사용한 만큼 지불 - AI Model Orchestration and Workflows Platform

혼잡한 AI 환경에서 올바른 LLM(대형 언어 모델)을 선택하는 것은 부담스러울 수 있습니다. GPT-5, Claude 및 Gemini와 같은 모델이 다양한 영역에서 탁월한 성능을 발휘하는 비교 플랫폼은 성능, 비용 및 사용 사례에 대한 병렬 분석을 제공하여 의사 결정 프로세스를 단순화합니다. 당신이 알아야 할 사항은 다음과 같습니다.
이러한 플랫폼은 비용 최적화, 안전 보장, 코딩 기능 평가 등 다양한 요구 사항을 충족합니다. 다음은 결정하는 데 도움이 되는 빠른 비교입니다.
올바른 플랫폼을 선택하는 것은 비용 절감, 안전 규정 준수 보장, 생산성 향상 등 목표에 따라 달라집니다. Prompts.ai와 같은 플랫폼은 여러 LLM을 관리하는 기업에 적합한 반면, APX Coding LLM은 개발자에게 적합합니다. 각 도구는 AI 전략을 안내하는 고유한 관점을 제공합니다.
Prompts.ai는 LLM(대규모 언어 모델)을 비교하고 배포하는 프로세스를 단순화하도록 설계된 엔터프라이즈 AI 플랫폼입니다. 35개 이상의 주요 LLM을 단일 통합 대시보드로 통합함으로써 플랫폼은 여러 도구를 저글링할 필요가 없습니다. 이 간소화된 설정은 복잡성을 줄일 뿐만 아니라 팀이 한 곳에서 성능, 비용 및 통합 속도에 대한 모델을 비교하여 정보에 입각한 결정을 내릴 수 있도록 해줍니다.
Prompts.ai는 GPT-5, Claude, LLaMA, Gemini, Grok-4, Flux Pro 및 Kling을 포함한 광범위한 최첨단 AI 모델에 대한 액세스를 제공합니다. 이 광범위한 라이브러리를 통해 사용자는 플랫폼을 전환하거나 여러 API 키를 관리하는 번거로움 없이 다양한 강점과 전문성을 갖춘 모델을 평가할 수 있습니다.
The platform's ability to aggregate these models ensures users can evaluate them based on real-world applications. Whether it’s testing coding efficiency, creative writing skills, or expertise in specific domains, the side-by-side comparison feature enables simultaneous testing of identical prompts across multiple models.
Prompts.ai는 모델 평가에 대한 사용자 우선 접근 방식을 취하여 일반적인 벤치마크를 뛰어넘는 유연성을 제공합니다. 사용자는 미리 설정된 지표에 의존하는 대신 자신만의 프롬프트와 데이터를 사용하여 고유한 요구 사항에 맞는 개인화된 평가 시나리오를 만들 수 있습니다.
The platform’s interface displays results side by side, offering a clear view of output quality, response times, and methodologies. This approach is especially beneficial for businesses that need to test models against proprietary datasets or industry-specific challenges that standard benchmarks fail to address.
Prompts.ai는 모든 모델에서 토큰 사용을 실시간으로 추적하는 FinOps 레이어를 통합합니다. 토큰 소비를 모니터링함으로써 팀은 성능과 재정적 영향을 직접 비교할 수 있으므로 어떤 모델이 최고의 가치를 제공하는지 더 쉽게 평가할 수 있습니다.
The platform’s Pay-As-You-Go TOKN credit system ensures that costs align with actual usage, potentially reducing expenses by up to 98%. For organizations managing tight budgets or allocating resources across multiple AI projects, this level of cost clarity supports smarter, data-driven decisions.
Prompts.ai keeps its users ahead of the curve by rapidly integrating new models as they become available. Its architecture is built for agility, ensuring emerging models are added quickly, so users don’t face delays in accessing the latest advancements.
새로운 모델 외에도 플랫폼은 업데이트와 최적화를 원활하게 출시합니다. 모델이 개선되고 새 버전이 출시됨에 따라 사용자는 Prompts.ai를 통해 이러한 향상된 기능에 중단 없이 액세스할 수 있으므로 끊임없이 진화하는 AI 환경에서 경쟁력을 유지할 수 있습니다.
