按需付费 - AI Model Orchestration and Workflows Platform

在拥挤的人工智能领域,选择正确的大语言模型 (LLM) 可能会让人不知所措。 GPT-5、Claude 和 Gemini 等模型在不同领域表现出色,比较平台通过提供性能、成本和用例的并行分析来简化决策过程。以下是您需要了解的内容:
这些平台可满足不同的需求 - 无论您是在优化成本、确保安全还是评估编码能力。下面是一个快速比较,可以帮助您做出决定。
选择正确的平台取决于您的目标 - 无论是降低成本、确保安全合规性还是提高生产力。像 Prompts.ai 这样的平台非常适合管理多个 LLM 的企业,而 APX Coding LLM 则非常适合开发人员。每个工具都提供了独特的视角来指导您的人工智能策略。
Prompts.ai 是一个企业人工智能平台,旨在简化比较和部署大型语言模型 (LLM) 的过程。通过将超过 35 个领先的法学硕士整合到一个统一的仪表板中,该平台消除了同时使用多个工具的需要。这种简化的设置不仅降低了复杂性,而且使团队能够通过比较模型的性能、成本和集成速度来做出明智的决策 - 所有这些都在一个地方。
Prompts.ai 提供对各种最先进的 AI 模型的访问,包括 GPT-5、Claude、LLaMA、Gemini、Grok-4、Flux Pro 和 Kling 等。这个广泛的库允许用户评估具有不同优势和专业的模型,而无需切换平台或管理多个 API 密钥的麻烦。
The platform's ability to aggregate these models ensures users can evaluate them based on real-world applications. Whether it’s testing coding efficiency, creative writing skills, or expertise in specific domains, the side-by-side comparison feature enables simultaneous testing of identical prompts across multiple models.
Prompts.ai 采用用户至上的方法进行模型评估,提供超越通用基准的灵活性。用户可以使用自己的提示和数据,根据自己的独特需求创建个性化的评估场景,而不是依赖预设的指标。
The platform’s interface displays results side by side, offering a clear view of output quality, response times, and methodologies. This approach is especially beneficial for businesses that need to test models against proprietary datasets or industry-specific challenges that standard benchmarks fail to address.
Prompts.ai 集成了 FinOps 层,可实时跟踪所有模型的代币使用情况。通过监控代币消耗,团队可以直接比较性能和财务影响,从而更轻松地评估哪些模型提供最佳价值。
The platform’s Pay-As-You-Go TOKN credit system ensures that costs align with actual usage, potentially reducing expenses by up to 98%. For organizations managing tight budgets or allocating resources across multiple AI projects, this level of cost clarity supports smarter, data-driven decisions.
Prompts.ai keeps its users ahead of the curve by rapidly integrating new models as they become available. Its architecture is built for agility, ensuring emerging models are added quickly, so users don’t face delays in accessing the latest advancements.
除了新型号之外,该平台还无缝推出更新和优化。随着模型的改进和新版本的发布,用户可以依靠 Prompts.ai 提供对这些增强功能的不间断访问,使他们能够在不断发展的人工智能领域保持竞争力。
人工分析专注于通过标准化基准和可重复的测试流程对大型语言模型 (LLM) 提供一致且全面的评估。通过坚持系统化方法,该平台可以深入了解不同的法学硕士在各种认知任务和实际应用中的表现。
The platform maintains an extensive database that includes evaluations of both proprietary and open-source LLMs from leading AI developers like OpenAI, Anthropic, Google, Meta, and newer players in the field. It doesn’t stop at mainstream models but also includes specialized and fine-tuned versions, offering users the chance to explore options tailored to unique or niche requirements. This wide-ranging coverage ensures users can access performance data for virtually any model they might consider.
