Paiement à l'Usage - AI Model Orchestration and Workflows Platform

Dans un paysage d’IA encombré, choisir le bon grand modèle de langage (LLM) peut s’avérer une tâche difficile. Avec des modèles comme GPT-5, Claude et Gemini excellant dans différents domaines, les plateformes de comparaison simplifient le processus de prise de décision en proposant des analyses côte à côte des performances, des coûts et des cas d'utilisation. Voici ce que vous devez savoir :
Ces plates-formes répondent à différents besoins, qu'il s'agisse d'optimiser les coûts, d'assurer la sécurité ou d'évaluer les capacités de codage. Vous trouverez ci-dessous une comparaison rapide pour vous aider à décider.
Le choix de la bonne plateforme dépend de vos objectifs, qu'il s'agisse de réduire les coûts, de garantir le respect des règles de sécurité ou d'améliorer la productivité. Des plates-formes telles que Prompts.ai se démarquent pour les entreprises gérant plusieurs LLM, tandis que les LLM APX Coding sont parfaites pour les développeurs. Chaque outil offre une perspective unique pour guider votre stratégie d'IA.
Prompts.ai est une plateforme d'IA d'entreprise conçue pour simplifier le processus de comparaison et de déploiement de grands modèles linguistiques (LLM). En consolidant plus de 35 LLM de premier plan dans un tableau de bord unique et unifié, la plateforme élimine le besoin de jongler avec plusieurs outils. Cette configuration rationalisée réduit non seulement la complexité, mais permet également aux équipes de prendre des décisions éclairées en comparant les modèles sur les performances, les coûts et la vitesse d'intégration, le tout en un seul endroit.
Prompts.ai offre l'accès à une large gamme de modèles d'IA de pointe, notamment GPT-5, Claude, LLaMA, Gemini, Grok-4, Flux Pro et Kling, entre autres. Cette vaste bibliothèque permet aux utilisateurs d'évaluer des modèles avec différentes forces et spécialités sans avoir à changer de plate-forme ou à gérer plusieurs clés API.
The platform's ability to aggregate these models ensures users can evaluate them based on real-world applications. Whether it’s testing coding efficiency, creative writing skills, or expertise in specific domains, the side-by-side comparison feature enables simultaneous testing of identical prompts across multiple models.
Prompts.ai adopte une approche axée sur l'utilisateur pour l'évaluation des modèles, offrant une flexibilité qui va au-delà des références génériques. Au lieu de s'appuyer sur des mesures prédéfinies, les utilisateurs peuvent créer des scénarios d'évaluation personnalisés adaptés à leurs besoins uniques, en utilisant leurs propres invites et données.
The platform’s interface displays results side by side, offering a clear view of output quality, response times, and methodologies. This approach is especially beneficial for businesses that need to test models against proprietary datasets or industry-specific challenges that standard benchmarks fail to address.
Prompts.ai intègre une couche FinOps qui fournit un suivi en temps réel de l'utilisation des jetons sur tous les modèles. En surveillant la consommation de jetons, les équipes peuvent comparer directement les performances et les implications financières, ce qui facilite l'évaluation des modèles offrant la meilleure valeur.
The platform’s Pay-As-You-Go TOKN credit system ensures that costs align with actual usage, potentially reducing expenses by up to 98%. For organizations managing tight budgets or allocating resources across multiple AI projects, this level of cost clarity supports smarter, data-driven decisions.
Prompts.ai keeps its users ahead of the curve by rapidly integrating new models as they become available. Its architecture is built for agility, ensuring emerging models are added quickly, so users don’t face delays in accessing the latest advancements.
Au-delà des nouveaux modèles, la plateforme déploie également des mises à jour et des optimisations de manière transparente. À mesure que les modèles s'améliorent et que de nouvelles versions sont publiées, les utilisateurs peuvent compter sur Prompts.ai pour fournir un accès ininterrompu à ces améliorations, leur permettant ainsi de rester compétitifs dans un paysage de l'IA en constante évolution.
