Bayar Sesuai Pemakaian - AI Model Orchestration and Workflows Platform

Dalam lanskap AI yang padat, memilih model bahasa besar (LLM) yang tepat bisa jadi sangat melelahkan. Dengan model seperti GPT-5, Claude, dan Gemini yang unggul di berbagai bidang, platform perbandingan menyederhanakan proses pengambilan keputusan dengan menawarkan analisis kinerja, biaya, dan kasus penggunaan secara berdampingan. Inilah yang perlu Anda ketahui:
Platform ini memenuhi berbagai kebutuhan - baik Anda mengoptimalkan biaya, memastikan keamanan, atau mengevaluasi kemampuan coding. Di bawah ini adalah perbandingan singkat untuk membantu Anda memutuskan.
Memilih platform yang tepat bergantung pada tujuan Anda - apakah itu mengurangi biaya, memastikan kepatuhan keselamatan, atau meningkatkan produktivitas. Platform seperti Prompts.ai menonjol untuk perusahaan yang mengelola banyak LLM, sedangkan APX Coding LLM sangat cocok untuk pengembang. Setiap alat menawarkan perspektif unik untuk memandu strategi AI Anda.
Prompts.ai adalah platform AI perusahaan yang dirancang untuk menyederhanakan proses perbandingan dan penerapan model bahasa besar (LLM). Dengan menggabungkan lebih dari 35 LLM terkemuka ke dalam satu dasbor terpadu, platform ini menghilangkan kebutuhan untuk mengatur banyak alat. Penyiapan yang disederhanakan ini tidak hanya mengurangi kompleksitas tetapi juga memungkinkan tim mengambil keputusan yang tepat dengan membandingkan model dalam hal performa, biaya, dan kecepatan integrasi - semuanya di satu tempat.
Prompts.ai menawarkan akses ke berbagai model AI canggih, antara lain GPT-5, Claude, LLaMA, Gemini, Grok-4, Flux Pro, dan Kling. Pustaka yang luas ini memungkinkan pengguna menilai model dengan berbagai kekuatan dan spesialisasi tanpa perlu repot berpindah platform atau mengelola beberapa kunci API.
The platform's ability to aggregate these models ensures users can evaluate them based on real-world applications. Whether it’s testing coding efficiency, creative writing skills, or expertise in specific domains, the side-by-side comparison feature enables simultaneous testing of identical prompts across multiple models.
Prompts.ai mengambil pendekatan yang mengutamakan pengguna dalam evaluasi model, menawarkan fleksibilitas yang melampaui tolok ukur umum. Daripada mengandalkan metrik yang telah ditentukan sebelumnya, pengguna dapat membuat skenario evaluasi yang dipersonalisasi dan disesuaikan dengan kebutuhan unik mereka, menggunakan petunjuk dan data mereka sendiri.
The platform’s interface displays results side by side, offering a clear view of output quality, response times, and methodologies. This approach is especially beneficial for businesses that need to test models against proprietary datasets or industry-specific challenges that standard benchmarks fail to address.
Prompts.ai mengintegrasikan lapisan FinOps yang menyediakan pelacakan penggunaan token secara real-time di semua model. Dengan memantau konsumsi token, tim dapat langsung membandingkan kinerja dan implikasi finansial, sehingga memudahkan untuk mengevaluasi model mana yang memberikan nilai terbaik.
The platform’s Pay-As-You-Go TOKN credit system ensures that costs align with actual usage, potentially reducing expenses by up to 98%. For organizations managing tight budgets or allocating resources across multiple AI projects, this level of cost clarity supports smarter, data-driven decisions.
Prompts.ai keeps its users ahead of the curve by rapidly integrating new models as they become available. Its architecture is built for agility, ensuring emerging models are added quickly, so users don’t face delays in accessing the latest advancements.
Selain model-model baru, platform ini juga meluncurkan pembaruan dan pengoptimalan dengan lancar. Seiring dengan peningkatan model dan versi baru yang dirilis, pengguna dapat mengandalkan Prompts.ai untuk memberikan akses tanpa gangguan terhadap penyempurnaan ini, sehingga memungkinkan mereka untuk tetap kompetitif dalam lanskap AI yang terus berkembang.
