Pay As You Go7 दिन का फ़्री ट्रायल; किसी क्रेडिट कार्ड की आवश्यकता नहीं


AI workflows in 2026 face challenges like fragmented tools, unchecked model drift, and escalating costs. To overcome these, organizations are adopting smarter, automated workflows that unify tools, improve governance, and optimize spending. Here’s how you can transform your AI operations:
These practices streamline workflows, enhance oversight, and reduce costs, enabling organizations to scale AI responsibly and efficiently.
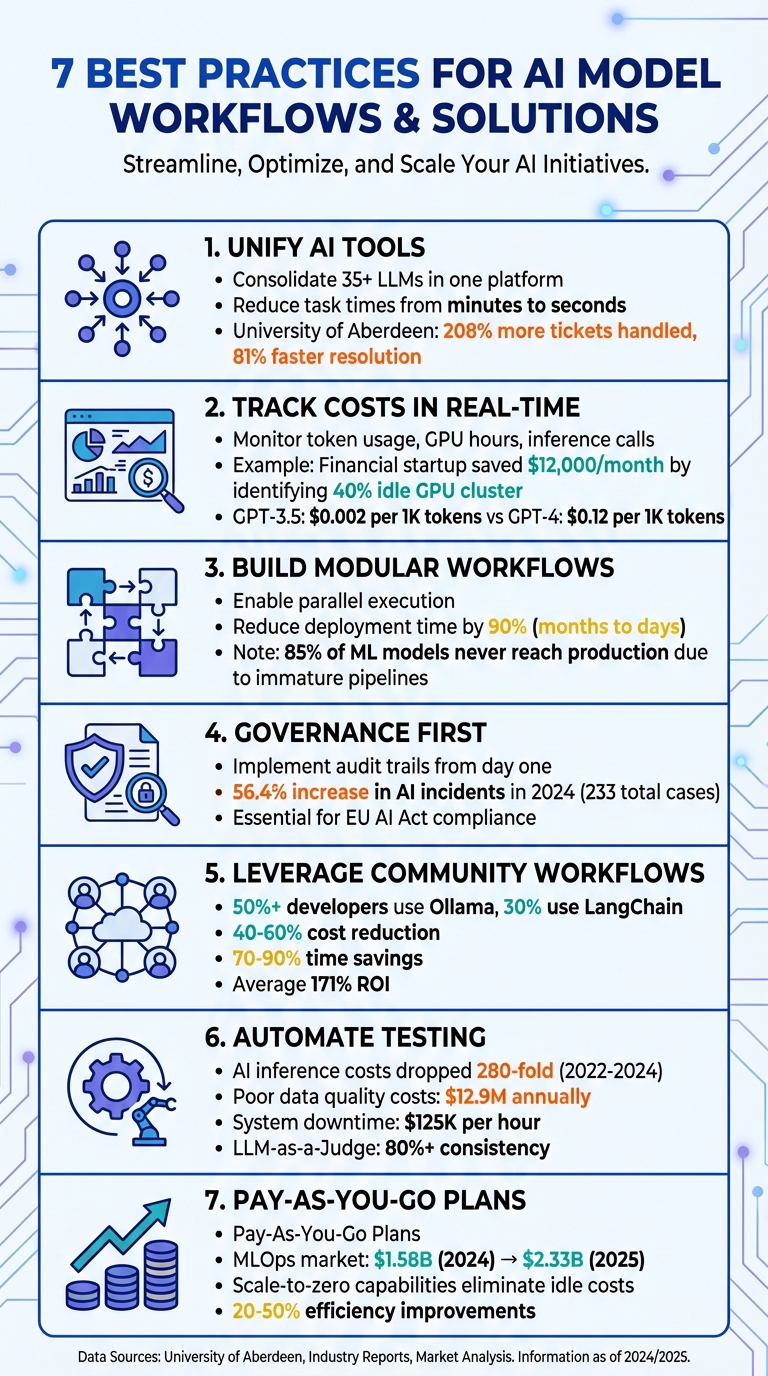
7 Best Practices for AI Model Workflows in 2026
Managing separate platforms for models like GPT-5, Claude, LLaMA, and Gemini can slow down operations and create unnecessary hurdles. By consolidating over 35 LLMs into one interface, Prompts.ai eliminates the hassle of juggling multiple logins and credentials, reducing task times from minutes to mere seconds.