인공 분석은 표준화된 벤치마크와 반복 가능한 테스트 프로세스를 통해 LLM(대형 언어 모델)에 대한 일관되고 철저한 평가를 제공하는 데 중점을 둡니다. 체계적인 접근 방식을 고수함으로써 플랫폼은 다양한 인지 작업과 실제 응용 프로그램에서 다양한 LLM이 어떻게 수행되는지에 대한 심층적인 통찰력을 제공합니다.
The platform maintains an extensive database that includes evaluations of both proprietary and open-source LLMs from leading AI developers like OpenAI, Anthropic, Google, Meta, and newer players in the field. It doesn’t stop at mainstream models but also includes specialized and fine-tuned versions, offering users the chance to explore options tailored to unique or niche requirements. This wide-ranging coverage ensures users can access performance data for virtually any model they might consider.
인공 분석은 여러 차원에 걸쳐 모델을 평가하도록 설계된 강력한 인텔리전스 벤치마킹 방법론을 사용합니다. 플랫폼은 단일 지표에 의존하는 대신 추론, 정확성, 창의성 및 작업별 기능을 평가하는 가중치 채점 시스템을 사용합니다. 각 모델은 표준화된 프롬프트와 데이터 세트를 사용하여 엄격하게 테스트되었으며 결과는 다양한 아키텍처와 규모에 걸쳐 공정한 비교를 보장하기 위해 정규화되었습니다. 자동 채점과 사람의 평가를 결합하면 이러한 평가에 깊이와 신뢰성이 더해집니다.
Keeping up with the rapidly changing LLM landscape, Artificial Analysis frequently updates its methodologies. The most recent update, Version 3.0, was released on 2025년 9월 2일. These regular updates ensure the platform remains a reliable source of up-to-date, actionable insights, enabling users to make informed decisions when selecting the best language model for their needs.
LMSYS Chatbot Arena는 실시간 인간 피드백을 통해 LLM(대형 언어 모델)을 평가하도록 설계된 협업 플랫폼입니다. 이 접근 방식을 사용하면 사용자 상호 작용과 모델의 지속적인 개선을 모두 포착하여 평가의 관련성을 유지할 수 있습니다.
이 플랫폼은 독점, 오픈 소스 및 실험적 옵션을 포함한 다양한 모델을 호스팅합니다. 이를 통해 사용자는 다양한 작업과 응용 프로그램에서 다양한 모델의 성능을 테스트하고 비교할 수 있습니다.
편향을 최소화하기 위해 사용자는 모델 간의 맹목적인 쌍별 비교에 참여합니다. 그런 다음 결과를 집계하여 대화 품질, 독창성 및 실제 유용성을 기준으로 모델의 순위를 매깁니다.
리더보드는 사용자 피드백을 통해 지속적으로 업데이트되어 최신 모델 출시 및 성능 추세를 반영합니다.
Vellum AI Leaderboard는 실제 비즈니스 애플리케이션에 맞게 특별히 맞춤화된 모델 성능에 대한 실행 가능한 통찰력을 제공합니다.
리더보드에는 기업용으로 설계된 엄선된 상용 및 오픈 소스 모델이 포함되어 있습니다. 여기에는 Llama 2 및 Mistral과 같은 오픈 소스 옵션과 함께 OpenAI, Anthropic 및 Google과 같은 제공업체의 제품이 포함됩니다.
Vellum이 눈에 띄는 이유는 비즈니스 지원 모델에 중점을 둔 것입니다. 실험적이거나 입증되지 않은 옵션을 나열하는 대신 안정성이 입증되고 상업적 배포에 적합한 모델을 강조합니다.
Vellum은 추론, 코드 생성, 창의적 글쓰기, 사실적 정확성, 지침 따르기, 안전 준수 등 6가지 주요 범주에 걸쳐 구조화된 접근 방식을 사용하여 모델을 평가합니다.
각 모델은 자동화된 채점과 인적 검토를 결합하여 실제 비즈니스 시나리오를 모방하는 프롬프트로 테스트됩니다. 이 이중 계층 평가는 결과가 단지 이론적인 벤치마크가 아닌 실제 유용성을 반영하도록 보장합니다. 평가 프로세스를 정기적으로 업데이트하면 리더보드가 LLM 공간의 최신 개발 내용과 일치하도록 유지됩니다.