Analisis Buatan berfokus pada penyampaian evaluasi model bahasa besar (LLM) yang konsisten dan menyeluruh melalui tolok ukur standar dan proses pengujian berulang. Dengan mengikuti pendekatan sistematis, platform ini memberikan wawasan mendalam tentang bagaimana kinerja LLM yang berbeda di berbagai tugas kognitif dan aplikasi praktis.
The platform maintains an extensive database that includes evaluations of both proprietary and open-source LLMs from leading AI developers like OpenAI, Anthropic, Google, Meta, and newer players in the field. It doesn’t stop at mainstream models but also includes specialized and fine-tuned versions, offering users the chance to explore options tailored to unique or niche requirements. This wide-ranging coverage ensures users can access performance data for virtually any model they might consider.
Analisis Buatan menggunakan Metodologi Pembandingan Intelijen yang kuat yang dirancang untuk mengevaluasi model di berbagai dimensi. Daripada mengandalkan satu metrik saja, platform ini menggunakan sistem penilaian berbobot yang menilai penalaran, akurasi, kreativitas, dan kemampuan spesifik tugas. Setiap model diuji secara ketat dengan perintah dan kumpulan data standar, dan hasilnya dinormalisasi untuk memastikan perbandingan yang adil di berbagai arsitektur dan ukuran. Kombinasi penilaian otomatis dan evaluasi manusia menambah kedalaman dan keandalan penilaian ini.
Mengikuti perkembangan lanskap LLM yang berubah dengan cepat, Analisis Buatan sering memperbarui metodologinya. Pembaruan terkini, Versi 3.0, dirilis pada 2 September 2025. Pembaruan rutin ini memastikan platform tetap menjadi sumber informasi terkini dan dapat ditindaklanjuti yang dapat diandalkan, memungkinkan pengguna membuat keputusan yang tepat ketika memilih model bahasa terbaik untuk kebutuhan mereka.
LMSYS Chatbot Arena adalah platform kolaboratif yang dirancang untuk menilai model bahasa besar (LLM) melalui masukan manusia secara real-time. Pendekatan ini memastikan bahwa evaluasi tetap relevan dengan menangkap interaksi pengguna dan perbaikan berkelanjutan pada model.
Platform ini menampung beragam pilihan model, termasuk opsi kepemilikan, sumber terbuka, dan eksperimental. Hal ini memungkinkan pengguna untuk menguji dan membandingkan kinerja berbagai model di berbagai tugas dan aplikasi.
Untuk meminimalkan bias, pengguna melakukan perbandingan berpasangan buta antar model. Hasilnya kemudian dikumpulkan untuk menentukan peringkat model berdasarkan kualitas percakapan, orisinalitas, dan kegunaan praktisnya.
Papan peringkat terus diperbarui dengan masukan pengguna, memastikan papan tersebut mencerminkan rilis model terbaru dan tren kinerja.
Papan Peringkat Vellum AI menawarkan wawasan yang dapat ditindaklanjuti mengenai kinerja model, yang dirancang khusus untuk aplikasi bisnis praktis.
Papan peringkat menampilkan pilihan model komersial dan sumber terbuka pilihan yang dirancang untuk penggunaan perusahaan. Ini termasuk penawaran dari penyedia seperti OpenAI, Anthropic, dan Google, serta opsi sumber terbuka seperti Llama 2 dan Mistral.
Apa yang membuat Vellum menonjol adalah fokusnya pada model yang siap untuk bisnis. Alih-alih mencantumkan opsi eksperimental atau belum terbukti, laporan ini menyoroti model yang telah menunjukkan keandalan dan cocok untuk penerapan komersial.
Vellum mengevaluasi model menggunakan pendekatan terstruktur dalam enam kategori utama: penalaran, pembuatan kode, penulisan kreatif, akurasi faktual, mengikuti instruksi, dan kepatuhan keselamatan.
Setiap model diuji dengan petunjuk yang meniru skenario bisnis dunia nyata, menggabungkan penilaian otomatis dengan tinjauan manusia. Evaluasi berlapis ganda ini memastikan hasilnya mencerminkan kegunaan praktis dan bukan sekadar tolok ukur teoretis. Pembaruan rutin pada proses evaluasi memastikan papan peringkat tetap selaras dengan perkembangan terkini di bidang LLM.
