Nutzungsbasierte Abrechnung - AI Model Orchestration and Workflows Platform

In einer überfüllten KI-Landschaft kann die Auswahl des richtigen großen Sprachmodells (LLM) überwältigend sein. Da Modelle wie GPT-5, Claude und Gemini in verschiedenen Bereichen herausragend sind, vereinfachen Vergleichsplattformen den Entscheidungsprozess, indem sie parallele Analysen von Leistung, Kosten und Anwendungsfällen anbieten. Folgendes müssen Sie wissen:
Diese Plattformen erfüllen unterschiedliche Anforderungen – unabhängig davon, ob Sie Kosten optimieren, Sicherheit gewährleisten oder Codierungsfunktionen bewerten möchten. Nachfolgend finden Sie einen kurzen Vergleich, der Ihnen bei der Entscheidung helfen soll.
Die Wahl der richtigen Plattform hängt von Ihren Zielen ab – ob es darum geht, Kosten zu senken, die Einhaltung von Sicherheitsvorschriften sicherzustellen oder die Produktivität zu steigern. Plattformen wie Prompts.ai zeichnen sich für Unternehmen aus, die mehrere LLMs verwalten, während APX Coding LLMs perfekt für Entwickler ist. Jedes Tool bietet eine einzigartige Perspektive als Leitfaden für Ihre KI-Strategie.
Prompts.ai ist eine KI-Plattform für Unternehmen, die den Prozess des Vergleichs und der Bereitstellung großer Sprachmodelle (LLMs) vereinfachen soll. Durch die Konsolidierung von über 35 führenden LLMs in einem einzigen, einheitlichen Dashboard macht die Plattform das Jonglieren mit mehreren Tools überflüssig. Dieses optimierte Setup reduziert nicht nur die Komplexität, sondern ermöglicht es Teams auch, fundierte Entscheidungen zu treffen, indem sie Modelle hinsichtlich Leistung, Kosten und Integrationsgeschwindigkeit vergleichen – alles an einem Ort.
Prompts.ai bietet Zugriff auf eine breite Palette hochmoderner KI-Modelle, darunter unter anderem GPT-5, Claude, LLaMA, Gemini, Grok-4, Flux Pro und Kling. Mit dieser umfangreichen Bibliothek können Benutzer Modelle mit unterschiedlichen Stärken und Besonderheiten bewerten, ohne die Plattform wechseln oder mehrere API-Schlüssel verwalten zu müssen.
The platform's ability to aggregate these models ensures users can evaluate them based on real-world applications. Whether it’s testing coding efficiency, creative writing skills, or expertise in specific domains, the side-by-side comparison feature enables simultaneous testing of identical prompts across multiple models.
Prompts.ai verfolgt bei der Modellbewertung einen benutzerorientierten Ansatz und bietet Flexibilität, die über allgemeine Benchmarks hinausgeht. Anstatt sich auf voreingestellte Metriken zu verlassen, können Benutzer mithilfe ihrer eigenen Eingabeaufforderungen und Daten personalisierte Bewertungsszenarien erstellen, die auf ihre individuellen Bedürfnisse zugeschnitten sind.
The platform’s interface displays results side by side, offering a clear view of output quality, response times, and methodologies. This approach is especially beneficial for businesses that need to test models against proprietary datasets or industry-specific challenges that standard benchmarks fail to address.
Prompts.ai integriert eine FinOps-Schicht, die eine Echtzeitverfolgung der Token-Nutzung über alle Modelle hinweg ermöglicht. Durch die Überwachung des Token-Verbrauchs können Teams die Leistung und die finanziellen Auswirkungen direkt vergleichen und so einfacher beurteilen, welche Modelle den besten Wert bieten.
The platform’s Pay-As-You-Go TOKN credit system ensures that costs align with actual usage, potentially reducing expenses by up to 98%. For organizations managing tight budgets or allocating resources across multiple AI projects, this level of cost clarity supports smarter, data-driven decisions.
Prompts.ai keeps its users ahead of the curve by rapidly integrating new models as they become available. Its architecture is built for agility, ensuring emerging models are added quickly, so users don’t face delays in accessing the latest advancements.
Über neue Modelle hinaus führt die Plattform auch Updates und Optimierungen nahtlos ein. Wenn sich Modelle verbessern und neue Versionen veröffentlicht werden, können sich Benutzer darauf verlassen, dass Prompts.ai ununterbrochenen Zugriff auf diese Verbesserungen bietet und so in einer sich ständig weiterentwickelnden KI-Landschaft wettbewerbsfähig bleibt.