L'analyse artificielle se concentre sur la fourniture d'évaluations cohérentes et approfondies de grands modèles de langage (LLM) via des références standardisées et des processus de test reproductibles. En adhérant à une approche systématique, la plateforme fournit des informations approfondies sur la façon dont les différents LLM fonctionnent dans une variété de tâches cognitives et d'applications pratiques.
The platform maintains an extensive database that includes evaluations of both proprietary and open-source LLMs from leading AI developers like OpenAI, Anthropic, Google, Meta, and newer players in the field. It doesn’t stop at mainstream models but also includes specialized and fine-tuned versions, offering users the chance to explore options tailored to unique or niche requirements. This wide-ranging coverage ensures users can access performance data for virtually any model they might consider.
L'analyse artificielle utilise une méthodologie robuste d'analyse comparative de l'intelligence conçue pour évaluer les modèles sur plusieurs dimensions. Au lieu de s'appuyer sur une seule mesure, la plateforme utilise un système de notation pondéré qui évalue le raisonnement, l'exactitude, la créativité et les capacités spécifiques à une tâche. Chaque modèle est rigoureusement testé avec des invites et des ensembles de données standardisés, et les résultats sont normalisés pour garantir des comparaisons équitables entre différentes architectures et tailles. Une combinaison de notation automatisée et d'évaluations humaines ajoute de la profondeur et de la fiabilité à ces évaluations.
Pour suivre l'évolution rapide du paysage LLM, Artificial Analysis met fréquemment à jour ses méthodologies. La mise à jour la plus récente, la version 3.0, a été publiée le 2 septembre 2025. Ces mises à jour régulières garantissent que la plateforme reste une source fiable d'informations à jour et exploitables, permettant aux utilisateurs de prendre des décisions éclairées lors de la sélection du modèle linguistique le mieux adapté à leurs besoins.
LMSYS Chatbot Arena est une plateforme collaborative conçue pour évaluer les grands modèles de langage (LLM) grâce à des commentaires humains en temps réel. Cette approche garantit que les évaluations restent pertinentes en capturant à la fois les interactions des utilisateurs et les améliorations continues des modèles.
La plate-forme héberge une sélection diversifiée de modèles, notamment des options propriétaires, open source et expérimentales. Cela permet aux utilisateurs de tester et de comparer les performances de différents modèles sur un large éventail de tâches et d'applications.
Pour minimiser les biais, les utilisateurs effectuent des comparaisons aveugles par paires entre les modèles. Les résultats sont ensuite regroupés pour classer les modèles en fonction de leur qualité conversationnelle, de leur originalité et de leur utilité pratique.
Le classement est continuellement actualisé avec les commentaires des utilisateurs, garantissant qu'il reflète les dernières versions de modèles et les tendances en matière de performances.
Le classement Vellum AI offre des informations exploitables sur les performances des modèles, spécialement adaptées aux applications métiers pratiques.
Le classement présente une sélection triée sur le volet de modèles commerciaux et open source conçus pour une utilisation en entreprise. Celles-ci incluent des offres de fournisseurs comme OpenAI, Anthropic et Google, ainsi que des options open source telles que Llama 2 et Mistral.
Ce qui distingue Vellum, c'est l'accent mis sur des modèles prêts à l'emploi. Au lieu de répertorier les options expérimentales ou non éprouvées, il met en évidence les modèles qui ont démontré leur fiabilité et sont adaptés à un déploiement commercial.
Vellum évalue les modèles à l'aide d'une approche structurée dans six catégories clés : raisonnement, génération de code, écriture créative, exactitude factuelle, suivi des instructions et conformité en matière de sécurité.
Chaque modèle est testé avec des invites qui imitent des scénarios commerciaux réels, combinant une notation automatisée et un examen humain. Cette évaluation à deux niveaux garantit que les résultats reflètent une utilisation pratique plutôt que de simples références théoriques. Des mises à jour régulières du processus d'évaluation garantissent que le classement reste aligné sur les derniers développements dans l'espace LLM.