This kind of integration drives measurable productivity gains. For example, when the University of Aberdeen adopted an AI-powered system in September 2025, their IT team managed to handle 208% more tickets while slashing resolution times by 81% [1]. Such results highlight how a streamlined system allows teams to focus on outcomes rather than wasting time managing fragmented tools. This approach paves the way for more efficient, reliable, and cost-effective AI workflows.
A unified interface doesn't just save time - it ensures greater reliability and flexibility. With all models accessible from a single platform, teams can switch seamlessly between engines, maintaining continuity even if one model fails or delivers inaccurate results. This proactive setup prevents runaway processes, which can lead to skyrocketing cloud costs when automated agents loop without proper controls.
The platform also enables side-by-side performance testing, so you can evaluate which model best suits specific tasks. For instance, customer support queries might be routed to one LLM, creative projects to another, and data processing to a third - all managed from the same dashboard. This model-agnostic design ensures you're not tied to a single vendor's limitations or pricing, giving you the freedom to optimize performance and costs.
Prompts.ai takes cost management to the next level by offering real-time insights into token usage across all models. This transparency helps prevent budget overruns before they happen. A built-in FinOps layer tracks spending at the prompt level, making it easier to identify which workflows deliver value and which drain resources. Organizations using AI workflow automation have reported an 84% ROI when they can link expenditures to business results. Databricks, for example, reduced support tickets by 23% through smart triaging powered by clean data models and transparent cost tracking [1].
The platform's pay-as-you-go TOKN credits align expenses with actual usage, eliminating the need to pay for unused capacity. By consolidating costs across multiple models, teams can save up to 98% compared to maintaining separate subscriptions for each tool, creating significant savings across projects and departments.
Prompts.ai also strengthens governance and compliance, offering unified audit trails that support both regulatory requirements and workflow improvements. The platform categorizes tasks into risk tiers, ensuring that high-stakes operations (like Level 4 tasks with catastrophic potential) remain under human supervision until AI systems are fully reliable.
With end-to-end encryption and strict access controls, sensitive data stays protected from misconfigurations or breaches. As 78% of organizations now use AI in at least one area of their business [2], Prompts.ai provides enterprise-grade security while maintaining the speed and agility teams need to innovate. Every interaction is secure, traceable, and auditable, giving organizations the confidence to scale AI responsibly.
AI workloads often lead to unpredictable expenses that cannot be fully understood through monthly invoices. Real-time FinOps changes this by offering immediate insights into costs as they occur. By tracking token usage, GPU hours, and inference calls in near-real time, teams can identify and address budget overruns before they spiral out of control.
For instance, a financial analytics startup found that 40% of its 8-GPU cluster sat idle, wasting nearly $12,000 every month. Through real-time monitoring, the team identified this inefficiency mid-sprint and made adjustments to optimize capacity immediately.
Granular tracking by team, project, or customer further refines chargeback models. By attaching metadata such as customer IDs to API requests, spending becomes more transparent. This allows departments to pay only for what they use, paving the way for operations that are both scalable and cost-efficient.
Real-time tracking doesn’t just monitor costs - it actively supports smarter scaling decisions. Autoscaling can now factor in both performance metrics (like latency) and financial data (such as cost per prediction). For example, during traffic spikes, systems can throttle or reroute requests based on cost signals, ensuring resources are used efficiently.
"FinOps operates on near-real-time signals; weekly invoices are too late to change behavior."