Papan peringkat diperbarui setiap bulan, dengan pembaruan tambahan untuk rilis model utama. Jadwal ini memastikan pengujian menyeluruh sambil tetap mengikuti perkembangan pesat dalam model bahasa besar.
Vellum juga melacak kinerja historis, memungkinkan pengguna meninjau bagaimana model berevolusi dari waktu ke waktu. Fitur ini membantu bisnis mengambil keputusan yang tepat mengenai kapan harus mengadopsi model baru atau meningkatkan model yang sudah ada.
Vellum memberikan rincian biaya, termasuk harga per 1.000 token dan perkiraan biaya untuk tugas-tugas seperti dukungan pelanggan, pembuatan konten, dan bantuan kode.
LiveBench mengatasi tantangan kontaminasi data dengan sering memperbarui pertanyaan benchmarknya. Hal ini memastikan model dievaluasi berdasarkan materi baru, mencegah model hanya mengingat data pelatihan.
LiveBench mendukung beragam model, mulai dari sistem yang lebih kecil dengan 0,5 miliar parameter hingga sistem besar yang memiliki 405 miliar parameter. Mereka telah menilai 49 model bahasa besar (LLM) yang berbeda, termasuk platform berpemilik terkemuka, alternatif sumber terbuka terkemuka, dan model khusus khusus.
The platform’s robust API compatibility allows seamless evaluation of any model with an OpenAI-compatible endpoint. This includes models from providers like Anthropic, Cohere, Mistral, Together, and Google.
Mulai 9 Oktober 2025, papan peringkat menampilkan model-model canggih seperti seri GPT-5 OpenAI (Tinggi, Sedang, Pro, Codex, Mini, o3, o4-Mini), Claude Sonnet 4.5 dan Claude 4.1 Opus dari Anthropic, Gemini 2.5 Pro dan Flash dari Google, Grok 4 dari xAI, DeepSeek V3.1, dan Qwen 3 Max dari Alibaba.
LiveBench menggunakan metodologi tahan kontaminasi, menguji model pada 21 tugas yang dibagi menjadi tujuh kategori, termasuk penalaran, pengkodean, matematika, dan pemahaman bahasa. Untuk menjaga integritas tolok ukurnya, platform ini memperbarui semua pertanyaan setiap enam bulan dan memperkenalkan tugas yang lebih kompleks dari waktu ke waktu. Misalnya, versi terbaru, LiveBench-2025-05-30, menambahkan tugas pengkodean agen di mana model harus menavigasi lingkungan pengembangan dunia nyata untuk menyelesaikan masalah repositori.
Untuk lebih menjaga proses evaluasi, sekitar 300 pertanyaan dari pembaruan terkini – sekitar 30% dari total – masih belum dipublikasikan. Hal ini memastikan model tidak dapat dilatih berdasarkan data pengujian yang tepat. Langkah-langkah ini, dikombinasikan dengan pembaruan rutin, menjaga tolok ukur tersebut tetap relevan dan menantang.
LiveBench mengikuti jadwal pembaruan yang ketat, merilis pertanyaan baru secara konsisten dan menyegarkan seluruh tolok ukur setiap enam bulan. Pengguna dapat meminta evaluasi untuk model yang baru dikembangkan dengan mengirimkan masalah GitHub atau menghubungi tim LiveBench melalui email. Hal ini memungkinkan model yang muncul untuk dinilai tanpa menunggu pembaruan terjadwal berikutnya. Penambahan terbaru dari Desember 2024 mencakup model seperti claude-3-5-haiku-20241022, claude-3-5-sonnet-20241022, gemini-exp-1114, gpt-4o-2024-11-20, grok-2, dan grok-2-mini.
LLM-Stats menyediakan cara berbasis data untuk membandingkan model bahasa besar dengan menganalisis statistik gabungan dari berbagai tolok ukur. Meskipun memberikan wawasan berharga tentang kinerja model, hal-hal spesifik seperti bagaimana model dikategorikan, metode evaluasi yang digunakan, detail harga, dan seberapa sering data diperbarui belum dibagikan. Pendekatan statistik ini berfungsi sebagai pendamping yang berguna bagi perbandingan kualitatif sebelumnya.