Le classement est actualisé mensuellement, avec des mises à jour supplémentaires pour les versions majeures des modèles. Ce calendrier garantit des tests approfondis tout en restant à jour avec les progrès rapides des grands modèles de langage.
Vellum suit également les performances historiques, permettant aux utilisateurs de voir comment les modèles ont évolué au fil du temps. Cette fonctionnalité aide les entreprises à prendre des décisions éclairées quant au moment d'adopter de nouveaux modèles ou de mettre à niveau ceux existants.
Vellum fournit une ventilation détaillée des coûts, y compris la tarification pour 1 000 jetons et les coûts estimés pour des tâches telles que le support client, la création de contenu et l'assistance au code.
LiveBench relève le défi de la contamination des données en mettant fréquemment à jour ses questions de référence. Cela garantit que les modèles sont évalués sur du nouveau matériel, les empêchant de simplement mémoriser les données d'entraînement.
LiveBench prend en charge une grande variété de modèles, allant des systèmes plus petits dotés de 0,5 milliard de paramètres aux systèmes massifs dotés de 405 milliards de paramètres. Il a évalué 49 grands modèles de langage (LLM) différents, y compris les principales plates-formes propriétaires, les principales alternatives open source et les modèles spécialisés de niche.
The platform’s robust API compatibility allows seamless evaluation of any model with an OpenAI-compatible endpoint. This includes models from providers like Anthropic, Cohere, Mistral, Together, and Google.
Depuis le 9 octobre 2025, le classement présente des modèles avancés tels que la série GPT-5 d'OpenAI (High, Medium, Pro, Codex, Mini, o3, o4-Mini), Claude Sonnet 4.5 et Claude 4.1 Opus d'Anthropic, Gemini 2.5 Pro et Flash de Google, Grok 4 de xAI, DeepSeek V3.1 et Qwen 3 Max d'Alibaba.
LiveBench utilise une méthodologie résistante à la contamination et teste des modèles sur 21 tâches divisées en sept catégories, notamment le raisonnement, le codage, les mathématiques et la compréhension du langage. Pour maintenir l'intégrité de ses benchmarks, la plateforme actualise toutes les questions tous les six mois et introduit des tâches plus complexes au fil du temps. Par exemple, la dernière version, LiveBench-2025-05-30, a ajouté une tâche de codage agent dans laquelle les modèles doivent naviguer dans des environnements de développement réels pour résoudre les problèmes de référentiel.
Afin de sécuriser davantage le processus d'évaluation, environ 300 questions issues de mises à jour récentes - soit environ 30 % du total - restent inédites. Cela garantit que les modèles ne peuvent pas être formés sur les données de test exactes. Ces mesures, combinées à des mises à jour régulières, maintiennent l'évaluation pertinente et stimulante.
LiveBench suit un calendrier de mise à jour strict, publiant régulièrement de nouvelles questions et actualisant l'intégralité du benchmark tous les six mois. Les utilisateurs peuvent demander des évaluations pour les modèles nouvellement développés en soumettant un problème GitHub ou en contactant l'équipe LiveBench par e-mail. Cela permet d’évaluer les modèles émergents sans attendre la prochaine mise à jour programmée. Les ajouts récents de décembre 2024 incluent des modèles comme claude-3-5-haiku-20241022, claude-3-5-sonnet-20241022, gemini-exp-1114, gpt-4o-2024-11-20, grok-2 et grok-2-mini.
LLM-Stats fournit un moyen basé sur les données pour comparer de grands modèles de langage en analysant les statistiques agrégées à partir d'une variété de références. Bien qu'il offre des informations précieuses sur les performances des modèles, des détails tels que la façon dont les modèles sont catégorisés, les méthodes d'évaluation utilisées, les détails des prix et la fréquence de mise à jour des données n'ont pas été partagés. Cette approche statistique constitue une contrepartie utile aux comparaisons qualitatives antérieures.
