जितना उपयोग करें उतना भुगतान करें - AI Model Orchestration and Workflows Platform

भीड़-भाड़ वाले एआई परिदृश्य में, सही बड़े भाषा मॉडल (एलएलएम) को चुनना भारी पड़ सकता है। GPT-5, क्लाउड और जेमिनी जैसे मॉडलों के विभिन्न क्षेत्रों में उत्कृष्ट प्रदर्शन के साथ, तुलना प्लेटफ़ॉर्म प्रदर्शन, लागत और उपयोग के मामलों के साथ-साथ विश्लेषण की पेशकश करके निर्णय लेने की प्रक्रिया को सरल बनाते हैं। यहां वह है जो आपको जानना आवश्यक है:
ये प्लेटफ़ॉर्म विभिन्न आवश्यकताओं को पूरा करते हैं - चाहे आप लागतों का अनुकूलन कर रहे हों, सुरक्षा सुनिश्चित कर रहे हों, या कोडिंग क्षमताओं का मूल्यांकन कर रहे हों। निर्णय लेने में आपकी सहायता के लिए नीचे एक त्वरित तुलना दी गई है।
सही प्लेटफ़ॉर्म चुनना आपके लक्ष्यों पर निर्भर करता है - चाहे वह लागत कम करना हो, सुरक्षा अनुपालन सुनिश्चित करना हो, या उत्पादकता बढ़ाना हो। Prompts.ai जैसे प्लेटफ़ॉर्म कई एलएलएम प्रबंधित करने वाले उद्यमों के लिए विशिष्ट हैं, जबकि एपीएक्स कोडिंग एलएलएम डेवलपर्स के लिए एकदम सही है। प्रत्येक टूल आपकी AI रणनीति का मार्गदर्शन करने के लिए एक अद्वितीय परिप्रेक्ष्य प्रदान करता है।
Prompts.ai एक एंटरप्राइज़ एआई प्लेटफ़ॉर्म है जिसे बड़े भाषा मॉडल (एलएलएम) की तुलना और तैनाती की प्रक्रिया को सरल बनाने के लिए डिज़ाइन किया गया है। 35 से अधिक अग्रणी एलएलएम को एक एकल, एकीकृत डैशबोर्ड में समेकित करके, प्लेटफ़ॉर्म एकाधिक टूल की आवश्यकता को समाप्त कर देता है। यह सुव्यवस्थित सेटअप न केवल जटिलता को कम करता है बल्कि टीमों को एक ही स्थान पर प्रदर्शन, लागत और एकीकरण गति पर मॉडलों की तुलना करके अच्छी तरह से सूचित निर्णय लेने में सक्षम बनाता है।
Prompts.ai अत्याधुनिक AI मॉडलों की एक विस्तृत श्रृंखला तक पहुंच प्रदान करता है, जिनमें GPT-5, क्लाउड, LLaMA, जेमिनी, ग्रोक-4, फ्लक्स प्रो और क्लिंग शामिल हैं। यह व्यापक लाइब्रेरी उपयोगकर्ताओं को प्लेटफ़ॉर्म स्विच करने या कई एपीआई कुंजियों को प्रबंधित करने की परेशानी के बिना विभिन्न शक्तियों और विशिष्टताओं वाले मॉडल का आकलन करने की अनुमति देती है।
The platform's ability to aggregate these models ensures users can evaluate them based on real-world applications. Whether it’s testing coding efficiency, creative writing skills, or expertise in specific domains, the side-by-side comparison feature enables simultaneous testing of identical prompts across multiple models.
Prompts.ai मॉडल मूल्यांकन के लिए उपयोगकर्ता-प्रथम दृष्टिकोण अपनाता है, जो लचीलेपन की पेशकश करता है जो सामान्य बेंचमार्क से परे है। पूर्व-निर्धारित मेट्रिक्स पर भरोसा करने के बजाय, उपयोगकर्ता अपने स्वयं के संकेतों और डेटा का उपयोग करके, अपनी विशिष्ट आवश्यकताओं के अनुरूप वैयक्तिकृत मूल्यांकन परिदृश्य बना सकते हैं।
The platform’s interface displays results side by side, offering a clear view of output quality, response times, and methodologies. This approach is especially beneficial for businesses that need to test models against proprietary datasets or industry-specific challenges that standard benchmarks fail to address.
Prompts.ai एक FinOps परत को एकीकृत करता है जो सभी मॉडलों में टोकन उपयोग की वास्तविक समय ट्रैकिंग प्रदान करता है। टोकन खपत की निगरानी करके, टीमें सीधे प्रदर्शन और वित्तीय निहितार्थों की तुलना कर सकती हैं, जिससे यह मूल्यांकन करना आसान हो जाता है कि कौन से मॉडल सर्वोत्तम मूल्य प्रदान करते हैं।
The platform’s Pay-As-You-Go TOKN credit system ensures that costs align with actual usage, potentially reducing expenses by up to 98%. For organizations managing tight budgets or allocating resources across multiple AI projects, this level of cost clarity supports smarter, data-driven decisions.
Prompts.ai keeps its users ahead of the curve by rapidly integrating new models as they become available. Its architecture is built for agility, ensuring emerging models are added quickly, so users don’t face delays in accessing the latest advancements.