OpenRouter Rankings mengambil pendekatan praktis untuk mengevaluasi kinerja model bahasa, dengan fokus pada bagaimana kinerja model dalam skenario dunia nyata daripada hanya mengandalkan tolok ukur teknis. Dengan menggabungkan data dari penggunaan sehari-hari, kami menyoroti model mana yang benar-benar memberikan nilai dalam aplikasi praktis. Penekanan pada metrik dunia nyata ini melengkapi evaluasi teknis yang lebih rinci yang disediakan oleh platform lain.
Platform ini mencakup berbagai model bahasa, yang disusun berdasarkan aplikasi spesifiknya. Dengan mengkategorikan model berdasarkan kasus penggunaannya, hal ini membantu pengguna dengan mudah mengidentifikasi solusi yang selaras dengan kebutuhan khusus mereka.
OpenRouter Rankings uses a usage-based evaluation system, considering multiple factors like response quality, efficiency, and cost. These metrics are combined into composite scores that provide a clear picture of each model’s overall effectiveness and value.
Pemeringkatan diperbarui secara berkala untuk memperhitungkan perubahan kinerja model dan tren penggunaan, memastikan data tetap relevan dan terkini.
Fokus utama dari platform ini adalah pada faktor ekonomi. Dengan menganalisis penetapan harga dan metrik terkait biaya, hal ini memberikan kejelasan tentang keseimbangan antara biaya dan kinerja, sehingga membantu pengguna mengambil keputusan yang tepat.
Papan Peringkat LLM Hugging Face Open menonjol sebagai platform khusus untuk mengevaluasi kinerja model bahasa sumber terbuka. Dirancang oleh Hugging Face, ini berfungsi sebagai sumber daya utama bagi para peneliti dan pengembang yang ingin membandingkan model dengan tolok ukur standar. Dengan berfokus secara eksklusif pada model sumber terbuka, papan peringkat ini selaras dengan kebutuhan mereka yang menghargai transparansi dan aksesibilitas terbuka dalam solusi AI mereka. Hal ini melengkapi perbandingan berbasis kinerja dan perusahaan yang telah dibahas sebelumnya, dan menawarkan perspektif unik mengenai lanskap AI sumber terbuka.
Papan peringkat mengatur berbagai model sumber terbuka berdasarkan ukuran parameter - 7B, 13B, 30B, dan 70B+ - yang mencakup desain eksperimental dan implementasi skala besar dari lembaga penelitian terkemuka.
Ini menampilkan kontribusi dari organisasi dan pengembang individu, membina ekosistem yang beragam dan dinamis yang mencerminkan kondisi AI sumber terbuka saat ini. Setiap entri model mencakup informasi terperinci tentang arsitektur, data pelatihan, dan ketentuan perizinan, memungkinkan pengguna membuat pilihan berdasarkan kebutuhan proyek dan persyaratan kepatuhan.
Dengan menggunakan kerangka evaluasi standar, Hugging Face menilai model berdasarkan berbagai tolok ukur, menawarkan analisis menyeluruh mengenai kemampuannya. Tolok ukur ini mencakup keterampilan penalaran, retensi pengetahuan, pemecahan masalah matematika, dan pemahaman membaca, memastikan pandangan menyeluruh tentang kinerja setiap model.
Platform ini menggunakan jalur pipa otomatis untuk mempertahankan kondisi pengujian yang konsisten di semua model. Hal ini menghilangkan perbedaan yang disebabkan oleh lingkungan atau metodologi yang berbeda-beda, sehingga memberikan perbandingan yang dapat diandalkan dan relevan bagi pengguna untuk mengidentifikasi yang paling sesuai untuk kasus penggunaan spesifik mereka.
Papan peringkat terus diperbarui dengan model-model baru saat model tersebut muncul di komunitas sumber terbuka. Berkat proses evaluasi otomatisnya, model dapat dinilai dan diberi peringkat dengan cepat tanpa penundaan yang disebabkan oleh intervensi manual.
Selain itu, platform ini mengevaluasi ulang model yang ada setiap kali metodologi benchmark disempurnakan. Hal ini memastikan model lama tetap terwakili secara adil, menjaga relevansi dan kepercayaan papan peringkat dari waktu ke waktu.
While the leaderboard doesn’t provide direct pricing, it includes key details such as model size, memory requirements, and inference speed. These metrics help users estimate the infrastructure costs involved in deploying each model.
