従量課金制 - AI Model Orchestration and Workflows Platform

混雑した AI 環境では、適切なラージ言語モデル (LLM) を選択するのは困難な場合があります。 GPT-5、Claude、Gemini などのモデルがさまざまな分野で優れているため、比較プラットフォームはパフォーマンス、コスト、ユースケースの並列分析を提供することで意思決定プロセスを簡素化します。知っておくべきことは次のとおりです。
これらのプラットフォームは、コストの最適化、安全性の確保、コーディング機能の評価など、さまざまなニーズに対応します。以下に、決定に役立つ簡単な比較を示します。
適切なプラットフォームの選択は、コストの削減、安全コンプライアンスの確保、生産性の向上などの目標によって異なります。 Prompts.ai のようなプラットフォームは複数の LLM を管理する企業に最適ですが、APX コーディング LLM は開発者に最適です。各ツールは、AI 戦略を導くための独自の視点を提供します。
Prompts.ai は、大規模言語モデル (LLM) の比較およびデプロイのプロセスを簡素化するように設計されたエンタープライズ AI プラットフォームです。このプラットフォームでは、35 を超える主要な LLM を単一の統合ダッシュボードに統合することで、複数のツールを使いこなす必要がなくなります。この合理化されたセットアップにより、複雑さが軽減されるだけでなく、チームはパフォーマンス、コスト、統合速度に関するモデルをすべて 1 か所で比較することで、十分な情報に基づいた意思決定を行うことができます。
Prompts.ai は、GPT-5、Claude、LLaMA、Gemini、Grok-4、Flux Pro、Kling など、幅広い最先端の AI モデルへのアクセスを提供します。この広範なライブラリを使用すると、ユーザーはプラットフォームを切り替えたり、複数の API キーを管理したりする手間をかけずに、さまざまな強みや専門性を持つモデルを評価できます。
The platform's ability to aggregate these models ensures users can evaluate them based on real-world applications. Whether it’s testing coding efficiency, creative writing skills, or expertise in specific domains, the side-by-side comparison feature enables simultaneous testing of identical prompts across multiple models.
Prompts.ai はモデル評価にユーザー第一のアプローチを採用し、一般的なベンチマークを超える柔軟性を提供します。ユーザーは、事前に設定された指標に依存する代わりに、独自のプロンプトとデータを使用して、独自のニーズに合わせたパーソナライズされた評価シナリオを作成できます。
The platform’s interface displays results side by side, offering a clear view of output quality, response times, and methodologies. This approach is especially beneficial for businesses that need to test models against proprietary datasets or industry-specific challenges that standard benchmarks fail to address.
Prompts.ai は、すべてのモデルにわたるトークン使用量のリアルタイム追跡を提供する FinOps レイヤーを統合します。トークンの消費を監視することで、チームはパフォーマンスと財務上の影響を直接比較できるため、どのモデルが最高の価値を提供するかを評価しやすくなります。
The platform’s Pay-As-You-Go TOKN credit system ensures that costs align with actual usage, potentially reducing expenses by up to 98%. For organizations managing tight budgets or allocating resources across multiple AI projects, this level of cost clarity supports smarter, data-driven decisions.
Prompts.ai keeps its users ahead of the curve by rapidly integrating new models as they become available. Its architecture is built for agility, ensuring emerging models are added quickly, so users don’t face delays in accessing the latest advancements.
このプラットフォームは、新しいモデルだけでなく、アップデートや最適化もシームレスに展開します。モデルが改良され、新しいバージョンがリリースされると、ユーザーは Prompts.ai を利用してこれらの機能強化への中断のないアクセスを提供し、進化し続ける AI 環境で競争力を維持できるようになります。
Artificial Analysis は、標準化されたベンチマークと反復可能なテスト プロセスを通じて、大規模言語モデル (LLM) の一貫した徹底的な評価を提供することに重点を置いています。このプラットフォームは、体系的なアプローチに従うことで、さまざまな認知タスクや実際のアプリケーションにわたってさまざまな LLM がどのように実行されるかについての深い洞察を提供します。
The platform maintains an extensive database that includes evaluations of both proprietary and open-source LLMs from leading AI developers like OpenAI, Anthropic, Google, Meta, and newer players in the field. It doesn’t stop at mainstream models but also includes specialized and fine-tuned versions, offering users the chance to explore options tailored to unique or niche requirements. This wide-ranging coverage ensures users can access performance data for virtually any model they might consider.