OpenRouter Rankings adopte une approche pratique pour évaluer les performances des modèles de langage, en se concentrant sur la manière dont les modèles fonctionnent dans des scénarios réels plutôt que de s'appuyer uniquement sur des références techniques. En regroupant les données d'utilisation quotidienne, il met en évidence quels modèles apportent réellement de la valeur dans des applications pratiques. Cet accent mis sur les mesures du monde réel complète les évaluations techniques plus détaillées fournies par d'autres plateformes.
La plateforme comprend une variété de modèles de langage, organisés en fonction de leurs applications spécifiques. En catégorisant les modèles en fonction de leurs cas d'utilisation, il aide les utilisateurs à identifier facilement les solutions qui correspondent à leurs besoins particuliers.
OpenRouter Rankings uses a usage-based evaluation system, considering multiple factors like response quality, efficiency, and cost. These metrics are combined into composite scores that provide a clear picture of each model’s overall effectiveness and value.
Les classements sont régulièrement mis à jour pour tenir compte des changements dans les performances des modèles et des tendances d'utilisation, garantissant ainsi que les données restent pertinentes et à jour.
La plate-forme se concentre principalement sur les facteurs économiques. En analysant les prix et les mesures liées aux coûts, il clarifie l'équilibre entre coût et performances, aidant ainsi les utilisateurs à prendre des décisions éclairées.
Le classement Hugging Face Open LLM se distingue comme une plateforme dédiée à l'évaluation des performances des modèles de langage open source. Conçu par Hugging Face, il constitue une ressource centrale pour les chercheurs et les développeurs cherchant à comparer des modèles à des références standardisées. En se concentrant exclusivement sur les modèles open source, le classement s'aligne sur les besoins de ceux qui valorisent la transparence et l'accessibilité ouverte dans leurs solutions d'IA. Il complète les comparaisons d’entreprise et axées sur les performances évoquées précédemment, offrant une perspective unique sur le paysage de l’IA open source.
Le classement organise une large gamme de modèles open source par taille de paramètre (7B, 13B, 30B et 70B+) couvrant à la fois les conceptions expérimentales et les implémentations à grande échelle des principaux instituts de recherche.
Il présente les contributions d'organisations et de développeurs individuels, favorisant un écosystème diversifié et dynamique qui reflète l'état actuel de l'IA open source. Chaque entrée de modèle comprend des informations détaillées sur l'architecture, les données de formation et les conditions de licence, permettant aux utilisateurs de faire des choix éclairés en fonction des besoins de leur projet et des exigences de conformité.
À l'aide d'un cadre d'évaluation standardisé, Hugging Face évalue les modèles sur plusieurs critères, offrant une analyse approfondie de leurs capacités. Ces critères couvrent les compétences de raisonnement, la rétention des connaissances, la résolution de problèmes mathématiques et la compréhension en lecture, garantissant une vue complète des performances de chaque modèle.
La plateforme utilise des pipelines automatisés pour maintenir des conditions de test cohérentes sur tous les modèles. Cela élimine les écarts causés par des environnements ou des méthodologies variables, offrant ainsi aux utilisateurs des comparaisons fiables de pommes à pommes pour identifier la meilleure solution pour leurs cas d'utilisation spécifiques.
Le classement est continuellement mis à jour avec de nouveaux modèles à mesure qu'ils émergent dans la communauté open source. Grâce à son processus d'évaluation automatisé, les modèles peuvent être évalués et classés rapidement sans retards causés par une intervention manuelle.
De plus, la plateforme réévalue les modèles existants chaque fois que les méthodologies de référence sont affinées. Cela garantit que les modèles plus anciens restent équitablement représentés, conservant ainsi la pertinence et la fiabilité du classement au fil du temps.
While the leaderboard doesn’t provide direct pricing, it includes key details such as model size, memory requirements, and inference speed. These metrics help users estimate the infrastructure costs involved in deploying each model.
Cette focalisation sur les exigences informatiques permet aux organisations de prendre des décisions soucieuses de leur budget, en particulier celles qui travaillent avec des ressources limitées ou des contraintes matérielles spécifiques. En mettant l'accent sur les modèles open source, la plateforme élimine également les frais de licence permanents, ce qui rend le coût total de possession plus prévisible et souvent plus gérable par rapport aux alternatives propriétaires.
