Pago por Uso - AI Model Orchestration and Workflows Platform

En un panorama saturado de IA, elegir el modelo de lenguaje grande (LLM) adecuado puede resultar abrumador. Con modelos como GPT-5, Claude y Gemini que destacan en diferentes áreas, las plataformas de comparación simplifican el proceso de toma de decisiones al ofrecer análisis en paralelo de rendimiento, costos y casos de uso. Esto es lo que necesita saber:
Estas plataformas satisfacen diferentes necesidades, ya sea que esté optimizando costos, garantizando la seguridad o evaluando las capacidades de codificación. A continuación se muestra una comparación rápida para ayudarle a decidir.
La elección de la plataforma adecuada depende de sus objetivos, ya sea reducir costos, garantizar el cumplimiento de la seguridad o mejorar la productividad. Plataformas como Prompts.ai se destacan para empresas que administran múltiples LLM, mientras que APX Coding LLM es perfecto para desarrolladores. Cada herramienta ofrece una perspectiva única para guiar su estrategia de IA.
Prompts.ai es una plataforma de inteligencia artificial empresarial diseñada para simplificar el proceso de comparación e implementación de modelos de lenguajes grandes (LLM). Al consolidar más de 35 LLM líderes en un panel único y unificado, la plataforma elimina la necesidad de hacer malabarismos con múltiples herramientas. Esta configuración optimizada no solo reduce la complejidad sino que también permite a los equipos tomar decisiones bien informadas al comparar modelos sobre rendimiento, costo y velocidad de integración, todo en un solo lugar.
Prompts.ai ofrece acceso a una amplia gama de modelos de IA de última generación, incluidos GPT-5, Claude, LLaMA, Gemini, Grok-4, Flux Pro y Kling, entre otros. Esta extensa biblioteca permite a los usuarios evaluar modelos con diferentes fortalezas y especialidades sin la molestia de cambiar de plataforma o administrar múltiples claves API.
The platform's ability to aggregate these models ensures users can evaluate them based on real-world applications. Whether it’s testing coding efficiency, creative writing skills, or expertise in specific domains, the side-by-side comparison feature enables simultaneous testing of identical prompts across multiple models.
Prompts.ai adopta un enfoque centrado en el usuario para la evaluación de modelos, ofreciendo una flexibilidad que va más allá de los puntos de referencia genéricos. En lugar de depender de métricas preestablecidas, los usuarios pueden crear escenarios de evaluación personalizados adaptados a sus necesidades únicas, utilizando sus propias indicaciones y datos.
The platform’s interface displays results side by side, offering a clear view of output quality, response times, and methodologies. This approach is especially beneficial for businesses that need to test models against proprietary datasets or industry-specific challenges that standard benchmarks fail to address.
Prompts.ai integra una capa FinOps que proporciona seguimiento en tiempo real del uso de tokens en todos los modelos. Al monitorear el consumo de tokens, los equipos pueden comparar directamente el desempeño y las implicaciones financieras, lo que facilita la evaluación de qué modelos ofrecen el mejor valor.
The platform’s Pay-As-You-Go TOKN credit system ensures that costs align with actual usage, potentially reducing expenses by up to 98%. For organizations managing tight budgets or allocating resources across multiple AI projects, this level of cost clarity supports smarter, data-driven decisions.
Prompts.ai keeps its users ahead of the curve by rapidly integrating new models as they become available. Its architecture is built for agility, ensuring emerging models are added quickly, so users don’t face delays in accessing the latest advancements.
Más allá de los nuevos modelos, la plataforma también implementa actualizaciones y optimizaciones sin problemas. A medida que los modelos mejoran y se lanzan nuevas versiones, los usuarios pueden confiar en Prompts.ai para brindar acceso ininterrumpido a estas mejoras, lo que les permitirá seguir siendo competitivos en un panorama de IA en constante evolución.