Artificial Analysis は、複数の次元にわたってモデルを評価するように設計された堅牢なインテリジェンス ベンチマーク手法を採用しています。このプラットフォームは、単一の指標に依存するのではなく、推論、正確さ、創造性、タスク固有の能力を評価する加重スコアリング システムを使用します。各モデルは標準化されたプロンプトとデータセットを使用して厳密にテストされ、結果はさまざまなアーキテクチャとサイズにわたって公平に比較できるように正規化されます。自動スコアリングと人間による評価を組み合わせることで、これらの評価に深みと信頼性が加わります。
Keeping up with the rapidly changing LLM landscape, Artificial Analysis frequently updates its methodologies. The most recent update, Version 3.0, was released on 2025年9月2日. These regular updates ensure the platform remains a reliable source of up-to-date, actionable insights, enabling users to make informed decisions when selecting the best language model for their needs.
LMSYS Chatbot Arena は、人間によるリアルタイムのフィードバックを通じて大規模言語モデル (LLM) を評価するように設計された共同プラットフォームです。このアプローチでは、ユーザーの対話とモデルの継続的な改善の両方を捕捉することで、評価の関連性を維持します。
このプラットフォームは、独自のオプション、オープンソース、実験的なオプションなど、さまざまなモデルをホストします。これにより、ユーザーはさまざまなモデルがさまざまなタスクやアプリケーションでどのように動作するかをテストおよび比較できます。
バイアスを最小限に抑えるために、ユーザーはモデル間のブラインドペア比較を行います。次に結果が集計され、会話の品質、独創性、実用的な有用性に基づいてモデルがランク付けされます。
リーダーボードはユーザーのフィードバックによって継続的に更新され、最新のモデルのリリースとパフォーマンスの傾向が確実に反映されます。
Vellum AI Leaderboard は、実際のビジネス アプリケーション向けに特別に調整された、モデルのパフォーマンスに関する実用的な洞察を提供します。
リーダーボードには、企業向けに設計された商用およびオープンソース モデルが厳選されています。これらには、OpenAI、Anthropic、Google などのプロバイダーの製品に加え、Llama 2 や Mistral などのオープンソース オプションが含まれます。
Vellum が際立っているのは、ビジネス対応モデルに焦点を当てていることです。実験的なオプションや実証されていないオプションをリストする代わりに、信頼性が実証され、商用展開に適したモデルを強調しています。
Vellum は、推論、コード生成、クリエイティブ ライティング、事実の正確さ、指示への準拠、安全性への準拠という 6 つの主要なカテゴリにわたる構造化アプローチを使用してモデルを評価します。
各モデルは、自動スコアリングと人間によるレビューを組み合わせて、実際のビジネス シナリオを模倣したプロンプトでテストされます。この二重層の評価により、結果が単なる理論上のベンチマークではなく、実際の使いやすさを反映していることが保証されます。評価プロセスを定期的に更新することで、リーダーボードが LLM 分野の最新の開発状況と常に一致するようになります。
リーダーボードは毎月更新され、メジャー モデル リリースの追加アップデートが行われます。このスケジュールにより、大規模な言語モデルの急速な進歩を常に最新の状態に保ちながら、徹底的なテストが保証されます。
Vellum は過去のパフォーマンスも追跡するため、ユーザーはモデルが時間の経過とともにどのように進化したかを確認できます。この機能は、企業が新しいモデルをいつ採用するか、既存のモデルをアップグレードするかについて情報に基づいた決定を下すのに役立ちます。
Vellum は、1,000 トークンあたりの価格や、カスタマー サポート、コンテンツ作成、コード支援などのタスクの推定コストを含む、詳細なコストの内訳を提供します。
LiveBench は、ベンチマークの質問を頻繁に更新することで、データ汚染の課題に取り組んでいます。これにより、モデルが新鮮な素材で評価されるようになり、トレーニング データを単純に記憶することがなくなります。
LiveBench は、5 億のパラメータを備えた小規模なシステムから 4,050 億のパラメータを誇る大規模なシステムまで、幅広いモデルをサポートしています。主要な独自プラットフォーム、著名なオープンソース代替モデル、ニッチな特化モデルなど、49 の異なる大規模言語モデル (LLM) を評価しました。
The platform’s robust API compatibility allows seamless evaluation of any model with an OpenAI-compatible endpoint. This includes models from providers like Anthropic, Cohere, Mistral, Together, and Google.