Der Schwerpunkt der künstlichen Analyse liegt auf der Bereitstellung konsistenter und gründlicher Bewertungen großer Sprachmodelle (LLMs) durch standardisierte Benchmarks und wiederholbare Testprozesse. Durch die Einhaltung eines systematischen Ansatzes bietet die Plattform detaillierte Einblicke in die Leistung verschiedener LLMs bei einer Vielzahl kognitiver Aufgaben und praktischer Anwendungen.
The platform maintains an extensive database that includes evaluations of both proprietary and open-source LLMs from leading AI developers like OpenAI, Anthropic, Google, Meta, and newer players in the field. It doesn’t stop at mainstream models but also includes specialized and fine-tuned versions, offering users the chance to explore options tailored to unique or niche requirements. This wide-ranging coverage ensures users can access performance data for virtually any model they might consider.
Die künstliche Analyse verwendet eine robuste Intelligence-Benchmarking-Methodik, die darauf ausgelegt ist, Modelle über mehrere Dimensionen hinweg zu bewerten. Anstatt sich auf eine einzelne Metrik zu verlassen, verwendet die Plattform ein gewichtetes Bewertungssystem, das Argumentation, Genauigkeit, Kreativität und aufgabenspezifische Fähigkeiten bewertet. Jedes Modell wird rigoros mit standardisierten Eingabeaufforderungen und Datensätzen getestet und die Ergebnisse werden normalisiert, um faire Vergleiche über verschiedene Architekturen und Größen hinweg zu gewährleisten. Eine Kombination aus automatisierter Bewertung und menschlichen Bewertungen verleiht diesen Bewertungen Tiefe und Zuverlässigkeit.
Um mit der sich schnell verändernden LLM-Landschaft Schritt zu halten, aktualisiert Artificial Analysis regelmäßig seine Methoden. Das neueste Update, Version 3.0, wurde am 2. September 2025 veröffentlicht. Diese regelmäßigen Updates stellen sicher, dass die Plattform weiterhin eine zuverlässige Quelle aktueller, umsetzbarer Erkenntnisse bleibt und es Benutzern ermöglicht, fundierte Entscheidungen bei der Auswahl des besten Sprachmodells für ihre Bedürfnisse zu treffen.
Die LMSYS Chatbot Arena ist eine kollaborative Plattform zur Bewertung großer Sprachmodelle (LLMs) durch menschliches Feedback in Echtzeit. Dieser Ansatz stellt sicher, dass Bewertungen relevant bleiben, indem sowohl Benutzerinteraktionen als auch laufende Verbesserungen der Modelle erfasst werden.
Die Plattform bietet eine vielfältige Auswahl an Modellen, darunter proprietäre, Open-Source- und experimentelle Optionen. Auf diese Weise können Benutzer testen und vergleichen, wie verschiedene Modelle bei einer Vielzahl von Aufgaben und Anwendungen funktionieren.
Um Verzerrungen zu minimieren, führen Benutzer blinde paarweise Vergleiche zwischen Modellen durch. Die Ergebnisse werden dann aggregiert, um die Modelle nach ihrer Konversationsqualität, Originalität und praktischen Nützlichkeit zu bewerten.
Die Bestenliste wird kontinuierlich mit Benutzerfeedback aktualisiert, um sicherzustellen, dass sie die neuesten Modellveröffentlichungen und Leistungstrends widerspiegelt.
Das Vellum AI Leaderboard bietet umsetzbare Einblicke in die Modellleistung, die speziell auf praktische Geschäftsanwendungen zugeschnitten sind.
Die Bestenliste bietet eine handverlesene Auswahl kommerzieller und Open-Source-Modelle für den Unternehmenseinsatz. Dazu gehören Angebote von Anbietern wie OpenAI, Anthropic und Google sowie Open-Source-Optionen wie Llama 2 und Mistral.
Was Vellum auszeichnet, ist sein Fokus auf geschäftstaugliche Modelle. Anstatt experimentelle oder unbewiesene Optionen aufzulisten, werden Modelle hervorgehoben, die sich als zuverlässig erwiesen haben und für den kommerziellen Einsatz geeignet sind.
Vellum bewertet Modelle mithilfe eines strukturierten Ansatzes in sechs Schlüsselkategorien: Argumentation, Codegenerierung, kreatives Schreiben, sachliche Genauigkeit, Befolgen von Anweisungen und Einhaltung von Sicherheitsvorschriften.
Jedes Modell wird mit Eingabeaufforderungen getestet, die reale Geschäftsszenarien nachahmen und automatisierte Bewertung mit menschlicher Überprüfung kombinieren. Diese zweischichtige Bewertung stellt sicher, dass die Ergebnisse die praktische Anwendbarkeit widerspiegeln und nicht nur theoretische Benchmarks. Regelmäßige Aktualisierungen des Bewertungsprozesses stellen sicher, dass die Rangliste mit den neuesten Entwicklungen im LLM-Bereich Schritt hält.