StreamForge AI adopted this strategy in September 2025 by integrating Kubecost with Prometheus and displaying utilization data on Grafana dashboards refreshed every five minutes. Using a dual-signaling autoscaling approach - balancing p95 latency and cost-per-request metrics - they significantly boosted GPU utilization and improved the cost-effectiveness of over 300 daily training jobs. This real-time approach helps avoid costly misconfigurations that could drain monthly budgets.
Centralizing cost tracking across multiple AI providers is essential when managing diverse models. A unified AI gateway simplifies this process by consolidating token usage, latency, and cost data into a single, reliable source. Whether you’re using OpenAI, Anthropic, or self-hosted models, this centralized system eliminates the need to piece together fragmented billing data.
This level of integration is crucial because different models have vastly different price points. For instance, GPT-3.5-Turbo costs about $0.002 per 1,000 tokens, while GPT-4 can go up to $0.12 per 1,000 tokens depending on the context window. Real-time tracking allows teams to compare these costs and route tasks to the most economical model. Whether handling simple customer queries or complex analyses, tasks are assigned to the right model based on live cost data, ensuring workflows remain both efficient and budget-friendly.
Breaking AI workflows into modular components revolutionizes how they are deployed and scaled. Instead of relying on a single, rigid pipeline to handle every stage, a modular approach allows individual parts to be updated or replaced without disrupting the entire system.
This design also enables parallel execution, where multiple tasks can run at the same time. For instance, a multilingual translation service can process various language versions simultaneously rather than one after another, cutting down processing time significantly. Adopting MLOps practices further accelerates deployment, reducing the time to move a model into production by up to 90%. Automated pipelines can shrink deployment timelines from months to just days.
Another advantage is replayability. If a specific step, such as post-processing, encounters an issue, you can rerun just that module using stored artifacts instead of redoing the entire workflow. This targeted rerun approach saves both time and resources, especially for tasks that require significant computational power. Modular workflows also make it easier to standardize and securely integrate components across the system.
Once a modular foundation is in place, ensuring smooth communication between components becomes essential. Standardizing input and output formats helps avoid cascading errors. For example, if a data ingestion module outputs a clearly defined JSON file that aligns perfectly with the expected input of an inference module, potential miscommunications are eliminated.
Separating AI logic from policy logic further enhances maintainability. This allows you to manage dynamic model behavior independently from fixed business rules, as highlighted in AWS Prescriptive Guidance. Tools like Docker or Kubernetes can containerize modules, ensuring they remain portable across different environments. A containerized module can operate consistently in development, staging, and production, and can even transition between cloud providers without requiring changes. For orchestration, AWS Step Functions provide serverless coordination with built-in retries, while Apache Airflow offers Python-based flexibility for managing more intricate workflows.
Modular designs also bring financial benefits by letting you allocate the right resources for each task. Complex reasoning models, which are resource-intensive, can be reserved for demanding analyses, while simpler tasks are handled by less expensive models. This ensures computational resources are used wisely.
Tracking metadata at the module level enhances transparency. By attaching details like timestamps, model versions, and cost data to each artifact as it moves through the pipeline, teams gain a clear audit trail. This not only aids in debugging but also in financial tracking. Aligning costs with module-specific metrics allows for precise budgeting while maintaining flexibility. Additionally, setting limits on batch sizes and concurrency can help prevent unexpected expenses during periods of high demand.
It’s worth noting that about 85% of machine-learning models never make it to production, often due to immature pipeline structures. Modular, iterative workflows offer a way to overcome this challenge. Teams can start small, validate one module at a time, and gradually scale up, reducing risks and ensuring systems are ready for production.
