ادفع حسب الاستخدام - AI Model Orchestration and Workflows Platform

في بيئة الذكاء الاصطناعي المزدحمة، قد يكون اختيار نموذج اللغة الكبير المناسب (LLM) أمرًا صعبًا. مع نماذج مثل GPT-5، وClaude، وGemini التي تتفوق في مجالات مختلفة، تعمل منصات المقارنة على تبسيط عملية اتخاذ القرار من خلال تقديم تحليلات جنبًا إلى جنب للأداء والتكاليف وحالات الاستخدام. إليك ما تحتاج إلى معرفته:
تلبي هذه الأنظمة الأساسية الاحتياجات المختلفة - سواء كنت تعمل على تحسين التكاليف، أو ضمان السلامة، أو تقييم قدرات البرمجة. فيما يلي مقارنة سريعة لمساعدتك على اتخاذ القرار.
يعتمد اختيار النظام الأساسي المناسب على أهدافك - سواء كانت خفض التكاليف، أو ضمان الامتثال للسلامة، أو تعزيز الإنتاجية. تبرز منصات مثل Prompts.ai للمؤسسات التي تدير العديد من دورات LLM، بينما تعتبر APX Coding LLMs مثالية للمطورين. تقدم كل أداة منظورًا فريدًا لتوجيه استراتيجية الذكاء الاصطناعي الخاصة بك.
Prompts.ai عبارة عن منصة للذكاء الاصطناعي للمؤسسات مصممة لتبسيط عملية مقارنة ونشر نماذج اللغات الكبيرة (LLMs). من خلال دمج أكثر من 35 ماجستيرًا في إدارة الأعمال (LLM) رائدًا في لوحة معلومات واحدة موحدة، تلغي المنصة الحاجة إلى التوفيق بين أدوات متعددة. لا يقلل هذا الإعداد المبسط من التعقيد فحسب، بل يمكّن الفرق أيضًا من اتخاذ قرارات مستنيرة من خلال مقارنة النماذج من حيث الأداء والتكلفة وسرعة التكامل - كل ذلك في مكان واحد.
يوفر Prompts.ai إمكانية الوصول إلى مجموعة واسعة من نماذج الذكاء الاصطناعي الحديثة، بما في ذلك GPT-5، وClaude، وLLaMA، وGemini، وGrok-4، وFlux Pro، وKling، وغيرها. تتيح هذه المكتبة الشاملة للمستخدمين تقييم النماذج ذات نقاط القوة والتخصصات المختلفة دون الحاجة إلى تبديل الأنظمة الأساسية أو إدارة مفاتيح API المتعددة.
The platform's ability to aggregate these models ensures users can evaluate them based on real-world applications. Whether it’s testing coding efficiency, creative writing skills, or expertise in specific domains, the side-by-side comparison feature enables simultaneous testing of identical prompts across multiple models.
يتبع Prompts.ai نهج المستخدم أولاً لتقييم النماذج، مما يوفر مرونة تتجاوز المعايير العامة. بدلاً من الاعتماد على مقاييس محددة مسبقًا، يمكن للمستخدمين إنشاء سيناريوهات تقييم مخصصة تناسب احتياجاتهم الفريدة، باستخدام المطالبات والبيانات الخاصة بهم.
The platform’s interface displays results side by side, offering a clear view of output quality, response times, and methodologies. This approach is especially beneficial for businesses that need to test models against proprietary datasets or industry-specific challenges that standard benchmarks fail to address.
تدمج Prompts.ai طبقة FinOps التي توفر تتبعًا في الوقت الفعلي لاستخدام الرمز المميز عبر جميع النماذج. من خلال مراقبة استهلاك الرموز، يمكن للفرق مقارنة الأداء والآثار المالية بشكل مباشر، مما يسهل تقييم النماذج التي تقدم أفضل قيمة.
The platform’s Pay-As-You-Go TOKN credit system ensures that costs align with actual usage, potentially reducing expenses by up to 98%. For organizations managing tight budgets or allocating resources across multiple AI projects, this level of cost clarity supports smarter, data-driven decisions.
Prompts.ai keeps its users ahead of the curve by rapidly integrating new models as they become available. Its architecture is built for agility, ensuring emerging models are added quickly, so users don’t face delays in accessing the latest advancements.
بالإضافة إلى النماذج الجديدة، تقوم المنصة أيضًا بطرح التحديثات والتحسينات بسلاسة. ومع تحسن النماذج وإصدار إصدارات جديدة، يمكن للمستخدمين الاعتماد على Prompts.ai لتوفير وصول غير منقطع إلى هذه التحسينات، مما يمكنهم من الحفاظ على قدرتهم التنافسية في مشهد الذكاء الاصطناعي المتطور باستمرار.