नए मॉडलों के अलावा, प्लेटफ़ॉर्म अपडेट और अनुकूलन भी निर्बाध रूप से पेश करता है। जैसे-जैसे मॉडल में सुधार होता है और नए संस्करण जारी होते हैं, उपयोगकर्ता इन संवर्द्धन तक निर्बाध पहुंच प्रदान करने के लिए Prompts.ai पर भरोसा कर सकते हैं, जिससे वे लगातार विकसित हो रहे एआई परिदृश्य में प्रतिस्पर्धी बने रहने में सक्षम हो सकते हैं।
कृत्रिम विश्लेषण मानकीकृत बेंचमार्क और दोहराने योग्य परीक्षण प्रक्रियाओं के माध्यम से बड़े भाषा मॉडल (एलएलएम) के सुसंगत और गहन मूल्यांकन प्रदान करने पर केंद्रित है। एक व्यवस्थित दृष्टिकोण का पालन करके, प्लेटफ़ॉर्म विभिन्न एलएलएम विभिन्न संज्ञानात्मक कार्यों और व्यावहारिक अनुप्रयोगों में कैसे प्रदर्शन करते हैं, इसकी गहन जानकारी प्रदान करता है।
The platform maintains an extensive database that includes evaluations of both proprietary and open-source LLMs from leading AI developers like OpenAI, Anthropic, Google, Meta, and newer players in the field. It doesn’t stop at mainstream models but also includes specialized and fine-tuned versions, offering users the chance to explore options tailored to unique or niche requirements. This wide-ranging coverage ensures users can access performance data for virtually any model they might consider.
कृत्रिम विश्लेषण कई आयामों में मॉडल का मूल्यांकन करने के लिए डिज़ाइन की गई एक मजबूत इंटेलिजेंस बेंचमार्किंग पद्धति को नियोजित करता है। एकल मीट्रिक पर भरोसा करने के बजाय, प्लेटफ़ॉर्म एक भारित स्कोरिंग प्रणाली का उपयोग करता है जो तर्क, सटीकता, रचनात्मकता और कार्य-विशिष्ट क्षमताओं का आकलन करता है। प्रत्येक मॉडल का मानकीकृत संकेतों और डेटासेट के साथ कठोरता से परीक्षण किया जाता है, और विभिन्न आर्किटेक्चर और आकारों में निष्पक्ष तुलना सुनिश्चित करने के लिए परिणामों को सामान्यीकृत किया जाता है। स्वचालित स्कोरिंग और मानव मूल्यांकन का संयोजन इन आकलनों में गहराई और विश्वसनीयता जोड़ता है।
Keeping up with the rapidly changing LLM landscape, Artificial Analysis frequently updates its methodologies. The most recent update, Version 3.0, was released on 2 सितंबर 2025. These regular updates ensure the platform remains a reliable source of up-to-date, actionable insights, enabling users to make informed decisions when selecting the best language model for their needs.
एलएमएसवाईएस चैटबॉट एरिना एक सहयोगी मंच है जिसे वास्तविक समय की मानवीय प्रतिक्रिया के माध्यम से बड़े भाषा मॉडल (एलएलएम) का आकलन करने के लिए डिज़ाइन किया गया है। यह दृष्टिकोण यह सुनिश्चित करता है कि उपयोगकर्ता इंटरैक्शन और मॉडल में चल रहे सुधार दोनों को कैप्चर करके मूल्यांकन प्रासंगिक बना रहे।
प्लेटफ़ॉर्म मॉडलों के विविध चयन को होस्ट करता है, जिसमें मालिकाना, ओपन-सोर्स और प्रयोगात्मक विकल्प शामिल हैं। यह उपयोगकर्ताओं को परीक्षण और तुलना करने की अनुमति देता है कि विभिन्न मॉडल कार्यों और अनुप्रयोगों की एक विस्तृत श्रृंखला में कैसा प्रदर्शन करते हैं।
पूर्वाग्रह को कम करने के लिए, उपयोगकर्ता मॉडलों के बीच अंधी जोड़ीवार तुलना में संलग्न होते हैं। फिर परिणामों को उनकी संवादी गुणवत्ता, मौलिकता और व्यावहारिक उपयोगिता के आधार पर मॉडलों को रैंक करने के लिए एकत्रित किया जाता है।
लीडरबोर्ड को उपयोगकर्ता की प्रतिक्रिया के साथ लगातार ताज़ा किया जाता है, यह सुनिश्चित करते हुए कि यह नवीनतम मॉडल रिलीज़ और प्रदर्शन रुझानों को दर्शाता है।
वेल्लम एआई लीडरबोर्ड मॉडल प्रदर्शन में कार्रवाई योग्य अंतर्दृष्टि प्रदान करता है, जो विशेष रूप से व्यावहारिक व्यावसायिक अनुप्रयोगों के लिए तैयार किया गया है।
लीडरबोर्ड में उद्यम उपयोग के लिए डिज़ाइन किए गए वाणिज्यिक और ओपन-सोर्स मॉडल का चुनिंदा चयन शामिल है। इनमें लामा 2 और मिस्ट्रल जैसे ओपन-सोर्स विकल्पों के साथ-साथ ओपनएआई, एंथ्रोपिक और गूगल जैसे प्रदाताओं की पेशकश शामिल है।
वेल्लम को जो चीज़ सबसे अलग बनाती है, वह है इसका व्यवसाय-तैयार मॉडल पर ध्यान केंद्रित करना। प्रायोगिक या अप्रमाणित विकल्पों को सूचीबद्ध करने के बजाय, यह उन मॉडलों पर प्रकाश डालता है जिन्होंने विश्वसनीयता प्रदर्शित की है और व्यावसायिक तैनाती के लिए उपयुक्त हैं।
वेल्लम छह प्रमुख श्रेणियों में एक संरचित दृष्टिकोण का उपयोग करके मॉडल का मूल्यांकन करता है: तर्क, कोड पीढ़ी, रचनात्मक लेखन, तथ्यात्मक सटीकता, निर्देशों का पालन और सुरक्षा अनुपालन।
प्रत्येक मॉडल का परीक्षण उन संकेतों के साथ किया जाता है जो वास्तविक दुनिया के व्यावसायिक परिदृश्यों की नकल करते हैं, मानव समीक्षा के साथ स्वचालित स्कोरिंग का संयोजन करते हैं। यह दोहरी-स्तरीय मूल्यांकन यह सुनिश्चित करता है कि परिणाम केवल सैद्धांतिक बेंचमार्क के बजाय व्यावहारिक उपयोगिता को दर्शाते हैं। मूल्यांकन प्रक्रिया के नियमित अपडेट यह सुनिश्चित करते हैं कि लीडरबोर्ड एलएलएम क्षेत्र में नवीनतम विकास के साथ जुड़ा रहे।