Die Bestenliste wird monatlich aktualisiert, mit zusätzlichen Updates für wichtige Modellversionen. Dieser Zeitplan gewährleistet gründliche Tests und bleibt gleichzeitig mit den rasanten Fortschritten bei großen Sprachmodellen auf dem Laufenden.
Vellum verfolgt auch die historische Leistung, sodass Benutzer überprüfen können, wie sich Modelle im Laufe der Zeit entwickelt haben. Diese Funktion hilft Unternehmen, fundierte Entscheidungen darüber zu treffen, wann neue Modelle eingeführt oder bestehende aktualisiert werden sollen.
Vellum bietet detaillierte Kostenaufschlüsselungen, einschließlich der Preise pro 1.000 Token und geschätzter Kosten für Aufgaben wie Kundensupport, Inhaltserstellung und Codeunterstützung.
LiveBench begegnet der Herausforderung der Datenkontamination, indem es seine Benchmark-Fragen regelmäßig aktualisiert. Dadurch wird sichergestellt, dass Modelle anhand von frischem Material bewertet werden, sodass sie sich die Trainingsdaten nicht einfach merken müssen.
LiveBench unterstützt eine Vielzahl von Modellen, von kleineren Systemen mit 0,5 Milliarden Parametern bis hin zu riesigen Systemen mit 405 Milliarden Parametern. Es wurden 49 verschiedene große Sprachmodelle (LLMs) bewertet, darunter führende proprietäre Plattformen, prominente Open-Source-Alternativen und spezialisierte Nischenmodelle.
The platform’s robust API compatibility allows seamless evaluation of any model with an OpenAI-compatible endpoint. This includes models from providers like Anthropic, Cohere, Mistral, Together, and Google.
Ab dem 9. Oktober 2025 werden in der Rangliste fortschrittliche Modelle wie die GPT-5-Serie von OpenAI (High, Medium, Pro, Codex, Mini, o3, o4-Mini), Claude Sonnet 4.5 und Claude 4.1 Opus von Anthropic, Gemini 2.5 Pro und Flash von Google, Grok 4 von xAI, DeepSeek V3.1 und Qwen 3 Max von Alibaba angezeigt.
LiveBench verwendet eine kontaminationsresistente Methodik und testet Modelle in 21 Aufgaben, die in sieben Kategorien unterteilt sind, darunter Argumentation, Codierung, Mathematik und Sprachverständnis. Um die Integrität ihrer Benchmarks zu wahren, aktualisiert die Plattform alle Fragen alle sechs Monate und führt im Laufe der Zeit komplexere Aufgaben ein. Beispielsweise wurde in der neuesten Version, LiveBench-2025-05-30, eine Agenten-Codierungsaufgabe hinzugefügt, bei der Modelle durch reale Entwicklungsumgebungen navigieren müssen, um Repository-Probleme zu lösen.
Um den Bewertungsprozess weiter abzusichern, bleiben rund 300 Fragen aus den letzten Aktualisierungen – etwa 30 % der Gesamtzahl – unveröffentlicht. Dadurch wird sichergestellt, dass Modelle nicht anhand der exakten Testdaten trainiert werden können. Diese Maßnahmen, kombiniert mit regelmäßigen Aktualisierungen, sorgen dafür, dass der Benchmark relevant und herausfordernd bleibt.
LiveBench folgt einem strengen Aktualisierungsplan, veröffentlicht regelmäßig neue Fragen und aktualisiert den gesamten Benchmark alle sechs Monate. Benutzer können Bewertungen für neu entwickelte Modelle anfordern, indem sie ein GitHub-Problem einreichen oder das LiveBench-Team per E-Mail kontaktieren. Dadurch können neue Modelle bewertet werden, ohne auf das nächste geplante Update warten zu müssen. Zu den jüngsten Ergänzungen ab Dezember 2024 gehören Modelle wie claude-3-5-haiku-20241022, claude-3-5-sonnet-20241022, gemini-exp-1114, gpt-4o-2024-11-20, grok-2 und grok-2-mini.
LLM-Stats bietet eine datengesteuerte Möglichkeit, große Sprachmodelle zu vergleichen, indem aggregierte Statistiken aus verschiedenen Benchmarks analysiert werden. Es bietet zwar wertvolle Einblicke in die Modellleistung, Einzelheiten wie die Kategorisierung der Modelle, die verwendeten Bewertungsmethoden, Preisdetails und die Häufigkeit der Datenaktualisierung wurden jedoch nicht bekannt gegeben. Dieser statistische Ansatz dient als nützliches Gegenstück zu den früheren qualitativen Vergleichen.