As of 2025年10月9日, the leaderboard showcases advanced models such as OpenAI's GPT-5 series (High, Medium, Pro, Codex, Mini, o3, o4-Mini), Anthropic's Claude Sonnet 4.5 and Claude 4.1 Opus, Google's Gemini 2.5 Pro and Flash, xAI's Grok 4, DeepSeek V3.1, and Alibaba's Qwen 3 Max.
LiveBench は汚染耐性のある手法を使用し、推論、コーディング、数学、言語理解など 7 つのカテゴリに分類された 21 のタスクにわたってモデルをテストします。ベンチマークの整合性を維持するために、プラットフォームはすべての質問を 6 か月ごとに更新し、時間の経過とともにより複雑なタスクを導入します。たとえば、最新バージョンの LiveBench-2025-05-30 では、リポジトリの問題を解決するためにモデルが実際の開発環境をナビゲートする必要があるエージェント コーディング タスクが追加されました。
評価プロセスをさらに保護するために、最近の更新からの約 300 の質問 (全体の約 30%) が未公開のままになっています。これにより、モデルを正確なテスト データでトレーニングすることができなくなります。これらの対策と定期的な更新を組み合わせることで、ベンチマークの関連性と挑戦性を維持できます。
LiveBench は厳密な更新スケジュールに従い、新しい質問を継続的にリリースし、6 か月ごとにベンチマーク全体を更新します。ユーザーは、GitHub の問題を送信するか、電子メールで LiveBench チームに連絡することで、新しく開発されたモデルの評価をリクエストできます。これにより、次に予定されているアップデートを待たずに、新しいモデルを評価できるようになります。 2024 年 12 月からの最近の追加には、claude-3-5-haiku-20241022、claude-3-5-sonnet-20241022、gemini-exp-1114、gpt-4o-2024-11-20、grok-2、grok-2-mini などのモデルが含まれます。
LLM-Stats は、さまざまなベンチマークからの集計統計を分析することで、大規模な言語モデルを比較するデータ駆動型の方法を提供します。これはモデルのパフォーマンスに関する貴重な洞察を提供しますが、モデルの分類方法、使用される評価方法、価格設定の詳細、データの更新頻度などの詳細は共有されていません。この統計的アプローチは、以前の定性的比較に相当する有用な手段として機能します。
OpenRouter ランキングは、言語モデルのパフォーマンスを評価するための実践的なアプローチを採用しており、技術的なベンチマークのみに依存するのではなく、現実のシナリオでモデルがどのように機能するかに焦点を当てています。日常的な使用からのデータを集約することにより、どのモデルが実際のアプリケーションで真に価値を提供するかを明らかにします。現実世界の指標に重点を置くことで、他のプラットフォームによって提供されるより詳細な技術評価が補完されます。
このプラットフォームには、特定のアプリケーションに基づいて編成されたさまざまな言語モデルが含まれています。ユースケースに応じてモデルを分類することで、ユーザーが特定のニーズに合ったソリューションを簡単に特定できるようになります。
OpenRouter Rankings uses a usage-based evaluation system, considering multiple factors like response quality, efficiency, and cost. These metrics are combined into composite scores that provide a clear picture of each model’s overall effectiveness and value.