प्रमुख मॉडल रिलीज़ के लिए अतिरिक्त अपडेट के साथ, लीडरबोर्ड को मासिक रूप से ताज़ा किया जाता है। यह शेड्यूल बड़े भाषा मॉडलों में तेजी से हो रही प्रगति के साथ अद्यतित रहते हुए संपूर्ण परीक्षण सुनिश्चित करता है।
वेल्लम ऐतिहासिक प्रदर्शन को भी ट्रैक करता है, जिससे उपयोगकर्ताओं को यह समीक्षा करने की अनुमति मिलती है कि समय के साथ मॉडल कैसे विकसित हुए हैं। यह सुविधा व्यवसायों को नए मॉडल अपनाने या मौजूदा मॉडल को अपग्रेड करने के बारे में सूचित निर्णय लेने में मदद करती है।
वेल्लम विस्तृत लागत विवरण प्रदान करता है, जिसमें प्रति 1,000 टोकन का मूल्य निर्धारण और ग्राहक सहायता, सामग्री निर्माण और कोड सहायता जैसे कार्यों के लिए अनुमानित लागत शामिल है।
लाइवबेंच अपने बेंचमार्क प्रश्नों को बार-बार अपडेट करके डेटा संदूषण की चुनौती से निपटता है। यह सुनिश्चित करता है कि मॉडलों का मूल्यांकन ताज़ा सामग्री पर किया जाए, जिससे उन्हें प्रशिक्षण डेटा को याद रखने से रोका जा सके।
लाइवबेंच विभिन्न प्रकार के मॉडलों का समर्थन करता है, जिनमें 0.5 बिलियन पैरामीटर वाले छोटे सिस्टम से लेकर 405 बिलियन पैरामीटर वाले बड़े सिस्टम तक शामिल हैं। इसने 49 विभिन्न बड़े भाषा मॉडल (एलएलएम) का मूल्यांकन किया है, जिसमें प्रमुख स्वामित्व वाले प्लेटफॉर्म, प्रमुख ओपन-सोर्स विकल्प और विशिष्ट विशेष मॉडल शामिल हैं।
The platform’s robust API compatibility allows seamless evaluation of any model with an OpenAI-compatible endpoint. This includes models from providers like Anthropic, Cohere, Mistral, Together, and Google.
As of 9 अक्टूबर 2025, the leaderboard showcases advanced models such as OpenAI's GPT-5 series (High, Medium, Pro, Codex, Mini, o3, o4-Mini), Anthropic's Claude Sonnet 4.5 and Claude 4.1 Opus, Google's Gemini 2.5 Pro and Flash, xAI's Grok 4, DeepSeek V3.1, and Alibaba's Qwen 3 Max.
लाइवबेंच एक संदूषण-प्रतिरोधी पद्धति का उपयोग करता है, जो तर्क, कोडिंग, गणित और भाषा समझ सहित सात श्रेणियों में विभाजित 21 कार्यों में मॉडल का परीक्षण करता है। अपने बेंचमार्क की अखंडता को बनाए रखने के लिए, प्लेटफ़ॉर्म हर छह महीने में सभी प्रश्नों को ताज़ा करता है और समय के साथ अधिक जटिल कार्यों को पेश करता है। उदाहरण के लिए, नवीनतम संस्करण, LiveBench-2025-05-30, ने एक एजेंटिक कोडिंग कार्य जोड़ा है जहां मॉडल को रिपॉजिटरी समस्याओं को हल करने के लिए वास्तविक दुनिया के विकास वातावरण को नेविगेट करना होगा।
मूल्यांकन प्रक्रिया को और अधिक सुरक्षित करने के लिए, हालिया अपडेट से लगभग 300 प्रश्न - कुल का लगभग 30% - अप्रकाशित रहते हैं। यह सुनिश्चित करता है कि मॉडलों को सटीक परीक्षण डेटा पर प्रशिक्षित नहीं किया जा सकता है। नियमित अपडेट के साथ मिलकर ये उपाय बेंचमार्क को प्रासंगिक और चुनौतीपूर्ण बनाए रखते हैं।
लाइवबेंच एक सख्त अपडेट शेड्यूल का पालन करता है, लगातार नए प्रश्न जारी करता है और हर छह महीने में पूरे बेंचमार्क को ताज़ा करता है। उपयोगकर्ता GitHub समस्या सबमिट करके या ईमेल के माध्यम से LiveBench टीम से संपर्क करके नए विकसित मॉडलों के मूल्यांकन का अनुरोध कर सकते हैं। यह अगले निर्धारित अद्यतन की प्रतीक्षा किए बिना उभरते मॉडलों का मूल्यांकन करने की अनुमति देता है। दिसंबर 2024 के हालिया परिवर्धन में क्लाउड-3-5-हाइकु-20241022, क्लाउड-3-5-सॉनेट-20241022, जेमिनी-एक्सप-1114, जीपीटी-4ओ-2024-11-20, ग्रोक-2 और ग्रोक-2-मिनी जैसे मॉडल शामिल हैं।
एलएलएम-स्टेट्स विभिन्न बेंचमार्क से एकत्रित आँकड़ों का विश्लेषण करके बड़े भाषा मॉडल की तुलना करने का डेटा-संचालित तरीका प्रदान करता है। हालाँकि यह मॉडल प्रदर्शन में मूल्यवान अंतर्दृष्टि प्रदान करता है, लेकिन मॉडलों को कैसे वर्गीकृत किया जाता है, उपयोग की जाने वाली मूल्यांकन विधियों, मूल्य निर्धारण विवरण और कितनी बार डेटा अपडेट किया जाता है, जैसी विशिष्ट बातें साझा नहीं की गई हैं। यह सांख्यिकीय दृष्टिकोण पहले की गुणात्मक तुलनाओं के उपयोगी समकक्ष के रूप में कार्य करता है।
ओपनराउटर रैंकिंग भाषा मॉडल के प्रदर्शन का मूल्यांकन करने के लिए एक व्यावहारिक दृष्टिकोण अपनाती है, केवल तकनीकी बेंचमार्क पर निर्भर रहने के बजाय इस पर ध्यान केंद्रित करती है कि मॉडल वास्तविक दुनिया के परिदृश्यों में कैसा प्रदर्शन करते हैं। रोजमर्रा के उपयोग से डेटा एकत्र करके, यह उजागर करता है कि कौन से मॉडल वास्तव में व्यावहारिक अनुप्रयोगों में मूल्य प्रदान करते हैं। वास्तविक दुनिया के मेट्रिक्स पर यह जोर अन्य प्लेटफार्मों द्वारा प्रदान किए गए अधिक विस्तृत तकनीकी मूल्यांकन का पूरक है।
प्लेटफ़ॉर्म में विभिन्न प्रकार के भाषा मॉडल शामिल हैं, जो उनके विशिष्ट अनुप्रयोगों के आधार पर व्यवस्थित हैं। मॉडलों को उनके उपयोग के मामलों के अनुसार वर्गीकृत करके, यह उपयोगकर्ताओं को उन समाधानों को आसानी से पहचानने में मदद करता है जो उनकी विशेष आवश्यकताओं के अनुरूप हैं।
OpenRouter Rankings uses a usage-based evaluation system, considering multiple factors like response quality, efficiency, and cost. These metrics are combined into composite scores that provide a clear picture of each model’s overall effectiveness and value.