يركز التحليل الاصطناعي على تقديم تقييمات متسقة وشاملة لنماذج اللغات الكبيرة (LLMs) من خلال معايير موحدة وعمليات اختبار قابلة للتكرار. من خلال الالتزام بنهج منظم، توفر المنصة رؤى متعمقة حول كيفية أداء LLMs المختلفة عبر مجموعة متنوعة من المهام المعرفية والتطبيقات العملية.
The platform maintains an extensive database that includes evaluations of both proprietary and open-source LLMs from leading AI developers like OpenAI, Anthropic, Google, Meta, and newer players in the field. It doesn’t stop at mainstream models but also includes specialized and fine-tuned versions, offering users the chance to explore options tailored to unique or niche requirements. This wide-ranging coverage ensures users can access performance data for virtually any model they might consider.
يستخدم التحليل الاصطناعي منهجية قوية لقياس الذكاء، مصممة لتقييم النماذج عبر أبعاد متعددة. بدلاً من الاعتماد على مقياس واحد، تستخدم المنصة نظام تسجيل مرجح يقوم بتقييم المنطق والدقة والإبداع والقدرات الخاصة بالمهمة. يتم اختبار كل نموذج بدقة باستخدام المطالبات ومجموعات البيانات الموحدة، ويتم تسوية النتائج لضمان إجراء مقارنات عادلة عبر مختلف البنى والأحجام. يضيف مزيج من التسجيل الآلي والتقييمات البشرية عمقًا وموثوقية لهذه التقييمات.
Keeping up with the rapidly changing LLM landscape, Artificial Analysis frequently updates its methodologies. The most recent update, Version 3.0, was released on 2 سبتمبر 2025. These regular updates ensure the platform remains a reliable source of up-to-date, actionable insights, enabling users to make informed decisions when selecting the best language model for their needs.
تعد LMSYS Chatbot Arena عبارة عن منصة تعاونية مصممة لتقييم نماذج اللغات الكبيرة (LLMs) من خلال التعليقات البشرية في الوقت الفعلي. يضمن هذا النهج أن تظل التقييمات ذات صلة من خلال التقاط تفاعلات المستخدم والتحسينات المستمرة في النماذج.
تستضيف المنصة مجموعة متنوعة من النماذج، بما في ذلك الخيارات الخاصة والمفتوحة المصدر والتجريبية. يتيح ذلك للمستخدمين اختبار ومقارنة أداء النماذج المختلفة عبر مجموعة واسعة من المهام والتطبيقات.
لتقليل التحيز، يقوم المستخدمون بإجراء مقارنات زوجية عمياء بين النماذج. يتم بعد ذلك تجميع النتائج لتصنيف النماذج بناءً على جودة المحادثة وأصالتها وفائدتها العملية.
يتم تحديث لوحة المتصدرين بشكل مستمر من خلال تعليقات المستخدمين، مما يضمن أنها تعكس أحدث إصدارات النماذج واتجاهات الأداء.
توفر لوحة Vellum AI Leaderboard رؤى قابلة للتنفيذ حول أداء النموذج، مصممة خصيصًا لتطبيقات الأعمال العملية.
تتميز لوحة المتصدرين بمجموعة مختارة بعناية من النماذج التجارية ومفتوحة المصدر المصممة للاستخدام المؤسسي. يتضمن ذلك عروضًا من مقدمي خدمات مثل OpenAI وAnthropic وGoogle، إلى جانب خيارات مفتوحة المصدر مثل Llama 2 وMistral.
ما يجعل Vellum بارزًا هو تركيزه على النماذج الجاهزة للأعمال. فبدلاً من إدراج الخيارات التجريبية أو غير المثبتة، فإنه يسلط الضوء على النماذج التي أثبتت موثوقيتها ومناسبة للنشر التجاري.
يقوم Vellum بتقييم النماذج باستخدام نهج منظم عبر ست فئات رئيسية: الاستدلال، وإنشاء التعليمات البرمجية، والكتابة الإبداعية، والدقة الواقعية، واتباع التعليمات، والامتثال للسلامة.
يتم اختبار كل نموذج من خلال المطالبات التي تحاكي سيناريوهات الأعمال في العالم الحقيقي، والجمع بين التسجيل الآلي والمراجعة البشرية. يضمن هذا التقييم المزدوج أن النتائج تعكس قابلية الاستخدام العملي بدلاً من مجرد المعايير النظرية. تضمن التحديثات المنتظمة لعملية التقييم بقاء لوحة المتصدرين متوافقة مع أحدث التطورات في مجال LLM.
يتم تحديث لوحة المتصدرين شهريًا، مع تحديثات إضافية لإصدارات النماذج الرئيسية. يضمن هذا الجدول إجراء اختبار شامل مع البقاء على اطلاع دائم بالتطورات السريعة في نماذج اللغات الكبيرة.