人工分析采用强大的情报基准方法论,旨在跨多个维度评估模型。该平台不依赖单一指标,而是使用加权评分系统来评估推理、准确性、创造力和特定任务的能力。每个模型都使用标准化提示和数据集进行严格测试,并对结果进行标准化,以确保在各种架构和规模之间进行公平比较。自动评分和人工评估的结合增加了这些评估的深度和可靠性。
Keeping up with the rapidly changing LLM landscape, Artificial Analysis frequently updates its methodologies. The most recent update, Version 3.0, was released on 2025年9月2日. These regular updates ensure the platform remains a reliable source of up-to-date, actionable insights, enabling users to make informed decisions when selecting the best language model for their needs.
LMSYS Chatbot Arena 是一个协作平台,旨在通过实时人类反馈评估大型语言模型 (LLM)。这种方法通过捕获用户交互和模型的持续改进来确保评估保持相关性。
该平台拥有多种模型选择,包括专有、开源和实验选项。这允许用户测试和比较不同模型在各种任务和应用程序中的执行情况。
为了最大限度地减少偏差,用户在模型之间进行盲目的成对比较。然后将结果汇总,根据模型的对话质量、原创性和实际用途对模型进行排名。
排行榜根据用户反馈不断更新,确保反映最新的模型版本和性能趋势。
Vellum AI 排行榜提供了针对模型性能的可行见解,专为实际业务应用量身定制。
该排行榜精选了专为企业使用而设计的商业和开源模型。其中包括 OpenAI、Anthropic 和 Google 等提供商的产品,以及 Llama 2 和 Mistral 等开源选项。
Vellum 之所以脱颖而出,是因为它专注于商业就绪模型。它没有列出实验性或未经验证的选项,而是重点介绍了已证明可靠性且适合商业部署的模型。
Vellum 使用结构化方法评估模型,涵盖六个关键类别:推理、代码生成、创意写作、事实准确性、指令遵循和安全合规性。
每个模型都通过模拟真实业务场景的提示进行测试,并将自动评分与人工审核相结合。这种双层评估确保结果反映实际可用性而不仅仅是理论基准。评估流程的定期更新可确保排行榜与法学硕士领域的最新发展保持一致。
排行榜每月刷新一次,并针对主要型号发布进行额外更新。这个时间表确保了彻底的测试,同时跟上大型语言模型的快节奏进步。
Vellum 还跟踪历史性能,使用户能够回顾模型如何随着时间的推移而演变。此功能可帮助企业就何时采用新模型或升级现有模型做出明智的决策。
Vellum 提供详细的成本明细,包括每 1,000 个代币的定价以及客户支持、内容创建和代码协助等任务的估计成本。
LiveBench 通过频繁更新其基准问题来应对数据污染的挑战。这确保了模型在新材料上进行评估,防止它们简单地记住训练数据。
LiveBench 支持多种模型,从具有 5 亿个参数的小型系统到拥有 4050 亿个参数的大型系统。它评估了 49 种不同的大型语言模型 (LLM),包括领先的专有平台、著名的开源替代方案和利基专业模型。
The platform’s robust API compatibility allows seamless evaluation of any model with an OpenAI-compatible endpoint. This includes models from providers like Anthropic, Cohere, Mistral, Together, and Google.
As of 2025年10月9日, the leaderboard showcases advanced models such as OpenAI's GPT-5 series (High, Medium, Pro, Codex, Mini, o3, o4-Mini), Anthropic's Claude Sonnet 4.5 and Claude 4.1 Opus, Google's Gemini 2.5 Pro and Flash, xAI's Grok 4, DeepSeek V3.1, and Alibaba's Qwen 3 Max.