El análisis artificial se centra en ofrecer evaluaciones consistentes y exhaustivas de modelos de lenguaje grandes (LLM) a través de puntos de referencia estandarizados y procesos de prueba repetibles. Al adherirse a un enfoque sistemático, la plataforma proporciona información detallada sobre cómo se desempeñan los diferentes LLM en una variedad de tareas cognitivas y aplicaciones prácticas.
The platform maintains an extensive database that includes evaluations of both proprietary and open-source LLMs from leading AI developers like OpenAI, Anthropic, Google, Meta, and newer players in the field. It doesn’t stop at mainstream models but also includes specialized and fine-tuned versions, offering users the chance to explore options tailored to unique or niche requirements. This wide-ranging coverage ensures users can access performance data for virtually any model they might consider.
El análisis artificial emplea una sólida metodología de evaluación comparativa de inteligencia diseñada para evaluar modelos en múltiples dimensiones. En lugar de depender de una única métrica, la plataforma utiliza un sistema de puntuación ponderada que evalúa el razonamiento, la precisión, la creatividad y las capacidades específicas de las tareas. Cada modelo se prueba rigurosamente con conjuntos de datos y solicitudes estandarizados, y los resultados se normalizan para garantizar comparaciones justas entre diversas arquitecturas y tamaños. Una combinación de puntuación automatizada y evaluaciones humanas añade profundidad y confiabilidad a estas evaluaciones.
Para mantenerse al día con el panorama de LLM que cambia rápidamente, el Análisis Artificial actualiza con frecuencia sus metodologías. La actualización más reciente, la versión 3.0, se lanzó el 2 de septiembre de 2025. Estas actualizaciones periódicas garantizan que la plataforma siga siendo una fuente confiable de información actualizada y procesable, lo que permite a los usuarios tomar decisiones informadas al seleccionar el mejor modelo de lenguaje para sus necesidades.
LMSYS Chatbot Arena es una plataforma colaborativa diseñada para evaluar grandes modelos de lenguaje (LLM) a través de comentarios humanos en tiempo real. Este enfoque garantiza que las evaluaciones sigan siendo relevantes al capturar tanto las interacciones de los usuarios como las mejoras continuas en los modelos.
La plataforma alberga una selección diversa de modelos, incluidas opciones patentadas, de código abierto y experimentales. Esto permite a los usuarios probar y comparar el rendimiento de diferentes modelos en una amplia gama de tareas y aplicaciones.
Para minimizar el sesgo, los usuarios realizan comparaciones ciegas por pares entre modelos. Luego, los resultados se agregan para clasificar los modelos según su calidad conversacional, originalidad y utilidad práctica.
La tabla de clasificación se actualiza continuamente con los comentarios de los usuarios, lo que garantiza que refleje los últimos lanzamientos de modelos y las tendencias de rendimiento.
La tabla de clasificación de Vellum AI ofrece información procesable sobre el rendimiento del modelo, diseñada específicamente para aplicaciones empresariales prácticas.
La tabla de clasificación presenta una selección cuidadosamente seleccionada de modelos comerciales y de código abierto diseñados para uso empresarial. Estos incluyen ofertas de proveedores como OpenAI, Anthropic y Google, junto con opciones de código abierto como Llama 2 y Mistral.
Lo que hace que Vellum se destaque es su enfoque en modelos listos para el negocio. En lugar de enumerar opciones experimentales o no probadas, destaca modelos que han demostrado confiabilidad y son adecuados para su implementación comercial.
Vellum evalúa modelos utilizando un enfoque estructurado en seis categorías clave: razonamiento, generación de código, escritura creativa, precisión de los hechos, seguimiento de instrucciones y cumplimiento de seguridad.
Cada modelo se prueba con indicaciones que imitan escenarios empresariales del mundo real, combinando puntuación automatizada con revisión humana. Esta evaluación de doble nivel garantiza que los resultados reflejen la usabilidad práctica en lugar de solo puntos de referencia teóricos. Las actualizaciones periódicas del proceso de evaluación garantizan que la tabla de clasificación se mantenga alineada con los últimos desarrollos en el espacio LLM.