يتتبع Vellum أيضًا الأداء التاريخي، مما يسمح للمستخدمين بمراجعة كيفية تطور النماذج بمرور الوقت. تساعد هذه الميزة الشركات على اتخاذ قرارات مستنيرة بشأن وقت اعتماد نماذج جديدة أو ترقية النماذج الحالية.
يوفر Vellum تفاصيل تفصيلية للتكلفة، بما في ذلك التسعير لكل 1000 رمز مميز والتكاليف المقدرة لمهام مثل دعم العملاء وإنشاء المحتوى والمساعدة في التعليمات البرمجية.
يعالج LiveBench التحدي المتمثل في تلوث البيانات من خلال تحديث أسئلته المعيارية بشكل متكرر. وهذا يضمن تقييم النماذج على مواد جديدة، مما يمنعهم من حفظ بيانات التدريب ببساطة.
يدعم LiveBench مجموعة واسعة من النماذج، بدءًا من الأنظمة الأصغر التي تحتوي على 0.5 مليار معلمة إلى الأنظمة الضخمة التي تضم 405 مليار معلمة. وقد قامت بتقييم 49 نموذجًا مختلفًا للغات الكبيرة (LLMs)، بما في ذلك منصات الملكية الرائدة، والبدائل البارزة مفتوحة المصدر، والنماذج المتخصصة المتخصصة.
The platform’s robust API compatibility allows seamless evaluation of any model with an OpenAI-compatible endpoint. This includes models from providers like Anthropic, Cohere, Mistral, Together, and Google.
As of 9 أكتوبر 2025, the leaderboard showcases advanced models such as OpenAI's GPT-5 series (High, Medium, Pro, Codex, Mini, o3, o4-Mini), Anthropic's Claude Sonnet 4.5 and Claude 4.1 Opus, Google's Gemini 2.5 Pro and Flash, xAI's Grok 4, DeepSeek V3.1, and Alibaba's Qwen 3 Max.
يستخدم LiveBench منهجية مقاومة للتلوث، ويختبر النماذج عبر 21 مهمة مقسمة إلى سبع فئات، بما في ذلك الاستدلال والترميز والرياضيات وفهم اللغة. وللحفاظ على سلامة معاييرها، تقوم المنصة بتحديث جميع الأسئلة كل ستة أشهر وتقدم مهام أكثر تعقيدًا بمرور الوقت. على سبيل المثال، أضاف الإصدار الأخير، LiveBench-2025-05-30، مهمة ترميز وكيل حيث يجب على النماذج التنقل في بيئات التطوير في العالم الحقيقي لحل مشكلات المستودع.
ولزيادة حماية عملية التقييم، يظل حوالي 300 سؤال من التحديثات الأخيرة - حوالي 30% من الإجمالي - غير منشورة. وهذا يضمن عدم إمكانية تدريب النماذج على بيانات الاختبار الدقيقة. تعمل هذه التدابير، جنبًا إلى جنب مع التحديثات المنتظمة، على إبقاء المعيار ملائمًا وصعبًا.
يتبع LiveBench جدول تحديث صارم، حيث يصدر أسئلة جديدة باستمرار ويحدث المعيار بأكمله كل ستة أشهر. يمكن للمستخدمين طلب تقييمات للنماذج المطورة حديثًا عن طريق إرسال مشكلة GitHub أو الاتصال بفريق LiveBench عبر البريد الإلكتروني. وهذا يسمح بتقييم النماذج الناشئة دون انتظار التحديث المجدول التالي. تتضمن الإضافات الحديثة اعتبارًا من ديسمبر 2024 نماذج مثل claude-3-5-haiku-20241022، و claude-3-5-sonnet-20241022، وgemini-exp-1114، وgpt-4o-2024-11-20، وgrok-2، وgrok-2-mini.
توفر LLM-Stats طريقة تعتمد على البيانات لمقارنة نماذج اللغات الكبيرة من خلال تحليل الإحصائيات المجمعة من مجموعة متنوعة من المعايير. على الرغم من أنه يقدم رؤى قيمة حول أداء النموذج، إلا أنه لم تتم مشاركة تفاصيل مثل كيفية تصنيف النماذج وطرق التقييم المستخدمة وتفاصيل التسعير وعدد مرات تحديث البيانات. يعد هذا النهج الإحصائي بمثابة نظير مفيد للمقارنات النوعية السابقة.