ランキングはモデルのパフォーマンスと使用傾向の変化を考慮して定期的に更新され、データの関連性と最新性が確保されます。
このプラットフォームの主な焦点は経済的要因です。価格設定とコスト関連の指標を分析することで、コストとパフォーマンスのバランスが明確になり、ユーザーが情報に基づいた意思決定を行えるようになります。
Hugging Face Open LLM Leaderboard は、オープンソース言語モデルのパフォーマンスを評価するための専用プラットフォームとして際立っています。 Hugging Face によって設計されたこのツールは、モデルを標準化されたベンチマークと比較したいと考えている研究者や開発者にとって中心的なリソースとして機能します。オープンソース モデルのみに焦点を当てることで、リーダーボードは AI ソリューションの透明性とオープン アクセシビリティを重視する人々のニーズに適合します。これは、前に説明したエンタープライズとパフォーマンス主導の比較を補完し、オープンソース AI 環境に関する独自の視点を提供します。
リーダーボードでは、実験計画と主要な研究機関による大規模実装の両方に及ぶ、7B、13B、30B、70B+ のパラメータ サイズごとに幅広いオープンソース モデルが整理されています。
組織や個人の開発者からの貢献が特徴で、オープンソース AI の現状を反映する多様で動的なエコシステムを促進します。各モデル エントリには、アーキテクチャ、トレーニング データ、ライセンス条件に関する詳細情報が含まれており、ユーザーはプロジェクトのニーズとコンプライアンス要件に基づいて情報に基づいた選択を行うことができます。
標準化された評価フレームワークを使用して、Hugging Face は複数のベンチマークでモデルを評価し、その機能の徹底的な分析を提供します。これらのベンチマークは、推論スキル、知識の保持、数学的問題解決、読解力をカバーしており、各モデルのパフォーマンスを包括的に把握できます。
このプラットフォームは自動パイプラインを採用し、すべてのモデルにわたって一貫したテスト条件を維持します。これにより、さまざまな環境や方法論によって生じる不一致が排除され、ユーザーは信頼性の高い完全な比較が可能になり、特定のユースケースに最適なものを特定できます。
リーダーボードは、オープンソース コミュニティに新しいモデルが登場するたびに、継続的に更新されます。自動化された評価プロセスのおかげで、手動介入による遅延なく、モデルを迅速に評価してランク付けできます。
さらに、ベンチマーク手法が改良されるたびに、プラットフォームは既存のモデルを再評価します。これにより、古いモデルが公正に表示され続け、リーダーボードの関連性と信頼性が長期にわたって維持されることが保証されます。
While the leaderboard doesn’t provide direct pricing, it includes key details such as model size, memory requirements, and inference speed. These metrics help users estimate the infrastructure costs involved in deploying each model.
コンピューティング要件に重点を置くことで、組織、特に限られたリソースや特定のハードウェア制約を扱う組織は、予算を意識した意思決定を行うことができます。オープンソース モデルを重視することで、このプラットフォームでは継続的なライセンス料も不要になり、独自の代替手段と比較して総所有コストがより予測可能になり、多くの場合管理しやすくなります。
Scale AI SEAL Leaderboard は、大規模言語モデル (LLM) の安全性、整合性、およびパフォーマンスの評価に特化しており、責任を持って AI を導入することに関する企業の主要な懸念に対処します。汎用のリーダーボードとは異なり、SEAL は、モデルが機密コンテンツをどの程度適切に処理し、倫理ガイドラインを遵守し、さまざまなシナリオにわたって一貫した動作を維持しているかを評価することに重点を置いています。これは、エンタープライズ環境における生のパフォーマンスと並んで、安全性と倫理的コンプライアンスの重要性を強調しています。その専門的なアプローチにより、モデルの機能、評価方法、更新スケジュール、および関連コストに関する詳細な洞察が得られます。
SEAL は、ビジネス アプリケーションで一般的に使用されるモデルに重点を置き、独自モデルとオープンソース モデルを組み合わせてレビューします。リーダーボードには、GPT-4、Claude、Gemini などの知名度の高い商用モデルだけでなく、Llama 2 や Mistral の亜種などの人気のあるオープンソース オプションも含まれています。
SEAL の特徴は、実験や研究に重点を置いたバージョンではなく、エンタープライズ対応モデルに重点を置いている点です。各モデルはさまざまなパラメータ サイズと微調整された構成にわたってテストされており、これらの変動が安全性とパフォーマンスのバランスにどのような影響を与えるかについてのより深い理解を提供します。このプラットフォームは、規制遵守やリスク管理が重要な医療や金融などの業界向けにカスタマイズされた特殊なモデルも評価します。
SEAL は、従来のパフォーマンス指標と広範な安全性テストを組み合わせた徹底的な評価フレームワークを使用しています。モデルは、有害なプロンプトを拒否し、事実の正確さを維持し、偏った出力や差別的な出力の生成を回避する能力について評価されます。
評価プロセスには、自動テストでは見落とされる可能性のある脆弱性や微妙なバイアスを明らかにするためのレッドチーム演習と人間によるレビューが含まれます。 SEAL は、自動評価と手動評価を組み合わせることで、安全性の考慮事項がパフォーマンスの指標と同等の重みを与えられるようにします。
SEAL リーダーボードは四半期ごとに更新され、その評価の詳細かつ安全性を中心とした性質が反映されています。各アップデートには新しくリリースされたモデルが組み込まれ、進化する安全性ベンチマークと基準に照らして既存のモデルが再評価されます。
これらのスケジュールされた更新に加えて、Scale AI は、AI コミュニティ内で重要なモデルの更新や安全関連のインシデントが発生したときに中間レポートをリリースします。この適応的なアプローチにより、企業ユーザーは最新の安全性評価にタイムリーにアクセスできるようになります。これは、モデルの進歩のペースが速いことを考えると特に重要です。これらの定期的な更新では、導入コストを分析するための貴重なデータも提供されます。
While SEAL doesn’t disclose direct pricing, it offers insights into the total cost of ownership, including factors like content moderation, compliance requirements, and liability risks. This helps enterprises weigh the costs of safety measures against operational expenses.