La tabla de clasificación se actualiza mensualmente, con actualizaciones adicionales para los principales lanzamientos de modelos. Este programa garantiza pruebas exhaustivas y, al mismo tiempo, se mantiene actualizado con los rápidos avances en grandes modelos de lenguaje.
Vellum también realiza un seguimiento del rendimiento histórico, lo que permite a los usuarios revisar cómo han evolucionado los modelos a lo largo del tiempo. Esta característica ayuda a las empresas a tomar decisiones informadas sobre cuándo adoptar nuevos modelos o actualizar los existentes.
Vellum proporciona desgloses detallados de costos, incluidos precios por 1000 tokens y costos estimados para tareas como atención al cliente, creación de contenido y asistencia con códigos.
LiveBench aborda el desafío de la contaminación de datos actualizando frecuentemente sus preguntas de referencia. Esto garantiza que los modelos se evalúen con material nuevo, evitando que simplemente memoricen datos de entrenamiento.
LiveBench admite una amplia variedad de modelos, desde sistemas más pequeños con 500 millones de parámetros hasta sistemas masivos con 405 mil millones de parámetros. Ha evaluado 49 modelos de lenguajes grandes (LLM) diferentes, incluidas plataformas propietarias líderes, alternativas destacadas de código abierto y modelos especializados de nicho.
The platform’s robust API compatibility allows seamless evaluation of any model with an OpenAI-compatible endpoint. This includes models from providers like Anthropic, Cohere, Mistral, Together, and Google.
A partir del 9 de octubre de 2025, la tabla de clasificación muestra modelos avanzados como la serie GPT-5 de OpenAI (High, Medium, Pro, Codex, Mini, o3, o4-Mini), Claude Sonnet 4.5 y Claude 4.1 Opus de Anthropic, Gemini 2.5 Pro y Flash de Google, Grok 4 de xAI, DeepSeek V3.1 y Qwen 3 Max de Alibaba.
LiveBench utiliza una metodología resistente a la contaminación y prueba modelos en 21 tareas divididas en siete categorías, que incluyen razonamiento, codificación, matemáticas y comprensión del lenguaje. Para mantener la integridad de sus puntos de referencia, la plataforma actualiza todas las preguntas cada seis meses e introduce tareas más complejas con el tiempo. Por ejemplo, la última versión, LiveBench-2025-05-30, agregó una tarea de codificación agente en la que los modelos deben navegar por entornos de desarrollo del mundo real para resolver problemas del repositorio.
Para salvaguardar aún más el proceso de evaluación, alrededor de 300 preguntas de actualizaciones recientes (aproximadamente el 30% del total) permanecen sin publicar. Esto garantiza que los modelos no puedan entrenarse con los datos de prueba exactos. Estas medidas, combinadas con actualizaciones periódicas, mantienen el índice de referencia relevante y desafiante.
LiveBench sigue un estricto cronograma de actualización, publica nuevas preguntas constantemente y actualiza el punto de referencia completo cada seis meses. Los usuarios pueden solicitar evaluaciones de modelos recientemente desarrollados enviando un problema de GitHub o comunicándose con el equipo de LiveBench por correo electrónico. Esto permite evaluar los modelos emergentes sin esperar a la próxima actualización programada. Las incorporaciones recientes de diciembre de 2024 incluyen modelos como claude-3-5-haiku-20241022, claude-3-5-sonnet-20241022, gemini-exp-1114, gpt-4o-2024-11-20, grok-2 y grok-2-mini.
LLM-Stats proporciona una forma basada en datos de comparar modelos de lenguajes grandes mediante el análisis de estadísticas agregadas de una variedad de puntos de referencia. Si bien ofrece información valiosa sobre el rendimiento del modelo, no se han compartido detalles específicos como cómo se clasifican los modelos, los métodos de evaluación utilizados, los detalles de precios y la frecuencia con la que se actualizan los datos. Este enfoque estadístico sirve como una contraparte útil de las comparaciones cualitativas anteriores.