Fokus pada persyaratan komputasi ini memungkinkan organisasi untuk membuat keputusan berdasarkan anggaran, terutama mereka yang bekerja dengan sumber daya terbatas atau kendala perangkat keras tertentu. Dengan menekankan model sumber terbuka, platform ini juga menghilangkan biaya lisensi yang berkelanjutan, menjadikan total biaya kepemilikan lebih dapat diprediksi dan seringkali lebih mudah dikelola dibandingkan dengan alternatif kepemilikan.
Papan Peringkat Scale AI SEAL didedikasikan untuk mengevaluasi keselamatan, keselarasan, dan kinerja model bahasa besar (LLM), mengatasi kekhawatiran utama perusahaan tentang penerapan AI secara bertanggung jawab. Berbeda dengan papan peringkat tujuan umum, SEAL berfokus pada penilaian seberapa baik model menangani konten sensitif, mematuhi pedoman etika, dan mempertahankan perilaku yang konsisten dalam berbagai skenario. Hal ini menyoroti pentingnya keselamatan dan kepatuhan etika di samping kinerja mentah di lingkungan perusahaan. Pendekatan khususnya memberikan wawasan terperinci mengenai kemampuan model, metode evaluasi, jadwal pembaruan, dan biaya terkait.
SEAL meninjau gabungan model kepemilikan dan sumber terbuka, dengan fokus kuat pada model yang biasa digunakan dalam aplikasi bisnis. Papan peringkat mencakup model komersial terkenal seperti GPT-4, Claude, dan Gemini, serta opsi sumber terbuka populer seperti varian Llama 2 dan Mistral.
Yang membedakan SEAL adalah penekanannya pada model yang siap digunakan oleh perusahaan dibandingkan versi eksperimental atau yang berfokus pada penelitian. Setiap model diuji dalam berbagai ukuran parameter dan konfigurasi yang disesuaikan, sehingga menawarkan pemahaman yang lebih mendalam tentang bagaimana variasi ini memengaruhi keseimbangan antara keselamatan dan kinerja. Platform ini juga mengevaluasi model khusus yang disesuaikan untuk industri seperti layanan kesehatan atau keuangan, yang mengutamakan kepatuhan terhadap peraturan dan manajemen risiko.
SEAL menggunakan kerangka evaluasi menyeluruh yang memadukan metrik kinerja tradisional dengan uji keselamatan ekstensif. Model dinilai berdasarkan kemampuannya dalam menolak dorongan yang merugikan, mempertahankan keakuratan faktual, dan menghindari menghasilkan keluaran yang bias atau diskriminatif.
Proses evaluasi mencakup latihan tim merah dan tinjauan manusia untuk mengungkap kerentanan dan bias halus yang mungkin diabaikan oleh pengujian otomatis. Dengan menggabungkan penilaian otomatis dan manual, SEAL memastikan bahwa pertimbangan keselamatan diberikan bobot yang sama di samping metrik kinerja.
Papan Peringkat SEAL diperbarui setiap triwulan, mencerminkan sifat evaluasinya yang terperinci dan berpusat pada keselamatan. Setiap pembaruan menggabungkan model-model yang baru dirilis dan mengevaluasi ulang model-model yang sudah ada terhadap tolok ukur dan standar keselamatan yang terus berkembang.
Selain pembaruan terjadwal ini, Scale AI merilis laporan sementara ketika pembaruan model yang signifikan atau insiden terkait keselamatan terjadi dalam komunitas AI. Pendekatan adaptif ini memastikan bahwa pengguna perusahaan memiliki akses tepat waktu terhadap penilaian keselamatan terbaru, yang sangat penting mengingat pesatnya kemajuan model. Pembaruan rutin ini juga menyediakan data berharga untuk menganalisis biaya penerapan.
While SEAL doesn’t disclose direct pricing, it offers insights into the total cost of ownership, including factors like content moderation, compliance requirements, and liability risks. This helps enterprises weigh the costs of safety measures against operational expenses.
Platform ini juga memberikan panduan mengenai kebutuhan infrastruktur untuk berbagai konfigurasi keselamatan, membantu organisasi memahami trade-off antara peningkatan keselamatan dan biaya operasional. Untuk pengguna perusahaan, SEAL memperkirakan potensi penghematan dari pengurangan upaya moderasi konten saat menerapkan model dengan fitur keselamatan bawaan yang kuat.