OpenRouter Rankings verfolgt einen praktischen Ansatz zur Bewertung der Leistung von Sprachmodellen und konzentriert sich auf die Leistung von Modellen in realen Szenarien, anstatt sich ausschließlich auf technische Benchmarks zu verlassen. Durch die Aggregation von Daten aus dem täglichen Gebrauch wird hervorgehoben, welche Modelle in der Praxis wirklich einen Mehrwert bieten. Diese Betonung realer Kennzahlen ergänzt die detaillierteren technischen Auswertungen anderer Plattformen.
Die Plattform umfasst eine Vielzahl von Sprachmodellen, die nach ihren spezifischen Anwendungen organisiert sind. Durch die Kategorisierung von Modellen nach ihren Anwendungsfällen können Benutzer leicht die Lösungen identifizieren, die ihren spezifischen Anforderungen entsprechen.
OpenRouter Rankings uses a usage-based evaluation system, considering multiple factors like response quality, efficiency, and cost. These metrics are combined into composite scores that provide a clear picture of each model’s overall effectiveness and value.
Die Rankings werden regelmäßig aktualisiert, um Änderungen in der Modellleistung und Nutzungstrends zu berücksichtigen und sicherzustellen, dass die Daten relevant und aktuell bleiben.
Ein Schwerpunkt der Plattform liegt auf wirtschaftlichen Faktoren. Durch die Analyse von Preisen und kostenbezogenen Kennzahlen schafft es Klarheit über das Gleichgewicht zwischen Kosten und Leistung und hilft Benutzern, fundierte Entscheidungen zu treffen.
Das Hugging Face Open LLM Leaderboard zeichnet sich als spezielle Plattform zur Bewertung der Leistung von Open-Source-Sprachmodellen aus. Es wurde von Hugging Face entwickelt und dient als zentrale Ressource für Forscher und Entwickler, die Modelle mit standardisierten Benchmarks vergleichen möchten. Durch die ausschließliche Konzentration auf Open-Source-Modelle orientiert sich die Rangliste an den Bedürfnissen derjenigen, die bei ihren KI-Lösungen Wert auf Transparenz und offene Zugänglichkeit legen. Es ergänzt die zuvor diskutierten unternehmens- und leistungsorientierten Vergleiche und bietet eine einzigartige Perspektive auf die Open-Source-KI-Landschaft.
Die Rangliste organisiert eine breite Palette von Open-Source-Modellen nach Parametergröße – 7B, 13B, 30B und 70B+ – und umfasst sowohl experimentelle Designs als auch groß angelegte Implementierungen führender Forschungseinrichtungen.
Es enthält Beiträge von Organisationen und einzelnen Entwicklern und fördert ein vielfältiges und dynamisches Ökosystem, das den aktuellen Stand der Open-Source-KI widerspiegelt. Jeder Modelleintrag enthält detaillierte Informationen zu Architektur, Trainingsdaten und Lizenzbedingungen, sodass Benutzer fundierte Entscheidungen basierend auf ihren Projektanforderungen und Compliance-Anforderungen treffen können.
Mithilfe eines standardisierten Bewertungsrahmens bewertet Hugging Face Modelle anhand mehrerer Benchmarks und bietet eine gründliche Analyse ihrer Fähigkeiten. Diese Benchmarks umfassen Argumentationsfähigkeiten, Wissensspeicherung, mathematische Problemlösung und Leseverständnis und gewährleisten so einen umfassenden Überblick über die Leistung jedes Modells.
Die Plattform nutzt automatisierte Pipelines, um konsistente Testbedingungen für alle Modelle aufrechtzuerhalten. Dadurch werden Diskrepanzen beseitigt, die durch unterschiedliche Umgebungen oder Methoden verursacht werden, und den Benutzern werden zuverlässige, direkte Vergleiche ermöglicht, um die beste Lösung für ihre spezifischen Anwendungsfälle zu ermitteln.
Die Bestenliste wird kontinuierlich mit neuen Modellen aktualisiert, sobald diese in der Open-Source-Community auftauchen. Dank des automatisierten Bewertungsprozesses können Modelle schnell bewertet und eingestuft werden, ohne dass es zu Verzögerungen durch manuelle Eingriffe kommt.
Darüber hinaus bewertet die Plattform bestehende Modelle neu, wenn Benchmark-Methoden verfeinert werden. Dadurch wird sichergestellt, dass ältere Modelle angemessen vertreten bleiben und die Relevanz und Vertrauenswürdigkeit der Bestenliste im Laufe der Zeit erhalten bleibt.
While the leaderboard doesn’t provide direct pricing, it includes key details such as model size, memory requirements, and inference speed. These metrics help users estimate the infrastructure costs involved in deploying each model.