OpenRouter Rankings adopta un enfoque práctico para evaluar el rendimiento de los modelos de lenguaje, centrándose en cómo se desempeñan los modelos en escenarios del mundo real en lugar de depender únicamente de puntos de referencia técnicos. Al agregar datos del uso diario, destaca qué modelos realmente ofrecen valor en aplicaciones prácticas. Este énfasis en métricas del mundo real complementa las evaluaciones técnicas más detalladas proporcionadas por otras plataformas.
La plataforma incluye una variedad de modelos de lenguaje, organizados en función de sus aplicaciones específicas. Al categorizar los modelos según sus casos de uso, ayuda a los usuarios a identificar fácilmente las soluciones que se alinean con sus necesidades particulares.
OpenRouter Rankings uses a usage-based evaluation system, considering multiple factors like response quality, efficiency, and cost. These metrics are combined into composite scores that provide a clear picture of each model’s overall effectiveness and value.
Las clasificaciones se actualizan periódicamente para tener en cuenta los cambios en el rendimiento del modelo y las tendencias de uso, lo que garantiza que los datos sigan siendo relevantes y actualizados.
Un enfoque clave de la plataforma está en los factores económicos. Al analizar los precios y las métricas relacionadas con los costos, proporciona claridad sobre el equilibrio entre costo y rendimiento, lo que ayuda a los usuarios a tomar decisiones informadas.
La tabla de clasificación Hugging Face Open LLM se destaca como una plataforma dedicada para evaluar el rendimiento de los modelos de lenguaje de código abierto. Diseñado por Hugging Face, sirve como recurso central para investigadores y desarrolladores que buscan comparar modelos con puntos de referencia estandarizados. Al centrarse exclusivamente en modelos de código abierto, la clasificación se alinea con las necesidades de quienes valoran la transparencia y la accesibilidad abierta en sus soluciones de IA. Complementa las comparaciones empresariales y basadas en el rendimiento discutidas anteriormente, ofreciendo una perspectiva única sobre el panorama de la IA de código abierto.
La tabla de clasificación organiza una amplia gama de modelos de código abierto por tamaño de parámetro (7B, 13B, 30B y 70B+) que abarcan tanto diseños experimentales como implementaciones a gran escala de instituciones de investigación líderes.
Presenta contribuciones de organizaciones y desarrolladores individuales, fomentando un ecosistema diverso y dinámico que refleja el estado actual de la IA de código abierto. Cada entrada del modelo incluye información detallada sobre arquitectura, datos de capacitación y términos de licencia, lo que permite a los usuarios tomar decisiones informadas basadas en las necesidades de su proyecto y los requisitos de cumplimiento.
Utilizando un marco de evaluación estandarizado, Hugging Face evalúa los modelos en múltiples puntos de referencia, ofreciendo un análisis exhaustivo de sus capacidades. Estos puntos de referencia cubren habilidades de razonamiento, retención de conocimientos, resolución de problemas matemáticos y comprensión lectora, lo que garantiza una visión completa del rendimiento de cada modelo.
La plataforma emplea procesos automatizados para mantener condiciones de prueba consistentes en todos los modelos. Esto elimina las discrepancias causadas por diferentes entornos o metodologías, proporcionando a los usuarios comparaciones confiables de manzanas con manzanas para identificar la mejor opción para sus casos de uso específicos.
La tabla de clasificación se actualiza continuamente con nuevos modelos a medida que surgen en la comunidad de código abierto. Gracias a su proceso de evaluación automatizado, los modelos se pueden evaluar y clasificar rápidamente sin retrasos causados por la intervención manual.
Además, la plataforma reevalúa los modelos existentes cada vez que se perfeccionan las metodologías de referencia. Esto garantiza que los modelos más antiguos sigan estando representados de manera justa, manteniendo la relevancia y confiabilidad de la tabla de clasificación a lo largo del tiempo.
While the leaderboard doesn’t provide direct pricing, it includes key details such as model size, memory requirements, and inference speed. These metrics help users estimate the infrastructure costs involved in deploying each model.