تتبع OpenRouter Rankings نهجًا عمليًا لتقييم أداء نماذج اللغة، مع التركيز على كيفية أداء النماذج في سيناريوهات العالم الحقيقي بدلاً من الاعتماد فقط على المعايير الفنية. ومن خلال تجميع البيانات من الاستخدام اليومي، فإنه يسلط الضوء على النماذج التي تقدم قيمة حقيقية في التطبيقات العملية. هذا التركيز على مقاييس العالم الحقيقي يكمل التقييمات الفنية الأكثر تفصيلاً التي تقدمها المنصات الأخرى.
تتضمن المنصة مجموعة متنوعة من نماذج اللغات، منظمة بناءً على تطبيقاتها المحددة. ومن خلال تصنيف النماذج وفقًا لحالات الاستخدام الخاصة بها، فإنه يساعد المستخدمين على تحديد الحلول التي تتوافق مع احتياجاتهم الخاصة بسهولة.
OpenRouter Rankings uses a usage-based evaluation system, considering multiple factors like response quality, efficiency, and cost. These metrics are combined into composite scores that provide a clear picture of each model’s overall effectiveness and value.
يتم تحديث التصنيفات بانتظام لمراعاة التغييرات في أداء النموذج واتجاهات الاستخدام، مما يضمن بقاء البيانات ذات صلة وحديثة.
ينصب التركيز الرئيسي للمنصة على العوامل الاقتصادية. ومن خلال تحليل الأسعار والمقاييس المتعلقة بالتكلفة، فإنه يوفر وضوحًا بشأن التوازن بين التكلفة والأداء، مما يساعد المستخدمين على اتخاذ قرارات مستنيرة.
تبرز Hugging Face Open LLM Leaderboard كمنصة مخصصة لتقييم أداء نماذج اللغات مفتوحة المصدر. تم تصميمه بواسطة Hugging Face، وهو بمثابة مورد مركزي للباحثين والمطورين الذين يتطلعون إلى مقارنة النماذج بالمعايير القياسية. من خلال التركيز حصريًا على النماذج مفتوحة المصدر، تتوافق لوحة المتصدرين مع احتياجات أولئك الذين يقدرون الشفافية وإمكانية الوصول المفتوحة في حلول الذكاء الاصطناعي الخاصة بهم. وهو يكمل المقارنات المستندة إلى المؤسسات والأداء التي تمت مناقشتها سابقًا، ويقدم منظورًا فريدًا لمشهد الذكاء الاصطناعي مفتوح المصدر.
تنظم لوحة المتصدرين مجموعة واسعة من النماذج مفتوحة المصدر حسب حجم المعلمة - 7B، و13B، و30B، و70B+ - والتي تشمل التصميمات التجريبية والتطبيقات واسعة النطاق من المؤسسات البحثية الرائدة.
ويتميز بمساهمات من المؤسسات والمطورين الأفراد، مما يعزز نظامًا بيئيًا متنوعًا وديناميكيًا يعكس الوضع الحالي للذكاء الاصطناعي مفتوح المصدر. يتضمن كل نموذج إدخال معلومات تفصيلية عن البنية وبيانات التدريب وشروط الترخيص، مما يمكّن المستخدمين من اتخاذ خيارات مستنيرة بناءً على احتياجات المشروع ومتطلبات الامتثال.
باستخدام إطار تقييم موحد، تقوم Hugging Face بتقييم النماذج بناءً على معايير متعددة، وتقدم تحليلاً شاملاً لقدراتها. تغطي هذه المعايير مهارات التفكير، والاحتفاظ بالمعرفة، وحل المشكلات الرياضية، وفهم القراءة، مما يضمن رؤية شاملة لأداء كل نموذج.
تستخدم المنصة خطوط أنابيب آلية للحفاظ على ظروف اختبار متسقة عبر جميع النماذج. يؤدي هذا إلى إزالة التناقضات الناجمة عن البيئات أو المنهجيات المختلفة، مما يوفر للمستخدمين مقارنات موثوقة ومتكاملة لتحديد الأنسب لحالات الاستخدام المحددة الخاصة بهم.
يتم تحديث لوحة المتصدرين باستمرار بنماذج جديدة عند ظهورها في مجتمع مفتوح المصدر. بفضل عملية التقييم الآلية، يمكن تقييم النماذج وتصنيفها بسرعة دون أي تأخير ناتج عن التدخل اليدوي.
بالإضافة إلى ذلك، تقوم المنصة بإعادة تقييم النماذج الحالية كلما تم تحسين المنهجيات المعيارية. ويضمن ذلك بقاء النماذج القديمة ممثلة بشكل عادل، مع الحفاظ على أهمية لوحة المتصدرين ومصداقيتها بمرور الوقت.
While the leaderboard doesn’t provide direct pricing, it includes key details such as model size, memory requirements, and inference speed. These metrics help users estimate the infrastructure costs involved in deploying each model.