मॉडल के प्रदर्शन और उपयोग के रुझान में बदलाव को ध्यान में रखते हुए रैंकिंग नियमित रूप से अपडेट की जाती है, जिससे यह सुनिश्चित होता है कि डेटा प्रासंगिक और अद्यतित बना रहे।
मंच का मुख्य फोकस आर्थिक कारकों पर है। मूल्य निर्धारण और लागत-संबंधी मेट्रिक्स का विश्लेषण करके, यह लागत और प्रदर्शन के बीच संतुलन पर स्पष्टता प्रदान करता है, जिससे उपयोगकर्ताओं को सूचित निर्णय लेने में मदद मिलती है।
हगिंग फेस ओपन एलएलएम लीडरबोर्ड ओपन-सोर्स भाषा मॉडल के प्रदर्शन के मूल्यांकन के लिए एक समर्पित मंच के रूप में खड़ा है। हगिंग फेस द्वारा डिज़ाइन किया गया, यह उन शोधकर्ताओं और डेवलपर्स के लिए एक केंद्रीय संसाधन के रूप में कार्य करता है जो मानकीकृत बेंचमार्क के खिलाफ मॉडल की तुलना करना चाहते हैं। विशेष रूप से ओपन-सोर्स मॉडल पर ध्यान केंद्रित करके, लीडरबोर्ड उन लोगों की जरूरतों के साथ संरेखित होता है जो अपने एआई समाधानों में पारदर्शिता और खुली पहुंच को महत्व देते हैं। यह पहले चर्चा की गई उद्यम और प्रदर्शन-संचालित तुलनाओं का पूरक है, जो ओपन-सोर्स एआई परिदृश्य पर एक अद्वितीय परिप्रेक्ष्य पेश करता है।
लीडरबोर्ड पैरामीटर आकार - 7बी, 13बी, 30बी, और 70बी+ के आधार पर ओपन-सोर्स मॉडल की एक विस्तृत श्रृंखला का आयोजन करता है - जिसमें प्रमुख अनुसंधान संस्थानों के प्रयोगात्मक डिजाइन और बड़े पैमाने पर कार्यान्वयन दोनों शामिल हैं।
इसमें संगठनों और व्यक्तिगत डेवलपर्स का योगदान शामिल है, जो एक विविध और गतिशील पारिस्थितिकी तंत्र को बढ़ावा देता है जो ओपन-सोर्स एआई की वर्तमान स्थिति को दर्शाता है। प्रत्येक मॉडल प्रविष्टि में वास्तुकला, प्रशिक्षण डेटा और लाइसेंसिंग शर्तों पर विस्तृत जानकारी शामिल है, जो उपयोगकर्ताओं को उनकी परियोजना आवश्यकताओं और अनुपालन आवश्यकताओं के आधार पर सूचित विकल्प बनाने में सक्षम बनाती है।
एक मानकीकृत मूल्यांकन ढांचे का उपयोग करते हुए, हगिंग फेस कई बेंचमार्क पर मॉडल का आकलन करता है, उनकी क्षमताओं का गहन विश्लेषण पेश करता है। ये बेंचमार्क तर्क कौशल, ज्ञान प्रतिधारण, गणितीय समस्या-समाधान और पढ़ने की समझ को कवर करते हैं, जिससे प्रत्येक मॉडल के प्रदर्शन का एक पूर्ण दृष्टिकोण सुनिश्चित होता है।
प्लेटफ़ॉर्म सभी मॉडलों में लगातार परीक्षण स्थितियों को बनाए रखने के लिए स्वचालित पाइपलाइनों को नियोजित करता है। यह अलग-अलग वातावरण या कार्यप्रणाली के कारण होने वाली विसंगतियों को दूर करता है, उपयोगकर्ताओं को उनके विशिष्ट उपयोग के मामलों के लिए सबसे उपयुक्त की पहचान करने के लिए विश्वसनीय, सेब-से-सेब तुलना प्रदान करता है।
ओपन-सोर्स समुदाय में उभरते ही लीडरबोर्ड को नए मॉडलों के साथ लगातार अपडेट किया जाता है। इसकी स्वचालित मूल्यांकन प्रक्रिया के लिए धन्यवाद, मैन्युअल हस्तक्षेप के कारण होने वाली देरी के बिना मॉडल का मूल्यांकन और रैंकिंग जल्दी से की जा सकती है।
इसके अतिरिक्त, जब भी बेंचमार्क पद्धतियों को परिष्कृत किया जाता है तो प्लेटफ़ॉर्म मौजूदा मॉडलों का पुनर्मूल्यांकन करता है। यह सुनिश्चित करता है कि पुराने मॉडलों का उचित प्रतिनिधित्व बना रहे, जिससे समय के साथ लीडरबोर्ड की प्रासंगिकता और विश्वसनीयता बनी रहे।
While the leaderboard doesn’t provide direct pricing, it includes key details such as model size, memory requirements, and inference speed. These metrics help users estimate the infrastructure costs involved in deploying each model.