Este enfoque en los requisitos computacionales permite a las organizaciones tomar decisiones conscientes del presupuesto, especialmente aquellas que trabajan con recursos limitados o restricciones de hardware específicas. Al enfatizar los modelos de código abierto, la plataforma también elimina las tarifas de licencia constantes, lo que hace que el costo total de propiedad sea más predecible y, a menudo, más manejable en comparación con las alternativas patentadas.
La tabla de clasificación Scale AI SEAL está dedicada a evaluar la seguridad, la alineación y el rendimiento de grandes modelos de lenguaje (LLM), abordando inquietudes empresariales clave sobre la implementación responsable de la IA. A diferencia de las tablas de clasificación de propósito general, SEAL se centra en evaluar qué tan bien los modelos manejan contenido confidencial, cumplen con las pautas éticas y mantienen un comportamiento consistente en diversos escenarios. Esto resalta la importancia de la seguridad y el cumplimiento ético junto con el desempeño puro en entornos empresariales. Su enfoque especializado proporciona información detallada sobre las capacidades del modelo, los métodos de evaluación, los cronogramas de actualización y los costos asociados.
SEAL revisa una combinación de modelos propietarios y de código abierto, con un fuerte enfoque en los que se usan comúnmente en aplicaciones comerciales. La clasificación incluye modelos comerciales de alto perfil como GPT-4, Claude y Gemini, así como opciones populares de código abierto como las variantes Llama 2 y Mistral.
Lo que distingue a SEAL es su énfasis en modelos listos para la empresa en lugar de versiones experimentales o centradas en la investigación. Cada modelo se prueba en varios tamaños de parámetros y configuraciones ajustadas, lo que ofrece una comprensión más profunda de cómo estas variaciones impactan el equilibrio entre seguridad y rendimiento. La plataforma también evalúa modelos especializados diseñados para industrias como la atención médica o las finanzas, donde el cumplimiento normativo y la gestión de riesgos son fundamentales.
SEAL utiliza un marco de evaluación exhaustivo que combina métricas de desempeño tradicionales con pruebas de seguridad exhaustivas. Los modelos se evalúan según su capacidad para rechazar indicaciones dañinas, mantener la precisión de los hechos y evitar producir resultados sesgados o discriminatorios.
El proceso de evaluación incluye ejercicios de formación de equipos rojos y revisiones humanas para descubrir vulnerabilidades y sesgos sutiles que las pruebas automatizadas podrían pasar por alto. Al combinar evaluaciones automatizadas y manuales, SEAL garantiza que las consideraciones de seguridad reciban la misma importancia que las métricas de rendimiento.
La tabla de clasificación SEAL se actualiza trimestralmente, lo que refleja la naturaleza detallada y centrada en la seguridad de sus evaluaciones. Cada actualización incorpora modelos recién lanzados y reevalúa los existentes comparándolos con estándares y puntos de referencia de seguridad en evolución.
Además de estas actualizaciones programadas, Scale AI publica informes provisionales cuando ocurren actualizaciones importantes del modelo o incidentes relacionados con la seguridad dentro de la comunidad de IA. Este enfoque adaptativo garantiza que los usuarios empresariales tengan acceso oportuno a las últimas evaluaciones de seguridad, lo cual es especialmente importante dado el rápido ritmo de los avances del modelo. Estas actualizaciones periódicas también proporcionan datos valiosos para analizar los costos de implementación.
While SEAL doesn’t disclose direct pricing, it offers insights into the total cost of ownership, including factors like content moderation, compliance requirements, and liability risks. This helps enterprises weigh the costs of safety measures against operational expenses.
La plataforma también proporciona orientación sobre las necesidades de infraestructura para diversas configuraciones de seguridad, ayudando a las organizaciones a comprender las ventajas y desventajas entre una mayor seguridad y los costos operativos. Para los usuarios empresariales, SEAL estima ahorros potenciales gracias a la reducción de los esfuerzos de moderación de contenido al implementar modelos con sólidas funciones de seguridad integradas.