Dieser Fokus auf Rechenanforderungen ermöglicht es Unternehmen, budgetbewusste Entscheidungen zu treffen, insbesondere wenn sie mit begrenzten Ressourcen oder spezifischen Hardware-Einschränkungen arbeiten. Durch die Betonung von Open-Source-Modellen eliminiert die Plattform auch laufende Lizenzgebühren, wodurch die Gesamtbetriebskosten im Vergleich zu proprietären Alternativen vorhersehbarer und häufig besser überschaubar sind.
Das Scale AI SEAL Leaderboard widmet sich der Bewertung der Sicherheit, Ausrichtung und Leistung großer Sprachmodelle (LLMs) und geht dabei auf wichtige Unternehmensanliegen hinsichtlich des verantwortungsvollen Einsatzes von KI ein. Im Gegensatz zu allgemeinen Bestenlisten konzentriert sich SEAL auf die Beurteilung, wie gut Modelle mit sensiblen Inhalten umgehen, ethische Richtlinien einhalten und in verschiedenen Szenarien ein konsistentes Verhalten aufrechterhalten. Dies unterstreicht die Bedeutung von Sicherheit und ethischer Compliance neben reiner Leistung in Unternehmensumgebungen. Sein spezialisierter Ansatz bietet detaillierte Einblicke in Modellfähigkeiten, Bewertungsmethoden, Aktualisierungspläne und damit verbundene Kosten.
SEAL prüft eine Mischung aus proprietären und Open-Source-Modellen, wobei der Schwerpunkt auf den Modellen liegt, die üblicherweise in Geschäftsanwendungen verwendet werden. Die Bestenliste umfasst hochkarätige kommerzielle Modelle wie GPT-4, Claude und Gemini sowie beliebte Open-Source-Optionen wie Llama 2 und Mistral-Varianten.
Was SEAL auszeichnet, ist der Schwerpunkt auf unternehmenstauglichen Modellen statt auf experimentellen oder forschungsorientierten Versionen. Jedes Modell wird anhand verschiedener Parametergrößen und fein abgestimmter Konfigurationen getestet und bietet so ein tieferes Verständnis dafür, wie sich diese Variationen auf das Gleichgewicht zwischen Sicherheit und Leistung auswirken. Die Plattform bewertet auch spezielle Modelle, die auf Branchen wie das Gesundheitswesen oder das Finanzwesen zugeschnitten sind, in denen die Einhaltung gesetzlicher Vorschriften und das Risikomanagement von entscheidender Bedeutung sind.
SEAL verwendet ein gründliches Bewertungsrahmenwerk, das traditionelle Leistungsmetriken mit umfangreichen Sicherheitstests verbindet. Modelle werden auf ihre Fähigkeit hin beurteilt, schädliche Aufforderungen abzulehnen, die sachliche Genauigkeit aufrechtzuerhalten und voreingenommene oder diskriminierende Ergebnisse zu vermeiden.
Der Bewertungsprozess umfasst Red-Teaming-Übungen und menschliche Überprüfungen, um Schwachstellen und subtile Vorurteile aufzudecken, die bei automatisierten Tests möglicherweise übersehen werden. Durch die Kombination automatisierter und manueller Bewertungen stellt SEAL sicher, dass Sicherheitsüberlegungen neben Leistungsmetriken gleichermaßen gewichtet werden.
Das SEAL Leaderboard wird vierteljährlich aktualisiert und spiegelt den detaillierten und sicherheitsorientierten Charakter seiner Bewertungen wider. Jedes Update umfasst neu veröffentlichte Modelle und bewertet bestehende Modelle anhand sich entwickelnder Sicherheitsmaßstäbe und -standards neu.
Zusätzlich zu diesen geplanten Aktualisierungen veröffentlicht Scale AI Zwischenberichte, wenn innerhalb der KI-Community bedeutende Modellaktualisierungen oder sicherheitsrelevante Vorfälle auftreten. Dieser adaptive Ansatz stellt sicher, dass Unternehmensbenutzer rechtzeitig Zugriff auf die neuesten Sicherheitsbewertungen haben, was angesichts der schnellen Modellentwicklung besonders wichtig ist. Diese regelmäßigen Updates liefern auch wertvolle Daten für die Analyse der Bereitstellungskosten.
While SEAL doesn’t disclose direct pricing, it offers insights into the total cost of ownership, including factors like content moderation, compliance requirements, and liability risks. This helps enterprises weigh the costs of safety measures against operational expenses.