Incorporating governance into your AI workflow from the very beginning saves you from costly adjustments down the line. By building on the automated evaluations and transparency discussed earlier, you can ensure compliance is baked into your processes right from the start. As soon as a model or use case is created, generate a tracking ticket in your workflow tool and assign an initial risk level. High-risk applications, such as credit scoring or hiring systems, demand stricter approval processes and closer monitoring compared to lower-risk tools used internally. This proactive "shift left" approach keeps you prepared for regulatory requirements, especially with frameworks like the EU AI Act mandating detailed documentation of training and evaluation processes.
A cornerstone of compliance is lineage tracking, which provides a clear and reproducible path from raw data to the final model output. Combine lineage tracking with snapshot traceability, ensuring that the exact state of your code, data, and configurations is preserved before deployment. This allows you to reproduce any model version as needed. Industry research highlights the urgency of these measures, noting a 56.4% increase in AI-related incidents in 2024, totaling 233 cases - emphasizing the need for robust audit trails.
Audit trails streamline troubleshooting by directly linking errors to their origins. Instead of sifting through logs manually, engineers can use lineage tracking to quickly identify where a pipeline broke or data quality declined. Automating governance tasks - like asset checks and risk evaluations - not only ensures compliance but also keeps your AI initiatives moving efficiently as they grow. By automating these steps, you can reduce approval times and maintain consistency across operations.
Strong data governance is essential for maintaining high-quality data. Centralized metadata management consolidates information about all AI assets in one place, removing redundancies and ensuring smooth operations. When every component, from prompts to model versions, is tracked with timestamps and cost details, teams gain a comprehensive execution history. This makes pipelines easier to reproduce and refine. Automated audit logs further reduce human error, establishing a reliable and repeatable workflow.
These governance strategies integrate seamlessly with modular workflows, ensuring compliance remains a core part of your system as it scales.
A unified governance layer ties together streamlined workflows and cost transparency, ensuring compliance across the board. Many systems - such as Snowflake, Databricks, cloud platforms, and edge environments - operate across multiple platforms. Without a unified governance approach, you risk "shadow AI", where models are deployed without oversight, making compliance verification impossible. Cross-system traceability ensures that runtime data lineage is captured across queries, notebooks, jobs, and dashboards, maintaining compliance as data moves between platforms. Standardized interfaces, like the Model Context Protocol (MCP) with centralized gateways, enable consistent logging and request tracking across servers and tenants. This gives you a complete audit trail, no matter where the work takes place.
Creating workflows from the ground up can be time-consuming and inefficient. Community-driven frameworks like LangChain and Ollama have become go-to solutions, offering pre-built templates for chaining prompts and integrating tools. These frameworks are widely adopted, with over 50% of developers using Ollama and nearly a third relying on LangChain to manage AI agents. They replace fragile custom code with flexible, serverless functions that operate independently, making them easier to manage and scale.
The key benefit is scalability without complexity. By relying on community-tested patterns, you can switch models - such as moving from GPT to Amazon Bedrock - without overhauling your orchestration logic. This flexibility speeds up deployment while maintaining consistency. Research shows that while orchestration is a priority for many organizations, only a few have fully implemented it. Community workflows offer a practical solution, enabling seamless integration across various AI platforms.
Community workflows also address the challenge of integrating AI tools across platforms. Standards like the Model Context Protocol (MCP) tackle the issue of platform sprawl, a concern for 63% of executives. These protocols allow AI agents and tools to work together across platforms like Gmail, Slack, and CRMs without requiring manual data entry. For example, a simple natural language request - such as "summarize the last 10 emails from Gmail" - can trigger structured tasks with pre-configured API connections.
"The gap isn't a lack of ambition. It's orchestration." - Eli Mogul, Telnyx
Interoperability is critical, with 87% of IT leaders identifying it as essential for adopting AI-driven systems. Community workflows are designed with resilience in mind, offering features like automated retries, timeouts, and parallel execution to handle potential model failures. These safeguards are vital, especially since 87% of developers worry about AI accuracy, and 81% are concerned about security and privacy. Beyond improving integration, these workflows also help reduce costs significantly.