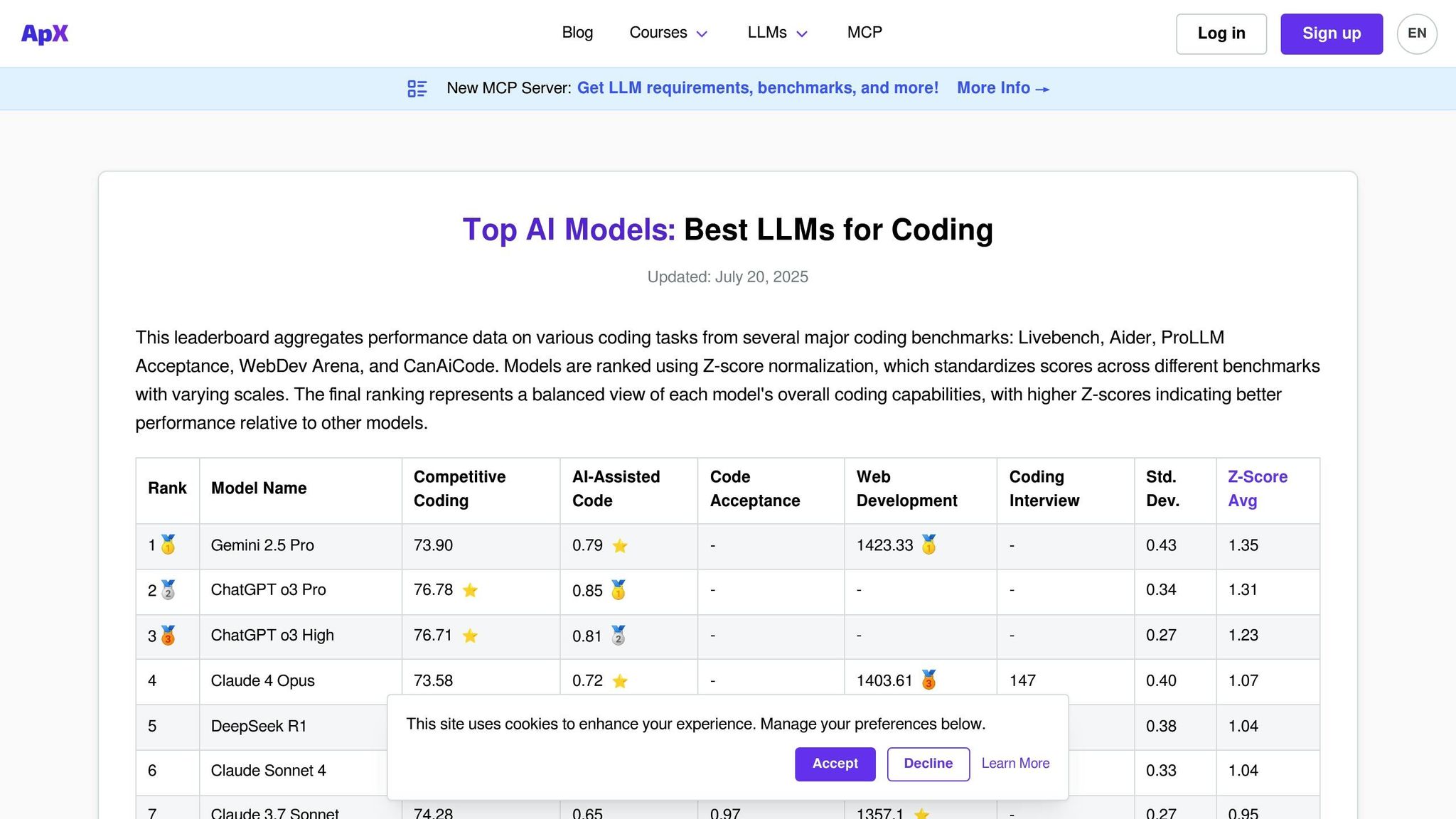
APX Coding LLMs es una plataforma diseñada específicamente para evaluar las capacidades de codificación de modelos de lenguaje. A diferencia de las tablas de clasificación de uso general que se centran en una amplia gama de habilidades conversacionales, APX se concentra en áreas como generación de código, depuración, implementación de algoritmos y resolución de problemas técnicos. Este enfoque lo convierte en una herramienta esencial para desarrolladores, equipos de ingeniería y organizaciones que buscan integrar asistentes de codificación con tecnología de inteligencia artificial en sus flujos de trabajo.