LiveBench 使用抗污染方法,测试 21 个任务的模型,分为七个类别,包括推理、编码、数学和语言理解。为了保持基准的完整性,该平台每六个月刷新一次所有问题,并随着时间的推移引入更复杂的任务。例如,最新版本 LiveBench-2025-05-30 添加了代理编码任务,其中模型必须导航现实世界的开发环境以解决存储库问题。
为了进一步保障评估过程,最近更新的约 300 个问题(约占总数的 30%)仍未发布。这确保模型无法根据确切的测试数据进行训练。这些措施与定期更新相结合,使基准保持相关性和挑战性。
LiveBench 遵循严格的更新计划,不断发布新问题,并每六个月刷新整个基准测试。用户可以通过提交 GitHub 问题或通过电子邮件联系 LiveBench 团队来请求对新开发的模型进行评估。这使得无需等待下一次计划更新即可评估新兴模型。 2024 年 12 月新增的模型包括 claude-3-5-haiku-20241022、claude-3-5-sonnet-20241022、gemini-exp-1114、gpt-4o-2024-11-20、grok-2 和 grok-2-mini 等模型。
LLM-Stats 提供了一种数据驱动的方法,通过分析各种基准的聚合统计数据来比较大型语言模型。虽然它提供了有关模型性能的宝贵见解,但诸如模型如何分类、使用的评估方法、定价详细信息以及数据更新频率等细节尚未共享。这种统计方法可以作为早期定性比较的有用对应物。
OpenRouter Rankings 采用实用的方法来评估语言模型的性能,重点关注模型在现实场景中的表现,而不是仅仅依赖技术基准。通过汇总日常使用的数据,它突出显示了哪些模型在实际应用中真正提供了价值。这种对现实世界指标的重视补充了其他平台提供的更详细的技术评估。
该平台包括各种语言模型,根据其特定应用程序进行组织。通过根据用例对模型进行分类,它可以帮助用户轻松识别符合其特定需求的解决方案。
OpenRouter Rankings uses a usage-based evaluation system, considering multiple factors like response quality, efficiency, and cost. These metrics are combined into composite scores that provide a clear picture of each model’s overall effectiveness and value.
排名会定期更新,以考虑模型性能和使用趋势的变化,确保数据保持相关性和最新性。
该平台的一个重点是经济因素。通过分析定价和成本相关指标,它可以明确成本和性能之间的平衡,帮助用户做出明智的决策。
Hugging Face Open LLM 排行榜作为评估开源语言模型性能的专用平台脱颖而出。它由 Hugging Face 设计,是希望将模型与标准化基准进行比较的研究人员和开发人员的中心资源。通过专注于开源模型,排行榜满足了那些重视人工智能解决方案透明度和开放可访问性的人们的需求。它补充了前面讨论的企业和性能驱动的比较,为开源人工智能领域提供了独特的视角。
该排行榜按参数大小组织了广泛的开源模型 - 7B、13B、30B 和 70B+ - 涵盖领先研究机构的实验设计和大规模实施。
它以组织和个人开发者的贡献为特色,培育了一个多样化、动态的生态系统,反映了开源人工智能的当前状态。每个模型条目都包含有关架构、培训数据和许可条款的详细信息,使用户能够根据其项目需求和合规性要求做出明智的选择。
Hugging Face 使用标准化的评估框架,在多个基准上评估模型,对其功能进行全面分析。这些基准涵盖推理技能、知识保留、数学问题解决和阅读理解,确保全面了解每个模型的性能。
该平台采用自动化管道来保持所有模型的测试条件一致。这消除了由不同环境或方法引起的差异,为用户提供可靠的同类比较,以确定最适合其特定用例的方案。
当开源社区中出现新模型时,排行榜会不断更新。得益于其自动化评估流程,可以快速评估模型并对其进行排名,而不会因人工干预而造成延迟。
此外,只要基准方法得到完善,该平台就会重新评估现有模型。这确保了旧模型保持公平的代表性,随着时间的推移保持排行榜的相关性和可信度。
While the leaderboard doesn’t provide direct pricing, it includes key details such as model size, memory requirements, and inference speed. These metrics help users estimate the infrastructure costs involved in deploying each model.