このプラットフォームは、さまざまな安全構成のためのインフラストラクチャのニーズに関するガイダンスも提供し、組織が安全性の強化と運用コストの間のトレードオフを理解するのに役立ちます。 SEAL は、エンタープライズ ユーザーに対して、堅牢な安全機能が組み込まれたモデルを導入する際のコンテンツ モデレーションの労力の削減による潜在的な節約額を見積もっています。
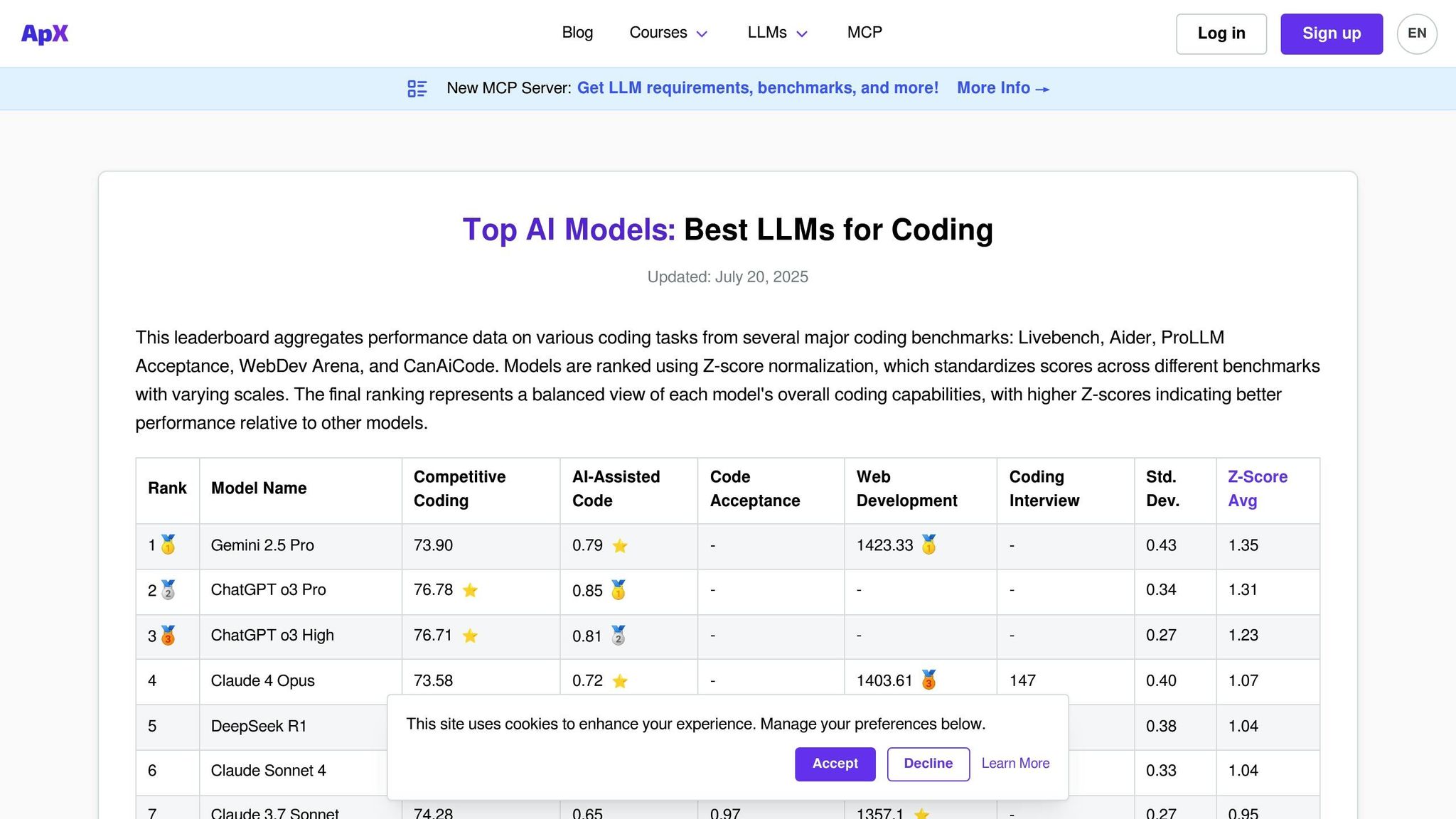
APX コーディング LLM は、言語モデルのコーディング機能を評価するために特別に設計されたプラットフォームです。幅広い会話スキルに焦点を当てた汎用リーダーボードとは異なり、APX はコード生成、デバッグ、アルゴリズム実装、技術的問題の解決などの分野に焦点を当てています。この点に重点を置いているため、AI を活用したコーディング アシスタントをワークフローに統合することを目指す開発者、エンジニアリング チーム、組織にとって不可欠なツールとなっています。
このプラットフォームは、モデルがさまざまな言語やフレームワークにわたる実践的なプログラミングの課題をどのように処理するかを評価します。他の評価プラットフォームと同様に、APX は評価プロセスを簡素化しますが、コードのパフォーマンスとセキュリティに重点を置いています。
APX は、コーディングの専門知識に基づいてテストされた商用モデルとオープンソース モデルの両方の広範なラインナップを備えています。このプラットフォームは、GitHub Copilot の基礎となる GPT モデル、CodeT5、StarCoder、Code Llama のバリアントなどのよく知られたコーディング モデルを定期的に評価します。 GPT-4、Claude、Gemini など、強力なプログラミング機能を備えた汎用モデルも含まれています。