Le classement Scale AI SEAL est dédié à l’évaluation de la sécurité, de l’alignement et des performances des grands modèles de langage (LLM), répondant ainsi aux principales préoccupations des entreprises concernant le déploiement responsable de l’IA. Contrairement aux classements à usage général, SEAL se concentre sur l’évaluation de la manière dont les modèles gèrent le contenu sensible, respectent les directives éthiques et maintiennent un comportement cohérent dans divers scénarios. Cela met en évidence l’importance de la sécurité et du respect de l’éthique ainsi que de la performance brute dans les environnements d’entreprise. Son approche spécialisée fournit des informations détaillées sur les capacités du modèle, les méthodes d'évaluation, les calendriers de mise à jour et les coûts associés.
SEAL examine un mélange de modèles propriétaires et open source, en mettant l'accent sur ceux couramment utilisés dans les applications professionnelles. Le classement comprend des modèles commerciaux de haut niveau comme GPT-4, Claude et Gemini, ainsi que des options open source populaires telles que les variantes Llama 2 et Mistral.
Ce qui distingue SEAL, c'est l'accent mis sur des modèles prêts à l'emploi plutôt que sur des versions expérimentales ou axées sur la recherche. Chaque modèle est testé sur différentes tailles de paramètres et configurations affinées, offrant une compréhension plus approfondie de l'impact de ces variations sur l'équilibre entre sécurité et performances. La plateforme évalue également des modèles spécialisés adaptés à des secteurs tels que la santé ou la finance, où la conformité réglementaire et la gestion des risques sont essentielles.
SEAL utilise un cadre d'évaluation approfondi qui combine des mesures de performance traditionnelles avec des tests de sécurité approfondis. Les modèles sont évalués en fonction de leur capacité à rejeter les invites nuisibles, à maintenir l’exactitude factuelle et à éviter de produire des résultats biaisés ou discriminatoires.
Le processus d'évaluation comprend des exercices d'équipe rouge et des examens humains pour découvrir les vulnérabilités et les biais subtils que les tests automatisés pourraient ignorer. En combinant des évaluations automatisées et manuelles, SEAL garantit que les considérations de sécurité ont le même poids que les mesures de performance.
Le classement SEAL est mis à jour tous les trimestres, reflétant la nature détaillée et centrée sur la sécurité de ses évaluations. Chaque mise à jour intègre des modèles nouvellement publiés et réévalue ceux existants par rapport à l'évolution des références et des normes de sécurité.
En plus de ces mises à jour programmées, Scale AI publie des rapports intermédiaires lorsque des mises à jour importantes du modèle ou des incidents liés à la sécurité se produisent au sein de la communauté IA. Cette approche adaptative garantit que les utilisateurs de l'entreprise ont accès en temps opportun aux dernières évaluations de sécurité, ce qui est particulièrement important compte tenu du rythme rapide des progrès des modèles. Ces mises à jour régulières fournissent également des données précieuses pour analyser les coûts de déploiement.
While SEAL doesn’t disclose direct pricing, it offers insights into the total cost of ownership, including factors like content moderation, compliance requirements, and liability risks. This helps enterprises weigh the costs of safety measures against operational expenses.
La plateforme fournit également des conseils sur les besoins en infrastructure pour diverses configurations de sécurité, aidant ainsi les organisations à comprendre les compromis entre une sécurité renforcée et les coûts opérationnels. Pour les utilisateurs d'entreprise, SEAL estime les économies potentielles résultant de la réduction des efforts de modération du contenu lors du déploiement de modèles dotés de fonctionnalités de sécurité intégrées robustes.