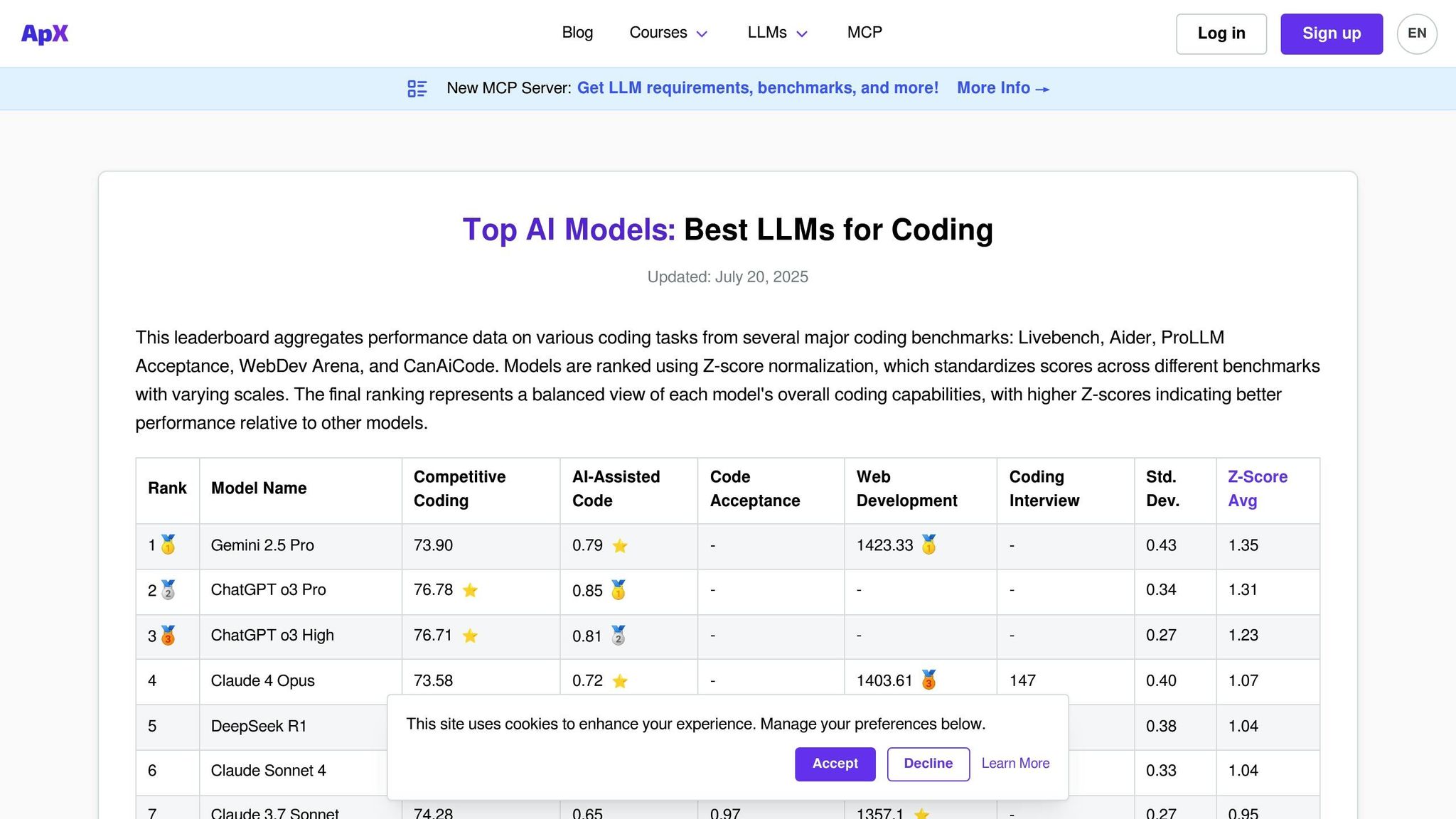
APX Coding LLMs adalah platform yang dirancang khusus untuk mengevaluasi kemampuan pengkodean model bahasa. Tidak seperti papan peringkat tujuan umum yang berfokus pada berbagai keterampilan percakapan, APX memusatkan perhatian pada bidang-bidang seperti pembuatan kode, debugging, implementasi algoritma, dan penyelesaian masalah teknis. Fokus ini menjadikannya alat penting bagi pengembang, tim teknik, dan organisasi yang ingin mengintegrasikan asisten pengkodean bertenaga AI ke dalam alur kerja mereka.