리더보드는 주요 모델 출시에 대한 추가 업데이트를 포함하여 매달 새로 고쳐집니다. 이 일정은 대규모 언어 모델의 빠른 발전에 대한 최신 정보를 유지하면서 철저한 테스트를 보장합니다.
또한 Vellum은 과거 성능을 추적하여 사용자가 시간이 지남에 따라 모델이 어떻게 발전했는지 검토할 수 있습니다. 이 기능은 기업이 새 모델을 채택하거나 기존 모델을 업그레이드할 시기를 정보에 기반한 결정을 내리는 데 도움이 됩니다.
Vellum은 1,000개 토큰당 가격 및 고객 지원, 콘텐츠 생성, 코드 지원과 같은 작업에 대한 예상 비용을 포함한 자세한 비용 분석을 제공합니다.
LiveBench는 벤치마크 질문을 자주 업데이트하여 데이터 오염 문제를 해결합니다. 이를 통해 모델이 새로운 자료로 평가되므로 단순히 훈련 데이터를 기억하는 것을 방지할 수 있습니다.
LiveBench는 5억 개의 매개변수를 가진 소형 시스템부터 4,050억 개의 매개변수를 자랑하는 대규모 시스템까지 다양한 모델을 지원합니다. 선도적인 독점 플랫폼, 주요 오픈 소스 대안 및 틈새 특화 모델을 포함하여 49개의 다양한 LLM(대형 언어 모델)을 평가했습니다.
The platform’s robust API compatibility allows seamless evaluation of any model with an OpenAI-compatible endpoint. This includes models from providers like Anthropic, Cohere, Mistral, Together, and Google.
As of 2025년 10월 9일, the leaderboard showcases advanced models such as OpenAI's GPT-5 series (High, Medium, Pro, Codex, Mini, o3, o4-Mini), Anthropic's Claude Sonnet 4.5 and Claude 4.1 Opus, Google's Gemini 2.5 Pro and Flash, xAI's Grok 4, DeepSeek V3.1, and Alibaba's Qwen 3 Max.
LiveBench는 오염 방지 방법론을 사용하여 추론, 코딩, 수학, 언어 이해 등 7개 범주로 분류된 21개 작업에 대한 모델을 테스트합니다. 벤치마크의 무결성을 유지하기 위해 플랫폼은 6개월마다 모든 질문을 새로 고치고 시간이 지남에 따라 더 복잡한 작업을 도입합니다. 예를 들어 최신 버전인 LiveBench-2025-05-30에는 모델이 저장소 문제를 해결하기 위해 실제 개발 환경을 탐색해야 하는 에이전트 코딩 작업이 추가되었습니다.
평가 프로세스를 더욱 안전하게 보호하기 위해 최근 업데이트의 약 300개 질문(전체 질문의 약 30%)이 게시되지 않은 상태로 남아 있습니다. 이렇게 하면 모델이 정확한 테스트 데이터에 대해 훈련될 수 없습니다. 정기적인 업데이트와 결합된 이러한 조치는 벤치마크의 관련성과 도전성을 유지합니다.
LiveBench는 엄격한 업데이트 일정을 따르며, 지속적으로 새로운 질문을 발표하고 6개월마다 전체 벤치마크를 새로 고칩니다. 사용자는 GitHub 문제를 제출하거나 이메일을 통해 LiveBench 팀에 연락하여 새로 개발된 모델에 대한 평가를 요청할 수 있습니다. 이를 통해 다음 예정된 업데이트를 기다리지 않고 새로운 모델을 평가할 수 있습니다. 2024년 12월에 최근 추가된 모델에는 clude-3-5-haiku-20241022, claude-3-5-sonnet-20241022, gemini-exp-1114, gpt-4o-2024-11-20, grok-2 및 grok-2-mini와 같은 모델이 포함됩니다.
LLM-Stats는 다양한 벤치마크에서 집계된 통계를 분석하여 대규모 언어 모델을 비교하는 데이터 기반 방법을 제공합니다. 모델 성능에 대한 귀중한 통찰력을 제공하지만 모델 분류 방법, 사용된 평가 방법, 가격 세부 정보 및 데이터 업데이트 빈도와 같은 세부 사항은 공유되지 않았습니다. 이 통계적 접근 방식은 이전의 정성적 비교에 대한 유용한 대응 역할을 합니다.