يتيح هذا التركيز على المتطلبات الحسابية للمؤسسات اتخاذ قرارات تراعي الميزانية، وخاصة تلك التي تعمل بموارد محدودة أو قيود أجهزة محددة. ومن خلال التركيز على النماذج مفتوحة المصدر، تعمل المنصة أيضًا على إلغاء رسوم الترخيص المستمرة، مما يجعل التكلفة الإجمالية للملكية أكثر قابلية للتنبؤ بها وأكثر قابلية للإدارة في كثير من الأحيان مقارنة بالبدائل الخاصة.
تم تخصيص لوحة المتصدرين Scale AI SEAL لتقييم سلامة ومواءمة وأداء نماذج اللغات الكبيرة (LLMs)، ومعالجة مخاوف المؤسسة الرئيسية بشأن نشر الذكاء الاصطناعي بشكل مسؤول. على عكس لوحات المتصدرين ذات الأغراض العامة، يركز SEAL على تقييم مدى جودة تعامل النماذج مع المحتوى الحساس، والالتزام بالمبادئ التوجيهية الأخلاقية، والحفاظ على السلوك المتسق عبر سيناريوهات متنوعة. وهذا يسلط الضوء على أهمية السلامة والامتثال الأخلاقي إلى جانب الأداء الأولي في بيئات المؤسسات. يوفر منهجها المتخصص رؤى تفصيلية حول قدرات النموذج وطرق التقييم وجداول التحديث والتكاليف المرتبطة بها.
يقوم SEAL بمراجعة مزيج من النماذج الخاصة والمفتوحة المصدر، مع التركيز القوي على تلك المستخدمة بشكل شائع في تطبيقات الأعمال. تشتمل لوحة المتصدرين على نماذج تجارية رفيعة المستوى مثل GPT-4 وClaude وGemini، بالإضافة إلى خيارات مفتوحة المصدر شائعة مثل متغيرات Llama 2 وMistral.
ما يميز SEAL هو تركيزه على النماذج الجاهزة للمؤسسات بدلاً من الإصدارات التجريبية أو التي تركز على الأبحاث. يتم اختبار كل نموذج عبر أحجام معلمات مختلفة وتكوينات مضبوطة بدقة، مما يوفر فهمًا أعمق لكيفية تأثير هذه الاختلافات على التوازن بين السلامة والأداء. تقوم المنصة أيضًا بتقييم النماذج المتخصصة المصممة خصيصًا لصناعات مثل الرعاية الصحية أو التمويل، حيث يعد الامتثال التنظيمي وإدارة المخاطر أمرًا بالغ الأهمية.
يستخدم SEAL إطار تقييم شامل يمزج مقاييس الأداء التقليدية مع اختبارات السلامة الشاملة. يتم تقييم النماذج على أساس قدرتها على رفض المطالبات الضارة، والحفاظ على الدقة الواقعية، وتجنب إنتاج مخرجات متحيزة أو تمييزية.
تتضمن عملية التقييم تمارين الفريق الأحمر والمراجعات البشرية للكشف عن نقاط الضعف والتحيزات الدقيقة التي قد يتجاهلها الاختبار الآلي. من خلال الجمع بين التقييمات الآلية واليدوية، يضمن SEAL أن يتم إعطاء اعتبارات السلامة وزنًا متساويًا إلى جانب مقاييس الأداء.
يتم تحديث لوحة المتصدرين لـ SEAL كل ثلاثة أشهر، مما يعكس الطبيعة التفصيلية التي تركز على السلامة لتقييماتها. يتضمن كل تحديث نماذج تم إصدارها حديثًا ويعيد تقييم النماذج الحالية وفقًا لمعايير ومعايير السلامة المتطورة.
بالإضافة إلى هذه التحديثات المجدولة، يصدر Scale AI تقارير مؤقتة عند حدوث تحديثات مهمة للنموذج أو حوادث متعلقة بالسلامة داخل مجتمع الذكاء الاصطناعي. ويضمن هذا النهج التكيفي حصول مستخدمي المؤسسات على إمكانية الوصول في الوقت المناسب إلى أحدث تقييمات السلامة، وهو أمر مهم بشكل خاص نظرًا للوتيرة السريعة لتقدم النماذج. توفر هذه التحديثات المنتظمة أيضًا بيانات قيمة لتحليل تكاليف النشر.
While SEAL doesn’t disclose direct pricing, it offers insights into the total cost of ownership, including factors like content moderation, compliance requirements, and liability risks. This helps enterprises weigh the costs of safety measures against operational expenses.
توفر المنصة أيضًا إرشادات حول احتياجات البنية التحتية لمختلف تكوينات السلامة، مما يساعد المؤسسات على فهم المفاضلات بين السلامة المعززة والتكاليف التشغيلية. بالنسبة لمستخدمي المؤسسات، يقوم SEAL بتقدير التوفير المحتمل من جهود الإشراف على المحتوى المنخفض عند نشر النماذج ذات ميزات الأمان المدمجة القوية.