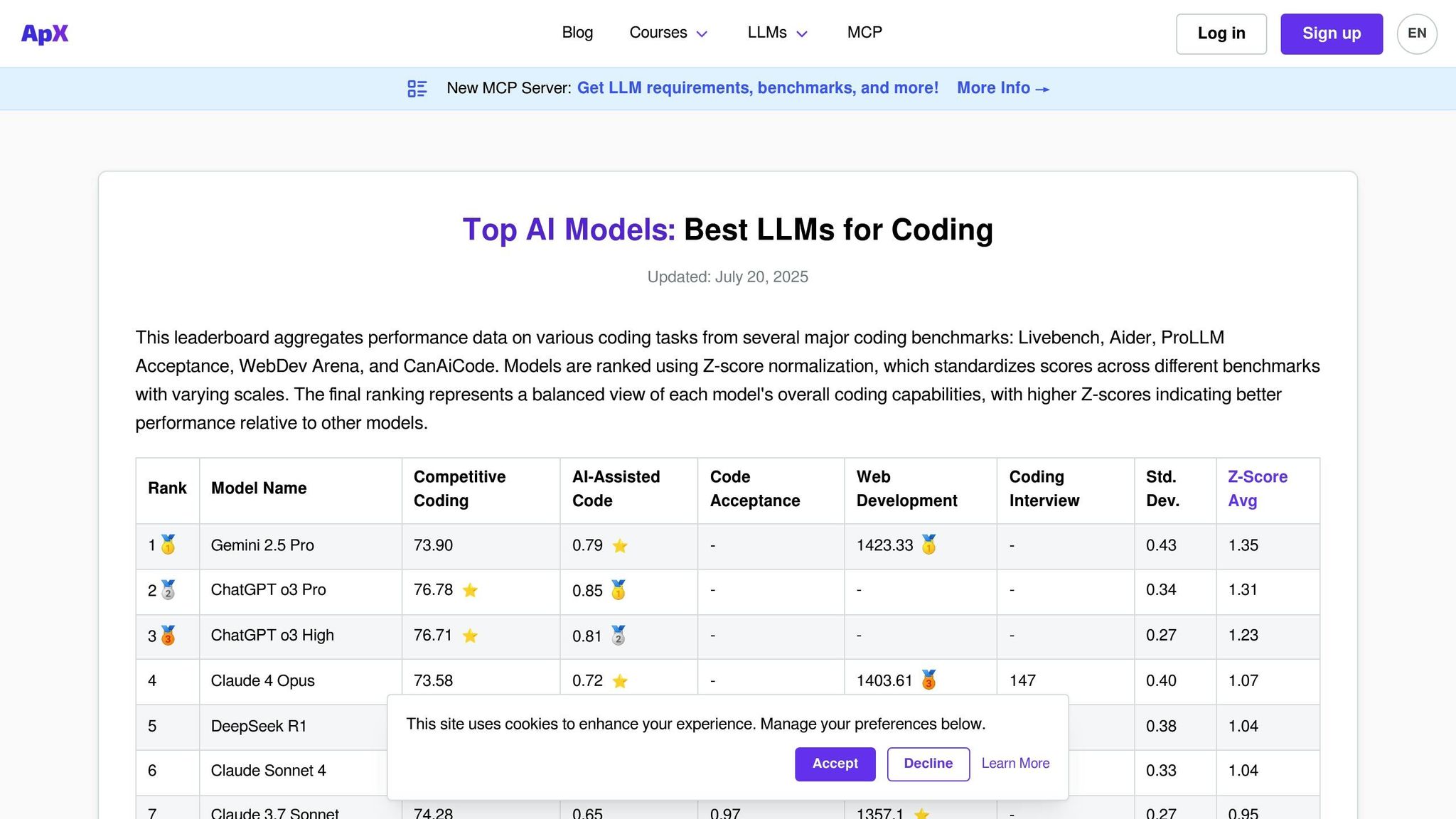
APX Coding LLMs est une plateforme conçue spécifiquement pour évaluer les capacités de codage des modèles de langage. Contrairement aux classements à usage général qui se concentrent sur un large éventail de compétences conversationnelles, APX se concentre sur des domaines tels que la génération de code, le débogage, la mise en œuvre d'algorithmes et la résolution de problèmes techniques. Cette orientation en fait un outil essentiel pour les développeurs, les équipes d'ingénierie et les organisations souhaitant intégrer des assistants de codage basés sur l'IA dans leurs flux de travail.