कम्प्यूटेशनल आवश्यकताओं पर यह ध्यान संगठनों को बजट-सचेत निर्णय लेने की अनुमति देता है, विशेष रूप से सीमित संसाधनों या विशिष्ट हार्डवेयर बाधाओं के साथ काम करने वालों को। ओपन-सोर्स मॉडल पर जोर देकर, प्लेटफ़ॉर्म चल रही लाइसेंसिंग फीस को भी समाप्त कर देता है, जिससे स्वामित्व की कुल लागत अधिक अनुमानित हो जाती है और मालिकाना विकल्पों की तुलना में अक्सर अधिक प्रबंधनीय हो जाती है।
स्केल एआई सील लीडरबोर्ड बड़े भाषा मॉडल (एलएलएम) की सुरक्षा, संरेखण और प्रदर्शन का मूल्यांकन करने के लिए समर्पित है, जो एआई को जिम्मेदारी से तैनात करने के बारे में प्रमुख उद्यम चिंताओं को संबोधित करता है। सामान्य प्रयोजन के लीडरबोर्ड के विपरीत, SEAL यह आकलन करने पर ध्यान केंद्रित करता है कि मॉडल संवेदनशील सामग्री को कितनी अच्छी तरह संभालते हैं, नैतिक दिशानिर्देशों का पालन करते हैं और विभिन्न परिदृश्यों में सुसंगत व्यवहार बनाए रखते हैं। यह उद्यम वातावरण में कच्चे प्रदर्शन के साथ-साथ सुरक्षा और नैतिक अनुपालन के महत्व पर प्रकाश डालता है। इसका विशेष दृष्टिकोण मॉडल क्षमताओं, मूल्यांकन विधियों, अद्यतन शेड्यूल और संबंधित लागतों में विस्तृत अंतर्दृष्टि प्रदान करता है।
SEAL मालिकाना और ओपन-सोर्स मॉडल के मिश्रण की समीक्षा करता है, जिसमें आमतौर पर व्यावसायिक अनुप्रयोगों में उपयोग किए जाने वाले मॉडलों पर विशेष ध्यान दिया जाता है। लीडरबोर्ड में जीपीटी-4, क्लाउड और जेमिनी जैसे हाई-प्रोफाइल वाणिज्यिक मॉडल, साथ ही लामा 2 और मिस्ट्रल वेरिएंट जैसे लोकप्रिय ओपन-सोर्स विकल्प शामिल हैं।
SEAL को जो चीज़ अलग करती है वह प्रयोगात्मक या अनुसंधान-केंद्रित संस्करणों के बजाय उद्यम-तैयार मॉडल पर जोर देना है। प्रत्येक मॉडल का परीक्षण विभिन्न पैरामीटर आकारों और सुव्यवस्थित कॉन्फ़िगरेशन में किया जाता है, जिससे इस बात की गहरी समझ मिलती है कि ये विविधताएं सुरक्षा और प्रदर्शन के बीच संतुलन को कैसे प्रभावित करती हैं। प्लेटफ़ॉर्म स्वास्थ्य देखभाल या वित्त जैसे उद्योगों के लिए तैयार किए गए विशेष मॉडल का भी मूल्यांकन करता है, जहां नियामक अनुपालन और जोखिम प्रबंधन महत्वपूर्ण हैं।
SEAL एक संपूर्ण मूल्यांकन ढांचे का उपयोग करता है जो पारंपरिक प्रदर्शन मेट्रिक्स को व्यापक सुरक्षा परीक्षणों के साथ मिश्रित करता है। मॉडलों का मूल्यांकन हानिकारक संकेतों को अस्वीकार करने, तथ्यात्मक सटीकता बनाए रखने और पक्षपातपूर्ण या भेदभावपूर्ण आउटपुट देने से बचने की उनकी क्षमता पर किया जाता है।
मूल्यांकन प्रक्रिया में कमजोरियों और सूक्ष्म पूर्वाग्रहों को उजागर करने के लिए रेड-टीमिंग अभ्यास और मानवीय समीक्षाएं शामिल हैं जिन्हें स्वचालित परीक्षण अनदेखा कर सकता है। स्वचालित और मैन्युअल मूल्यांकन के संयोजन से, SEAL यह सुनिश्चित करता है कि प्रदर्शन मेट्रिक्स के साथ-साथ सुरक्षा संबंधी विचारों को भी समान महत्व दिया जाता है।
SEAL लीडरबोर्ड को त्रैमासिक रूप से अद्यतन किया जाता है, जो इसके मूल्यांकन की विस्तृत और सुरक्षा-केंद्रित प्रकृति को दर्शाता है। प्रत्येक अद्यतन में नए जारी किए गए मॉडल शामिल होते हैं और विकसित हो रहे सुरक्षा मानकों और मानकों के अनुसार मौजूदा मॉडलों का पुनर्मूल्यांकन किया जाता है।
इन निर्धारित अद्यतनों के अलावा, स्केल एआई अंतरिम रिपोर्ट जारी करता है जब एआई समुदाय के भीतर महत्वपूर्ण मॉडल अपडेट या सुरक्षा-संबंधी घटनाएं होती हैं। यह अनुकूली दृष्टिकोण सुनिश्चित करता है कि एंटरप्राइज़ उपयोगकर्ताओं के पास नवीनतम सुरक्षा आकलन तक समय पर पहुंच हो, जो मॉडल प्रगति की तीव्र गति को देखते हुए विशेष रूप से महत्वपूर्ण है। ये नियमित अपडेट परिनियोजन लागत का विश्लेषण करने के लिए मूल्यवान डेटा भी प्रदान करते हैं।
While SEAL doesn’t disclose direct pricing, it offers insights into the total cost of ownership, including factors like content moderation, compliance requirements, and liability risks. This helps enterprises weigh the costs of safety measures against operational expenses.