这种对计算要求的关注使组织能够做出注重预算的决策,尤其是那些资源有限或特定硬件限制的组织。通过强调开源模型,该平台还消除了持续的许可费用,与专有替代方案相比,使总拥有成本更可预测,并且通常更易于管理。
Scale AI SEAL 排行榜致力于评估大型语言模型 (LLM) 的安全性、一致性和性能,解决企业对负责任地部署 AI 的关键问题。与通用排行榜不同,SEAL 专注于评估模型处理敏感内容、遵守道德准则以及在不同场景下保持一致行为的能力。这凸显了安全和道德合规以及企业环境中原始性能的重要性。其专业方法提供了对模型功能、评估方法、更新时间表和相关成本的详细见解。
SEAL 审查专有模型和开源模型的组合,重点关注业务应用程序中常用的模型。排行榜包括 GPT-4、Claude 和 Gemini 等备受瞩目的商业模型,以及 Llama 2 和 Mistral 变体等流行的开源选项。
SEAL 的与众不同之处在于它强调企业就绪模型,而不是实验或以研究为重点的版本。每个模型都经过各种参数大小和微调配置的测试,可以更深入地了解这些变化如何影响安全性和性能之间的平衡。该平台还评估为医疗保健或金融等行业量身定制的专业模型,这些行业的监管合规性和风险管理至关重要。
SEAL 使用全面的评估框架,将传统的性能指标与广泛的安全测试相结合。模型的评估标准是其拒绝有害提示、保持事实准确性以及避免产生有偏见或歧视性输出的能力。
评估过程包括红队练习和人工审查,以发现自动化测试可能忽略的漏洞和微妙偏差。通过结合自动和手动评估,SEAL 确保安全考虑与性能指标同等重要。
海豹突击队排行榜每季度更新一次,反映了其评估的详细性和以安全为中心的性质。每次更新都包含新发布的模型,并根据不断变化的安全基准和标准重新评估现有模型。
除了这些预定的更新之外,当人工智能社区内发生重大模型更新或安全相关事件时,Scale AI 还会发布临时报告。这种自适应方法可确保企业用户能够及时访问最新的安全评估,考虑到模型进步的快速步伐,这一点尤其重要。这些定期更新还为分析部署成本提供了宝贵的数据。
While SEAL doesn’t disclose direct pricing, it offers insights into the total cost of ownership, including factors like content moderation, compliance requirements, and liability risks. This helps enterprises weigh the costs of safety measures against operational expenses.