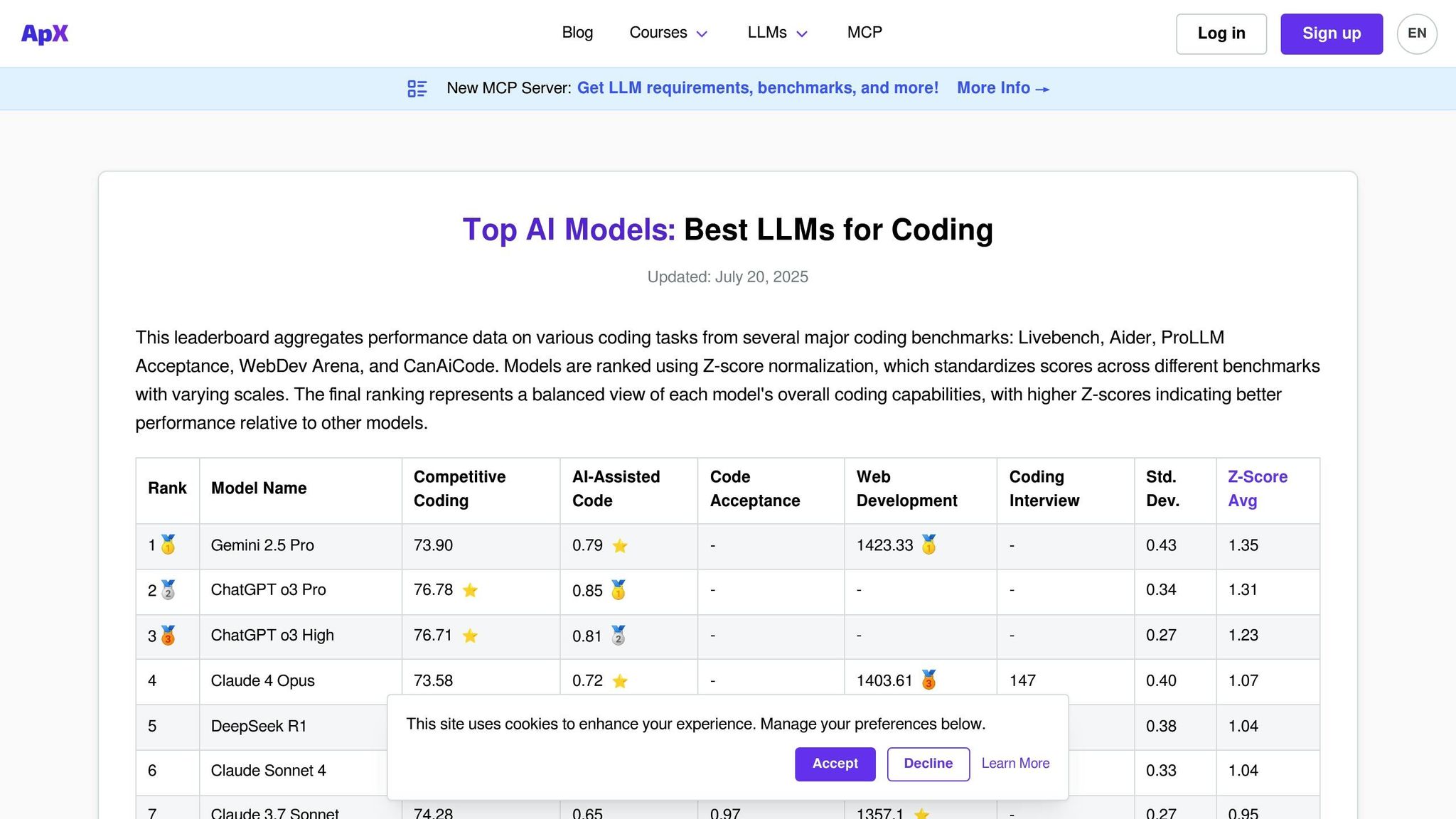
APX Coding LLMs عبارة عن منصة مصممة خصيصًا لتقييم إمكانيات الترميز لنماذج اللغة. على عكس لوحات المتصدرين ذات الأغراض العامة التي تركز على مجموعة واسعة من مهارات المحادثة، تركز APX على مجالات مثل إنشاء التعليمات البرمجية وتصحيح الأخطاء وتنفيذ الخوارزمية وحل المشكلات الفنية. وهذا التركيز يجعلها أداة أساسية للمطورين والفرق الهندسية والمؤسسات التي تهدف إلى دمج مساعدي البرمجة الذين يعملون بالذكاء الاصطناعي في سير عملهم.