प्लेटफ़ॉर्म विभिन्न सुरक्षा कॉन्फ़िगरेशन के लिए बुनियादी ढांचे की ज़रूरतों पर मार्गदर्शन भी प्रदान करता है, जिससे संगठनों को बढ़ी हुई सुरक्षा और परिचालन लागत के बीच व्यापार-बंद को समझने में मदद मिलती है। एंटरप्राइज़ उपयोगकर्ताओं के लिए, SEAL मजबूत अंतर्निहित सुरक्षा सुविधाओं के साथ मॉडल तैनात करते समय कम सामग्री मॉडरेशन प्रयासों से संभावित बचत का अनुमान लगाता है।
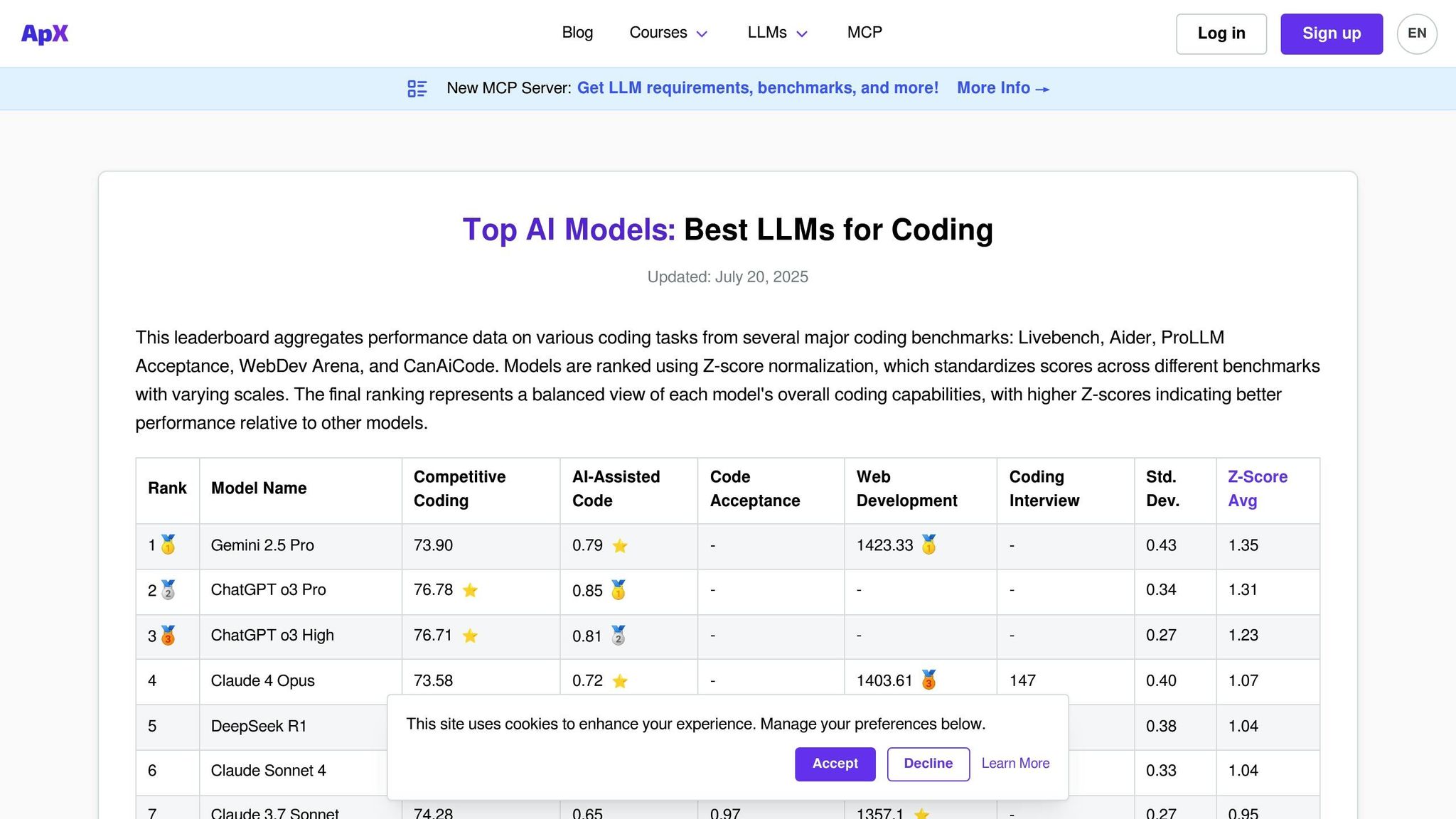
APX कोडिंग एलएलएम एक प्लेटफ़ॉर्म है जिसे विशेष रूप से भाषा मॉडल की कोडिंग क्षमताओं का मूल्यांकन करने के लिए डिज़ाइन किया गया है। सामान्य-उद्देश्य वाले लीडरबोर्ड के विपरीत, जो वार्तालाप कौशल की एक विस्तृत श्रृंखला पर ध्यान केंद्रित करते हैं, एपीएक्स कोड जनरेशन, डिबगिंग, एल्गोरिदम कार्यान्वयन और तकनीकी समस्याओं को हल करने जैसे क्षेत्रों पर ध्यान केंद्रित करता है। यह फोकस इसे डेवलपर्स, इंजीनियरिंग टीमों और संगठनों के लिए एक आवश्यक उपकरण बनाता है, जिनका लक्ष्य एआई-संचालित कोडिंग सहायकों को अपने वर्कफ़्लो में एकीकृत करना है।
प्लेटफ़ॉर्म मूल्यांकन करता है कि मॉडल विभिन्न भाषाओं और रूपरेखाओं में व्यावहारिक प्रोग्रामिंग चुनौतियों को कैसे संभालते हैं। अन्य मूल्यांकन प्लेटफार्मों के समान, एपीएक्स मूल्यांकन प्रक्रिया को सरल बनाता है लेकिन कोड प्रदर्शन और सुरक्षा पर गहरा ध्यान देता है।
एपीएक्स में कोडिंग विशेषज्ञता के लिए परीक्षण किए गए वाणिज्यिक और ओपन-सोर्स मॉडल दोनों की एक विस्तृत लाइनअप है। प्लेटफ़ॉर्म नियमित रूप से प्रसिद्ध कोडिंग मॉडल जैसे GitHub Copilot के अंतर्निहित GPT मॉडल, CodeT5, StarCoder और Code Llama वेरिएंट का मूल्यांकन करता है। इसमें GPT-4, क्लाउड और जेमिनी जैसी मजबूत प्रोग्रामिंग क्षमताओं वाले सामान्य-उद्देश्य वाले मॉडल भी शामिल हैं।
APX के लिए एक मुख्य विभेदक विशेष कोडिंग मॉडल का समावेश है जो व्यापक लीडरबोर्ड पर दिखाई नहीं दे सकता है लेकिन विशिष्ट प्रोग्रामिंग क्षेत्रों में उत्कृष्टता प्राप्त कर सकता है। इन मॉडलों का परीक्षण विभिन्न पैरामीटर आकारों और सुव्यवस्थित संस्करणों में किया जाता है, जिसमें पायथन, जावास्क्रिप्ट, जावा, सी ++, रस्ट और गो जैसी भाषाओं के लिए डोमेन-विशिष्ट वेरिएंट शामिल हैं। प्लेटफ़ॉर्म रिएक्ट, Django, TensorFlow और PyTorch जैसे फ्रेमवर्क के साथ प्रदर्शन का मूल्यांकन भी करता है।
यह व्यापक कवरेज सुनिश्चित करता है कि APX वास्तविक दुनिया की कोडिंग आवश्यकताओं के लिए कठोर और व्यावहारिक परीक्षण प्रदान करता है।
APX वास्तविक दुनिया के कोडिंग परिदृश्यों के अनुरूप एक विस्तृत परीक्षण ढाँचा नियोजित करता है। यह स्वचालित परीक्षणों और विशेषज्ञ समीक्षाओं के संयोजन के माध्यम से कोड की शुद्धता, दक्षता, पठनीयता और सुरक्षा मानकों के पालन जैसे पहलुओं पर मॉडल का मूल्यांकन करता है।
परीक्षण परिदृश्यों में एल्गोरिथम चुनौतियाँ, त्रुटिपूर्ण कोड को डीबग करना, रीफैक्टरिंग कार्य और दस्तावेज़ तैयार करना शामिल हैं। मॉडलों का मूल्यांकन जटिल कोड अवधारणाओं को समझाने और अनुकूलन का सुझाव देने की उनकी क्षमता के लिए भी किया जाता है।
