), और वन-क्लास SVM अत्यधिक प्रभावी हैं। जब टेक्स्ट डेटा को साफ करने और मानकीकृत करने की बात आती है, तो AI-संचालित NLP विधियाँ - जैसे कि टोकनाइजेशन, नॉइज़ रिमूवल, नॉर्मलाइज़ेशन, स्टॉप वर्ड रिमूवल, और लेमेटाइज़ेशन/स्टेमिंग - निर्बाध रूप से एक साथ काम करें। इसके अतिरिक्त, डोमेन-विशिष्ट विधियाँ विशिष्ट सामग्री, जैसे मेडिकल रिकॉर्ड, कानूनी दस्तावेज़, या तकनीकी मैनुअल के अनुरूप अनुकूलित प्रीप्रोसेसिंग की अनुमति देती हैं।
AI तकनीकों का एकीकरण एक फीडबैक लूप बनाता है जो डेटा की गुणवत्ता में लगातार सुधार करता है। जैसे-जैसे सिस्टम अधिक डेटा प्रोसेस करता है, यह नए प्रकार के शोर और विसंगतियों का पता लगाने में बेहतर होता जाता है, जिससे वर्कफ़्लो तेजी से कुशल होता जाता है। ये प्लेटफ़ॉर्म इस बात पर भी ज़ोर देते हैं दृश्यता और ऑडिटेबिलिटी, यह सुनिश्चित करना कि प्रत्येक प्रीप्रोसेसिंग निर्णय की समीक्षा की जा सकती है और उसे मान्य किया जा सकता है, जो उच्च डेटा मानकों के अनुपालन और रखरखाव के लिए महत्वपूर्ण है।
प्रीप्रोसेसिंग सही तरीके से प्राप्त करना किसी भी सफल एलएलएम प्रोजेक्ट की रीढ़ है। जैसा कि AI/ML इंजीनियर केवल देकिवाडिया ने उपयुक्त रूप से कहा है, “असंरचित पाठ को एक संरचित प्रारूप में बदलने के लिए उचित डेटा तैयार करना आवश्यक है, जिसकी व्याख्या तंत्रिका नेटवर्क कर सकते हैं, जिससे मॉडल के प्रदर्शन पर काफी प्रभाव पड़ता है”। दूसरे शब्दों में, आप अपने डेटा को तैयार करने में जो प्रयास करते हैं, वह सीधे तौर पर बताता है कि व्यावहारिक, वास्तविक दुनिया के परिदृश्यों में आपका मॉडल कितना अच्छा प्रदर्शन करता है।
दिलचस्प बात यह है कि डेटा प्रीप्रोसेसिंग में AI प्रोजेक्ट पर खर्च किए गए कुल समय का 80% तक लग सकता है। लेकिन इस बार निवेश व्यर्थ नहीं गया है - यह सटीकता में सुधार करके, शोर को कम करने और टोकन को अनुकूलित करने से लाभ देता है। ये लाभ यह सुनिश्चित करने के लिए महत्वपूर्ण हैं कि आपका मॉडल प्रभावी ढंग से सीखे और भरोसेमंद प्रदर्शन करे।
स्वच्छ, संरचित और सार्थक डेटा देने के लिए व्यवस्थित सफाई, गुणवत्ता फ़िल्टरिंग, डी-डुप्लीकेशन और चल रही निगरानी जैसे महत्वपूर्ण कदम आवश्यक हैं। इन प्रथाओं का पालन करके, आप बेहतर सीखने और प्रदर्शन के परिणामों को प्राप्त करने के लिए अपने एलएलएम के लिए मंच तैयार करते हैं।
आधुनिक उपकरण, जैसे कि prompts.ai जैसे प्लेटफ़ॉर्म, मानकीकरण, त्रुटि में कमी और स्केलेबिलिटी जैसी प्रक्रियाओं को स्वचालित करके इसे एक कदम आगे ले जाते हैं। यह मैन्युअल बाधाओं को दूर करता है और समय के साथ डेटा गुणवत्ता में लगातार सुधार सुनिश्चित करता है।