La plateforme évalue la manière dont les modèles gèrent les défis pratiques de programmation dans différents langages et frameworks. Semblable à d’autres plateformes d’évaluation, APX simplifie le processus d’évaluation mais en mettant l’accent sur les performances et la sécurité du code.
APX propose une vaste gamme de modèles commerciaux et open source testés pour leur expertise en codage. La plateforme évalue régulièrement des modèles de codage bien connus tels que les modèles GPT sous-jacents de GitHub Copilot, les variantes CodeT5, StarCoder et Code Llama. Il comprend également des modèles à usage général dotés de fortes capacités de programmation, comme GPT-4, Claude et Gemini.
L'un des principaux différenciateurs d'APX réside dans l'inclusion de modèles de codage spécialisés qui n'apparaissent peut-être pas dans des classements plus larges, mais excellent dans des domaines de programmation de niche. Ces modèles sont testés sur différentes tailles de paramètres et versions affinées, y compris des variantes spécifiques au domaine pour des langages comme Python, JavaScript, Java, C++, Rust et Go. La plateforme évalue également les performances avec des frameworks tels que React, Django, TensorFlow et PyTorch.
Cette couverture complète garantit qu'APX fournit des tests rigoureux et pratiques pour les besoins de codage du monde réel.
APX utilise un cadre de test détaillé adapté aux scénarios de codage du monde réel. Il évalue les modèles sur des aspects tels que l'exactitude du code, l'efficacité, la lisibilité et le respect des normes de sécurité grâce à une combinaison de tests automatisés et d'avis d'experts.
Les scénarios de test incluent des défis d'algorithme, le débogage de code défectueux, des tâches de refactorisation et la génération de documentation. Les modèles sont également évalués pour leur capacité à expliquer des concepts de code complexes et à suggérer des optimisations.
Incorporating industry-standard coding practices, APX evaluates whether models follow established conventions for naming, commenting, and structuring code. Additionally, it tests the models’ ability to recognize and avoid common security vulnerabilities, making it especially valuable for enterprises where secure coding is a priority.
Le classement APX est mis à jour mensuellement pour suivre le rythme de l'évolution rapide du paysage des outils de codage d'IA. Les mises à jour incluent l'ajout de modèles récemment publiés et la réévaluation de ceux existants, garantissant ainsi l'alignement avec les derniers défis et normes de programmation.
La plateforme offre également un suivi des performances en temps réel pour les mises à jour importantes des modèles, donnant ainsi aux développeurs un accès immédiat aux dernières fonctionnalités. Lorsque des modèles majeurs axés sur le codage sont lancés, APX effectue des cycles d'évaluation spéciaux pour fournir des informations opportunes sur leurs performances.
APX fournit une analyse détaillée du coût par jeton spécifiquement adaptée aux tâches de codage. Cette analyse aide les utilisateurs à comprendre les implications financières de différents modèles pour divers cas d'utilisation. Les coûts sont ventilés par langage de programmation et par complexité des tâches, offrant ainsi un aperçu clair des modèles offrant la meilleure valeur.
L'analyse des coûts prend en compte des facteurs tels que la fréquence des appels d'API lors des tâches de codage typiques, les modèles d'utilisation des jetons et les économies potentielles grâce à la réduction du temps de débogage. APX estime même le coût total de possession pour les équipes qui adoptent des assistants de codage IA, en comparant les gains de productivité aux frais d'abonnement et d'utilisation. Ce niveau de détail fait d’APX une ressource précieuse pour évaluer l’impact financier des solutions de codage basées sur l’IA.
Les plates-formes de comparaison côte à côte pour les grands modèles de langage (LLM) répondent à une variété de besoins. Prompts.ai se démarque en offrant un accès à plus de 35 modèles de premier plan, associés à des outils centralisés pour gérer les coûts et assurer la gouvernance. Cela en fait un choix judicieux pour les grandes organisations qui ont besoin de flux de travail sécurisés et conformes avec une surveillance robuste.