Using community templates to transform natural language prompts into automated workflows can drastically cut costs and save time. Organizations report 40-60% cost reductions and 70-90% time savings when they adopt AI automation through these workflows. Starting with tested solutions eliminates the need for expensive trial-and-error processes.
These workflows also enhance transparency by incorporating standardized audit trails and metadata tracking. They automatically log details like data sources, permissions, and agent decision histories. Many include human-in-the-loop checkpoints for manual review of sensitive or high-cost tasks, ensuring oversight where it matters most. By managing inference costs during scaling, companies have seen an average 171% ROI when leveraging community-built workflows.
Automating testing and evaluation is the final piece in creating a seamless AI lifecycle. It eliminates the delays caused by manual testing, which often prevent models from reaching production - 85% of models fail to get deployed due to process inefficiencies. By leveraging automated CI/CD/CT (Continuous Training) pipelines, deployment times shrink from months to just days. These pipelines can automatically retrain models when performance metrics dip below set thresholds or when new data becomes available, removing the need for constant manual oversight.
The financial benefits are clear. Between 2022 and 2024, AI inference costs dropped 280-fold, making continuous monitoring and retraining a practical option. Automated pipelines also help catch issues early, avoiding costly errors. For example, poor data quality can cost companies $12.9 million annually, while unplanned system downtime can reach $125,000 per hour. Automated data validation steps, like identifying schema mismatches, null values, or distribution shifts, ensure issues are addressed at the ingestion stage, preventing larger problems down the line.
Automation not only accelerates workflows but also trims unnecessary expenses. Self-adjusting pipelines ensure retraining happens only when necessary, reducing the use of expensive GPU resources during idle periods. Tools like LLM-as-a-Judge streamline evaluation processes, cutting costs while maintaining over 80% consistency across thousands of tests.
Testing strategies can further optimize budgets. Simulating tests with tools like Dev Proxy allows you to stress-test endpoints without incurring per-call fees. Starting with smaller models and representative datasets helps validate ideas before committing to full-scale evaluations. Additionally, tagging cloud resources by project, team, or model version provides detailed billing insights, making it easier to decide which workflows are worth the investment.
Automated testing also bolsters governance by creating the audit trails regulators require. Governance gates ensure workflows pause until critical assets - like schemas and baseline data - are validated. Each model snapshot undergoes a standard risk assessment, with results automatically logged and failure-triggered tickets issued for tracking.
Automation can monitor for three key types of drift: data drift (shifts in input distributions), performance drift (declines in accuracy or slower response times), and safety drift (increased toxicity or exposure of sensitive information). Alerts flag these issues early, preventing them from affecting end users. Additionally, kill switches allow teams to quickly disable problematic model routes or features during incidents, demonstrating a hands-on approach to governance that ensures systems remain under control when it matters most.
Pay-as-you-go plans are a smart way to manage AI expenses while enabling teams to grow and adapt effortlessly. These plans build on strategies like cost tracking and modular scalability to ensure that resources are used efficiently.
With pay-as-you-go pricing, you’re only charged for the tokens and compute time you actually use. Real-time dashboards provide insights into token consumption, latencies, and outcomes, helping to pinpoint inefficiencies and eliminate unnecessary spending. When combined with scale-to-zero capabilities, this model becomes even more effective - idle inference endpoints automatically shut down, so you’re not paying for unused GPU resources.
For tasks that aren’t time-sensitive, such as exploratory data analysis or offline model training, spot pricing offers a lower-cost alternative to on-demand rates. These savings add up, especially when paired with tools that track usage and performance in real time, allowing teams to fine-tune their compute needs and stay within budget.
Elastic compute ensures that your workflows can adapt to changing demands without manual adjustments. Features like autoscaling node pools and serverless architectures handle fluctuating workloads seamlessly, so there’s no need to overprovision resources for peak usage. By separating model artifacts from application code and using cloud storage, pods can start up almost instantly, making scaling operations faster and more efficient.