该平台还提供有关各种安全配置的基础设施需求的指导,帮助组织了解增强安全性和运营成本之间的权衡。对于企业用户,SEAL 估计在部署具有强大的内置安全功能的模型时,通过减少内容审核工作可能节省的成本。
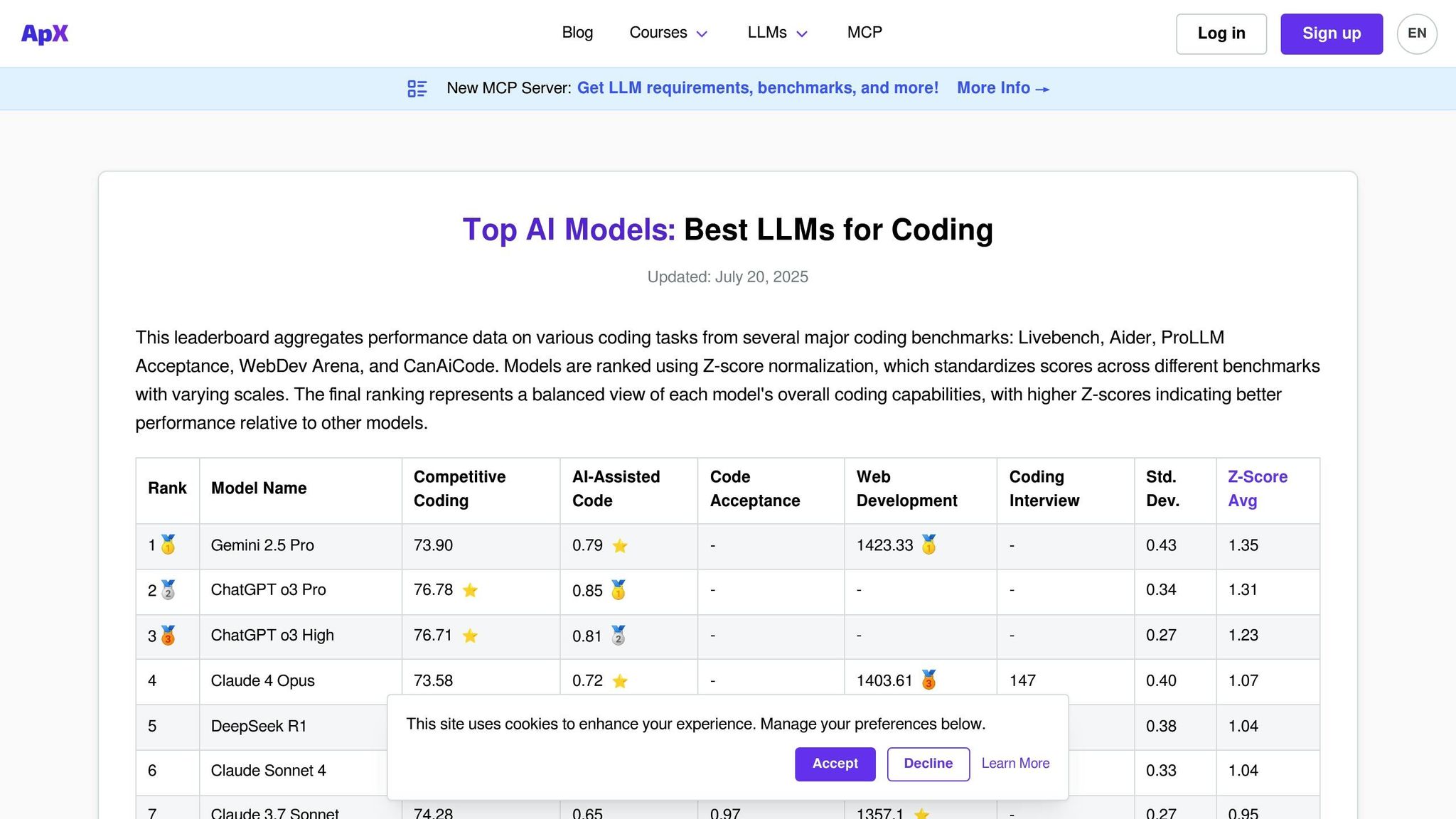
APX Coding LLMs 是专门为评估语言模型的编码能力而设计的平台。与关注广泛的对话技能的通用排行榜不同,APX 专注于代码生成、调试、算法实现和解决技术问题等领域。这一重点使其成为开发人员、工程团队和旨在将人工智能驱动的编码助手集成到其工作流程中的组织的重要工具。
该平台评估模型如何应对各种语言和框架的实际编程挑战。与其他评估平台类似,APX 简化了评估过程,但重点关注代码性能和安全性。
APX 具有广泛的商业和开源模型阵容,经过测试其编码专业知识。该平台定期评估众所周知的编码模型,例如 GitHub Copilot 的底层 GPT 模型、CodeT5、StarCoder 和 Code Llama 变体。它还包括具有强大编程能力的通用模型,如 GPT-4、Claude 和 Gemini。
APX 的一个关键区别在于它包含专门的编码模型,这些模型可能不会出现在更广泛的排行榜上,但在利基编程领域表现出色。这些模型在各种参数大小和微调版本上进行了测试,包括 Python、JavaScript、Java、C++、Rust 和 Go 等语言的特定领域变体。该平台还评估 React、Django、TensorFlow 和 PyTorch 等框架的性能。
这种全面的覆盖范围确保 APX 能够针对现实世界的编码需求提供严格且实用的测试。
APX 采用针对实际编码场景量身定制的详细测试框架。它通过自动化测试和专家评审相结合,从代码正确性、效率、可读性和遵守安全标准等方面评估模型。
测试场景包括算法挑战、调试有缺陷的代码、重构任务和生成文档。还评估模型解释复杂代码概念和建议优化的能力。
Incorporating industry-standard coding practices, APX evaluates whether models follow established conventions for naming, commenting, and structuring code. Additionally, it tests the models’ ability to recognize and avoid common security vulnerabilities, making it especially valuable for enterprises where secure coding is a priority.