Die Plattform bietet außerdem Hinweise zu Infrastrukturanforderungen für verschiedene Sicherheitskonfigurationen und hilft Unternehmen dabei, die Kompromisse zwischen erhöhter Sicherheit und Betriebskosten zu verstehen. Für Unternehmensbenutzer schätzt SEAL potenzielle Einsparungen durch einen geringeren Aufwand für die Inhaltsmoderation bei der Bereitstellung von Modellen mit robusten integrierten Sicherheitsfunktionen.
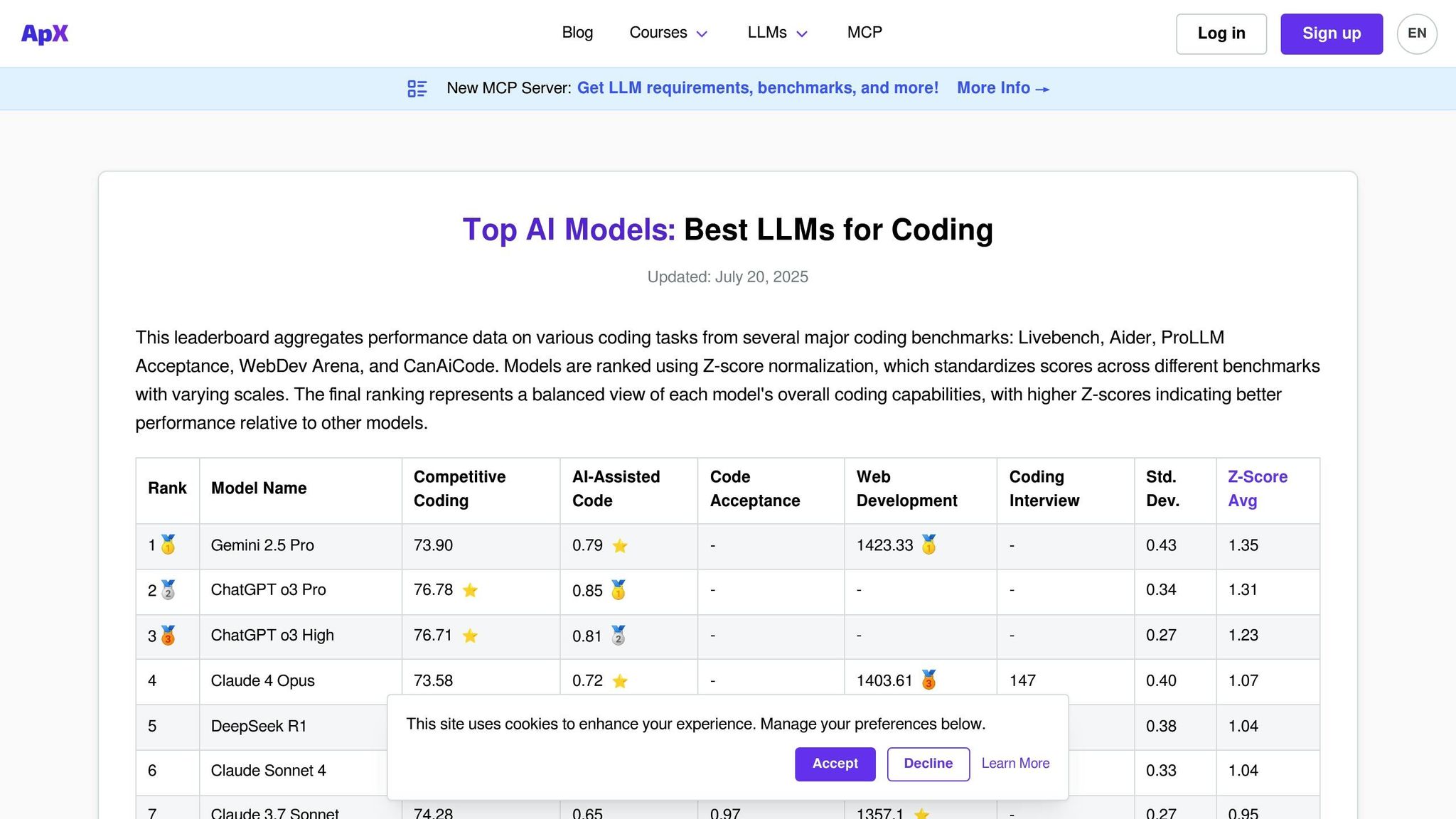
APX Coding LLMs ist eine Plattform, die speziell zur Bewertung der Codierungsfunktionen von Sprachmodellen entwickelt wurde. Im Gegensatz zu allgemeinen Bestenlisten, die sich auf ein breites Spektrum an Konversationsfähigkeiten konzentrieren, konzentriert sich APX auf Bereiche wie Codegenerierung, Debugging, Algorithmusimplementierung und Lösung technischer Probleme. Dieser Fokus macht es zu einem unverzichtbaren Werkzeug für Entwickler, Ingenieurteams und Organisationen, die KI-gestützte Codierungsassistenten in ihre Arbeitsabläufe integrieren möchten.