OpenRouter Rankings는 기술 벤치마크에만 의존하기보다는 실제 시나리오에서 모델이 어떻게 작동하는지에 초점을 맞춰 언어 모델 성능을 평가하는 실용적인 접근 방식을 취합니다. 일상적인 사용에서 수집된 데이터를 통해 어떤 모델이 실제 응용 분야에서 실제로 가치를 제공하는지 강조합니다. 실제 측정항목에 대한 이러한 강조는 다른 플랫폼에서 제공하는 보다 자세한 기술 평가를 보완합니다.
플랫폼에는 특정 애플리케이션을 기반으로 구성된 다양한 언어 모델이 포함되어 있습니다. 사용 사례에 따라 모델을 분류함으로써 사용자가 특정 요구 사항에 맞는 솔루션을 쉽게 식별하는 데 도움이 됩니다.
OpenRouter Rankings uses a usage-based evaluation system, considering multiple factors like response quality, efficiency, and cost. These metrics are combined into composite scores that provide a clear picture of each model’s overall effectiveness and value.
순위는 모델 성능 및 사용 추세의 변화를 고려하여 정기적으로 업데이트되므로 데이터가 관련성과 최신 상태로 유지됩니다.
플랫폼의 주요 초점은 경제적 요인에 있습니다. 가격 및 비용 관련 지표를 분석함으로써 비용과 성능 간의 균형을 명확하게 제공하여 사용자가 정보에 입각한 결정을 내릴 수 있도록 돕습니다.
Hugging Face Open LLM Leaderboard는 오픈 소스 언어 모델의 성능을 평가하기 위한 전용 플랫폼입니다. Hugging Face가 설계한 이 제품은 표준화된 벤치마크와 모델을 비교하려는 연구원 및 개발자를 위한 중앙 리소스 역할을 합니다. 오픈 소스 모델에만 집중함으로써 리더보드는 AI 솔루션의 투명성과 개방형 접근성을 중시하는 사람들의 요구 사항에 부합합니다. 앞서 설명한 엔터프라이즈 및 성능 중심 비교를 보완하여 오픈 소스 AI 환경에 대한 고유한 관점을 제공합니다.
리더보드는 주요 연구 기관의 실험 설계와 대규모 구현을 모두 포괄하는 매개변수 크기(7B, 13B, 30B, 70B+)별로 광범위한 오픈 소스 모델을 구성합니다.
이는 조직과 개인 개발자의 기여를 특징으로 하며 오픈 소스 AI의 현재 상태를 반영하는 다양하고 역동적인 생태계를 육성합니다. 각 모델 항목에는 아키텍처, 교육 데이터 및 라이센스 조건에 대한 자세한 정보가 포함되어 있어 사용자가 프로젝트 요구 사항 및 규정 준수 요구 사항에 따라 정보를 바탕으로 선택할 수 있습니다.
Hugging Face는 표준화된 평가 프레임워크를 사용하여 여러 벤치마크에서 모델을 평가하고 해당 기능에 대한 철저한 분석을 제공합니다. 이러한 벤치마크에서는 추론 기술, 지식 보유, 수학적 문제 해결 및 독해력을 다루며 각 모델의 성능에 대한 균형 잡힌 관점을 보장합니다.
플랫폼은 자동화된 파이프라인을 사용하여 모든 모델에 걸쳐 일관된 테스트 조건을 유지합니다. 이는 다양한 환경이나 방법론으로 인해 발생하는 불일치를 제거하여 사용자에게 신뢰할 수 있는 비교를 제공하여 특정 사용 사례에 가장 적합한 것을 식별합니다.
리더보드는 오픈 소스 커뮤니티에 등장하는 새로운 모델로 지속적으로 업데이트됩니다. 자동화된 평가 프로세스 덕분에 수동 개입으로 인한 지연 없이 신속하게 모델을 평가하고 순위를 매길 수 있습니다.
또한 플랫폼은 벤치마크 방법론이 개선될 때마다 기존 모델을 재평가합니다. 이를 통해 이전 모델이 공정하게 대표되어 시간이 지나도 순위표의 관련성과 신뢰성이 유지됩니다.
While the leaderboard doesn’t provide direct pricing, it includes key details such as model size, memory requirements, and inference speed. These metrics help users estimate the infrastructure costs involved in deploying each model.