Incorporating industry-standard coding practices, APX evaluates whether models follow established conventions for naming, commenting, and structuring code. Additionally, it tests the models’ ability to recognize and avoid common security vulnerabilities, making it especially valuable for enterprises where secure coding is a priority.
एआई कोडिंग टूल के तेजी से विकसित हो रहे परिदृश्य के साथ तालमेल बनाए रखने के लिए APX लीडरबोर्ड को मासिक रूप से अपडेट किया जाता है। अपडेट में नए जारी किए गए मॉडलों को शामिल करना और मौजूदा मॉडलों का पुनर्मूल्यांकन करना, नवीनतम प्रोग्रामिंग चुनौतियों और मानकों के साथ संरेखण सुनिश्चित करना शामिल है।
प्लेटफ़ॉर्म महत्वपूर्ण मॉडल अपडेट के लिए वास्तविक समय प्रदर्शन ट्रैकिंग भी प्रदान करता है, जिससे डेवलपर्स को नवीनतम क्षमताओं तक तत्काल पहुंच मिलती है। जब प्रमुख कोडिंग-केंद्रित मॉडल लॉन्च किए जाते हैं, तो एपीएक्स उनके प्रदर्शन में समय पर अंतर्दृष्टि प्रदान करने के लिए विशेष मूल्यांकन चक्र आयोजित करता है।
एपीएक्स विशेष रूप से कोडिंग कार्यों के लिए तैयार किए गए लागत-प्रति-टोकन विश्लेषण का विस्तृत विवरण प्रदान करता है। यह विश्लेषण उपयोगकर्ताओं को विभिन्न उपयोग के मामलों के लिए विभिन्न मॉडलों के लागत निहितार्थ को समझने में मदद करता है। प्रोग्रामिंग भाषा और कार्य जटिलता के आधार पर लागतों को विभाजित किया जाता है, जिससे यह स्पष्ट जानकारी मिलती है कि कौन से मॉडल सर्वोत्तम मूल्य प्रदान करते हैं।
लागत विश्लेषण विशिष्ट कोडिंग कार्यों के दौरान एपीआई कॉल आवृत्ति, टोकन उपयोग पैटर्न और कम डिबगिंग समय से संभावित बचत जैसे कारकों पर विचार करता है। एपीएक्स एआई कोडिंग सहायकों को अपनाने वाली टीमों के लिए स्वामित्व की कुल लागत का भी अनुमान लगाता है, जो सदस्यता और उपयोग शुल्क के मुकाबले उत्पादकता लाभ का वजन करता है। विवरण का यह स्तर एपीएक्स को एआई-संचालित कोडिंग समाधानों के वित्तीय प्रभाव का आकलन करने के लिए एक मूल्यवान संसाधन बनाता है।
बड़े भाषा मॉडल (एलएलएम) के लिए साथ-साथ तुलना प्लेटफ़ॉर्म विभिन्न प्रकार की ज़रूरतों को पूरा करते हैं। Prompts.ai लागत प्रबंधन और शासन सुनिश्चित करने के लिए केंद्रीकृत उपकरणों के साथ 35 से अधिक शीर्ष स्तरीय मॉडलों तक पहुंच प्रदान करके खड़ा है। यह इसे बड़े संगठनों के लिए एक मजबूत विकल्प बनाता है जिन्हें मजबूत निरीक्षण के साथ सुरक्षित और अनुपालन कार्यप्रवाह की आवश्यकता होती है।
जबकि Prompts.ai लागत प्रबंधन और शासन पर जोर देता है, अन्य प्लेटफ़ॉर्म विभिन्न प्राथमिकताओं पर ध्यान केंद्रित करते हैं। इनमें समुदाय-संचालित फीडबैक, तकनीकी बेंचमार्क या सुरक्षा और संरेखण जैसे विशेष मेट्रिक्स शामिल हो सकते हैं। ये प्लेटफ़ॉर्म अपने मॉडल चयन, मूल्यांकन विधियों, अपडेट शेड्यूल और मूल्य निर्धारण में पारदर्शिता में भिन्न हैं।
This summary complements earlier in-depth analyses, helping you identify the tools that best fit your goals. Whether your focus is budget, technical depth, or specific use cases, it’s worth noting that many organizations rely on a mix of platforms to achieve a well-rounded understanding of both technical and business needs.