APX の主な差別化要因は、広範なリーダーボードには表示されないかもしれないが、ニッチなプログラミング分野では優れている特殊なコーディング モデルが含まれていることです。これらのモデルは、Python、JavaScript、Java、C++、Rust、Go などの言語のドメイン固有のバリアントを含む、さまざまなパラメーター サイズと微調整されたバージョンにわたってテストされています。このプラットフォームは、React、Django、TensorFlow、PyTorch などのフレームワークを使用してパフォーマンスも評価します。
この包括的な対応により、APX は現実世界のコーディング ニーズに対して厳密かつ実践的なテストを提供できるようになります。
APX は、現実世界のコーディング シナリオに合わせた詳細なテスト フレームワークを採用しています。自動テストと専門家によるレビューを組み合わせて、コードの正確性、効率、読みやすさ、セキュリティ標準への準拠などの側面でモデルを評価します。
テスト シナリオには、アルゴリズムの課題、欠陥のあるコードのデバッグ、タスクのリファクタリング、ドキュメントの生成が含まれます。モデルは、複雑なコードの概念を説明し、最適化を提案する能力についても評価されます。
Incorporating industry-standard coding practices, APX evaluates whether models follow established conventions for naming, commenting, and structuring code. Additionally, it tests the models’ ability to recognize and avoid common security vulnerabilities, making it especially valuable for enterprises where secure coding is a priority.