La plataforma evalúa cómo los modelos manejan los desafíos prácticos de programación en varios lenguajes y marcos. Al igual que otras plataformas de evaluación, APX simplifica el proceso de evaluación pero con un gran enfoque en el rendimiento y la seguridad del código.
APX presenta una amplia gama de modelos comerciales y de código abierto probados por su experiencia en codificación. La plataforma evalúa periódicamente modelos de codificación conocidos, como los modelos GPT subyacentes de GitHub Copilot, las variantes CodeT5, StarCoder y Code Llama. También incluye modelos de uso general con sólidas capacidades de programación, como GPT-4, Claude y Gemini.
Un diferenciador clave para APX es la inclusión de modelos de codificación especializados que pueden no aparecer en tablas de clasificación más amplias, pero sobresalen en áreas de programación específicas. Estos modelos se prueban en varios tamaños de parámetros y versiones ajustadas, incluidas variantes específicas de dominio para lenguajes como Python, JavaScript, Java, C++, Rust y Go. La plataforma también evalúa el rendimiento con marcos como React, Django, TensorFlow y PyTorch.
Esta cobertura integral garantiza que APX proporcione pruebas rigurosas y prácticas para las necesidades de codificación del mundo real.
APX emplea un marco de prueba detallado adaptado a escenarios de codificación del mundo real. Evalúa modelos en aspectos como la corrección del código, la eficiencia, la legibilidad y el cumplimiento de los estándares de seguridad mediante una combinación de pruebas automatizadas y revisiones de expertos.
Los escenarios de prueba incluyen desafíos de algoritmos, depuración de código defectuoso, tareas de refactorización y generación de documentación. Los modelos también se evalúan por su capacidad para explicar conceptos de código complejos y sugerir optimizaciones.
Incorporating industry-standard coding practices, APX evaluates whether models follow established conventions for naming, commenting, and structuring code. Additionally, it tests the models’ ability to recognize and avoid common security vulnerabilities, making it especially valuable for enterprises where secure coding is a priority.
La tabla de clasificación APX se actualiza mensualmente para seguir el ritmo del panorama en rápida evolución de las herramientas de codificación de IA. Las actualizaciones incluyen la incorporación de modelos recientemente lanzados y reevaluaciones de los existentes, lo que garantiza la alineación con los últimos desafíos y estándares de programación.
La plataforma también ofrece seguimiento del rendimiento en tiempo real para actualizaciones importantes del modelo, lo que brinda a los desarrolladores acceso inmediato a las últimas capacidades. Cuando se lanzan modelos importantes centrados en la codificación, APX lleva a cabo ciclos de evaluación especiales para proporcionar información oportuna sobre su desempeño.
APX proporciona un desglose detallado del análisis de costo por token diseñado específicamente para tareas de codificación. Este análisis ayuda a los usuarios a comprender las implicaciones de costos de diferentes modelos para diversos casos de uso. Los costos se desglosan por lenguaje de programación y complejidad de las tareas, lo que ofrece información clara sobre qué modelos ofrecen el mejor valor.
El análisis de costos considera factores como la frecuencia de llamadas a la API durante las tareas de codificación típicas, los patrones de uso de tokens y los ahorros potenciales derivados de la reducción del tiempo de depuración. APX incluso estima el costo total de propiedad de los equipos que adoptan asistentes de codificación de IA, sopesando las ganancias de productividad con las tarifas de suscripción y uso. Este nivel de detalle convierte a APX en un recurso valioso para evaluar el impacto financiero de las soluciones de codificación basadas en IA.