컴퓨팅 요구 사항에 중점을 두어 조직은 예산에 민감한 결정을 내릴 수 있으며, 특히 제한된 리소스나 특정 하드웨어 제약 조건을 사용하는 조직에서는 더욱 그렇습니다. 오픈 소스 모델을 강조함으로써 플랫폼은 지속적인 라이센스 비용을 없애고 독점 대안에 비해 총 소유 비용을 더 예측 가능하게 만들고 관리하기 쉽게 만듭니다.
Scale AI SEAL 리더보드는 대규모 언어 모델(LLM)의 안전성, 정렬 및 성능을 평가하고 AI를 책임감 있게 배포하는 데 대한 기업의 주요 우려 사항을 해결하는 데 전념하고 있습니다. 범용 순위표와 달리 SEAL은 모델이 민감한 콘텐츠를 얼마나 잘 처리하고 윤리 지침을 준수하며 다양한 시나리오에서 일관된 동작을 유지하는지 평가하는 데 중점을 둡니다. 이는 기업 환경에서 기본적인 성과와 함께 안전 및 윤리 준수의 중요성을 강조합니다. 전문적인 접근 방식은 모델 기능, 평가 방법, 업데이트 일정 및 관련 비용에 대한 자세한 통찰력을 제공합니다.
SEAL은 비즈니스 애플리케이션에서 일반적으로 사용되는 모델에 중점을 두고 독점 모델과 오픈 소스 모델의 혼합을 검토합니다. 리더보드에는 GPT-4, Claude 및 Gemini와 같은 유명 상용 모델뿐만 아니라 Llama 2 및 Mistral 변종과 같은 인기 있는 오픈 소스 옵션도 포함되어 있습니다.
SEAL의 차별점은 실험적이거나 연구 중심 버전이 아닌 기업용 모델에 중점을 둔다는 것입니다. 각 모델은 다양한 매개변수 크기와 미세 조정된 구성에 걸쳐 테스트되어 이러한 변형이 안전과 성능 간의 균형에 어떤 영향을 미치는지 더 깊이 이해할 수 있습니다. 또한 이 플랫폼은 규제 준수 및 위험 관리가 중요한 의료 또는 금융과 같은 산업에 맞춰진 전문 모델을 평가합니다.
SEAL은 전통적인 성능 지표와 광범위한 안전 테스트를 혼합한 철저한 평가 프레임워크를 사용합니다. 모델은 유해한 메시지를 거부하고, 사실적 정확성을 유지하고, 편향되거나 차별적인 출력을 생성하지 않는 능력을 평가합니다.
평가 프로세스에는 자동화된 테스트에서 간과할 수 있는 취약성과 미묘한 편견을 찾아내기 위한 레드팀 구성 연습과 인적 검토가 포함됩니다. SEAL은 자동 평가와 수동 평가를 결합하여 안전 고려 사항이 성능 지표와 동일한 비중을 갖도록 보장합니다.
SEAL 순위표는 세부적이고 안전 중심의 평가 특성을 반영하여 분기별로 업데이트됩니다. 각 업데이트에는 새로 출시된 모델이 통합되어 있으며 발전하는 안전 벤치마크 및 표준을 기준으로 기존 모델을 재평가합니다.
이러한 예정된 업데이트 외에도 Scale AI는 AI 커뮤니티 내에서 중요한 모델 업데이트 또는 안전 관련 사고가 발생할 때 중간 보고서를 발표합니다. 이러한 적응형 접근 방식을 통해 기업 사용자는 최신 안전 평가에 적시에 액세스할 수 있으며, 이는 빠른 모델 발전 속도를 고려할 때 특히 중요합니다. 이러한 정기 업데이트는 배포 비용을 분석하는 데 유용한 데이터도 제공합니다.
While SEAL doesn’t disclose direct pricing, it offers insights into the total cost of ownership, including factors like content moderation, compliance requirements, and liability risks. This helps enterprises weigh the costs of safety measures against operational expenses.
또한 이 플랫폼은 다양한 안전 구성을 위한 인프라 요구 사항에 대한 지침을 제공하여 조직이 향상된 안전과 운영 비용 간의 균형을 이해하는 데 도움을 줍니다. 기업 사용자의 경우 SEAL은 강력한 안전 기능이 내장된 모델을 배포할 때 콘텐츠 조정 노력을 줄여 잠재적인 절감 효과를 추정합니다.