Platform ini mengevaluasi bagaimana model menangani tantangan pemrograman praktis di berbagai bahasa dan kerangka kerja. Mirip dengan platform evaluasi lainnya, APX menyederhanakan proses penilaian tetapi dengan fokus pada kinerja dan keamanan kode.
APX menampilkan beragam model komersial dan sumber terbuka yang diuji keahlian pengkodeannya. Platform ini secara rutin mengevaluasi model pengkodean terkenal seperti model GPT yang mendasari GitHub Copilot, CodeT5, StarCoder, dan varian Code Llama. Ini juga mencakup model tujuan umum dengan kemampuan pemrograman yang kuat, seperti GPT-4, Claude, dan Gemini.
Pembeda utama APX adalah dimasukkannya model pengkodean khusus yang mungkin tidak muncul di papan peringkat yang lebih luas namun unggul dalam bidang pemrograman khusus. Model ini diuji pada berbagai ukuran parameter dan versi yang disempurnakan, termasuk varian khusus domain untuk bahasa seperti Python, JavaScript, Java, C++, Rust, dan Go. Platform ini juga mengevaluasi kinerja dengan kerangka kerja seperti React, Django, TensorFlow, dan PyTorch.
Cakupan komprehensif ini memastikan bahwa APX menyediakan pengujian yang ketat dan praktis untuk kebutuhan pengkodean di dunia nyata.
APX menggunakan kerangka pengujian terperinci yang disesuaikan dengan skenario pengkodean dunia nyata. Ini mengevaluasi model berdasarkan aspek seperti kebenaran kode, efisiensi, keterbacaan, dan kepatuhan terhadap standar keamanan melalui kombinasi pengujian otomatis dan tinjauan ahli.
Skenario pengujian mencakup tantangan algoritma, debugging kode yang cacat, tugas refactoring, dan menghasilkan dokumentasi. Model juga dinilai kemampuannya dalam menjelaskan konsep kode yang kompleks dan menyarankan pengoptimalan.
Incorporating industry-standard coding practices, APX evaluates whether models follow established conventions for naming, commenting, and structuring code. Additionally, it tests the models’ ability to recognize and avoid common security vulnerabilities, making it especially valuable for enterprises where secure coding is a priority.
Papan peringkat APX diperbarui setiap bulan untuk mengimbangi lanskap alat pengkodean AI yang berkembang pesat. Pembaruan mencakup penambahan model yang baru dirilis dan evaluasi ulang model yang sudah ada, memastikan keselarasan dengan tantangan dan standar pemrograman terkini.
Platform ini juga menawarkan pelacakan kinerja real-time untuk pembaruan model yang signifikan, memberikan pengembang akses langsung ke kemampuan terbaru. Ketika model utama yang berfokus pada pengkodean diluncurkan, APX melakukan siklus evaluasi khusus untuk memberikan wawasan yang tepat waktu mengenai kinerjanya.
APX memberikan rincian analisis biaya per token yang dirancang khusus untuk tugas pengkodean. Analisis ini membantu pengguna memahami implikasi biaya dari berbagai model untuk berbagai kasus penggunaan. Biaya dikelompokkan berdasarkan bahasa pemrograman dan kompleksitas tugas, sehingga memberikan wawasan yang jelas tentang model mana yang memberikan nilai terbaik.
Analisis biaya mempertimbangkan faktor-faktor seperti frekuensi panggilan API selama tugas pengkodean umum, pola penggunaan token, dan potensi penghematan dari pengurangan waktu debugging. APX bahkan memperkirakan total biaya kepemilikan untuk tim yang mengadopsi asisten pengkodean AI, dengan mempertimbangkan peningkatan produktivitas dibandingkan biaya berlangganan dan penggunaan. Tingkat detail ini menjadikan APX sebagai sumber berharga untuk menilai dampak finansial dari solusi pengkodean berbasis AI.