Las plataformas de comparación en paralelo para modelos de lenguajes grandes (LLM) satisfacen una variedad de necesidades. Prompts.ai se destaca por ofrecer acceso a más de 35 modelos de primer nivel, junto con herramientas centralizadas para gestionar costos y garantizar la gobernanza. Esto lo convierte en una buena opción para organizaciones más grandes que necesitan flujos de trabajo seguros y compatibles con una supervisión sólida.
Si bien Prompts.ai enfatiza la gestión y la gobernanza de costos, otras plataformas se centran en diferentes prioridades. Estos pueden incluir comentarios impulsados por la comunidad, puntos de referencia técnicos o métricas especializadas como seguridad y alineación. Estas plataformas varían en su selección de modelos, métodos de evaluación, cronogramas de actualización y transparencia en los precios.
This summary complements earlier in-depth analyses, helping you identify the tools that best fit your goals. Whether your focus is budget, technical depth, or specific use cases, it’s worth noting that many organizations rely on a mix of platforms to achieve a well-rounded understanding of both technical and business needs.
When evaluating platforms for large language model (LLM) comparison, the best choice ultimately hinges on balancing factors like cost, performance, and compliance. The decision should align with your organization’s specific needs, technical capabilities, and workflow demands.
For enterprises seeking a unified AI orchestration solution, Prompts.ai offers a compelling option. With access to over 35 leading LLMs, integrated cost management tools, and enterprise-grade governance controls, it’s designed to simplify operations for organizations overseeing multiple teams and complex projects.
That said, the LLM platform landscape is diverse, and there’s no universal solution that fits every scenario. Many organizations adopt a mix of tools to address both research and production requirements. By focusing on your primary goals - whether it’s reducing costs, enhancing performance, or ensuring compliance - you can refine your platform selection process and streamline AI implementation.
Elegir las herramientas de orquestación y comparación adecuadas puede generar mejoras mensurables en sus iniciativas de IA e impulsar resultados comerciales significativos.
Prompts.ai simplifica el desafío de evaluar múltiples modelos de lenguajes grandes (LLM) al brindar información clara y práctica sobre su rendimiento, escalabilidad y rentabilidad. Esto permite a los usuarios tomar decisiones informadas, seleccionando el modelo que mejor se adapte a sus necesidades sin salirse del presupuesto.
Con herramientas diseñadas para evaluar el equilibrio entre costo y rendimiento, así como la eficiencia operativa, Prompts.ai garantiza que las empresas puedan evitar gastos innecesarios y concentrarse en implementar las soluciones más efectivas adaptadas a sus requisitos únicos.
Las plataformas que ofrecen herramientas para personalizar las comparaciones de modelos de lenguaje grandes (LLM) son invaluables porque permiten a los usuarios ajustar las evaluaciones para que coincidan con sus objetivos únicos. Al centrarse en aspectos críticos como el rendimiento, las características y las aplicaciones prácticas, estas herramientas simplifican el proceso de identificación del modelo más adecuado, reduciendo las conjeturas.
Estas herramientas de comparación también ofrecen evaluaciones comparativas más detalladas y ofrecen información valiosa para investigadores, desarrolladores y empresas por igual. Ya sea que esté perfeccionando una solución para una tarea específica o sopesando múltiples opciones, estas plataformas hacen que la toma de decisiones sea más rápida y efectiva.
Actualizar periódicamente los métodos de evaluación y las bases de datos de modelos es esencial para mantener la precisión, la confiabilidad y la credibilidad en las plataformas de IA. Estas actualizaciones permiten que los modelos se mantengan actualizados incorporando datos nuevos, adaptándose a las tendencias y abordando nuevos casos de uso, lo que en última instancia mejora el rendimiento y la toma de decisiones.
El refinamiento constante de las metodologías permite a las plataformas abordar los sesgos, mejorar la adaptabilidad del modelo y cumplir con los estándares cambiantes de la industria. Esta dedicación al progreso garantiza que las soluciones de IA sigan siendo eficientes, conformes y equipadas para satisfacer las necesidades de los usuarios en un entorno en rápida evolución.



