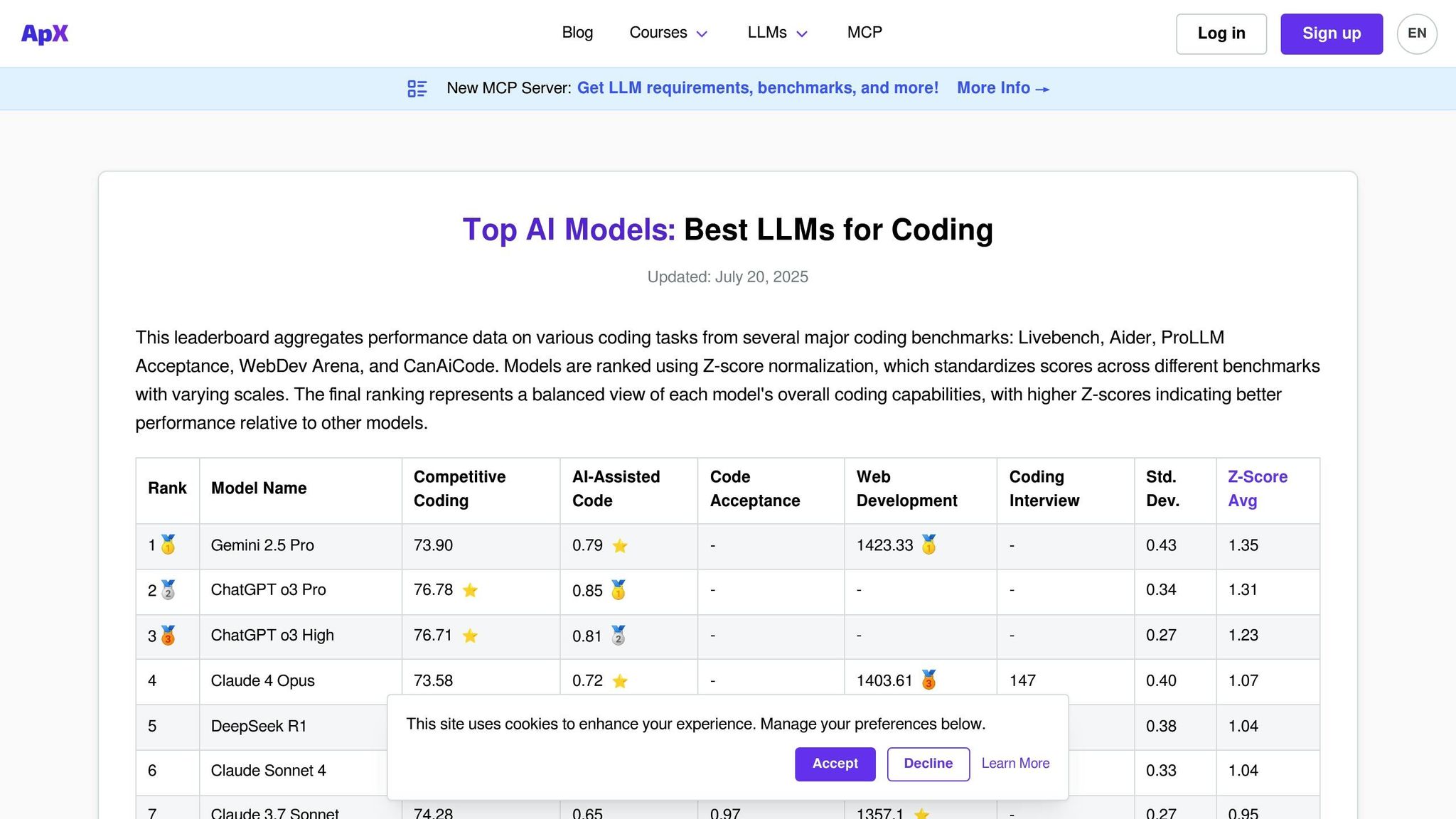
APX Coding LLM은 언어 모델의 코딩 기능을 평가하기 위해 특별히 설계된 플랫폼입니다. 광범위한 대화 기술에 초점을 맞춘 범용 순위표와 달리 APX는 코드 생성, 디버깅, 알고리즘 구현 및 기술 문제 해결과 같은 영역에 중점을 둡니다. 이러한 초점으로 인해 AI 기반 코딩 도우미를 워크플로에 통합하려는 개발자, 엔지니어링 팀 및 조직에 필수적인 도구가 되었습니다.