تقوم المنصة بتقييم كيفية تعامل النماذج مع تحديات البرمجة العملية عبر اللغات والأطر المختلفة. على غرار منصات التقييم الأخرى، تعمل APX على تبسيط عملية التقييم ولكن مع التركيز الشديد على أداء التعليمات البرمجية وأمانها.
تتميز APX بتشكيلة واسعة من النماذج التجارية ومفتوحة المصدر التي تم اختبارها لخبرتها في البرمجة. تقوم المنصة بانتظام بتقييم نماذج الترميز المعروفة مثل نماذج GPT الأساسية لـ GitHub Copilot، ومتغيرات CodeT5، وStarCoder، وCode Llama. ويتضمن أيضًا نماذج للأغراض العامة تتمتع بقدرات برمجية قوية، مثل GPT-4 وClaude وGemini.
أحد الفروق الرئيسية لـ APX هو تضمينها لنماذج الترميز المتخصصة التي قد لا تظهر على لوحات المتصدرين الأوسع ولكنها تتفوق في مجالات البرمجة المتخصصة. يتم اختبار هذه النماذج عبر أحجام معلمات مختلفة وإصدارات مضبوطة بدقة، بما في ذلك المتغيرات الخاصة بالمجال للغات مثل Python وJavaScript وJava وC++ وRust وGo. تقوم المنصة أيضًا بتقييم الأداء باستخدام أطر عمل مثل React وDjango وTensorFlow وPyTorch.
تضمن هذه التغطية الشاملة أن APX توفر اختبارات صارمة وعملية لاحتياجات الترميز في العالم الحقيقي.
تستخدم APX إطار اختبار مفصلًا مصممًا لسيناريوهات الترميز في العالم الحقيقي. يقوم بتقييم النماذج في جوانب مثل صحة التعليمات البرمجية والكفاءة وسهولة القراءة والالتزام بمعايير الأمان من خلال مجموعة من الاختبارات الآلية ومراجعات الخبراء.
تتضمن سيناريوهات الاختبار تحديات الخوارزمية، وتصحيح التعليمات البرمجية المعيبة، ومهام إعادة البناء، وإنشاء الوثائق. يتم تقييم النماذج أيضًا لقدرتها على شرح مفاهيم التعليمات البرمجية المعقدة واقتراح التحسينات.
Incorporating industry-standard coding practices, APX evaluates whether models follow established conventions for naming, commenting, and structuring code. Additionally, it tests the models’ ability to recognize and avoid common security vulnerabilities, making it especially valuable for enterprises where secure coding is a priority.
يتم تحديث لوحة المتصدرين APX شهريًا لمواكبة المشهد سريع التطور لأدوات ترميز الذكاء الاصطناعي. تتضمن التحديثات إضافة النماذج التي تم إصدارها حديثًا وإعادة تقييم النماذج الحالية، مما يضمن التوافق مع أحدث تحديات ومعايير البرمجة.
كما توفر المنصة أيضًا تتبعًا للأداء في الوقت الفعلي للحصول على تحديثات مهمة للنماذج، مما يمنح المطورين إمكانية الوصول الفوري إلى أحدث الإمكانات. عند إطلاق النماذج الرئيسية التي تركز على الترميز، تجري APX دورات تقييم خاصة لتوفير رؤى في الوقت المناسب حول أدائها.
توفر APX تحليلاً مفصلاً لتحليل التكلفة لكل رمز مميز مصمم خصيصًا لمهام الترميز. يساعد هذا التحليل المستخدمين على فهم الآثار المترتبة على تكلفة النماذج المختلفة لحالات الاستخدام المختلفة. يتم تقسيم التكاليف حسب لغة البرمجة وتعقيد المهام، مما يوفر رؤى واضحة حول النماذج التي تقدم أفضل قيمة.
يأخذ تحليل التكلفة في الاعتبار عوامل مثل تكرار استدعاء واجهة برمجة التطبيقات (API) أثناء مهام الترميز النموذجية، وأنماط استخدام الرمز المميز، والتوفير المحتمل من تقليل وقت تصحيح الأخطاء. وتقوم APX أيضًا بتقدير التكلفة الإجمالية للملكية للفرق التي تتبنى مساعدي البرمجة بالذكاء الاصطناعي، وموازنة مكاسب الإنتاجية مقابل رسوم الاشتراك والاستخدام. هذا المستوى من التفاصيل يجعل من APX موردًا قيمًا لتقييم التأثير المالي لحلول الترميز المعتمدة على الذكاء الاصطناعي.