This approach is particularly valuable when transitioning from pilot projects to full-scale production. As the global MLOps market grows - expected to rise from $1.58 billion in 2024 to $2.33 billion by 2025 - organizations need scalable systems that won’t require constant rebuilding. Pay-as-you-go plans align costs with actual usage, making it easier to expand models, users, or teams without driving up expenses.
Pay-as-you-go plans work hand-in-hand with advanced team tools to streamline cost management and operational workflows. Modern tools integrate governance, audit trails, and security features like single sign-on (SSO) and role-based access control (RBAC) directly into the orchestration layer. These capabilities are essential for meeting compliance requirements such as SOC 2 or ISO 27001.
Platforms offering support for OpenAI-compatible APIs allow teams to switch between LLM providers or models without overhauling their workflows, ensuring flexibility as new technologies emerge. Managed environments further enhance team operations by incorporating features like permissions, SLAs, centralized metadata tracking, and authorization controls. These systems not only scale alongside your organization but also maintain the transparency and control needed to meet regulatory standards, ensuring every team member has the right access and every action is logged for auditing.
Building effective AI workflows requires powerful models combined with a structured and scalable approach. The seven practices discussed earlier help transform disjointed AI initiatives into streamlined, enterprise-ready processes. By incorporating diverse LLMs, maintaining continuous cost monitoring, and leveraging modular designs, you can remove bottlenecks and create workflows that evolve alongside your needs. Starting with governance ensures every AI decision is both traceable and compliant, while community-driven prompts and automated testing cycles speed up development without compromising quality. These strategies form the backbone of efficient and reliable AI operations.
As highlighted earlier, these methods can improve efficiency by 20% to 50% across workflows like onboarding and incident management. Real-time cost tracking, paired with pay-as-you-go models, keeps expenses aligned with usage, avoiding budget overruns while supporting seamless scaling. By integrating automation and feedback loops, AI systems can self-optimize, identifying anomalies, suggesting refinements, and autonomously managing complex tasks.
The move toward integrated governance and adaptive architectures underscores the importance of building workflows on solid foundations. Standardized tools, clear component boundaries, and detailed traces ensure your systems stay flexible as new models and capabilities emerge. By focusing on scalable, repeatable processes, you can transition from pilot projects to full-scale production without constant overhauls.
Together, these strategies turn fragmented experiments into efficient, accountable, and cost-conscious workflows. Ready to take control of your AI workflows? With Prompts.ai, you can secure your models, manage costs, and scale effortlessly. Access over 35 top models, utilize built-in FinOps controls, and implement enterprise-grade governance - all within a single interface. Prompts.ai eliminates tool sprawl, ensures compliance, and lets your team focus on innovation, turning AI chaos into a streamlined, ROI-driven operation.
To choose the most suitable large language model (LLM), begin by clearly identifying your specific needs - whether it's for writing, coding, customer support, or another application. Evaluate models using a structured approach that considers factors like performance, cost, and privacy. For tasks with minimal risk, prioritize models that are quicker and more budget-friendly. On the other hand, high-stakes tasks demand models that are more reliable and include proper oversight. Benchmarking is a critical step to ensure the chosen model meets both your task requirements and operational goals.
To keep AI costs under control, it's essential to monitor token usage as it happens. This involves tracking requests, prompts, and model calls. By staying on top of these metrics, you can spot inefficiencies and make adjustments to optimize resource use, maintaining a balance between cost and performance.
To stay ahead of model drift, set up automated monitoring systems that keep a close eye on performance metrics and data quality in real time. These tools can spot shifts like concept drift, covariate shift, or label drift by examining changes in data distribution and prediction accuracy. When drift is detected, predefined retraining triggers can kick in to update your models quickly, maintaining consistent validation and smooth integration within your MLOps processes.



