이 플랫폼은 모델이 다양한 언어와 프레임워크에서 실제 프로그래밍 문제를 어떻게 처리하는지 평가합니다. 다른 평가 플랫폼과 유사하게 APX는 평가 프로세스를 단순화하지만 코드 성능과 보안에 중점을 둡니다.
APX는 코딩 전문성을 테스트한 상용 및 오픈 소스 모델의 광범위한 라인업을 갖추고 있습니다. 이 플랫폼은 GitHub Copilot의 기본 GPT 모델, CodeT5, StarCoder 및 Code Llama 변형과 같은 잘 알려진 코딩 모델을 정기적으로 평가합니다. 또한 GPT-4, Claude 및 Gemini와 같은 강력한 프로그래밍 기능을 갖춘 범용 모델도 포함됩니다.
APX의 주요 차별화 요소는 더 넓은 순위표에는 나타나지 않지만 틈새 프로그래밍 영역에서는 뛰어난 특수 코딩 모델이 포함되어 있다는 것입니다. 이러한 모델은 Python, JavaScript, Java, C++, Rust 및 Go와 같은 언어에 대한 도메인별 변형을 포함하여 다양한 매개변수 크기와 미세 조정된 버전에서 테스트되었습니다. 플랫폼은 또한 React, Django, TensorFlow 및 PyTorch와 같은 프레임워크를 사용하여 성능을 평가합니다.
이러한 포괄적인 범위를 통해 APX는 실제 코딩 요구 사항에 대한 엄격하고 실용적인 테스트를 제공합니다.
APX는 실제 코딩 시나리오에 맞춰진 상세한 테스트 프레임워크를 사용합니다. 자동화된 테스트와 전문가 검토를 결합하여 코드 정확성, 효율성, 가독성 및 보안 표준 준수와 같은 측면에서 모델을 평가합니다.
테스트 시나리오에는 알고리즘 문제, 결함이 있는 코드 디버깅, 작업 리팩터링 및 문서 생성이 포함됩니다. 모델은 복잡한 코드 개념을 설명하고 최적화를 제안하는 능력도 평가됩니다.
Incorporating industry-standard coding practices, APX evaluates whether models follow established conventions for naming, commenting, and structuring code. Additionally, it tests the models’ ability to recognize and avoid common security vulnerabilities, making it especially valuable for enterprises where secure coding is a priority.
APX 리더보드는 빠르게 진화하는 AI 코딩 도구 환경에 맞춰 매월 업데이트됩니다. 업데이트에는 새로 출시된 모델의 추가와 기존 모델의 재평가가 포함되어 최신 프로그래밍 문제 및 표준에 부합하도록 보장합니다.
또한 이 플랫폼은 중요한 모델 업데이트에 대한 실시간 성능 추적을 제공하여 개발자가 최신 기능에 즉시 액세스할 수 있도록 합니다. 주요 코딩 중심 모델이 출시되면 APX는 성능에 대한 시기적절한 통찰력을 제공하기 위해 특별한 평가 주기를 수행합니다.
APX는 코딩 작업에 맞게 특별히 맞춤화된 토큰당 비용 분석에 대한 자세한 분석을 제공합니다. 이 분석은 사용자가 다양한 사용 사례에 대해 다양한 모델의 비용 영향을 이해하는 데 도움이 됩니다. 비용은 프로그래밍 언어와 작업 복잡성에 따라 분류되어 어떤 모델이 최고의 가치를 제공하는지에 대한 명확한 통찰력을 제공합니다.
비용 분석에서는 일반적인 코딩 작업 중 API 호출 빈도, 토큰 사용 패턴, 디버깅 시간 단축으로 인한 잠재적 절감 효과 등의 요소를 고려합니다. APX는 AI 코딩 도우미를 채택한 팀의 총 소유 비용을 추정하여 구독 및 사용 비용 대비 생산성 향상을 평가합니다. 이러한 세부 수준으로 인해 APX는 AI 기반 코딩 솔루션의 재정적 영향을 평가하는 데 유용한 리소스가 됩니다.