تلبي منصات المقارنة جنبًا إلى جنب لنماذج اللغات الكبيرة (LLMs) مجموعة متنوعة من الاحتياجات. تبرز Prompts.ai من خلال توفير الوصول إلى أكثر من 35 نموذجًا من الدرجة الأولى، مقترنة بأدوات مركزية لإدارة التكاليف وضمان الحوكمة. وهذا يجعله خيارًا قويًا للمؤسسات الأكبر حجمًا التي تحتاج إلى سير عمل آمن ومتوافق مع إشراف قوي.
بينما تركز Prompts.ai على إدارة التكلفة والحوكمة، تركز المنصات الأخرى على أولويات مختلفة. وقد تشمل هذه الملاحظات التعليقات التي يحركها المجتمع، أو المعايير الفنية، أو المقاييس المتخصصة مثل السلامة والمواءمة. تختلف هذه المنصات في اختيارات النماذج وطرق التقييم وجداول التحديث والشفافية في التسعير.
This summary complements earlier in-depth analyses, helping you identify the tools that best fit your goals. Whether your focus is budget, technical depth, or specific use cases, it’s worth noting that many organizations rely on a mix of platforms to achieve a well-rounded understanding of both technical and business needs.
When evaluating platforms for large language model (LLM) comparison, the best choice ultimately hinges on balancing factors like cost, performance, and compliance. The decision should align with your organization’s specific needs, technical capabilities, and workflow demands.
For enterprises seeking a unified AI orchestration solution, Prompts.ai offers a compelling option. With access to over 35 leading LLMs, integrated cost management tools, and enterprise-grade governance controls, it’s designed to simplify operations for organizations overseeing multiple teams and complex projects.
That said, the LLM platform landscape is diverse, and there’s no universal solution that fits every scenario. Many organizations adopt a mix of tools to address both research and production requirements. By focusing on your primary goals - whether it’s reducing costs, enhancing performance, or ensuring compliance - you can refine your platform selection process and streamline AI implementation.
يمكن أن يؤدي اختيار أدوات التنسيق والمقارنة المناسبة إلى تحسينات قابلة للقياس في مبادرات الذكاء الاصطناعي الخاصة بك وتحقيق نتائج أعمال مفيدة.
تعمل Prompts.ai على تبسيط التحدي المتمثل في تقييم نماذج اللغات الكبيرة المتعددة (LLMs) من خلال تقديم رؤى واضحة وقابلة للتنفيذ حول أدائها وقابلية التوسع وفعالية التكلفة. وهذا يمكّن المستخدمين من اتخاذ خيارات مستنيرة، واختيار النموذج الذي يناسب احتياجاتهم بشكل أفضل مع البقاء في حدود الميزانية.
باستخدام الأدوات المصممة لتقييم التوازن بين التكلفة والأداء، فضلاً عن الكفاءة التشغيلية، تضمن Prompts.ai للشركات إمكانية تجنب النفقات غير الضرورية والتركيز على تنفيذ الحلول الأكثر فعالية المصممة خصيصًا لمتطلباتها الفريدة.
إن المنصات التي تقدم أدوات لتخصيص المقارنات لنماذج اللغات الكبيرة (LLMs) لا تقدر بثمن لأنها تسمح للمستخدمين بضبط التقييمات لتتناسب مع أهدافهم الفريدة. ومن خلال التركيز على الجوانب الهامة مثل الأداء والميزات والتطبيقات العملية، تعمل هذه الأدوات على تبسيط عملية تحديد النموذج الأكثر ملاءمة، مما يقلل من التخمين.
توفر أدوات المقارنة هذه أيضًا معايير أكثر تفصيلاً، وتقدم رؤى قيمة للباحثين والمطورين والشركات على حدٍ سواء. سواء كنت تعمل على تحسين حل لمهمة محددة أو تقييم خيارات متعددة، فإن هذه الأنظمة الأساسية تجعل عملية اتخاذ القرار أسرع وأكثر فعالية.
يعد التحديث المنتظم لأساليب التقييم وقواعد البيانات النموذجية أمرًا ضروريًا للحفاظ على الدقة والاعتمادية والمصداقية في منصات الذكاء الاصطناعي. تعمل هذه التحديثات على تمكين النماذج من البقاء محدثة من خلال دمج البيانات الجديدة، والتكيف مع الاتجاهات، ومعالجة حالات الاستخدام الجديدة، مما يؤدي في النهاية إلى تعزيز الأداء وصنع القرار.
يسمح التحسين المستمر للمنهجيات للمنصات بمعالجة التحيزات، وتحسين القدرة على التكيف مع النماذج، وتلبية معايير الصناعة المتغيرة. يضمن هذا التفاني في التقدم أن تظل حلول الذكاء الاصطناعي فعالة ومتوافقة ومجهزة لتلبية احتياجات المستخدم في بيئة سريعة الحركة.



