Die Plattform bewertet, wie Modelle praktische Programmierherausforderungen in verschiedenen Sprachen und Frameworks bewältigen. Ähnlich wie andere Evaluierungsplattformen vereinfacht APX den Bewertungsprozess, legt jedoch besonderen Wert auf Codeleistung und Sicherheit.
APX verfügt über eine umfangreiche Palette sowohl kommerzieller als auch Open-Source-Modelle, die auf ihre Programmierkompetenz getestet wurden. Die Plattform bewertet regelmäßig bekannte Codierungsmodelle wie die zugrunde liegenden GPT-Modelle von GitHub Copilot, CodeT5-, StarCoder- und Code Llama-Varianten. Es umfasst auch Allzweckmodelle mit starken Programmierfähigkeiten, wie GPT-4, Claude und Gemini.
Ein wesentliches Unterscheidungsmerkmal für APX ist die Einbeziehung spezialisierter Codierungsmodelle, die möglicherweise nicht auf breiteren Bestenlisten erscheinen, sich aber in Nischenprogrammierungsbereichen auszeichnen. Diese Modelle werden mit verschiedenen Parametergrößen und fein abgestimmten Versionen getestet, einschließlich domänenspezifischer Varianten für Sprachen wie Python, JavaScript, Java, C++, Rust und Go. Die Plattform bewertet auch die Leistung mit Frameworks wie React, Django, TensorFlow und PyTorch.
Diese umfassende Abdeckung stellt sicher, dass APX strenge und praktische Tests für reale Codierungsanforderungen bietet.
APX verwendet ein detailliertes Test-Framework, das auf reale Codierungsszenarien zugeschnitten ist. Es bewertet Modelle hinsichtlich Aspekten wie Codekorrektheit, Effizienz, Lesbarkeit und Einhaltung von Sicherheitsstandards durch eine Kombination aus automatisierten Tests und Expertenbewertungen.
Die Testszenarien umfassen Algorithmusherausforderungen, das Debuggen von fehlerhaftem Code, Refactoring-Aufgaben und die Erstellung von Dokumentation. Modelle werden auch auf ihre Fähigkeit hin bewertet, komplexe Codekonzepte zu erklären und Optimierungen vorzuschlagen.
Incorporating industry-standard coding practices, APX evaluates whether models follow established conventions for naming, commenting, and structuring code. Additionally, it tests the models’ ability to recognize and avoid common security vulnerabilities, making it especially valuable for enterprises where secure coding is a priority.
Die APX-Bestenliste wird monatlich aktualisiert, um mit der sich schnell entwickelnden Landschaft der KI-Codierungstools Schritt zu halten. Zu den Aktualisierungen gehören die Hinzufügung neu veröffentlichter Modelle und die Neubewertung vorhandener Modelle, um die Anpassung an die neuesten Programmierherausforderungen und -standards sicherzustellen.
Die Plattform bietet außerdem Echtzeit-Leistungsverfolgung für wichtige Modellaktualisierungen und ermöglicht Entwicklern so sofortigen Zugriff auf die neuesten Funktionen. Wenn wichtige codierungsorientierte Modelle auf den Markt kommen, führt APX spezielle Bewertungszyklen durch, um zeitnahe Einblicke in ihre Leistung zu liefern.
APX bietet eine detaillierte Aufschlüsselung der Kosten-pro-Token-Analyse, die speziell auf Codierungsaufgaben zugeschnitten ist. Diese Analyse hilft Benutzern, die Kostenauswirkungen verschiedener Modelle für verschiedene Anwendungsfälle zu verstehen. Die Kosten werden nach Programmiersprache und Aufgabenkomplexität aufgeschlüsselt und bieten klare Einblicke in die Modelle, die den besten Wert bieten.
Die Kostenanalyse berücksichtigt Faktoren wie die Häufigkeit von API-Aufrufen während typischer Codierungsaufgaben, Token-Nutzungsmuster und potenzielle Einsparungen durch kürzere Debugging-Zeiten. APX schätzt sogar die Gesamtbetriebskosten für Teams, die KI-Codierungsassistenten einführen, und wägt dabei Produktivitätssteigerungen gegen Abonnement- und Nutzungsgebühren ab. Dieser Detaillierungsgrad macht APX zu einer wertvollen Ressource für die Bewertung der finanziellen Auswirkungen von KI-gesteuerten Codierungslösungen.