के प्रदर्शन को बेहतर बनाने में टेक्स्ट डेटा को प्रीप्रोसेस करना महत्वपूर्ण भूमिका निभाता है बड़े भाषा मॉडल (एलएलएम) यह सुनिश्चित करके कि इनपुट डेटा स्वच्छ, सुव्यवस्थित और प्रासंगिक है। जब शोर - जैसे टाइपो, अप्रासंगिक विवरण, या विसंगतियां - हटा दी जाती हैं, तो मॉडल उच्च-गुणवत्ता वाली जानकारी पर ध्यान केंद्रित कर सकता है, जिससे पैटर्न की पहचान करना और विश्वसनीय आउटपुट तैयार करना आसान हो जाता है।
मुख्य प्रीप्रोसेसिंग चरणों में अक्सर टेक्स्ट को साफ करना, आउटलेर्स को संबोधित करना, प्रारूपों को मानकीकृत करना और अतिरेक को समाप्त करना शामिल होता है। ये क्रियाएँ न केवल प्रशिक्षण प्रक्रिया को सरल बनाती हैं, बल्कि विभिन्न कार्यों में प्रभावी ढंग से अनुकूलन करने और प्रदर्शन करने की मॉडल की क्षमता में भी सुधार करती हैं। अपने डेटा को प्री-प्रोसेस करने में समय लगाने से आपके एलएलएम प्रोजेक्ट्स की सटीकता और दक्षता में महत्वपूर्ण अंतर आ सकता है।
टेक्स्ट डेटा में आउटलेर्स से निपटने के लिए, इसका उपयोग करके विसंगतियों का पता लगाकर शुरुआत करें सांख्यिकीय तकनीकें जैसे Z- स्कोर या इंटरक्वेर्टाइल रेंज (IQR)। यदि आपका डेटासेट अधिक जटिल है, तो आप खोज कर सकते हैं दूरी-आधारित या घनत्व-आधारित तरीके असामान्य पैटर्न की पहचान करने के लिए। इसके अतिरिक्त, मशीन लर्निंग मॉडल जैसे वन-क्लास एसवीएम आउटलेर्स का पता लगाने और उन्हें संभालने का एक शक्तिशाली तरीका हो सकता है।
आउटलेर्स का प्रबंधन शोर को कम करने में मदद करता है और आपके डेटासेट की गुणवत्ता को बढ़ाता है, जो आपके बड़े भाषा मॉडल (LLM) के प्रदर्शन को काफी बढ़ा सकता है।
प्लेटफ़ॉर्म जैसे prompts.ai डेटा को साफ करने, शोर कम करने और आउटलेर्स को प्रबंधित करने जैसे आवश्यक कार्यों को स्वचालित करके बड़े भाषा मॉडल (एलएलएम) के लिए टेक्स्ट प्रीप्रोसेसिंग की परेशानी को दूर करें। यह सुनिश्चित करता है कि आपका डेटा न केवल सुसंगत है, बल्कि अच्छी तरह से तैयार भी है, जिससे आपके मॉडल के प्रदर्शन को बढ़ाते हुए आपके समय की बचत होती है।
उसके ऊपर, prompts.ai जैसी सुविधाओं से भरा हुआ आता है शीघ्र डिजाइन प्रबंधन, टोकनाइजेशन ट्रैकिंग, और वर्कफ़्लो ऑटोमेशन। ये उपकरण संपूर्ण प्रीप्रोसेसिंग प्रक्रिया को आसान और अधिक कुशल बनाते हैं। मैन्युअल काम में कटौती करके और जटिल वर्कफ़्लो को सरल बनाकर, prompts.ai यूज़र को अपने LLM प्रोजेक्ट्स में मूल्य प्रदान करने और बेहतर परिणाम लाने पर ध्यान केंद्रित करने की अनुमति देता है।


