LLM(대형 언어 모델)을 위한 병렬 비교 플랫폼은 다양한 요구 사항을 충족합니다. Prompts.ai는 비용 관리 및 거버넌스 보장을 위한 중앙 집중식 도구와 함께 35개 이상의 최상위 모델에 대한 액세스를 제공한다는 점에서 두각을 나타냅니다. 따라서 강력한 감독과 함께 안전하고 규정을 준수하는 워크플로가 필요한 대규모 조직에 강력한 선택이 됩니다.
Prompts.ai는 비용 관리와 거버넌스를 강조하지만 다른 플랫폼은 다양한 우선순위에 중점을 둡니다. 여기에는 커뮤니티 중심 피드백, 기술 벤치마크 또는 안전 및 조정과 같은 전문 측정항목이 포함될 수 있습니다. 이러한 플랫폼은 모델 선택, 평가 방법, 업데이트 일정 및 가격 투명성이 다양합니다.
This summary complements earlier in-depth analyses, helping you identify the tools that best fit your goals. Whether your focus is budget, technical depth, or specific use cases, it’s worth noting that many organizations rely on a mix of platforms to achieve a well-rounded understanding of both technical and business needs.
When evaluating platforms for large language model (LLM) comparison, the best choice ultimately hinges on balancing factors like cost, performance, and compliance. The decision should align with your organization’s specific needs, technical capabilities, and workflow demands.
For enterprises seeking a unified AI orchestration solution, Prompts.ai offers a compelling option. With access to over 35 leading LLMs, integrated cost management tools, and enterprise-grade governance controls, it’s designed to simplify operations for organizations overseeing multiple teams and complex projects.
That said, the LLM platform landscape is diverse, and there’s no universal solution that fits every scenario. Many organizations adopt a mix of tools to address both research and production requirements. By focusing on your primary goals - whether it’s reducing costs, enhancing performance, or ensuring compliance - you can refine your platform selection process and streamline AI implementation.
올바른 조정 및 비교 도구를 선택하면 AI 이니셔티브가 눈에 띄게 개선되고 의미 있는 비즈니스 결과를 얻을 수 있습니다.
Prompts.ai는 성능, 확장성 및 비용 효율성에 대한 명확하고 실행 가능한 통찰력을 제공하여 여러 LLM(대형 언어 모델)을 평가하는 과제를 단순화합니다. 이를 통해 사용자는 예산 내에서 자신의 필요에 가장 적합한 모델을 선택하여 정보에 입각한 선택을 할 수 있습니다.
Prompts.ai는 비용과 성능 간의 균형과 운영 효율성을 평가하도록 설계된 도구를 통해 기업이 불필요한 비용을 피하고 고유한 요구 사항에 맞는 가장 효과적인 솔루션 구현에 집중할 수 있도록 보장합니다.
LLM(대형 언어 모델)에 대한 비교를 사용자 정의하는 도구를 제공하는 플랫폼은 사용자가 고유한 목표에 맞게 평가를 미세 조정할 수 있기 때문에 매우 중요합니다. 성능, 기능, 실제 적용과 같은 중요한 측면을 집중적으로 분석함으로써 이러한 도구는 가장 적합한 모델을 식별하는 프로세스를 단순화하고 추측을 줄입니다.
또한 이러한 비교 도구는 보다 자세한 벤치마킹을 제공하여 연구원, 개발자 및 기업 모두에게 귀중한 통찰력을 제공합니다. 특정 작업을 위한 솔루션을 개선하든 여러 옵션을 고려하든 이러한 플랫폼을 사용하면 더 빠르고 효과적인 의사 결정을 내릴 수 있습니다.
AI 플랫폼의 정확성, 신뢰성, 신뢰성을 유지하려면 평가 방법과 모델 데이터베이스를 정기적으로 업데이트하는 것이 필수적입니다. 이러한 업데이트를 통해 최신 데이터를 통합하고 추세에 적응하며 새로운 사용 사례를 해결함으로써 모델이 최신 상태를 유지하고 궁극적으로 성능과 의사 결정이 향상됩니다.
방법론의 일관된 개선을 통해 플랫폼은 편견을 해결하고 모델 적응성을 향상하며 변화하는 업계 표준을 충족할 수 있습니다. 발전을 위한 이러한 헌신을 통해 AI 솔루션은 효율적이고 규정을 준수하며 빠르게 변화하는 환경에서 사용자 요구 사항을 충족할 수 있습니다.



