Side-by-Side-Vergleichsplattformen für große Sprachmodelle (LLMs) erfüllen eine Vielzahl von Anforderungen. Prompts.ai zeichnet sich dadurch aus, dass es Zugriff auf über 35 erstklassige Modelle bietet, gepaart mit zentralisierten Tools zur Kostenverwaltung und Gewährleistung der Governance. Dies macht es zu einer guten Wahl für größere Unternehmen, die sichere und konforme Arbeitsabläufe mit robuster Überwachung benötigen.
Während Prompts.ai den Schwerpunkt auf Kostenmanagement und Governance legt, konzentrieren sich andere Plattformen auf andere Prioritäten. Dazu können Community-Feedback, technische Benchmarks oder spezielle Kennzahlen wie Sicherheit und Ausrichtung gehören. Diese Plattformen unterscheiden sich in der Modellauswahl, den Bewertungsmethoden, den Aktualisierungsplänen und der Preistransparenz.
This summary complements earlier in-depth analyses, helping you identify the tools that best fit your goals. Whether your focus is budget, technical depth, or specific use cases, it’s worth noting that many organizations rely on a mix of platforms to achieve a well-rounded understanding of both technical and business needs.
When evaluating platforms for large language model (LLM) comparison, the best choice ultimately hinges on balancing factors like cost, performance, and compliance. The decision should align with your organization’s specific needs, technical capabilities, and workflow demands.
For enterprises seeking a unified AI orchestration solution, Prompts.ai offers a compelling option. With access to over 35 leading LLMs, integrated cost management tools, and enterprise-grade governance controls, it’s designed to simplify operations for organizations overseeing multiple teams and complex projects.
That said, the LLM platform landscape is diverse, and there’s no universal solution that fits every scenario. Many organizations adopt a mix of tools to address both research and production requirements. By focusing on your primary goals - whether it’s reducing costs, enhancing performance, or ensuring compliance - you can refine your platform selection process and streamline AI implementation.
Die Wahl der richtigen Orchestrierungs- und Vergleichstools kann zu messbaren Verbesserungen Ihrer KI-Initiativen führen und aussagekräftige Geschäftsergebnisse erzielen.
Prompts.ai vereinfacht die Herausforderung der Evaluierung mehrerer großer Sprachmodelle (LLMs), indem es klare, umsetzbare Einblicke in deren Leistung, Skalierbarkeit und Kosteneffizienz liefert. Dadurch können Benutzer fundierte Entscheidungen treffen und das Modell auswählen, das ihren Anforderungen am besten entspricht und gleichzeitig das Budget einhält.
Mit Tools zur Bewertung des Gleichgewichts zwischen Kosten und Leistung sowie der betrieblichen Effizienz stellt Prompts.ai sicher, dass Unternehmen unnötige Ausgaben vermeiden und sich auf die Implementierung der effektivsten Lösungen konzentrieren können, die auf ihre individuellen Anforderungen zugeschnitten sind.
Plattformen, die Tools zum Anpassen von Vergleichen für große Sprachmodelle (LLMs) anbieten, sind von unschätzbarem Wert, da sie Benutzern die Feinabstimmung von Auswertungen ermöglichen, um sie an ihre individuellen Ziele anzupassen. Durch die Fokussierung auf kritische Aspekte wie Leistung, Funktionen und praktische Anwendungen vereinfachen diese Tools den Prozess der Identifizierung des am besten geeigneten Modells und reduzieren das Rätselraten.
Diese Vergleichstools liefern auch detailliertere Benchmarking-Werte und bieten wertvolle Erkenntnisse für Forscher, Entwickler und Unternehmen gleichermaßen. Unabhängig davon, ob Sie eine Lösung für eine bestimmte Aufgabe verfeinern oder mehrere Optionen abwägen, machen diese Plattformen die Entscheidungsfindung schneller und effektiver.
Die regelmäßige Aktualisierung von Bewertungsmethoden und Modelldatenbanken ist für die Aufrechterhaltung der Präzision, Zuverlässigkeit und Glaubwürdigkeit von KI-Plattformen unerlässlich. Durch diese Aktualisierungen bleiben Modelle auf dem neuesten Stand, indem sie neue Daten integrieren, sich an Trends anpassen und neue Anwendungsfälle berücksichtigen, was letztendlich die Leistung und Entscheidungsfindung steigert.
Durch die konsequente Weiterentwicklung der Methoden können Plattformen Vorurteile bekämpfen, die Anpassungsfähigkeit von Modellen verbessern und sich ändernden Industriestandards gerecht werden. Dieses Engagement für den Fortschritt stellt sicher, dass KI-Lösungen effizient, konform und gerüstet bleiben, um die Benutzeranforderungen in einer sich schnell verändernden Umgebung zu erfüllen.



