APX リーダーボードは、AI コーディング ツールの急速に進化する状況に歩調を合わせるために毎月更新されます。更新には、新しくリリースされたモデルの追加や既存のモデルの再評価が含まれており、最新のプログラミングの課題や標準との整合性が確保されます。
このプラットフォームは、モデルの重要な更新に対するリアルタイムのパフォーマンス追跡も提供し、開発者が最新の機能に即座にアクセスできるようにします。コーディングに重点を置いた主要なモデルが発売されると、APX は特別な評価サイクルを実施して、そのパフォーマンスに関するタイムリーな洞察を提供します。
APX は、コーディング タスクに特化したトークンあたりのコスト分析の詳細な内訳を提供します。この分析は、ユーザーがさまざまなユースケースにおけるさまざまなモデルのコストへの影響を理解するのに役立ちます。コストはプログラミング言語とタスクの複雑さによって分類され、どのモデルが最高の価値を提供するかについて明確な洞察が得られます。
コスト分析では、一般的なコーディング タスク中の API 呼び出しの頻度、トークンの使用パターン、デバッグ時間の短縮による節約の可能性などの要素が考慮されます。 APX は、生産性の向上とサブスクリプション料金および使用料を比較検討して、AI コーディング アシスタントを導入するチームの総所有コストも見積もっています。このレベルの詳細により、APX は AI 主導のコーディング ソリューションの財務上の影響を評価するための貴重なリソースになります。
大規模言語モデル (LLM) の並列比較プラットフォームは、さまざまなニーズに応えます。 Prompts.ai は、コスト管理とガバナンスを確保するための一元化ツールと組み合わせて、35 を超える最上位モデルへのアクセスを提供することで際立っています。そのため、堅牢な監視機能を備えた安全でコンプライアンスに準拠したワークフローを必要とする大規模組織にとって、強力な選択肢となります。
Prompts.ai はコスト管理とガバナンスを重視していますが、他のプラットフォームは異なる優先事項に重点を置いています。これらには、コミュニティ主導のフィードバック、技術的なベンチマーク、または安全性や調整などの特殊な指標が含まれる場合があります。これらのプラットフォームは、モデルの選択、評価方法、更新スケジュール、価格の透明性が異なります。
This summary complements earlier in-depth analyses, helping you identify the tools that best fit your goals. Whether your focus is budget, technical depth, or specific use cases, it’s worth noting that many organizations rely on a mix of platforms to achieve a well-rounded understanding of both technical and business needs.
When evaluating platforms for large language model (LLM) comparison, the best choice ultimately hinges on balancing factors like cost, performance, and compliance. The decision should align with your organization’s specific needs, technical capabilities, and workflow demands.
For enterprises seeking a unified AI orchestration solution, Prompts.ai offers a compelling option. With access to over 35 leading LLMs, integrated cost management tools, and enterprise-grade governance controls, it’s designed to simplify operations for organizations overseeing multiple teams and complex projects.
That said, the LLM platform landscape is diverse, and there’s no universal solution that fits every scenario. Many organizations adopt a mix of tools to address both research and production requirements. By focusing on your primary goals - whether it’s reducing costs, enhancing performance, or ensuring compliance - you can refine your platform selection process and streamline AI implementation.
適切なオーケストレーションおよび比較ツールを選択すると、AI イニシアチブに目に見える改善がもたらされ、有意義なビジネス結果がもたらされる可能性があります。
Prompts.ai は、パフォーマンス、スケーラビリティ、コスト効率に関する明確で実用的な洞察を提供することで、複数の大規模言語モデル (LLM) を評価するという課題を簡素化します。これにより、ユーザーは情報に基づいた選択が可能になり、予算内でニーズに最適なモデルを選択できるようになります。
Prompts.ai は、コストとパフォーマンスのバランス、および運用効率を評価するように設計されたツールを使用して、企業が不必要な経費を回避し、独自の要件に合わせた最も効果的なソリューションの実装に集中できるようにします。
大規模言語モデル (LLM) の比較をカスタマイズするツールを提供するプラットフォームは、ユーザーが独自の目標に合わせて評価を微調整できるため、非常に貴重です。これらのツールは、パフォーマンス、機能、実際のアプリケーションなどの重要な側面に焦点を当てることで、推測に頼る作業を減らし、最適なモデルを特定するプロセスを簡素化します。
これらの比較ツールは、より詳細なベンチマークも提供し、研究者、開発者、企業などに貴重な洞察を提供します。特定のタスクに合わせてソリューションを改良する場合でも、複数のオプションを比較検討する場合でも、これらのプラットフォームを使用すると、意思決定がより迅速かつ効果的に行われます。
AI プラットフォームの精度、信頼性、信頼性を維持するには、評価方法とモデル データベースを定期的に更新することが不可欠です。これらのアップデートにより、最新のデータを組み込み、トレンドに適応し、新しいユースケースに対処することでモデルを最新の状態に保つことができ、最終的にパフォーマンスと意思決定が向上します。
手法を一貫して改良することで、プラットフォームはバイアスに対処し、モデルの適応性を向上させ、変化する業界標準に対応できるようになります。この進歩への献身により、AI ソリューションは効率的でコンプライアンスに準拠し、急速に変化する環境でもユーザーのニーズを満たす装備を維持することができます。



