APX 排行榜每月更新一次,以跟上 AI 编码工具快速发展的步伐。更新包括添加新发布的模型以及对现有模型的重新评估,以确保符合最新的编程挑战和标准。
该平台还提供重要模型更新的实时性能跟踪,使开发人员能够立即访问最新功能。当主要的以编码为中心的模型推出时,APX 会进行特殊的评估周期,以及时洞察其性能。
APX 提供专为编码任务量身定制的每个代币成本分析的详细细分。此分析可帮助用户了解不同模型对各种用例的成本影响。成本按编程语言和任务复杂性进行细分,从而清楚地了解哪些模型可以提供最佳价值。
成本分析考虑了典型编码任务期间的 API 调用频率、令牌使用模式以及减少调试时间带来的潜在节省等因素。 APX 甚至估算了采用 AI 编码助手的团队的总拥有成本,权衡了生产力提升与订阅和使用费用。这种详细程度使 APX 成为评估人工智能驱动编码解决方案的财务影响的宝贵资源。
大型语言模型 (LLM) 的并排比较平台可满足各种需求。 Prompts.ai 因提供对超过 35 个顶级模型的访问而脱颖而出,并配有用于管理成本和确保治理的集中式工具。这使得它成为需要安全、合规工作流程和强大监督的大型组织的有力选择。
虽然 Prompts.ai 强调成本管理和治理,但其他平台则侧重于不同的优先事项。这些可能包括社区驱动的反馈、技术基准或安全性和一致性等专门指标。这些平台在模型选择、评估方法、更新时间表和定价透明度方面各不相同。
This summary complements earlier in-depth analyses, helping you identify the tools that best fit your goals. Whether your focus is budget, technical depth, or specific use cases, it’s worth noting that many organizations rely on a mix of platforms to achieve a well-rounded understanding of both technical and business needs.
When evaluating platforms for large language model (LLM) comparison, the best choice ultimately hinges on balancing factors like cost, performance, and compliance. The decision should align with your organization’s specific needs, technical capabilities, and workflow demands.
For enterprises seeking a unified AI orchestration solution, Prompts.ai offers a compelling option. With access to over 35 leading LLMs, integrated cost management tools, and enterprise-grade governance controls, it’s designed to simplify operations for organizations overseeing multiple teams and complex projects.
That said, the LLM platform landscape is diverse, and there’s no universal solution that fits every scenario. Many organizations adopt a mix of tools to address both research and production requirements. By focusing on your primary goals - whether it’s reducing costs, enhancing performance, or ensuring compliance - you can refine your platform selection process and streamline AI implementation.
选择正确的编排和比较工具可以使您的人工智能计划取得可衡量的改进,并推动有意义的业务成果。
Prompts.ai 通过对多个大型语言模型 (LLM) 的性能、可扩展性和成本效率提供清晰、可操作的见解,简化了评估多个大型语言模型 (LLM) 的挑战。这使用户能够做出明智的选择,在不超出预算的情况下选择最适合他们需求的型号。
Prompts.ai 借助旨在评估成本与性能以及运营效率之间的平衡的工具,确保企业可以避免不必要的开支,并专注于实施根据其独特需求量身定制的最有效的解决方案。
提供定制大型语言模型 (LLM) 比较工具的平台非常宝贵,因为它们可以让用户微调评估以匹配其独特的目标。通过专注于性能、功能和实际应用等关键方面,这些工具简化了识别最合适模型的过程,减少了猜测。
这些比较工具还提供更详细的基准测试,为研究人员、开发人员和企业等提供宝贵的见解。无论您是为特定任务完善解决方案还是权衡多个选项,这些平台都可以让您更快、更有效地制定决策。
定期更新评估方法和模型数据库对于保持人工智能平台的精度、可靠性和可信度至关重要。这些更新使模型能够通过纳入新数据、适应趋势和解决新用例来保持最新状态,最终提高性能和决策。
方法论的持续改进使平台能够解决偏差、提高模型适应性并满足不断变化的行业标准。这种对进步的奉献精神确保人工智能解决方案保持高效、合规,并能够满足快速变化的环境中的用户需求。



