When evaluating platforms for large language model (LLM) comparison, the best choice ultimately hinges on balancing factors like cost, performance, and compliance. The decision should align with your organization’s specific needs, technical capabilities, and workflow demands.
For enterprises seeking a unified AI orchestration solution, Prompts.ai offers a compelling option. With access to over 35 leading LLMs, integrated cost management tools, and enterprise-grade governance controls, it’s designed to simplify operations for organizations overseeing multiple teams and complex projects.
That said, the LLM platform landscape is diverse, and there’s no universal solution that fits every scenario. Many organizations adopt a mix of tools to address both research and production requirements. By focusing on your primary goals - whether it’s reducing costs, enhancing performance, or ensuring compliance - you can refine your platform selection process and streamline AI implementation.
सही ऑर्केस्ट्रेशन और तुलना उपकरण चुनने से आपकी एआई पहल में मापने योग्य सुधार हो सकते हैं और सार्थक व्यावसायिक परिणाम मिल सकते हैं।
Prompts.ai उनके प्रदर्शन, स्केलेबिलिटी और लागत-दक्षता में स्पष्ट, कार्रवाई योग्य अंतर्दृष्टि प्रदान करके कई बड़े भाषा मॉडल (एलएलएम) का मूल्यांकन करने की चुनौती को सरल बनाता है। यह उपयोगकर्ताओं को बजट के भीतर रहते हुए उनकी आवश्यकताओं के लिए सबसे उपयुक्त मॉडल का चयन करके सूचित विकल्प चुनने का अधिकार देता है।
लागत और प्रदर्शन के बीच संतुलन के साथ-साथ परिचालन दक्षता का आकलन करने के लिए डिज़ाइन किए गए टूल के साथ, Prompts.ai यह सुनिश्चित करता है कि व्यवसाय अनावश्यक खर्चों को दूर कर सकते हैं और अपनी अनूठी आवश्यकताओं के अनुरूप सबसे प्रभावी समाधान लागू करने पर ध्यान केंद्रित कर सकते हैं।
बड़े भाषा मॉडल (एलएलएम) के लिए तुलनाओं को अनुकूलित करने के लिए उपकरण प्रदान करने वाले प्लेटफ़ॉर्म अमूल्य हैं क्योंकि वे उपयोगकर्ताओं को उनके अद्वितीय लक्ष्यों से मेल खाने के लिए मूल्यांकन को बेहतर बनाने की सुविधा देते हैं। प्रदर्शन, सुविधाओं और व्यावहारिक अनुप्रयोगों जैसे महत्वपूर्ण पहलुओं पर ध्यान देकर, ये उपकरण अनुमान लगाने में कटौती करते हुए, सबसे उपयुक्त मॉडल की पहचान करने की प्रक्रिया को सरल बनाते हैं।
ये तुलना उपकरण अधिक विस्तृत बेंचमार्किंग भी प्रदान करते हैं, शोधकर्ताओं, डेवलपर्स और व्यवसायों के लिए मूल्यवान अंतर्दृष्टि प्रदान करते हैं। चाहे आप किसी विशिष्ट कार्य के लिए समाधान को परिष्कृत कर रहे हों या कई विकल्पों पर विचार कर रहे हों, ये प्लेटफ़ॉर्म निर्णय लेने को तेज़ और अधिक प्रभावी बनाते हैं।
एआई प्लेटफार्मों में सटीकता, निर्भरता और विश्वसनीयता बनाए रखने के लिए मूल्यांकन विधियों और मॉडल डेटाबेस को नियमित रूप से अपडेट करना आवश्यक है। ये अपडेट ताज़ा डेटा को शामिल करके, रुझानों को अपनाकर और नए उपयोग के मामलों को संबोधित करके मॉडलों को वर्तमान में बने रहने में सक्षम बनाते हैं, जिससे अंततः प्रदर्शन और निर्णय लेने की क्षमता में वृद्धि होती है।
कार्यप्रणाली के लगातार परिशोधन से प्लेटफार्मों को पूर्वाग्रहों से निपटने, मॉडल अनुकूलनशीलता में सुधार करने और बदलते उद्योग मानकों को पूरा करने की अनुमति मिलती है। प्रगति के प्रति यह समर्पण सुनिश्चित करता है कि एआई समाधान कुशल, अनुपालनशील और तेजी से आगे बढ़ने वाले वातावरण में उपयोगकर्ता की जरूरतों को पूरा करने के लिए सुसज्जित रहें।



