Alors que Prompts.ai met l'accent sur la gestion des coûts et la gouvernance, d'autres plateformes se concentrent sur des priorités différentes. Ceux-ci peuvent inclure des commentaires de la communauté, des références techniques ou des mesures spécialisées telles que la sécurité et l'alignement. Ces plates-formes varient dans leurs sélections de modèles, leurs méthodes d'évaluation, leurs calendriers de mise à jour et la transparence des prix.
This summary complements earlier in-depth analyses, helping you identify the tools that best fit your goals. Whether your focus is budget, technical depth, or specific use cases, it’s worth noting that many organizations rely on a mix of platforms to achieve a well-rounded understanding of both technical and business needs.
When evaluating platforms for large language model (LLM) comparison, the best choice ultimately hinges on balancing factors like cost, performance, and compliance. The decision should align with your organization’s specific needs, technical capabilities, and workflow demands.
For enterprises seeking a unified AI orchestration solution, Prompts.ai offers a compelling option. With access to over 35 leading LLMs, integrated cost management tools, and enterprise-grade governance controls, it’s designed to simplify operations for organizations overseeing multiple teams and complex projects.
That said, the LLM platform landscape is diverse, and there’s no universal solution that fits every scenario. Many organizations adopt a mix of tools to address both research and production requirements. By focusing on your primary goals - whether it’s reducing costs, enhancing performance, or ensuring compliance - you can refine your platform selection process and streamline AI implementation.
Choisir les bons outils d’orchestration et de comparaison peut conduire à des améliorations mesurables de vos initiatives d’IA et générer des résultats commerciaux significatifs.
Prompts.ai simplifie le défi de l'évaluation de plusieurs grands modèles de langage (LLM) en fournissant des informations claires et exploitables sur leurs performances, leur évolutivité et leur rentabilité. Cela permet aux utilisateurs de faire des choix éclairés, en sélectionnant le modèle qui correspond le mieux à leurs besoins tout en respectant leur budget.
Avec des outils conçus pour évaluer l'équilibre entre les coûts et les performances, ainsi que l'efficacité opérationnelle, Prompts.ai garantit que les entreprises peuvent éviter les dépenses inutiles et se concentrer sur la mise en œuvre des solutions les plus efficaces adaptées à leurs besoins uniques.
Les plates-formes proposant des outils permettant de personnaliser les comparaisons pour les grands modèles de langage (LLM) sont inestimables car elles permettent aux utilisateurs d'affiner les évaluations en fonction de leurs objectifs uniques. En se concentrant sur des aspects critiques tels que les performances, les fonctionnalités et les applications pratiques, ces outils simplifient le processus d'identification du modèle le plus approprié, réduisant ainsi les incertitudes.
Ces outils de comparaison fournissent également des analyses comparatives plus détaillées, offrant des informations précieuses aux chercheurs, aux développeurs et aux entreprises. Que vous affiniez une solution pour une tâche spécifique ou que vous évaluiez plusieurs options, ces plateformes rendent la prise de décision plus rapide et plus efficace.
La mise à jour régulière des méthodes d’évaluation et des bases de données de modèles est essentielle pour maintenir la précision, la fiabilité et la crédibilité des plateformes d’IA. Ces mises à jour permettent aux modèles de rester à jour en incorporant de nouvelles données, en s'adaptant aux tendances et en traitant de nouveaux cas d'utilisation, améliorant ainsi les performances et la prise de décision.
L'affinement cohérent des méthodologies permet aux plateformes de lutter contre les biais, d'améliorer l'adaptabilité des modèles et de répondre aux normes changeantes de l'industrie. Cet engagement envers le progrès garantit que les solutions d’IA restent efficaces, conformes et équipées pour répondre aux besoins des utilisateurs dans un environnement en évolution rapide.



