Platform perbandingan berdampingan untuk model bahasa besar (LLM) memenuhi berbagai kebutuhan. Prompts.ai menonjol dengan menawarkan akses ke lebih dari 35 model papan atas, dipadukan dengan alat terpusat untuk mengelola biaya dan memastikan tata kelola. Hal ini menjadikannya pilihan tepat bagi organisasi besar yang membutuhkan alur kerja yang aman dan patuh dengan pengawasan yang kuat.
Meskipun Prompts.ai menekankan manajemen biaya dan tata kelola, platform lain berfokus pada prioritas yang berbeda. Hal ini dapat mencakup umpan balik berbasis komunitas, tolok ukur teknis, atau metrik khusus seperti keselamatan dan keselarasan. Platform-platform ini bervariasi dalam pemilihan model, metode evaluasi, jadwal pembaruan, dan transparansi harga.
This summary complements earlier in-depth analyses, helping you identify the tools that best fit your goals. Whether your focus is budget, technical depth, or specific use cases, it’s worth noting that many organizations rely on a mix of platforms to achieve a well-rounded understanding of both technical and business needs.
When evaluating platforms for large language model (LLM) comparison, the best choice ultimately hinges on balancing factors like cost, performance, and compliance. The decision should align with your organization’s specific needs, technical capabilities, and workflow demands.
For enterprises seeking a unified AI orchestration solution, Prompts.ai offers a compelling option. With access to over 35 leading LLMs, integrated cost management tools, and enterprise-grade governance controls, it’s designed to simplify operations for organizations overseeing multiple teams and complex projects.
That said, the LLM platform landscape is diverse, and there’s no universal solution that fits every scenario. Many organizations adopt a mix of tools to address both research and production requirements. By focusing on your primary goals - whether it’s reducing costs, enhancing performance, or ensuring compliance - you can refine your platform selection process and streamline AI implementation.
Memilih alat orkestrasi dan perbandingan yang tepat dapat menghasilkan peningkatan terukur dalam inisiatif AI Anda dan mendorong hasil bisnis yang berarti.
Prompts.ai menyederhanakan tantangan dalam mengevaluasi berbagai model bahasa besar (LLM) dengan memberikan wawasan yang jelas dan dapat ditindaklanjuti mengenai kinerja, skalabilitas, dan efisiensi biayanya. Hal ini memberdayakan pengguna untuk membuat pilihan yang tepat, memilih model yang paling sesuai dengan kebutuhan mereka dan tetap sesuai anggaran.
Dengan alat yang dirancang untuk menilai keseimbangan antara biaya dan kinerja, serta efisiensi operasional, Prompts.ai memastikan bisnis dapat menghindari pengeluaran yang tidak perlu dan berkonsentrasi pada penerapan solusi paling efektif yang disesuaikan dengan kebutuhan unik mereka.
Platform yang menawarkan alat untuk menyesuaikan perbandingan model bahasa besar (LLM) sangat berharga karena memungkinkan pengguna menyempurnakan evaluasi agar sesuai dengan tujuan unik mereka. Dengan mempertajam aspek-aspek penting seperti performa, fitur, dan aplikasi praktis, alat ini menyederhanakan proses mengidentifikasi model yang paling sesuai, sehingga mengurangi dugaan-dugaan.
Alat perbandingan ini juga memberikan tolok ukur yang lebih mendetail, menawarkan wawasan berharga bagi peneliti, pengembang, dan bisnis. Baik Anda menyempurnakan solusi untuk tugas tertentu atau mempertimbangkan beberapa opsi, platform ini membuat pengambilan keputusan menjadi lebih cepat dan efektif.
Memperbarui metode evaluasi dan database model secara berkala sangat penting untuk menjaga presisi, ketergantungan, dan kredibilitas dalam platform AI. Pembaruan ini memungkinkan model untuk tetap mengikuti perkembangan terkini dengan menggabungkan data baru, beradaptasi dengan tren, dan menangani kasus penggunaan baru, yang pada akhirnya meningkatkan kinerja dan pengambilan keputusan.
Penyempurnaan metodologi yang konsisten memungkinkan platform mengatasi bias, meningkatkan kemampuan adaptasi model, dan memenuhi standar industri yang terus berubah. Dedikasi terhadap kemajuan ini memastikan solusi AI tetap efisien, patuh, dan dilengkapi untuk memenuhi kebutuhan pengguna di lingkungan yang bergerak cepat.



















